






Wonderland团队 投稿
量子位 | 公众号 QbitAI
只需一张图,就能生成高质量、广范围的3D场景!
泰迪熊、花园、山谷都从平面图片变成了仿佛触手可及的立体物品。

这就是来自多伦多大学、Snap和UCLA的研究团队推出的全新模型——Wonderland。

他们首次证明,三维重建模型可以有效地建立在扩散模型的潜在空间上,进而实现高效的三维场景生成,是单视图3D场景生成领域的一次突破性进展。
具体来说,团队引入了一种大规模重建模型,该模型使用视频扩散模型中的潜在信息,以前馈方式预测场景的3D表示(3DGS)。
视频扩散模型可以精确地按照指定的相机轨迹创建视频,生成包含多视角信息的潜在特征,同时保持三维一致性。
三维重建模型则通过渐进式训练策略在视频潜在空间进行训练,高效地生成高质量、大范围和通用的三维场景。

这样一来,机器就可以高效地模拟人类从单张图像中感知并想象三维世界的能力了。
技术突破:从单张图像到三维世界的关键创新
传统的3D重建技术往往依赖于多视角数据或逐个场景(per-scene)的优化,且在处理背景和不可见区域时容易失真。
为解决这些问题,Wonderland创新性地结合视频生成模型和大规模3D重建模型,实现了高效高质量的大规模3D场景生成:
向视频扩散模型中嵌入3D意识
通过向视频扩散模型中引入相机位姿控制,Wonderland在视频latent空间中嵌入了场景的多视角信息,并能保证3D一致性。视频生成模型在相机运动轨迹的精准控制下,将单张图像扩展为包含丰富空间关系的多视角视频。
双分支相机控制机制
利用ControlNet和LoRA模块,Wonderland实现了在视频生成过程中对于丰富的相机视角变化的精确控制,显著提升了多视角生成的视频质量、几何一致性和静态特征。
大规模latent-based 3D重建模型(LaLRM)
Wonderland创新地引入了3D重建模型LaLRM,利用视频生成模型生成的latent直接重构3D场景(feed-forward reconstruction)。重建模型的训练采用了高效的逐步训练策略,将视频latent空间中的信息转化为3D高斯点分布(3D Gaussian Splatting, 3DGS),显著降低了内存需求和重建时间成本。凭借这种设计,LaLRM能够有效地将生成和重建任务对齐,同时在图像空间与三维空间之间建立了桥梁,实现了更加高效且一致的广阔3D场景构建。
效果展示:视频生成
基于单张图和camera condition,实现视频生成的精准视角控制:
Input Image and Camera Trajectory
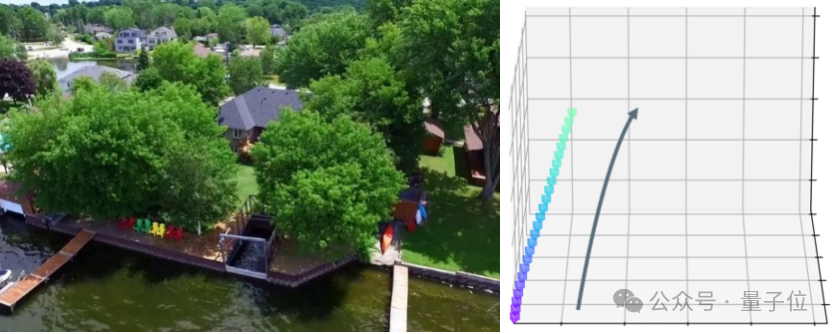

Input Image and Camera Trajectory


Camera-guided视频生成模型可以精确地遵循轨迹的条件,生成3D-geometry一致的高质量视频,并具有很强的泛化性,可以遵循各种复杂的轨迹,并适用于各种风格的输入图片。
一起来看看更多的例子:
不同的输入图片,同样的三条相机轨迹,生成的视频:
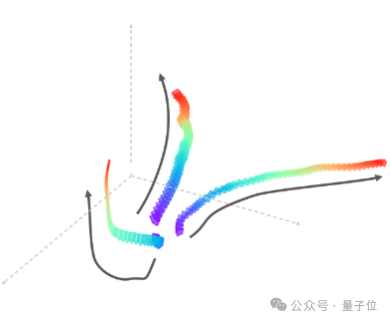




给定输入图片和多条相机轨迹,生成视频可以深度地探索场景:


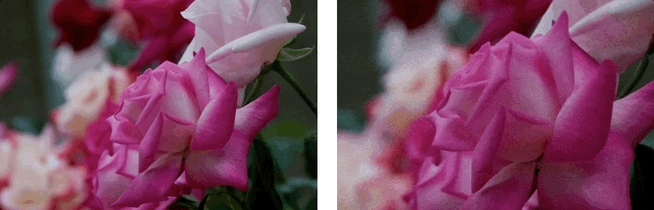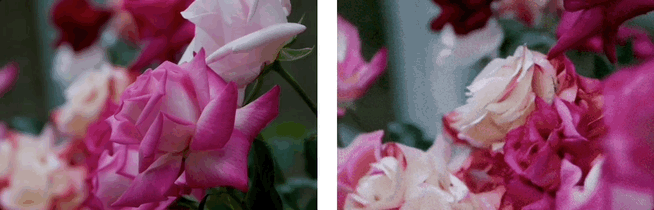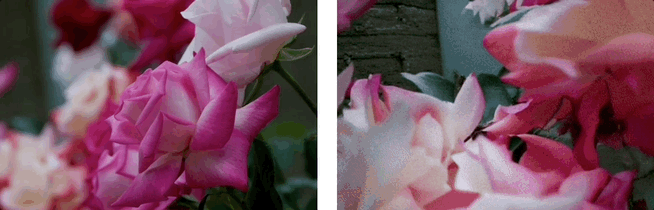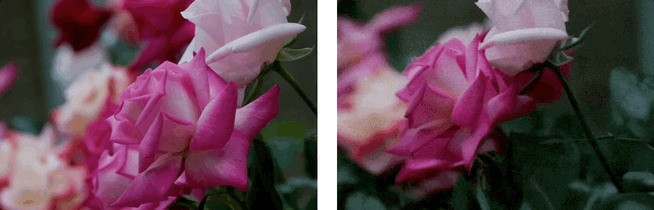


