






明敏 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
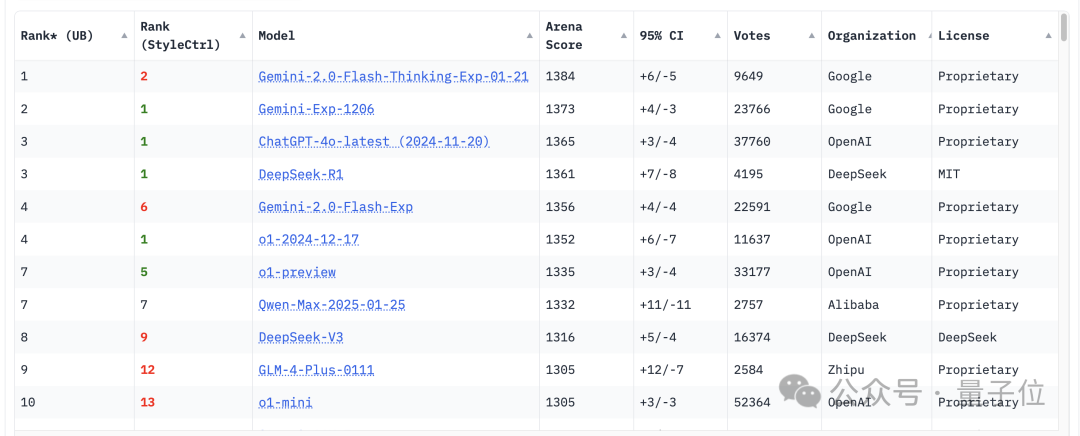
刚刚,大模型竞技场榜单上再添一款国产模型——
来自阿里,Qwen2.5-Max,超越了DeepSeek-V3,以总分1332的成绩位列总榜第七。
同时还一举超越Claude 3.5 Sonnet、Llama 3.1 405B等模型。
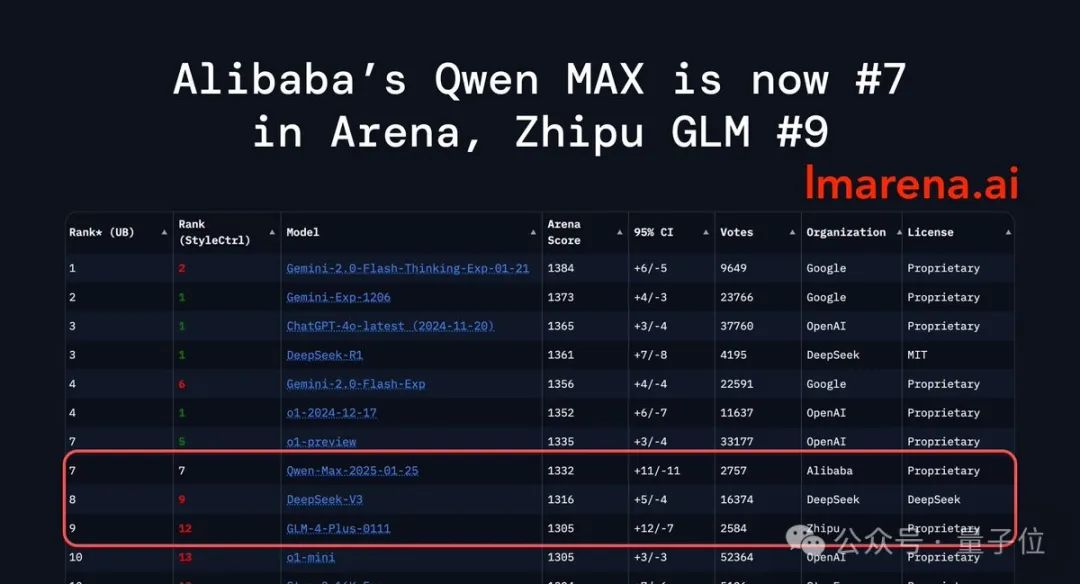
特别是在编程、数学等方面表现格外突出,能够与满血o1、DeepSeek-R1并列第一。
Chatbot Arena是由LMSYS Org推出的大模型性能测试平台,目前集成了190多种模型,采用模型两两组队交给用户盲测,根据真实对话体验对模型能力进行投票。
也正因此, Chatbot Arena LLM Leaderboard是全球顶级大模型的最权威、最重要的竞技场。
在其新开的网页应用开发WebDev榜单上,Qwen2.5-Max也冲进了前十。
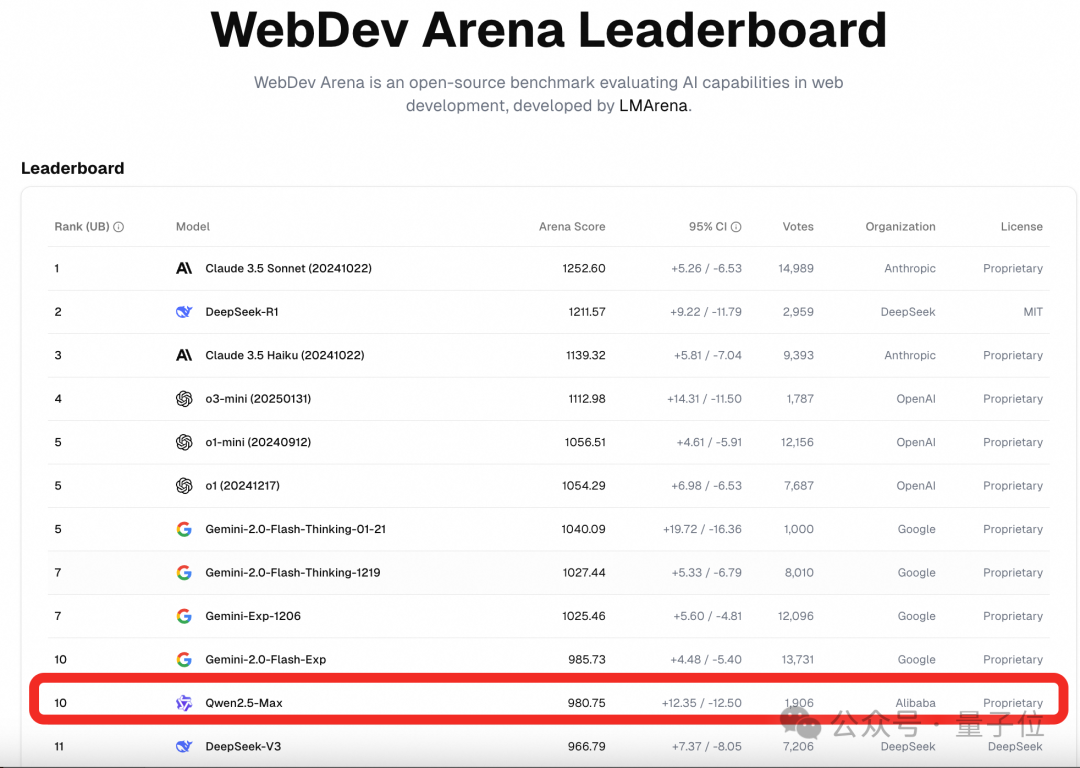
对此lmsys官方评价说,中国AI正在快速缩小差距!

