






Ubuntu 20.04上搭建基于Kind的Kubernetes集群
基于你提供的信息和特定要求,这是一套详细的步骤用于在Ubuntu 20.04服务器上安装Docker,配置阿里云Docker源,安装kubectl,以及使用Kind创建一个Kubernetes集群。此教程假设你具备sudo权限,并且你的服务器连接互联网。
安装 Docker
-
使apt支持HTTPS传输:
sudo apt install apt-transport-https ca-certificates curl software-properties-common -y -
添加Docker官方GPG公钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - #使用阿里云 curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - -
将阿里云的Docker存储库添加到系统的APT源:
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu focal stable" echo "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu focal stable" >> /etc/apt/sources.list -
更新APT包列表:
sudo apt update -
安装 Docker CE:
sudo apt install -y docker-ce -
配置Docker使用阿里云镜像:
sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://nol6uuul.mirror.aliyuncs.com"] } EOF sudo systemctl daemon-reload sudo systemctl restart docker -
检查Docker运行状态:
systemctl status docker
安装 kubectl
-
安装必要的软件以支持HTTPS源:
sudo apt install apt-transport-https ca-certificates -y -
添加阿里云的Kubernetes源:
echo 'deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add - sudo apt update -
安装kubectl:
sudo apt-get install -y kubectl -
配置命令行自动补全(可选):
sudo apt install bash-completion -y echo 'source <(kubectl completion bash)' >>~/.bashrc echo 'alias k=kubectl' >>~/.bashrc echo 'complete -F __start_kubectl k' >>~/.bashrc source ~/.bashrc
安装 Kind
-
下载并安装 Kind:
根据你的操作系统架构选择合适的下载命令:# For AMD64 / x86_64 curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.20.0/kind-linux-amd64 chmod +x ./kind sudo mv ./kind /usr/local/bin/kind
使用 Kind 创建 Kubernetes 集群
-
创建集群配置文件 (
cluster.yaml):cd ~ vim cluster.yamlkind: Cluster apiVersion: kind.x-k8s.io/v1alpha4 nodes: - role: control-plane extraPortMappings: - containerPort: 31000 hostPort: 31000 protocol: tcp - role: worker - role: worker - role: worker #**注意: ** 因为 kind 搭建的集群也是容器, 我们要访问容器的服务, 我们需要把集群的 Service 暴露为 NodePort 类型进行访问, (NodePort 范围30000~32767) -
使用配置文件创建集群:
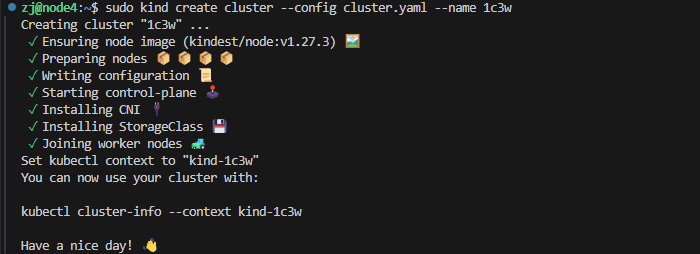
kind create cluster --config cluster.yaml --name 1c3w
补充1
可能会遇到当前用户没有权限访问Docker守护进程。这通常是因为当前用户不在Docker用户组内。你可以将当前用户添加到Docker组来解决这个问题,这样你就不需要每次使用Docker命令时都加上
sudo。执行以下命令将当前用户添加到Docker用户组:
sudo usermod -aG docker $USER完成后,你需要注销并重新登录,或者可以通过执行新的shell会话来刷新用户组设置:
