







基于Python北京二手房爬虫&数据分析项目
运行环境:jupyter notebook
项目包含:一份数据集(1800条)➕一份爬虫代码➕一份分析代码➕一份分析报告

创建一个基于Python的北京二手房爬虫及数据分析项目涉及多个步骤,包括数据抓取、数据清洗和数据分析。我们将使用requests和BeautifulSoup进行网页抓取,并使用pandas和matplotlib等库进行数据分析和可视化。
1. 安装必要的库
首先确保安装了以下库:
pip install requests beautifulsoup4 pandas matplotlib seaborn
2. 爬虫部分
下面是一个简单的爬虫示例,用于从某房产网站抓取北京二手房信息。请注意,实际操作时需要根据目标网站的结构调整代码,并遵守网站的robots.txt文件和服务条款。
# house_crawler.py
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_house_listings(page=1):
url = f"https://bj.lianjia.com/ershoufang/pg{page}/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
listings = []
for item in soup.find_all('li', class_='clear'):
try:
title = item.find('div', {'class': 'title'}).text.strip()
price = item.find('div', {'class': 'totalPrice'}).text.strip()
unit_price = item.find('div', {'class': 'unitPrice'}).text.strip()
area = item.find('div', {'class': 'houseInfo'}).text.split('|')[1].strip()
listings.append([title, price, unit_price, area])
except AttributeError:
continue
return listings
def main():
all_listings = []
# 假设我们抓取前5页的数据
for i in range(1, 6):
print(f"Fetching page {i}")
listings = get_house_listings(i)
all_listings.extend(listings)
df = pd.DataFrame(all_listings, columns=['Title', 'Total Price', 'Unit Price', 'Area'])
df.to_csv('beijing_ershoufang.csv', index=False)
print("Data saved to beijing_ershoufang.csv")
if __name__ == '__main__':
main()
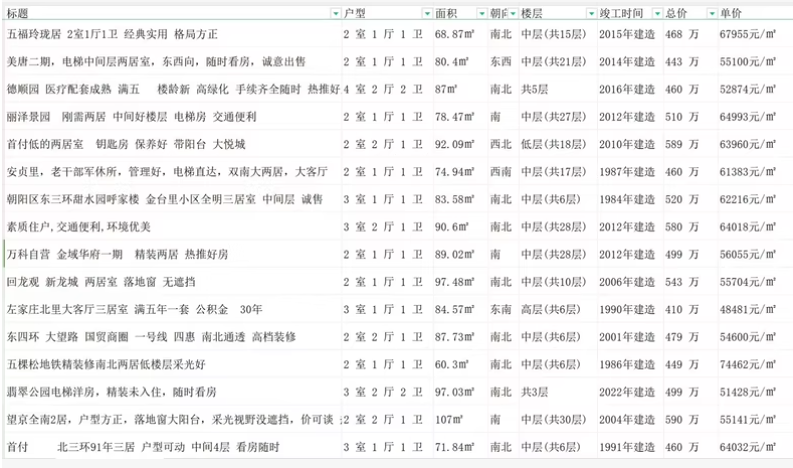
3. 数据分析与可视化
接下来,我们将对收集的数据进行一些基本的分析和可视化。
# data_analysis.py
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def load_and_clean_data(file_path='beijing_ershoufang.csv'):
df = pd.read_csv(file_path)
# 清理数据:去除总价或单价为空的记录
df.dropna(subset=['Total Price', 'Unit Price'], inplace=True)
# 提取单价中的数字
df['Unit Price'] = df['Unit Price'].str.extract('(\d+)')
df['Unit Price'] = df['Unit Price'].astype(float)
# 提取总面积中的数字
df['Area'] = df['Area'].str.extract('(\d+.\d+)').astype(float)
# 转换总价为浮点数
df['Total Price'] = df['Total Price'].str.extract('(\d+)')
df['Total Price'] = df['Total Price'].astype(float)
return df
def basic_analysis(df):
print(df.describe())
# 绘制总价分布直方图
plt.figure(figsize=(10, 6))
sns.histplot(df['Total Price'], bins=30, kde=True)
plt.title('Distribution of Total Prices')
plt.xlabel('Total Price')
plt.ylabel('Frequency')
plt.show()
def correlation_analysis(df):
corr_matrix = df[['Total Price', 'Unit Price', 'Area']].corr()
sns.heatmap(corr_matrix, annot=True)
plt.title('Correlation Matrix')
plt.show()
if __name__ == '__main__':
df = load_and_clean_data()
basic_analysis(df)
correlation_analysis(df)
4. 运行代码
- 首先运行
house_crawler.py以抓取北京二手房信息并保存到CSV文件。 - 接着运行
data_analysis.py来加载这个CSV文件,执行基础数据分析和相关性分析。


















 2118
2118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