并且亲身使用过的网友表示,相比之下Qwen的表现更加稳定。
还有人说,Qwen很快就会取代硅谷的所有普通模型。
四种单项能力登顶
综合榜单前三名中第一、二名被谷歌Gemini家族包揽,GPT-4o和DeepSeek-R1并列第三。
Qwen2.5-Max则是和o1-preview一起并列第七名,稍逊于满血o1。
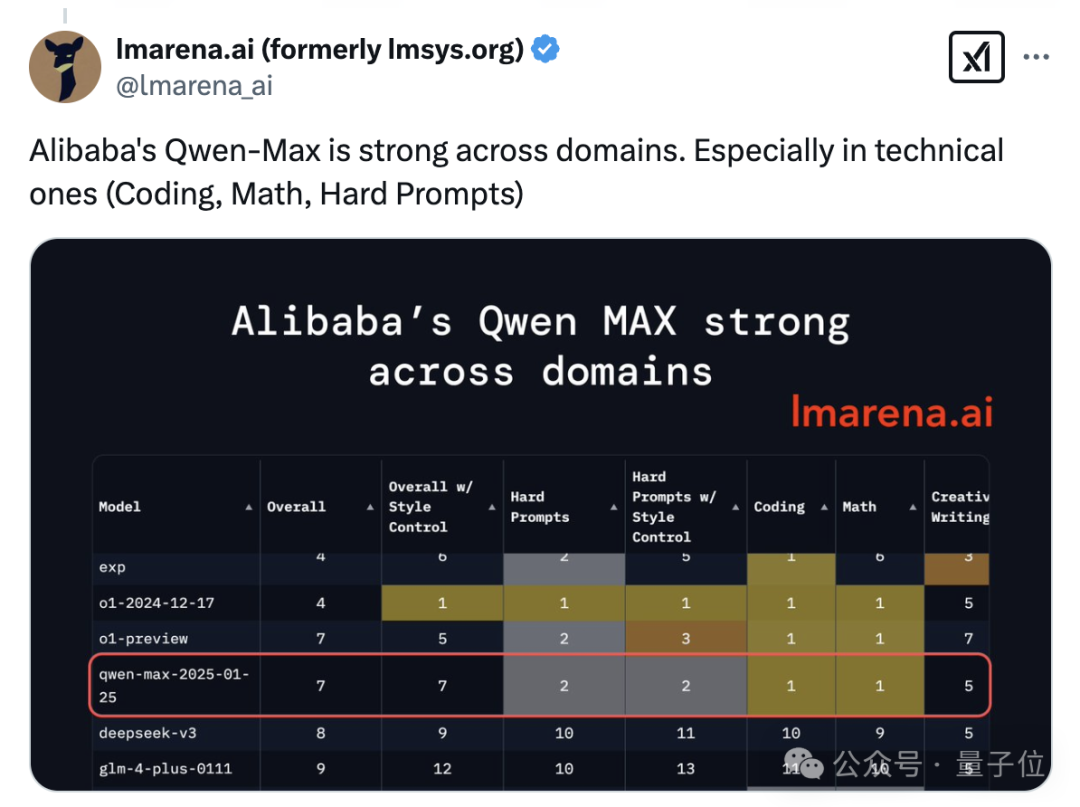
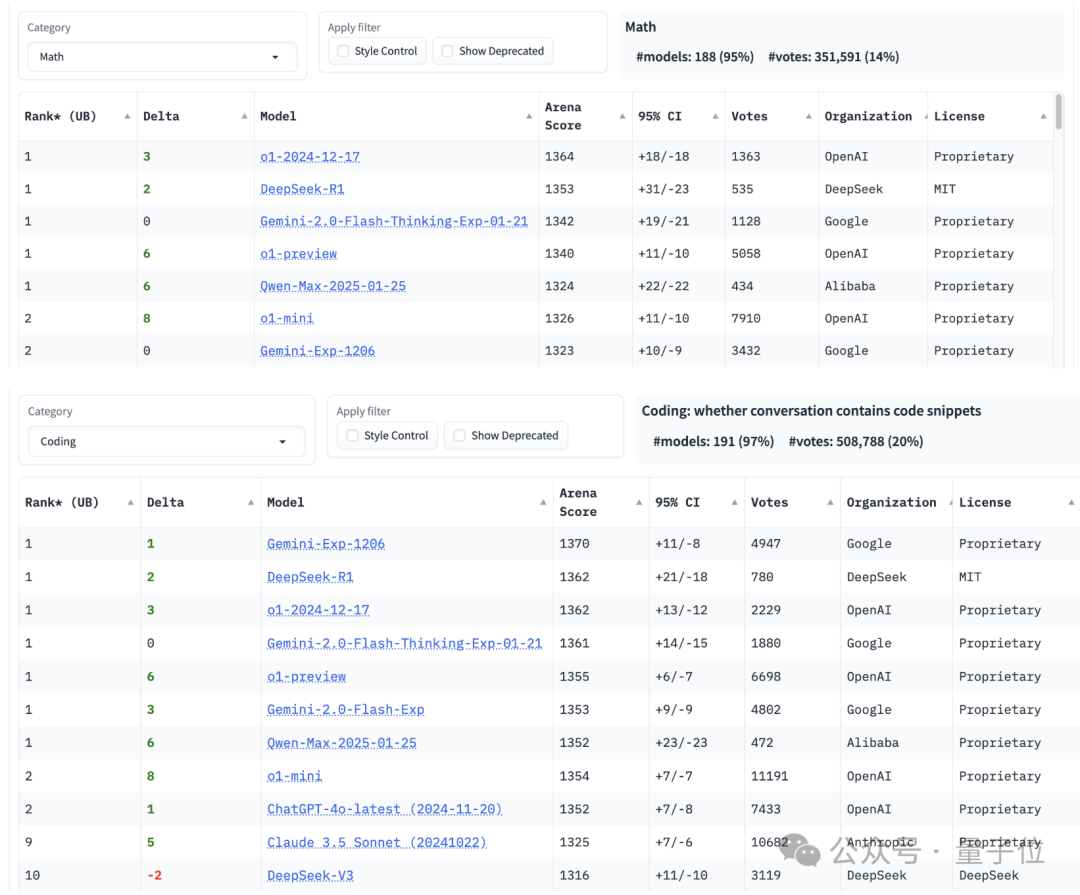
接下来Qwen2.5-Max在各个单项中的表现。