效果展示:3D场景生成
基于单张图,利用LaLRM, Wonderland 可以生成高质量的、广阔的3D场景:





基于单张图和多条相机轨迹,Wonderland 可以深度探索和生成高质量的、广阔的3D场景:


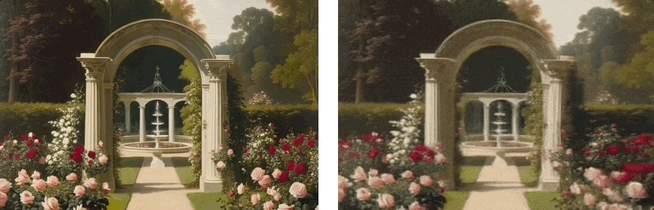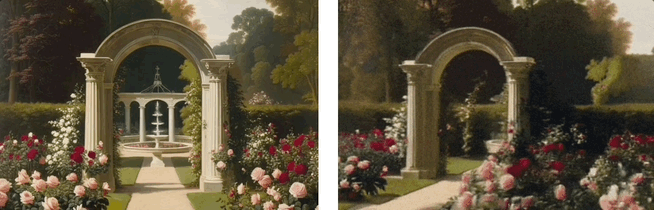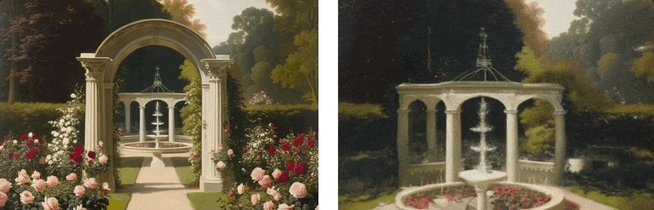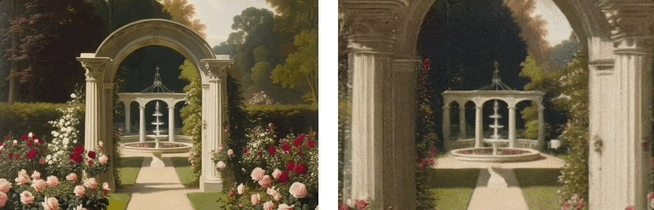


卓越性能:在视觉质量和生成效率等多个维度上表现卓越
Wonderland的主要特点在于其精确的视角控制、卓越的场景生成质量、生成的高效性和广泛的适用性。
实验结果显示,该模型在多个数据集上的表现超越现有方法,包括视频生成的视角控制、视频生成的视觉质量、3D重建的几何一致性和渲染的图像质量、以及端到端的生成速度均取得了优异的表现:
双分支相机条件策略:通过引入双分支相机条件控制策略,视频扩散模型能够生成3D-geometry一致的多视图场景捕捉,且相较于现有方法达到了更精确的姿态控制。
Zero-shot 3D 场景生成:在单图像输入的前提下,Wonderland可进行高效的3D场景前向重建,在多个基准数据集(例如RealEstate10K、DL3DV 和Tanks-and-Temples)上的3D场景重建质量均优于现有方法。
广覆盖场景生成能力: 与过去的3D 前向重建通常受限于小视角范围或者物体级别的重建不同,Wonderland能够高效生成广范围的复杂场景。其生成的3D场景不仅具备高度的几何一致性,还具有很强的泛化性,能处理out-of-domain的场景。
超高效率: 在单张图像输入的问题设定下,利用单张A100,Wonderland仅需约5分钟即可生成完整的3D场景。这一速度相比需要16分钟的Cat3D提升了3.2倍,相较需要3小时的ZeroNVS更是提升了36倍。
应用场景:视频和3D场景内容创作的新工具
Wonderland的出现为视频和3D场景的创作提供了一种崭新的解决方案。
在建筑设计、虚拟现实、影视特效以及游戏开发等领域,该技术展现了广阔的应用潜力。
通过其精准的视频位姿控制和具备广视角、高清晰度的3D场景生成能力,Wonderland能够满足复杂场景中对高质量内容的需求,为创作者带来更多可能性。
尽管模型表现优异,Wonderland研发团队深知仍有许多值得提升和探索的方向。
例如,进一步优化对动态场景的适配能力、提升对真实场景细节的还原度等,都是未来努力的重点。
希望通过不断改进和完善,让这一研发思路不仅推动单视图3D场景生成技术的进步,也能为视频生成与3D技术在实际应用中的广泛普及贡献力量。
论文: https://arxiv.org/abs/2412.12091
项目主页:https://snap-research.github.io/wonderland/


















 59
59

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









