






RaML团队 投稿
量子位 | 公众号 QbitAI
近年来,大语言模型(LLM)以其卓越的文本生成和逻辑推理能力,深刻改变了我们与技术的互动方式。然而,这些令人瞩目的表现背后,LLM的内部机制却像一个神秘的“黑箱”,让人难以捉摸其决策过程。
上海AI Lab的研究团队的近期提出Reasoning as Meta-Learning(RaML),尝试从梯度下降和元学习(Meta-Learning)的角度,揭示了LLM如何“思考”,并为优化其性能提供了新思路。

RaML的核心洞察:推理即“梯度下降”
RaML框架的核心在于一个直观的类比:LLM在解决问题时生成的“推理轨迹”(即一步步推导的过程),就像模型参数在优化过程中的“伪梯度下降”更新。
这意味着,当LLM进行多步推理时,其内部状态(即模型参数)会像典型的参数优化过程一样,逐步地“调整”和“适应”,每一步都朝着更优的解决方案逼近,直到得出最终的答案 。
研究团队通过理论推导发现,在Transformer模型中,每个推理轨迹的令牌都可以看作对参数的一次“隐式更新”。考虑典型的transformer块的计算过程,当输入中增加一个推理轨迹令牌时,transformer块的输出可以表示为:
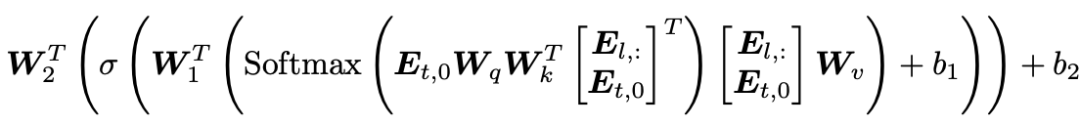
经过推导,可以发现增加的令牌能够内化为对模型参数的更新,即: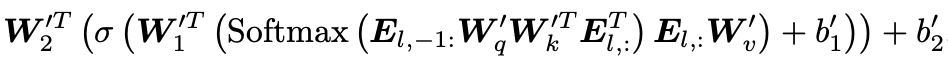
将这一发现推广到整个推理轨迹上,每个令牌都可被视为一个参数更新步,最终使得模型的内部状态逐步“收敛”到最佳状态,最终输出正确答案
为了更好地理解并佐证这一观点,研究团队进行了实证验证。
以QwQ-32B模型在AIME24数据集上的推理为例,团队利用大模型关于正确答案的置信度作为探针,衡量其参数的收敛程度。
结果如下图所示,随着推理轨迹的解码,模型关于正确答案的置信度在逐步上升,有力地证明了推理轨迹作为参数更新的合理性 。
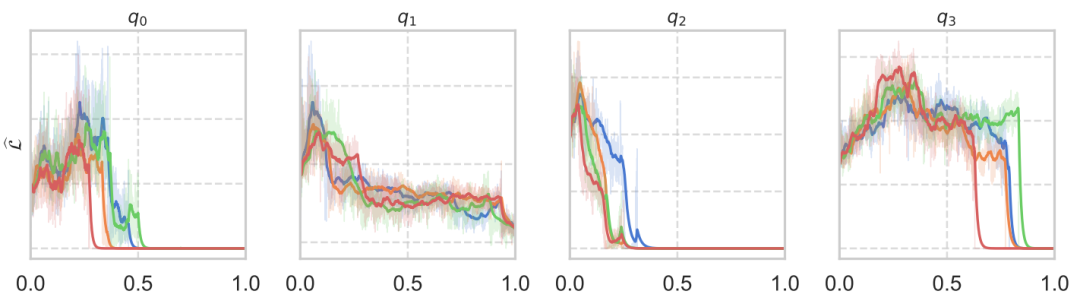
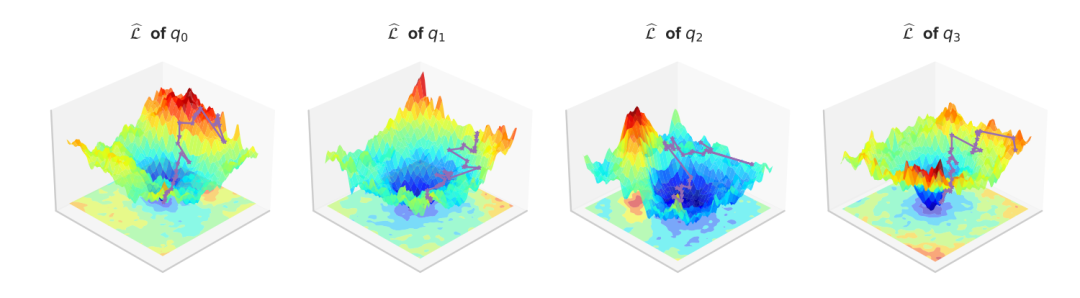
元学习框架下的LLM推理训练:LLM的“学习如何推理”