在逻辑性较强的数学和代码任务当中,Qwen2.5-Max的成绩都超过了o1-mini,和满血o1以及DeepSeek-R1并列第一。
并且在数学榜单上并列第一的模型当中,Qwen2.5-Max是唯一一个非推理模型。
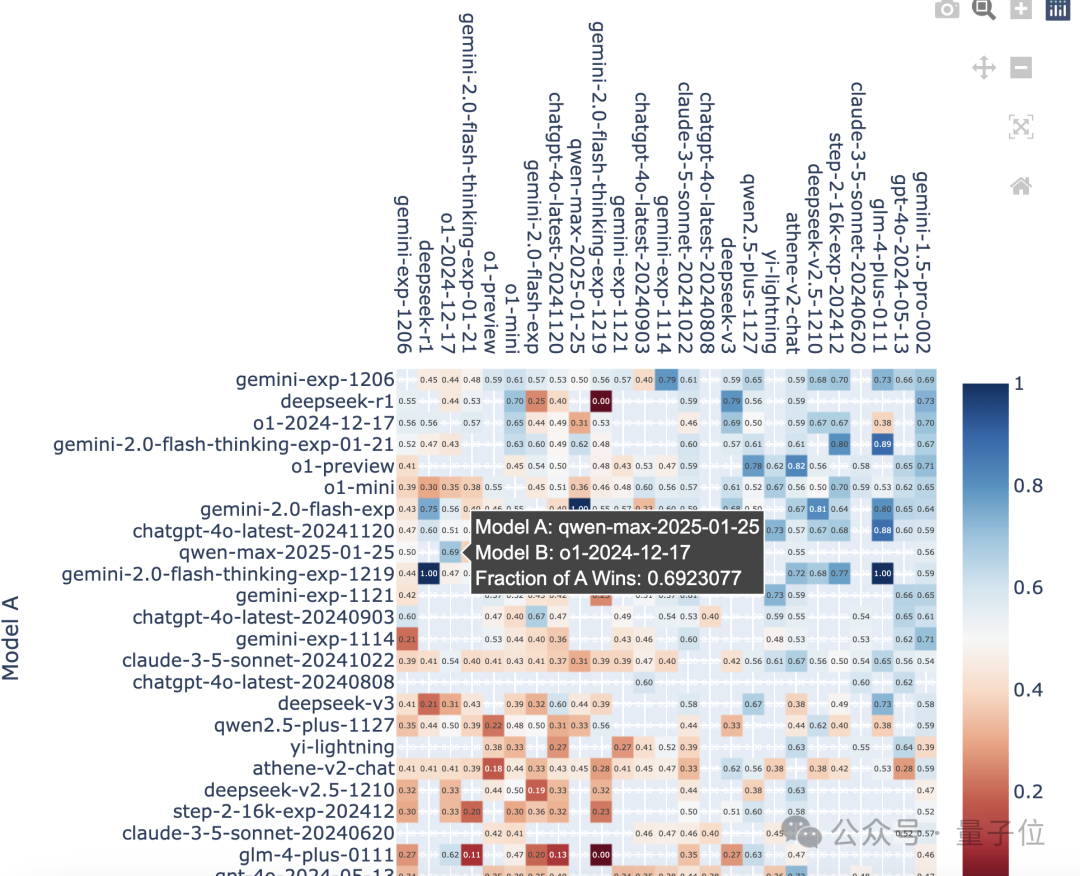
如果仔细观察具体的对战记录,还可以发现,Qwen2.5-Max在代码能力上和满血o1进行PK的胜率达到了69%。
复杂提示词任务中,Qwen2.5-Max和o1-preview并列第二,如果仅限英文则可以排到第一,和o1-preview、DeepSeek-R1等平起平坐。