newgrp docker添加用户到Docker组并重新登录后,再次尝试创建Kind集群。如果问题依然存在,请确保Docker服务正在运行:
sudo systemctl status docker如果Docker没有运行,可以使用以下命令启动它:
sudo systemctl start docker
补充2
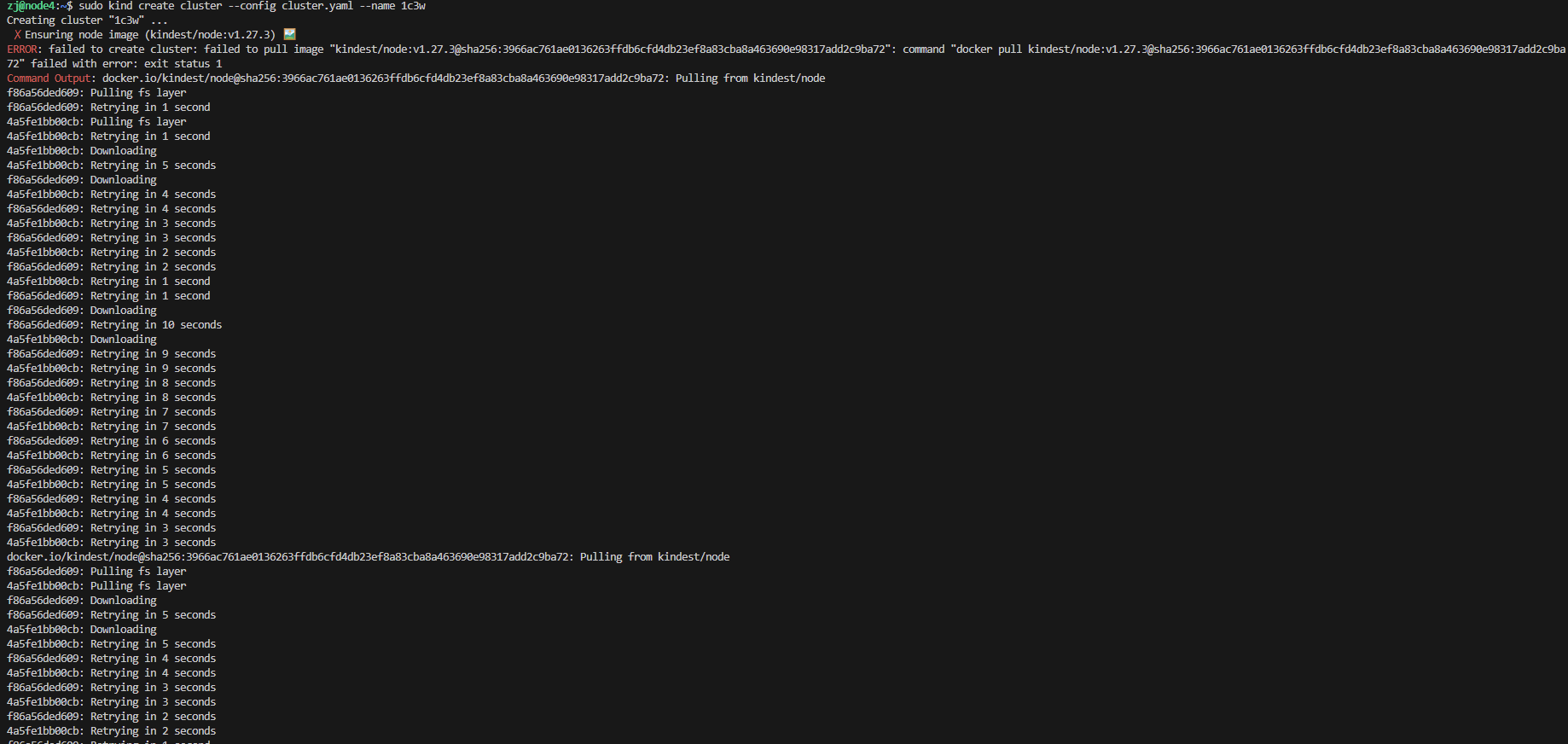
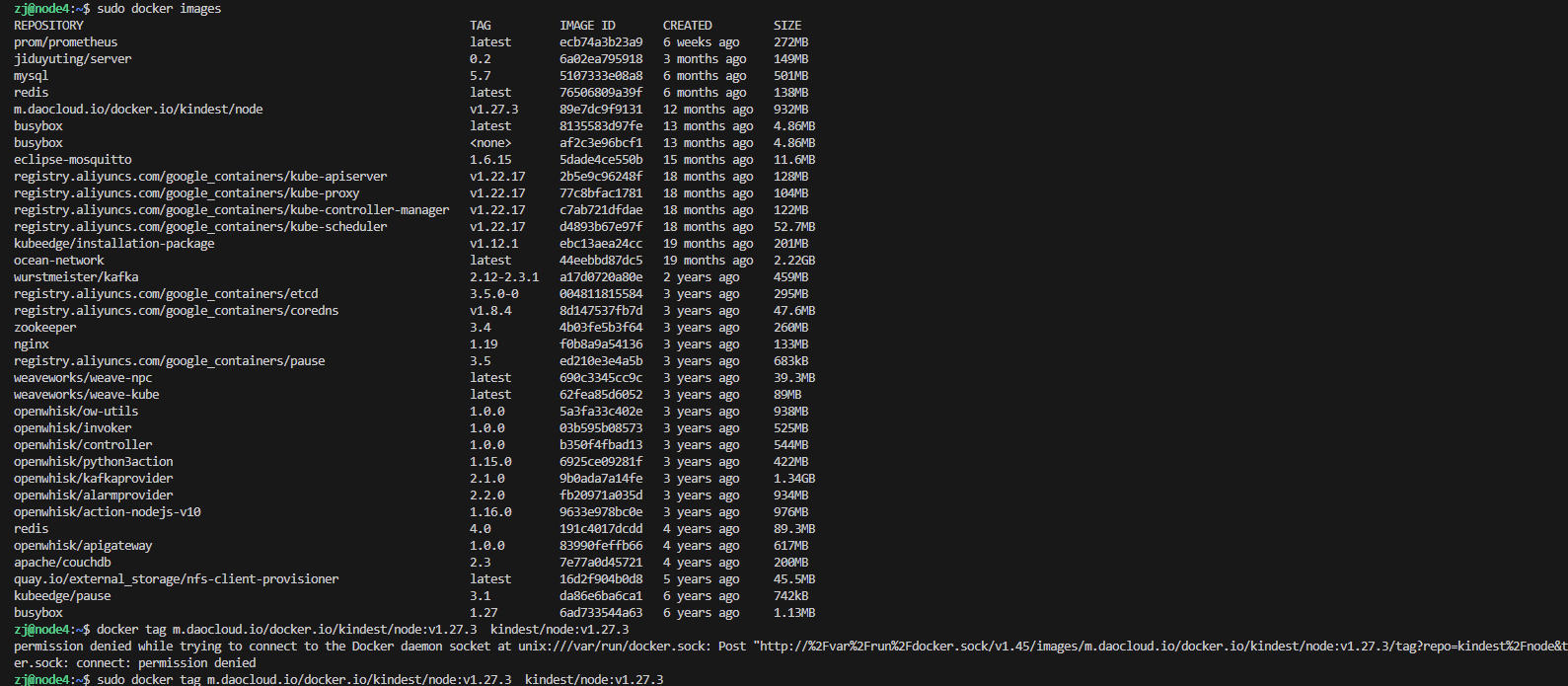
如果集群部署失败,就手动拉群镜像,参考文档

-
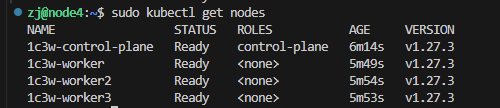
验证集群状态:
kubectl cluster-info --context kind-1c3w kubectl get nodes

按照上述步骤执行,你将在你的Ubuntu服务器上成功安装Docker和kubectl,并且使用Kind创建了一个Kubernetes集群。这样的配置非常适合开发和测试环境,以及学习Kubernetes的基本操作。
创建 service
# 创建一个 nginx 的 deploy 测试服务
$ kubectl create deploy nginx --image=nginx
# 冗余部署实现高可用
$ kubectl scale deployment nginx --replicas 3
# 暴露服务
$ kubectl expose deployment nginx --name nginx --port=80 --target-port=80 --type=NodePort
# 修改 NodePort 端口为 31000 让主机能够访问
$ kubectl edit svc nginx
......
ports:
- nodePort: 31000 # 修改
port: 80
protocol: TCP
targetPort: 80
....
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45m
nginx NodePort 10.96.56.39 <none> 80:31000/TCP 11m
验证服务
$ curl localhost:31000
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
也可在浏览器输入<虚拟机 ip>:31000















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