研究团队进一步将LLM的推理任务训练过程置于一个元学习框架下进行解释 。这提供了一个更宏观的视角来理解LLM如何学习解决复杂推理问题,以及其强大的泛化能力从何而来。
在这个框架下,每一个具体的问题,例如一道数学题或一个逻辑推理问答,都被清晰地定义为一个独立的“任务” 。
关键在于,大模型在解决这个任务时所经历的推理轨迹,被赋予了“内循环优化”的角色 。
这意味着模型在处理当前问题时,会通过生成推理轨迹来动态地调整其内部参数,以更好地适应和解决这个特定任务。同时,在“外循环优化”中:大模型基于经过内循环(推理轨迹)优化后的参数,优化关于正确答案的置信度 。
RaML将LLM的训练过程解构为两个层次:针对特定任务的“即时学习”(内循环,即推理轨迹)和从多个任务中学习“学习策略”的“元学习”(外循环)。这解释了为什么LLM能够举一反三,在面对新问题时快速适应。内循环是模型在“思考”过程中进行微调,而外循环则是模型在“思考”结束后,根据结果反思并调整其“思考”能力本身。这种双循环机制是LLM实现强大泛化能力的关键。
RaML框架提供了一个统一的解释框架,来理解LLM在不同训练策略、推理策略和任务泛化能力上的表现。
有监督微调(SFT)与强化学习(RL)的对比
研究团队首先对比了社区中先进的有监督微调(SFT)模型和强化学习(RL)模型在数学基准上的性能,发现基于SFT的蒸馏模型相比于单纯的RL模型具有较明显的优势 ,如何解释这种差异呢?
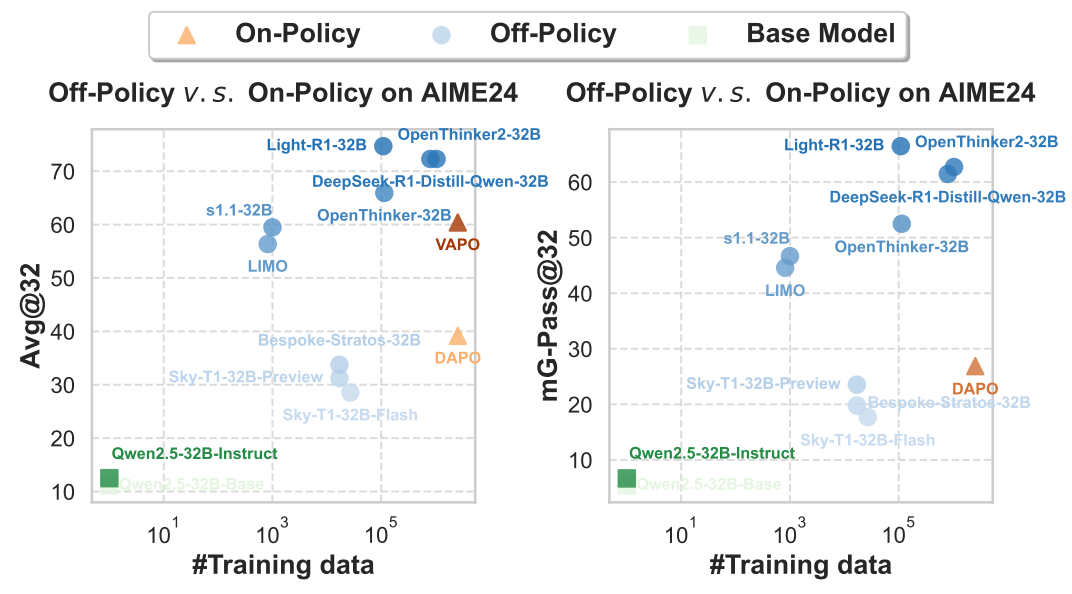
在RaML的定义下,对大模型进行推理任务训练时用到的推理轨迹与元学习中的内循环优化路径等价。内循环优化的结果对于模型的训练至关重要。
由于推理轨迹是大模型通过自回归解码生成的,大模型作为一个元优化器需要学习如何针对不同问题进行内部优化。根据元学习的相关研究,元优化器的学习是非常困难的 。SFT相当于从一个“训练好的优化器”(如人类标注或是更强的模型)获取指导,来帮助模型自身快速收敛。与之相比,RL依赖于模型自身的探索,如果模型自身能力有限,则需要更多的数据和训练步骤才能收敛 。
因此,对于规模相对较小的模型,SFT的收益更大,因为它提供了“正确答案的路径”,相当于给模型一个“最优梯度”的指导,能够迅速提升其“学习如何思考”的能力。但对于规模更大的强推理模型,RL的理论上限更高,因为它能探索更广阔的解空间。