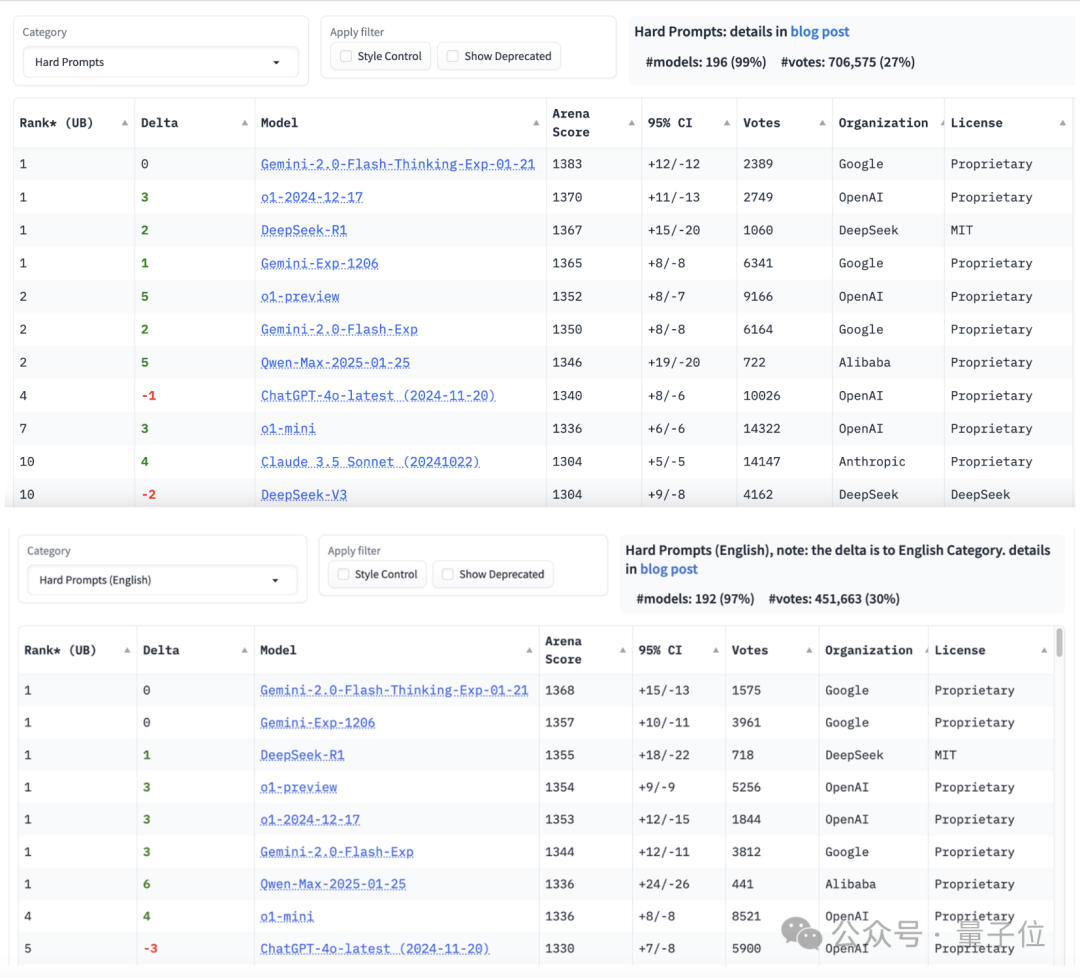
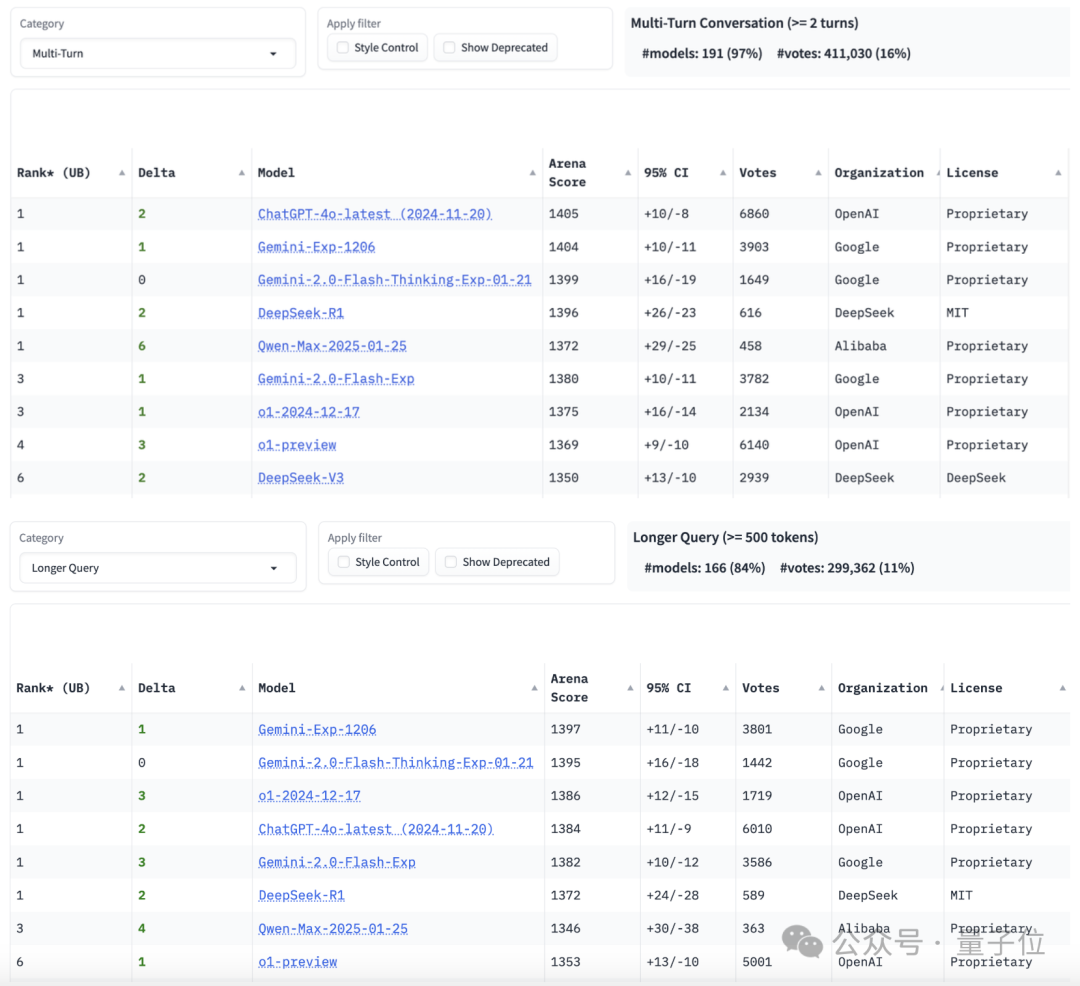
另外,Qwen2.5-Max的多轮对话能力也和DeepSeek-R1并列第一;长文本(不低于500tokens)则排行第三,超过了o1-preview。
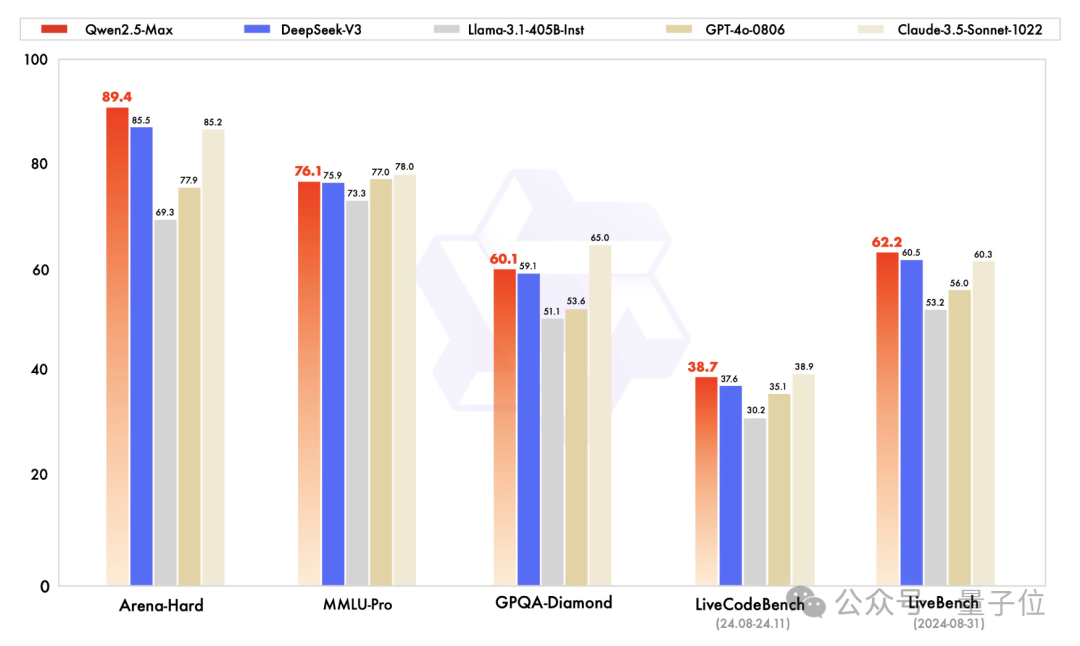
此外,阿里还在技术报告中展示了Qwen2.5-Max在一些经典榜单上的表现。
