







分类决策树算法-python实现
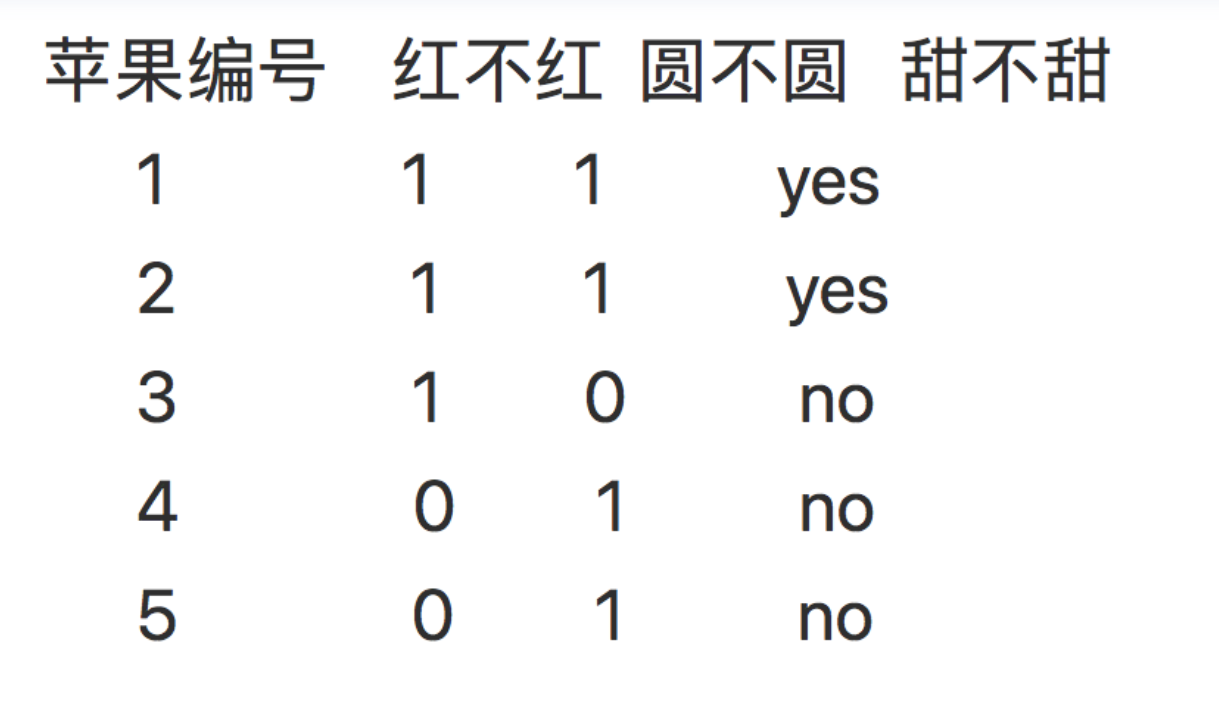
数据集
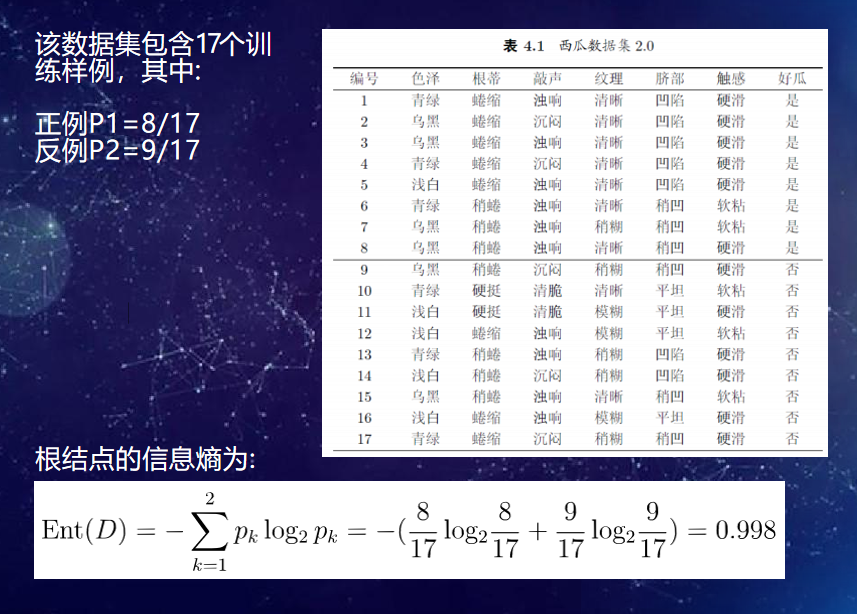
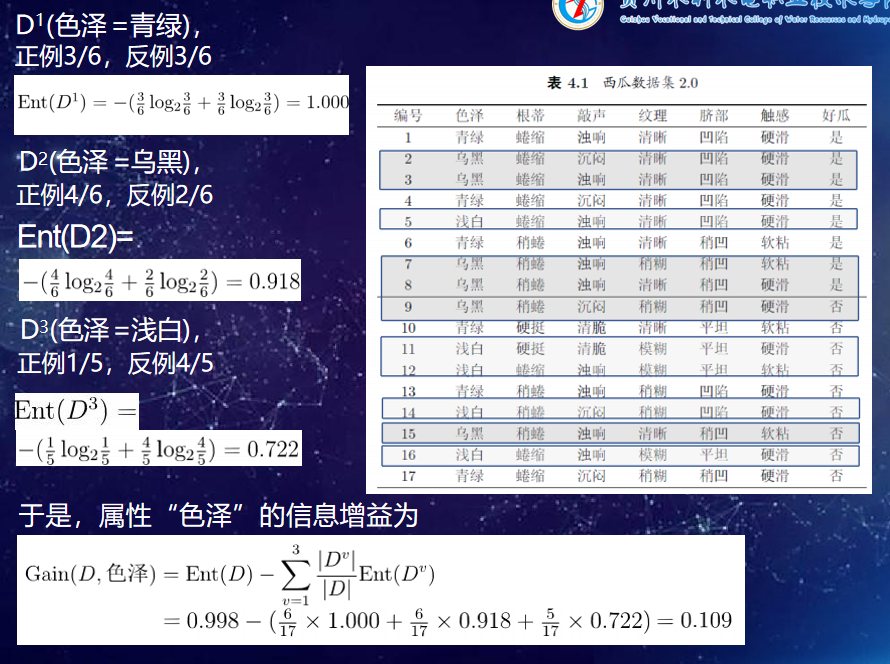
具体方法是:从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。
递归构建决策树的两种停止条件:
(1) 当前结点包含的样本全属于同一类别,无需划分;
(2) 当前属性集为空, 或是所当前结点包含的样本集合为空, 无需划分,取当前最多的哪个类别当叶子节点的分类即可;
具体实现代码:
import numpy as np
import math
from typing import Dict
from collections import Counter
import copy
class DeciseTreeNode:
def __init__(self, propety="", classify_result=None, labelIndex=-1):
# 属性
self.propety = propety
# 分类结果
self.classify_result = classify_result
# labels索引
self.labelIndex = labelIndex
# 属性分类 我们通过字典存储每个属性的类别(分支)
self.children: Dict[DeciseTreeNode] = {}
class DeciseTree:
def __init__(self):
# 决策树根节点
self.tree: DeciseTreeNode | None = None
# 决策树输入数据标签
self.labels = []
# 列表去重
def __filterRepeat(self, l: list):
res = []
for item in l:
if res.count(item) == 0:
res.append(item)
return res
# 计算香农熵
def calcShannonEnt(self, train_x: list[list], train_y: list):
value_dict, res, size = {}, 0, len(train_x)
for item in train_y:
if value_dict.get(item):
value_dict[item] += 1
else:
value_dict[item] = 1
for item in value_dict:
res -= ((value_dict[item] / size) * math.log2(value_dict[item] / size))
return res
# 计算信息增益
def calcMsgIncrease(self, train_x: list[list], train_y: list):
H = self.calcShannonEnt(train_x, train_y)
classify_values = self.__filterRepeat(train_y) # [yes no]
# 属性个数,分类个数
property_nums, classify_nums = len(train_x[0]), len(set(train_y)) # 2 2