另一方面,对于较弱的基座模型,也可以通过有监督微调先帮助其确定优化方向,稳定内循环优化,再进行强化学习提升性能,如下图实验结果所示。

推理轨迹对于推理性能的影响
由于推理轨迹对应于内循环优化,每个令牌对应一个优化步,因此更长的推理轨迹通常意味着更好的内循环优化效果,从而带来更好的训练效果和推理性能。这一发现与近期社区的研究进展高度一致 。这与传统优化算法中的迭代次数类似,更多的迭代通常意味着更精细的优化和更接近全局最优解。
“反思”令牌的作用
目前社区普遍认为长推理模型在推理轨迹过程中存在“反思”模式,一些特设的“反思”令牌代表了模型对自身推理结果的审视与验证 。RaML从优化角度分析了这些令牌的特殊之处:团队统计了一些典型的“反思”令牌对于大模型输出正确答案的置信度的影响,实验结果发现这些令牌会引起模型置信度的显著变化,这意味着这些令牌有助于模型跳出鞍点区域,从而提升推理性能 。
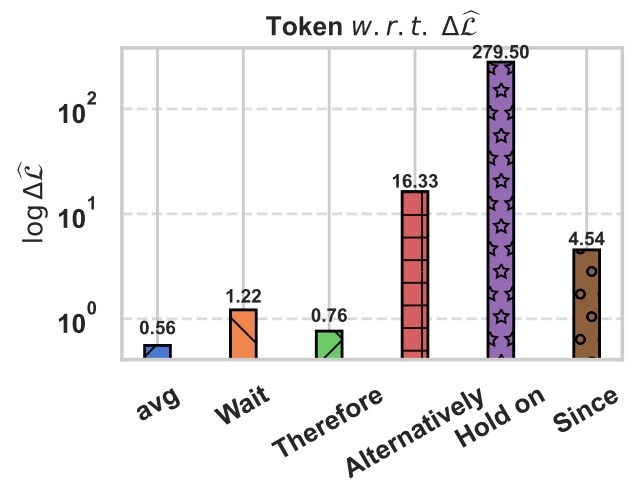
从优化角度看,“反思”可以理解为一种“重启动”或“跳出局部最优”的机制。当模型在推理过程中陷入某种“思维定势”或“局部最优解”时,反思令牌能够促使其重新审视问题,调整内部状态,从而找到更好的优化路径,就像优化算法中的“动量”或“退火”策略,能够有效提升优化效率和质量。
“非思考模式”与“思考模式”的对比
其次,社区中关于思考模式与非思考模式的切换的研究也收到极大的关注,一些工作使用特殊的令牌序列结束思考过程,以节省解码开销。团队针对这些非思考模式序列进行了分析,发现这样的令牌序列(或类似于‘Therefore, after all thinking, the answer is’之类的budget forcing令牌序列)会使得大模型快速地达到一个相对稳定的收敛态,以准备好输出答案,但这种状态有可能是鞍点,因此造成非思考模式相比于思考模式的性能差距。
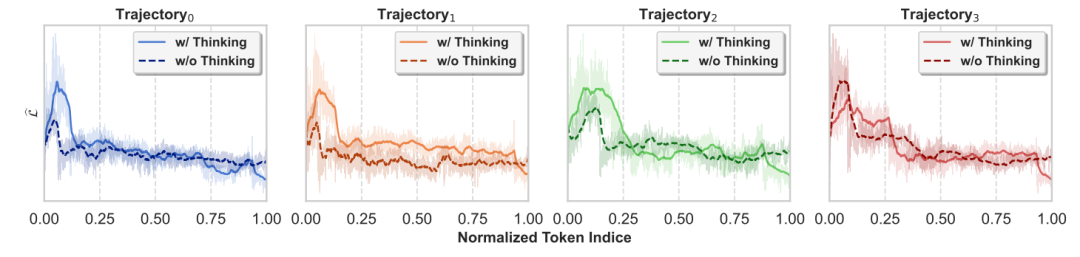
目前的方法过早或强制结束“思考”过程,虽然节省了计算资源,但可能导致模型未能充分探索解空间,从而停留在次优解。这就像梯度下降过早停止,未能达到真正的最优解。
推理任务泛化性
元学习的核心优势之一是通过在少量任务实例上的训练达到在未见过的任务上的泛化性 ,那么在大模型推理的训练中是否也存在这种泛化性呢?