其中指令模型的对比当中,Qwen2.5-Max在Arena-Hard(近似人类偏好)、MMLU-Pro(大学水平知识)等基准当中,都和GPT-4o以及Claude 3.5-Sonnet处于近似或更高的水准。
在开源的基座模型对比当中,Qwen2.5-Max的成绩也全面超过了DeepSeek-V3,并遥遥领先于Llama 3.1-405B。
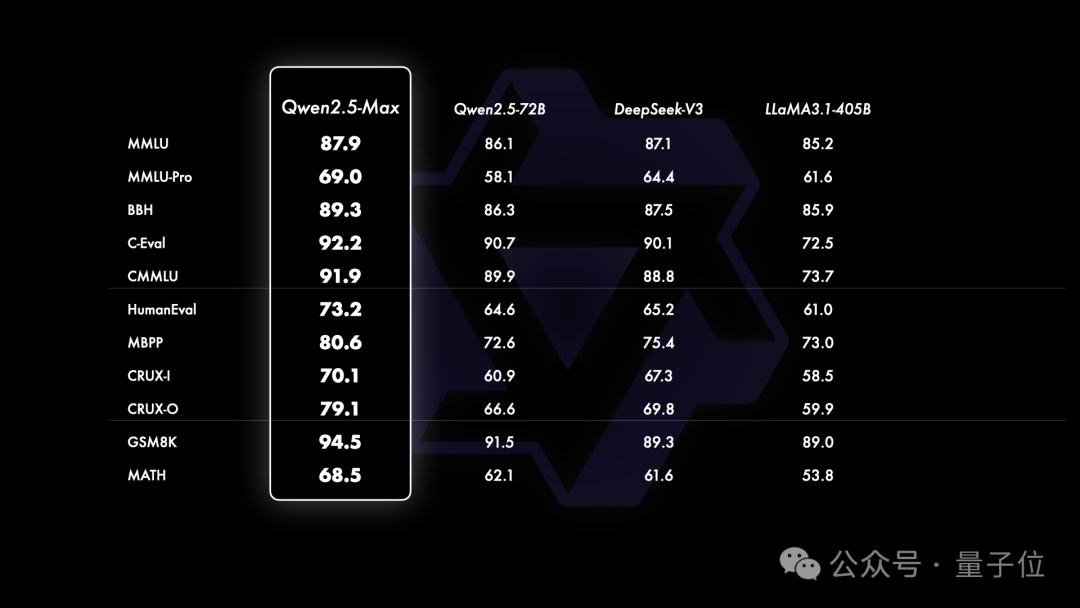
至于base model,Qwen2.5-Max在大多数基准测试中,也都展现出了显著的优势(闭源模型base model无法访问,只能比较开源模型)。
