






奇月 发自 凹非寺
量子位 | 公众号 QbitAI
入职MIT电气工程和计算机科学系的何恺明,第一波门下弟子现在曝光——

可以看到,四位研究者中其中有三位都是3位是华人:白行建、邓明扬、黎天鸿。
我们熟悉的IMO、IOI双料奥赛金牌得主邓明扬也在列。
事实上,在不久之前,他们就已经合作了一篇文章:无需矢量量化的自回归图像生成 何恺明新作再战AI生成:入职MIT后首次带队,奥赛双料金牌得主邓明扬参与
这篇文章提出了一种新的图像生成方法,通过扩散过程来建模每个标记的概率分布,从而避免了使用离散值的tokenizer,并在连续值空间中实现了自回归模型的应用。

这篇文章黎天鸿博士后是论文的一作,此外他还参与了何恺明团队的其他多项学术研究:


何恺明副教授的主页也更新了头像、联系方式和履历,还有一些最新的MIT课程和演讲等:


何恺明MIT实验室成员首次公开
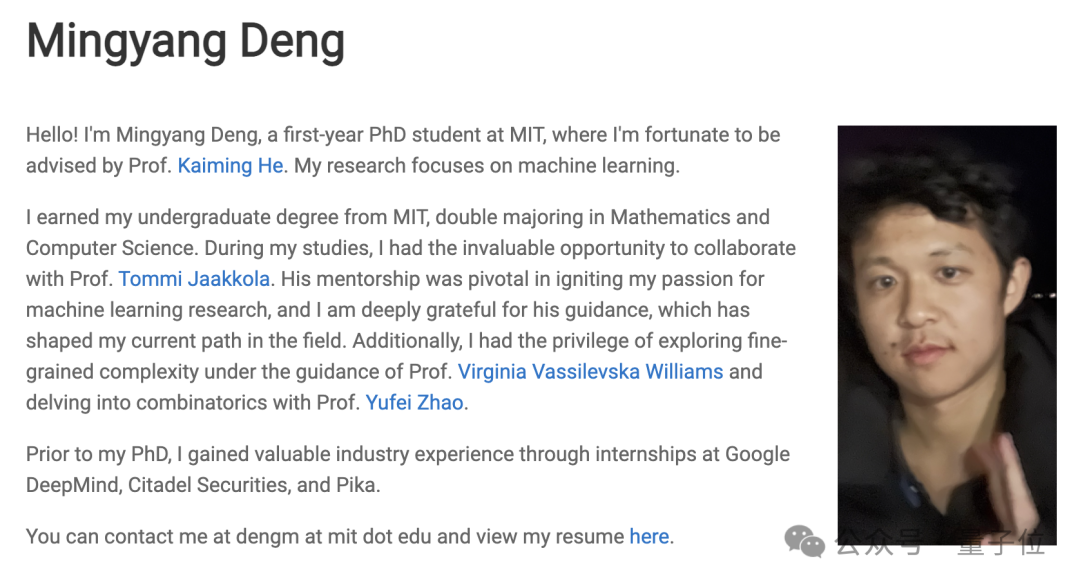
博士一年级生邓明扬
邓明扬,MIT数学和计算机科学本科。
他从小学三年级就开始竞赛,在高一获得IMO(国际数学奥林匹克竞赛)金牌,高三获得IOI(国际信息学奥林匹克竞赛)金牌,国内首位在不同学科获得国际金牌的选手,也是IOI历史上第三位满分选手,人称“乖神”。
此外他还曾获得ICPC国际大学生程序设计竞赛世界总决赛的第1名。
目前邓明扬的研究重点是机器学习,特别是理解和推进生成式基础模型,包括扩散模型和大型语言模型。

博士一年级生白行健
白行健高中毕业于北师大实验中学,在牛津大学获得了数学和计算机科学的硕士和学士学位。
他的研究重点目前是是经典算法和深度学习的交叉领域。
他也参与了多项竞赛,曾获得2018年CCO(加拿大信息学奥林匹克竞赛)第一名,NOI(中国信息学奥林匹克竞赛)银牌,NOIP(中国信息学联赛)北京市提高组一等奖第3名等。
高三时,他就凭借自适应图卷积神经网络检测网络暴力的论文入围了丘成桐中学科学奖决赛。


博士后黎天鸿
黎天鸿本科毕业于清华叉院姚班,在MIT获得了硕博学位之后,目前在何恺明组内从事博士后研究。
根据他的主页最新消息显示,他将担任ICLR 2025的区域主席。
他的主要研究方向是表示学习和生成模型,目标是构建能够理解人类感知之外的世界的智能视觉系统。
此前曾作为一作和何恺明开发了自条件图像生成框架RCG,团队最新的多项研究中他也都有参与。

有趣的是,他还非常喜欢做饭,主页上放了很多自己总结的食谱。
博士生Jake Austin
还有一位博士生Jake Austin,之前在加州伯克利大学人工智能研究所任职。
她的谷歌学术主页被引数超过了500,主要成果也是集中在计算机视觉领域。
何恺明团队的最新动态
CV相关
何恺明团队最新的学术研究成果还是主要集中在他擅长的CV领域。
最新一篇是发表于10月17日的一篇论文:Fluid: Scaling Autoregressive Text-to-image Generative Models with Continuous Tokens。
这篇论文通过实证研究表明,使用连续标记和随机顺序生成的自回归模型在文本到图像生成任务中表现出最佳的扩展性和生成质量,团队提出的Fluid模型刷新了新的零样本FID和GenEval分数。

另一篇Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformers发表于9月30日。
这篇文章提出了一种名为Heterogeneous Pre-trained Transformers (HPT) 的架构,通过跨不同机器人本体和任务的异构预训练来学习通用的策略表示,并在大规模机器人仿真和真实世界环境中验证了其有效性。

主页还列出了更多研究内容,包括自回归图像生成、单张图像3D物理建模、使用拉格朗日体积网格表示高质量几何形状等等,多篇文章都已被NeurlPS 2024接收。

AI for Science相关
之前,何恺明副教授在MIT的求职演讲上特意提到,AI for Science也将是他未来的工作方向。
5月他曾发表了这个方向的首个工作:使用强化学习的动态异构量子资源调度。文章使用自注意力机制处理量子比特对的序列信息,在概率性环境中训练强化学习模型,提供动态实时调度指导,最终将量子系统性能提升了3倍以上。

多位大神云集,让我们一起期待何恺明团队未来的更多成果吧!
参考链接:
[1]https://people.csail.mit.edu/kaiming/


















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









