






一、爬虫概念
1.概念
网络爬虫也叫网络蛛,特指一类自动批量下载网络资源的程序,这是一个比较口语化的定义。
更加专业和全面对的定义是:网络爬虫是伪装成客户端与服务端进行数据交互的程序。
2.作用
a.数据采集
b.搜索引擎
c.模拟操作
3.爬虫开发的重难点
a.数据的获取
b.采集的速度
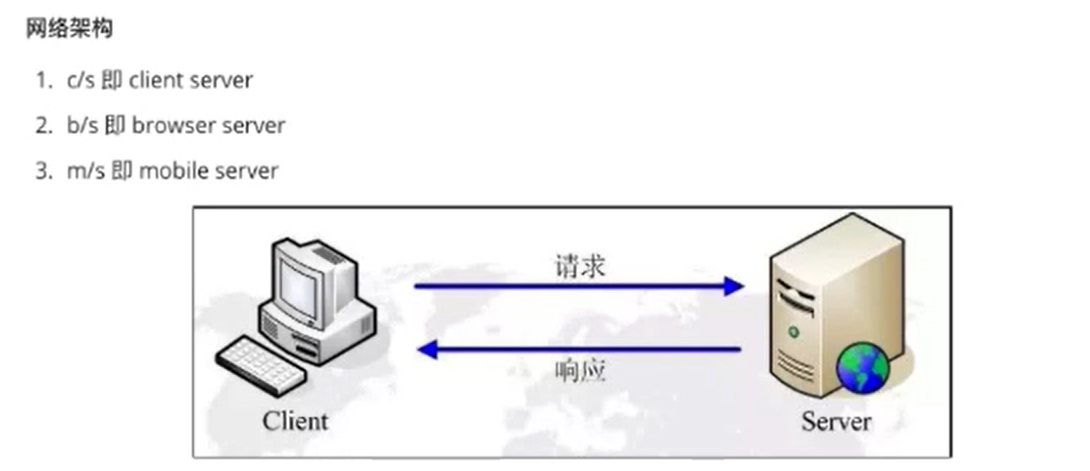
二、网络架构
三、Proxy代理
1.代理的概念
代理实际指代理服务器,它的功能是代替用户取获取网络信息,就像是一个网络信息的中转站。正常情况下请求一个网站时,我们发送请求给web服务器,然后web服务器把响应传回给我们;而如果设置了代理服务器,此时我们就不是直接给web服务器发送请求,而是先向代理服务器发送请求,然后代理服务器再把我们的请求转发给目标web服务器,接着web服务器把响应返回给代理服务器,之后代理服务器再把响应返回给我们。使用这样的访问方式,我们同样可以正常访问网页,但是中间经过了代理服务器后,web服务器就不能识别到我们本机的IP了,只能识别代理服务器的IP,这样我们本机的真实IP就被伪装起来了,这就是代理服务器的基本原理和作用。
2.代理的作用
代理具体有什么作用呢
突破自身IP访问限制:访问一些自身IP不能访问的站点。
访问一些单位或团体内部资源:比如使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度。
隐藏真实IP:上网者也可以通过这种方法隐藏自己的P,免受攻击。对于爬虫来说,我们用代理就是为了隐藏自身IP,防止自身的IP被封锁。
代理对于爬虫的作用
由于爬虫爬取速度过快,在爬取过程中可能遇到同一个IP访问过于频繁的问题,此时网站就会让我们输入验证码登录或者直接封锁IP,这样会给爬取带来极大的不便。便用代理隐真实的IP,让服务器误以为是代理服务器在请求自己。这样在爬取过程中通过不断更换代理,就不会被封锁,可以达到很好的爬取效果。
四、网页解析解析工具
xpath在Python的爬虫学习中,起着举足轻重的地位,对比正则表达式 re两者可以完成同样的工作,实现的功能也差不多,但xpath明显比re具有优势,在网页分析上使re退居二线。
xpath 全称为XML Path Language 一种小型的查询语言 xpath的优点:
可在XML中查找信息
支持HTML的查找
通过元素和属性进行导航
python开发使用XPath条件: 由于XPath属于lxml库模块,所以首先要安装库lxml。
from lxml import etree
selector=etree.HTML(源码) #将源码转化为能被XPath匹配的格式
selector.xpath(表达式) #返回为一列表
【1】路径表达式
表达式 描述 实例 解析
/ 从根节点选取 /body/div[1] 选取根结点下的body下的第一个div标签
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 //a 选取文档中所有的a标签
./ 当前节点再次进行xpath ./a 选取当前节点下的所有a标签
@ 选取属性 //@calss 选取所有的class属性五、爬虫实现基本流程
1.明确需求
明确采集的网站以及数据内容
网址 :https://www.dongchedi.com/sales
数据:汽车销量榜
2.抓包分析:通过浏览器开发者工具分析对应的数据来源
打开开发者工具 F12
刷新网页
通过关键字找到对应的数据包
3.代码实现步骤
a.发送请求 :模拟浏览器对url地址发送请求
导入数据请求模块(需要安装 pip install requests)
import requests模拟浏览器:请求标头中的参数内容
注意:需要构建完整的键值对(字典形式)
为什么不加cookie?
可以先只加UA,如果后续请求得不到数据的时候,再尝试加上其他的
#模拟浏览器
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0',
'Cookie': 'ttwid=1%7CtUrIcoWYq3Ve-MAoXYX2A8qYW39I2hYAiiWH-cHGw9U%7C1744881027%7Ccf247a1f8aa94effe868941ff9750386c00576c13a98f1f15ca6d467a71add4b; tt_webid=7494206870677521982; tt_web_version=new; is_dev=false; is_boe=false; Hm_lvt_3e79ab9e4da287b5752d8048743b95e6=1744881038; HMACCOUNT=611680547FF79A18; x-web-secsdk-uid=1bfb1735-19c6-4e1e-84a0-f12940130397; _gid=GA1.2.1300919104.1744881039; s_v_web_id=verify_m9l54ald_KC6HeCVq_kqv5_4QFj_8FQl_dBWKYCp2potk; city_name=%E9%9D%92%E5%B2%9B; Hm_lpvt_3e79ab9e4da287b5752d8048743b95e6=1744884828; _ga=GA1.1.1581644554.1744881039; _ga_YB3EWSDTGF=GS1.1.1744881038.1.1.1744885720.40.0.0',
'Referer': 'https://cn.bing.com/'
}请求网址:
#请求网址
url = 'https://www.dongchedi.com/sales'发送请求:
response=requests.get(url=url,headers=header)b.获取数据 :获取服务器返回的响应数据(整个网页数据)
搜索查询我们需要的数据是否存在(校验)
# 获取响应数据
html=response.text
print(html)c.解析数据 :把我们需要的车辆信息提取出来
导入数据解析模块(需要安装 pip intsall lxml)
from lxml import etree
selector=etree.HTML(源码) #将源码转化为能被XPath匹配的格式
selector.xpath(表达式) #返回为一列表根据路径表达式选择对应的元素
# 获取车辆信息所在列表
data = box.xpath('//ol[@class="tw-mt-12"]')4.保存数据 :保存本地文件


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