代码/推理突出,支持Artifacts
Qwen2.5-Max上线后,大量网友都来实测。
目前发现它在代码、推理等方面的表现突出。
比如让它用JavaScript写一个象棋游戏。
因为具备Artifacts功能,一句话开发的小游戏,可立刻开玩:
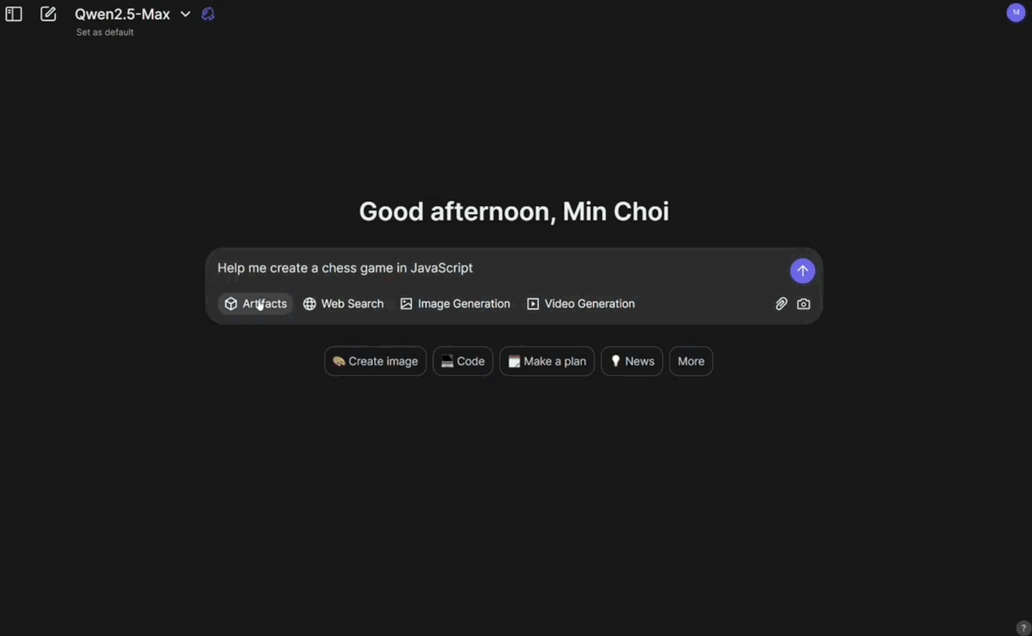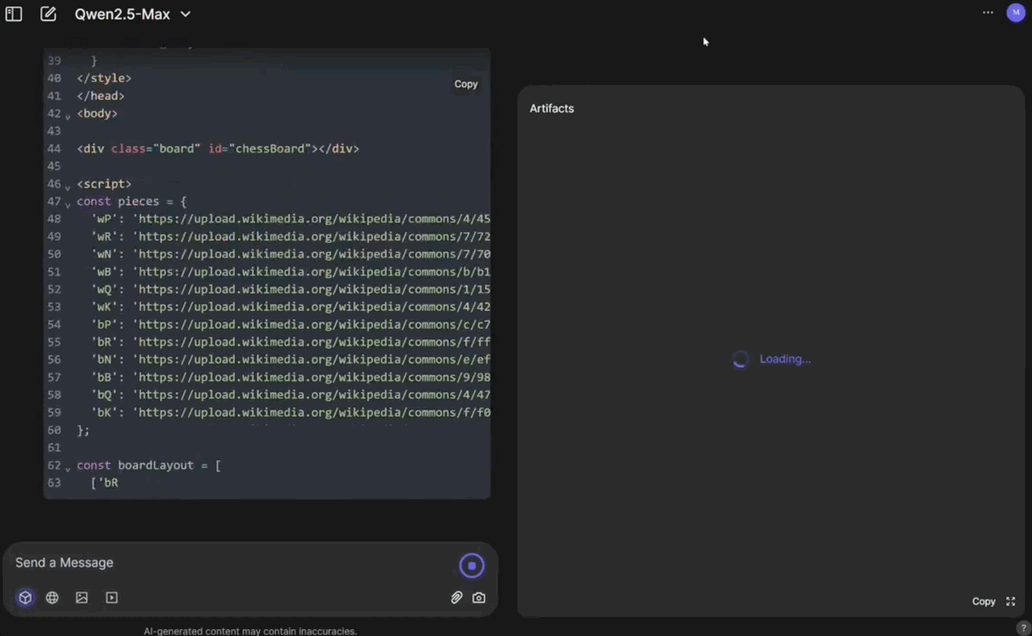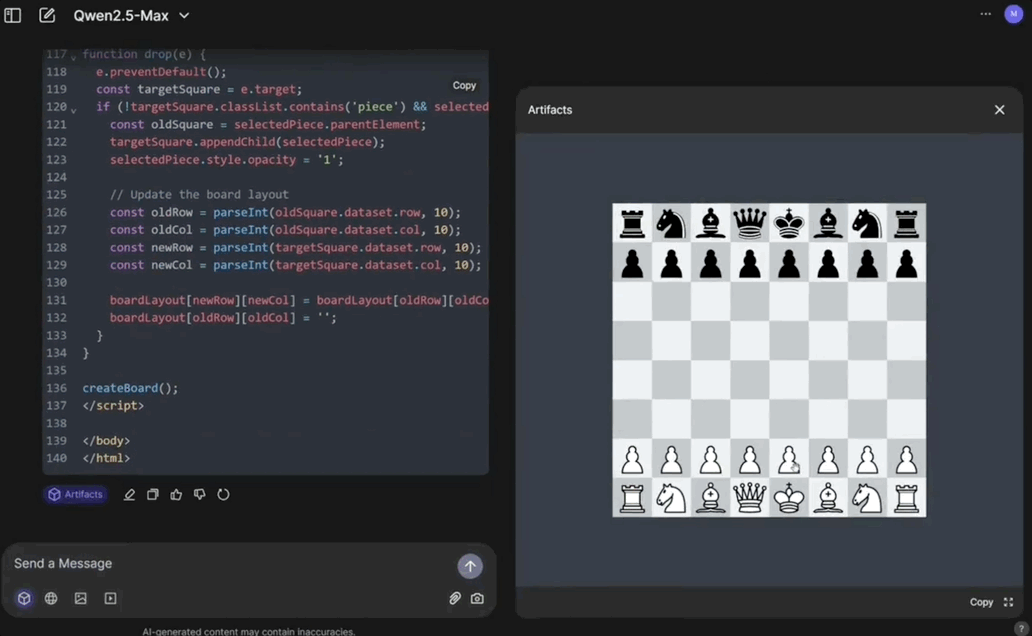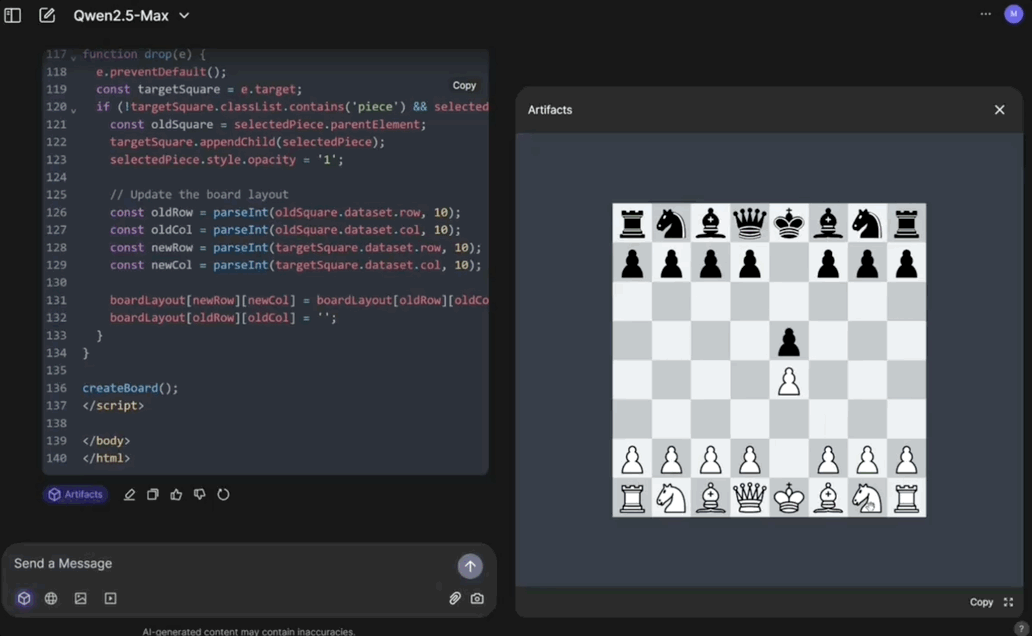
它生成的代码往往更简单易读好用。
复杂提示词的推理问题上,Qwen2.5-Max快速又准确:
您的团队处理客户请求共有3步:
数据收集(阶段A):每个请求需要5分钟。
处理(阶段B):每个请求需要10分钟。
验证(阶段C):每个请求花费8分钟。团队当前按顺序操作,但您正在考虑并行工作流。如果每个阶段分配两个人,并允许并行工作流程,则每小时的产出将增加20%。然而,添加并行工作流在操作开销上要多花费15%。考虑到时间和成本,你是否应该使用并行工作流程来优化效率?