团队在数学推理上通过有监督蒸馏和强化学习分别训练了大模型,接着在科学推理和代码推理任务上进行了评测,实验结果可以发现仅在数学推理上进行训练,同样可以提升其他推理任务的表现。
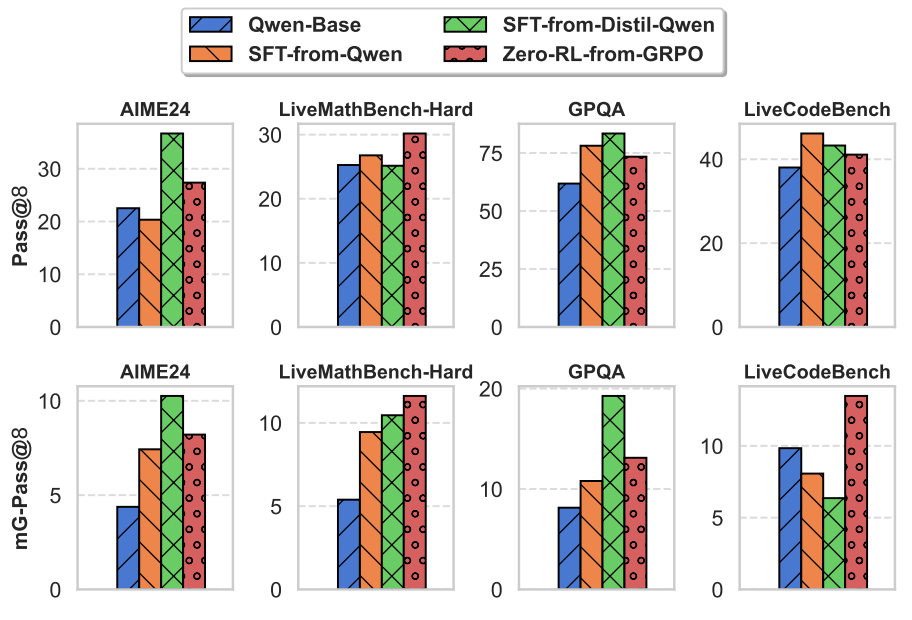
这表明大模型在类似元学习的训练过程中,从不同的“任务”(问题)中学习到了所有推理任务共同的普适特征。当遇到新问题时,大模型能够基于这些普适特征生成推理轨迹,进而“内循环”优化自身参数以快速适应新问题,最终输出答案 。这是元学习的“学习如何学习”的核心优势。LLM在大量任务上进行内循环优化后,其“元优化器”能力得到提升,能够识别不同任务中共同的底层推理逻辑。这使得模型在面对全新的、未曾见过的推理任务时,也能通过其习得的“优化策略”快速构建有效的推理轨迹,从而实现强大的零样本或少样本泛化能力。
RaML的启示:元学习能带来什么?