max_msgIncrease_index, max_msgIncrease = 0, 0.0
for i in range(property_nums):
data = [item[i] for item in train_x] # [1,1,1,0,0]
set_data = self.__filterRepeat(data) # [1,0]
msgIncrease = 0.0
for feature_value in set_data: # 1
count = data.count(feature_value) # 1的次数
res = 0.0
for types in classify_values:
times = 0
for index, item in enumerate(data):
if item == feature_value and train_y[index] == types: times += 1
if times != 0:
res -= ((times / count) * math.log2(times / count))
msgIncrease += (count / len(data) * res)
# print(f"属性{labels[i]}的信息增益是{H - msgIncrease}")
if (H - msgIncrease) > max_msgIncrease:
max_msgIncrease = H - msgIncrease
max_msgIncrease_index = i
return max_msgIncrease_index
"""
函数说明:递归构建决策树
Parameters:
train_x - 训练数据集x
train_y - 训练数据集y
labels - 分类属性标签
Returns:
Tree: DeciseTreeNode - 决策树
"""
def createDeciseTree(self, train_x: list[list], train_y: list, labels: list):
if len(np.unique(train_y)) == 1:
return DeciseTreeNode("", train_y[0])
if len(train_x[0]) == 0 and len(train_y) != 0:
result, result_times = Counter(train_y).most_common(1)[0]
return DeciseTreeNode("", result)
feature_index = self.calcMsgIncrease(train_x, train_y)
label_index = self.labels.index(labels[feature_index])
feature_values = np.unique([item[feature_index] for item in train_x]) # [1,0]
node = DeciseTreeNode(labels[feature_index], labelIndex=label_index)
for f_v in feature_values:
sub_train_x, sub_train_y = [], []