Qwen2.5-Max不到30秒就可以完成全部推理,将整体过程清晰分为5步:当前工作流分析、并行工作流分析、成本含义、成本效率权衡、结论。
最终很快得出结论:应该使用并行工作流程。
与同为非推理模型的DeepSeek-V3相比,Qwen2.5-Max的回答更简洁迅速。
亦或是让它生成一个由ASCII数字组成的旋转球体,离视角最近的数字是纯白的,最远的逐渐变成灰色,背景是黑色。
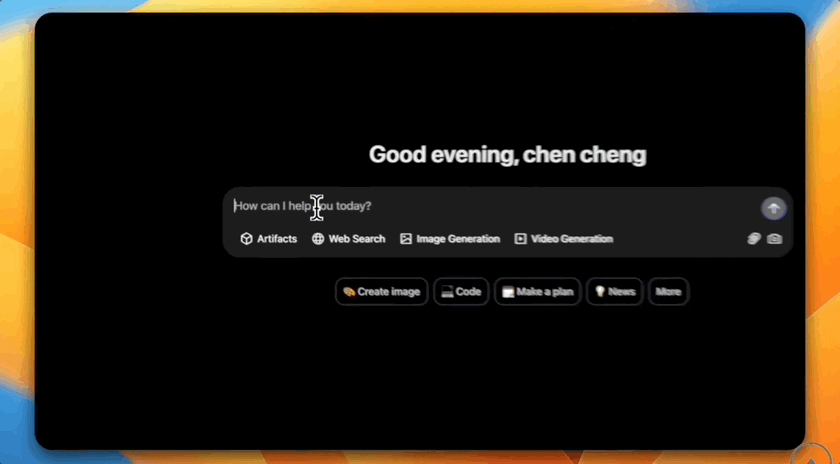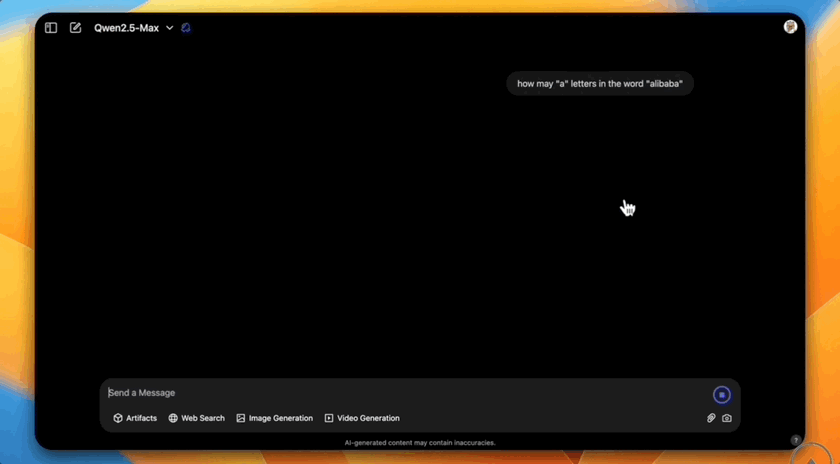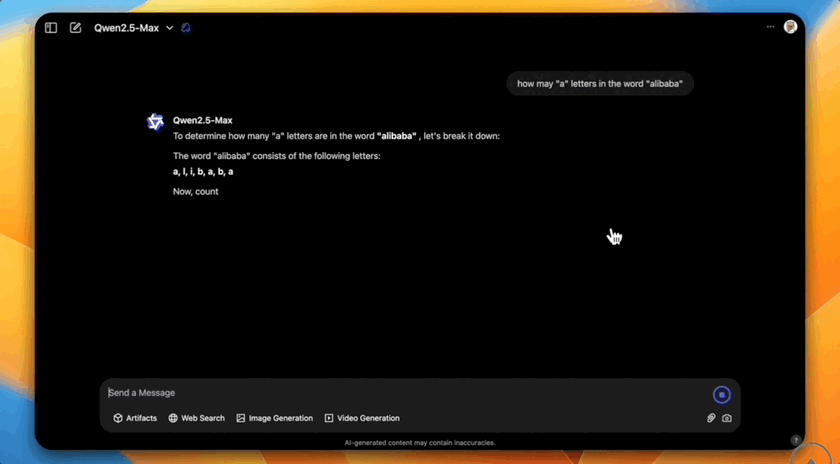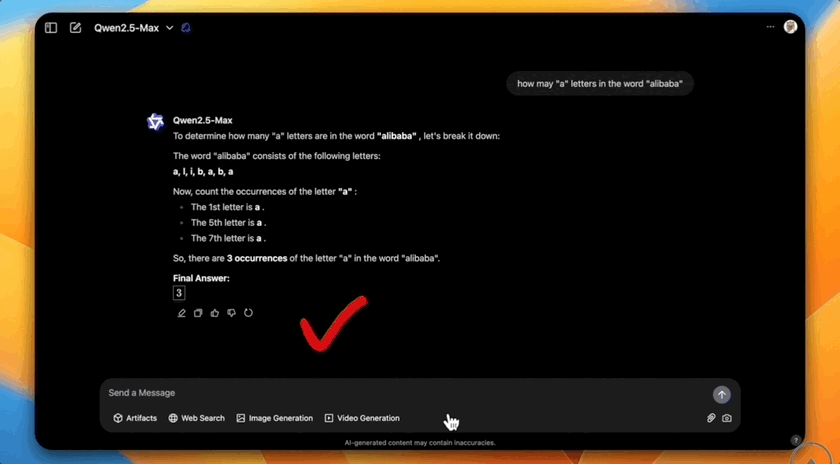
数单词中特定字母的数量更是不在话下。
如果你也想上手实测,Qwen2.5-Max已在Qwen Chat平台上线,可免费体验。
企业用户可以在阿里云百炼调用Qwen2.5-Max模型的API。
感兴趣的同学,速来尝鲜吧~


















 5
5

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