RaML框架的价值不仅停留在分析与解释层面,更直接提供了具有实践指导意义的优化策略。团队进行了两个简单的尝试,以验证从元学习研究中获得启发的可行性。
提升每个问题的训练轨迹数量
在RaML的场景中,每个问题的训练轨迹数量直接对应于元学习中的“支撑集”大小 。元学习领域的已有研究明确指出,增加支撑集的大小有助于提升内循环的优化效果,从而显著提升整体训练表现 。
团队在有监督蒸馏和强化学习两种训练方式中验证提升增加每个问题训练轨迹数量的效果,发现在不同训练范式增加单一问题的训练轨迹数量都有助于提升推理表现。
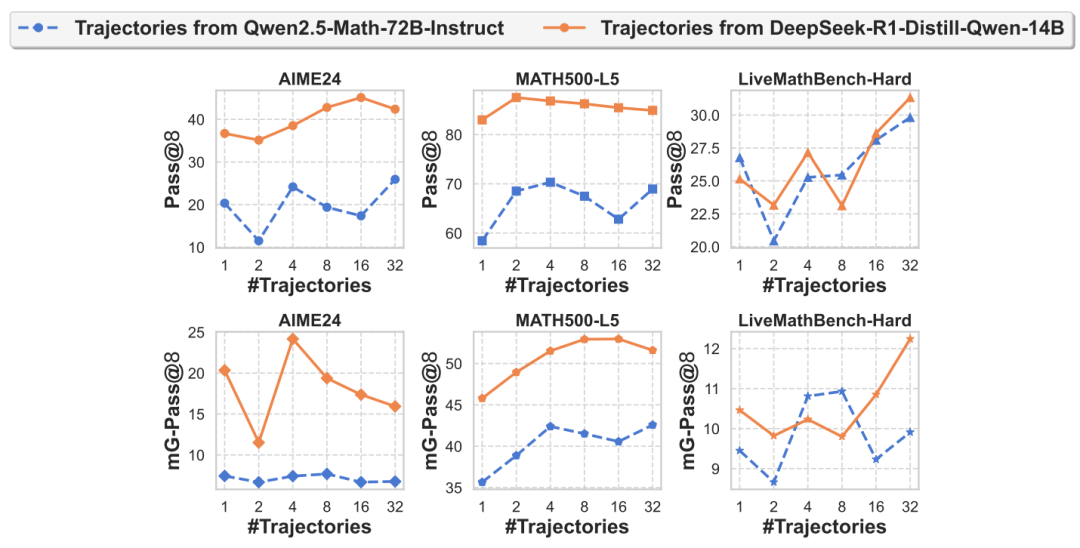
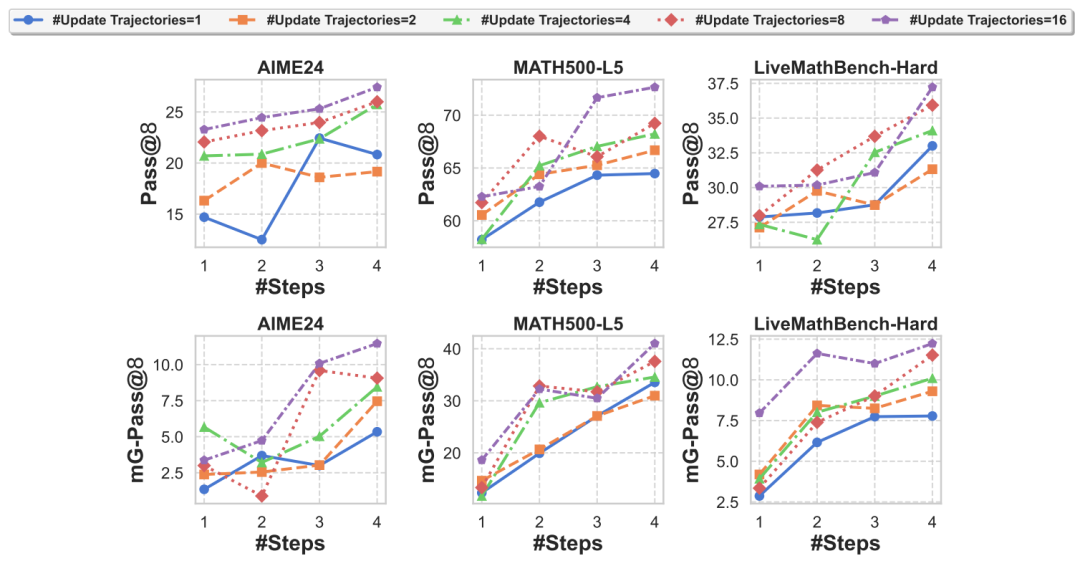
从优化的角度提升大模型思考效率
当前大模型推理通过长推理轨迹链实现了性能上的极大提升,然而也带来了显著的解码开销增加,这在实际应用中是一个重要瓶颈 。核心问题在于:既然推理轨迹本质上代表了一条优化轨迹,那么是否存在一种方法,能够找到等价的、更短的优化轨迹,在起到类似优化效果的同时,大幅降低解码开销?