for k_x, k_y in [(x, y) for x, y in zip(train_x, train_y) if x[feature_index] == f_v]:
sub_train_x.append([v for v_index, v in enumerate(k_x) if v_index != feature_index])
sub_train_y.append(k_y)
node.children[f_v] = self.createDeciseTree(sub_train_x, sub_train_y,
[item for item_index, item in enumerate(labels) if
item_index != feature_index])
return node
def fit(self, train_x: list[list], train_y: list, labels=[]):
xLen = len(train_x[0])
if len(labels) != xLen:
self.labels = [item for item in range(xLen)]
else:
self.labels = labels
labels = copy.deepcopy(self.labels)
self.tree = self.createDeciseTree(train_x,train_y,labels)
def getResult(self,tree: DeciseTreeNode,x: list):
if tree.classify_result is not None:
return tree.classify_result
return self.getResult(tree.children[x[tree.labelIndex]],x)
def predict(self,x: list):
if len(x)!=len(self.labels):
raise ValueError("输入数据列表长度不匹配!")
return self.getResult(self.tree,x)
#
# dataSet = [[1, 1, 'yes'], # 数据集
# [1, 1, 'yes'],
# [1, 0, 'no'],
# [0, 1, 'no'],
# [0, 1, 'no']]
# labels = ['红不红', '圆不圆']
# X = [item[:2] for item in dataSet]
# Y = [item[2] for item in dataSet]
dataSet = [[0, 0, 0, 0, 'no'], # 数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
X = [item[:4] for item in dataSet]
Y = [item[4] for item in dataSet]
model = DeciseTree()
model.fit(train_x=X,train_y=Y,labels=labels)
print(model.predict([2,0,0,0]))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