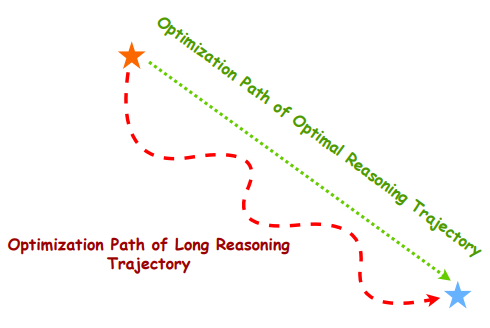
团队提出了一种简单的启发式方法:对已有的长推理轨迹进行摘要,提炼总结其最重要的部分,然后令大模型基于这个摘要后的短推理轨迹直接输出答案 。
实验结果令人鼓舞:即使是这种相对简单的方法,也能取得与原始长推理轨迹可比较的推理结果,并且极大地降低了解码开销 。这是一种“知识蒸馏”或“效率优化”的思路。如果推理轨迹是优化路径,那么其中可能存在冗余或效率不高的步骤。通过摘要,可以提炼出最关键的“优化信号”,从而在不损失核心性能的前提下,大幅减少计算量。
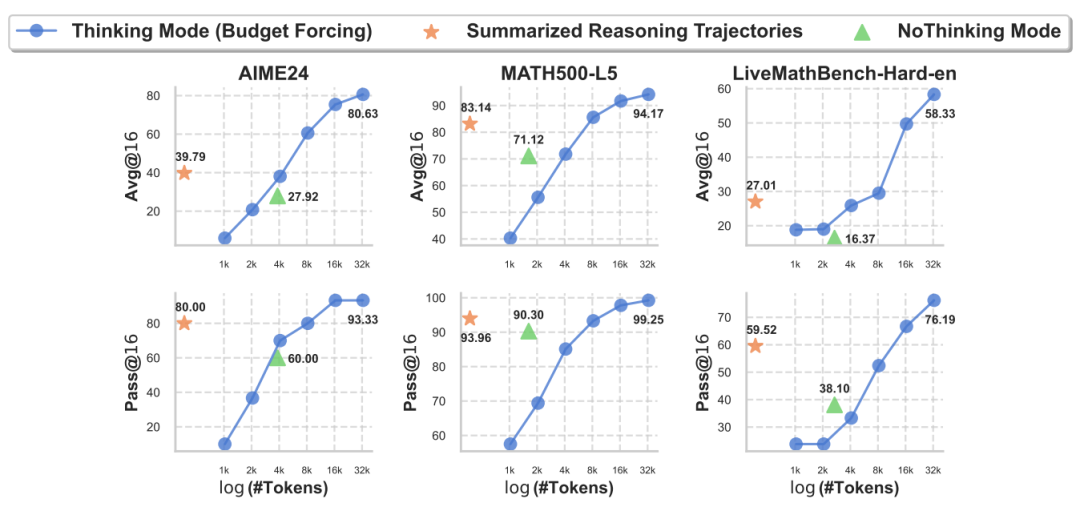
这一初步尝试意味着,未来可以通过某种更有效的方法,从长推理轨迹中提取出更高效的短推理轨迹,从而在后训练阶段降低长推理模型的解码开销。更有效的提取方法将是未来研究的重要方向 。
基于上述讨论,还有更多的研究问题可以探索,例如:大模型如何学习到推理轨迹到优化轨迹的映射?这种映射与令牌的语义有何种关联;不同推理任务的配比是否会对大模型推理能力的泛化有影响,有何种影响;训练轨迹对推理训练的影响,例如参考元学习中的support set采样策略等;如何进一步从Meta Learning的角度,指导对模型推理能力的提升。
总结
研究团队提出的RaML框架,为理解和思考大模型推理与训练提供了一种全新的视角 。通过严谨的实证分析,该研究讨论并揭示了大模型推理与元学习和梯度下降之间的紧密关联。更重要的是,RaML为大模型推理的未来发展提供了一些有价值的启发。
论文:https://arxiv.org/abs/2505.19815
代码:https://github.com/open-compass/RaML
— 完 —
📪 量子位AI主题策划正在征集中!欢迎参与专题365行AI落地方案,一千零一个AI应用,或与我们分享你在寻找的AI产品,或发现的AI新动向。
💬 也欢迎你加入量子位每日AI交流群,一起来畅聊AI吧~



















 17
17

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









