







入门相关概念知识请看这篇 ElasticSearch6.x 入门
基础的增删改请看这篇 ElasticSearch6.x 基本操作
目录
准备工作
SmsLogs类
public class SmsLogs {
private String id;// 唯一ID 1
private Date createDate;// 创建时间
private Date sendDate; // 发送时间
private String longCode;// 发送的长号码
private String mobile;// 下发手机号
private String corpName;// 发送公司名称
private String smsContent; // 下发短信内容
private Integer state; // 短信下发状态 0 成功 1 失败
private Integer operatorId; // '运营商编号 1 移动 2 联通 3 电信
private String province;// 省份
private String ipAddr; //下发服务器IP地址
private Integer replyTotal; //短信状态报告返回时长(秒)
private Integer fee; // 费用
public SmsLogs() {
}
public SmsLogs(String id, Date createDate, Date sendDate, String longCode, String mobile, String corpName, String smsContent, Integer state, Integer operatorId, String province, String ipAddr, Integer replyTotal, Integer fee) {
this.id = id;
this.createDate = createDate;
this.sendDate = sendDate;
this.longCode = longCode;
this.mobile = mobile;
this.corpName = corpName;
this.smsContent = smsContent;
this.state = state;
this.operatorId = operatorId;
this.province = province;
this.ipAddr = ipAddr;
this.replyTotal = replyTotal;
this.fee = fee;
}
getter()... setter()...
}测试数据
public class TestData {
ObjectMapper mapper = new ObjectMapper();
RestHighLevelClient client = ESClient.getClient();
String index = "sms-logs-index";
String type = "sms-logs-type";
/**
* 创建索引
* @throws IOException
*/
@Test
public void createSmsLogsIndex() throws IOException {
//1. settings
Settings.Builder settings = Settings.builder()
.put("number_of_shards", 3)
.put("number_of_replicas", 1);
//2. mapping.
XContentBuilder mapping = JsonXContent.contentBuilder()
.startObject()
.startObject("properties")
.startObject("createDate")
.field("type", "date")
.endObject()
.startObject("sendDate")
.field("type", "date")
.endObject()
.startObject("longCode")
.field("type", "keyword")
.endObject()
.startObject("mobile")
.field("type", "keyword")
.endObject()
.startObject("corpName")
.field("type", "keyword")
.endObject()
.startObject("smsContent")
.field("type", "text")
.field("analyzer", "ik_max_word")
.endObject()
.startObject("state")
.field("type", "integer")
.endObject()
.startObject("operatorId")
.field("type", "integer")
.endObject()
.startObject("province")
.field("type", "keyword")
.endObject()
.startObject("ipAddr")
.field("type", "ip")
.endObject()
.startObject("replyTotal")
.field("type", "integer")
.endObject()
.startObject("fee")
.field("type", "long")
.endObject()
.endObject()
.endObject();
//3. 添加索引.
CreateIndexRequest request = new CreateIndexRequest(index);
request.settings(settings);
request.mapping(type, mapping);
client.indices().create(request, RequestOptions.DEFAULT);
System.out.println("OK!!");
}
/**
* 文档
* @throws IOException
*/
@Test
public void addTestData() throws IOException {
BulkRequest request = new BulkRequest();
SmsLogs smsLogs = new SmsLogs();
smsLogs.setMobile("13800000000");
smsLogs.setCorpName("途虎养车");
smsLogs.setCreateDate(new Date());
smsLogs.setSendDate(new Date());
smsLogs.setIpAddr("10.126.2.9");
smsLogs.setLongCode("10690000988");
smsLogs.setReplyTotal(10);
smsLogs.setState(0);
smsLogs.setSmsContent("【途虎养车】亲爱的张三先生/女士,您在途虎购买的货品(单号TH123456)已 到指定安装店多日," + "现需与您确认订单的安装情况,请点击链接按实际情况选择(此链接有效期为72H)。您也可以登录途 虎APP进入" + "“我的-待安装订单”进行预约安装。若您在服务过程中有任何疑问,请致电400-111-8868向途虎咨 询。");
smsLogs.setProvince("北京");
smsLogs.setOperatorId(1);
smsLogs.setFee(3);
request.add(new IndexRequest(index, type, "21").source(mapper.writeValueAsString(smsLogs), XContentType.JSON));
smsLogs.setMobile("13700000001");
smsLogs.setProvince("上海");
smsLogs.setSmsContent("【途虎养车】亲爱的刘红先生/女士,您在途虎购买的货品(单号TH1234526)已 到指定安装店多日," + "现需与您确认订单的安装情况,请点击链接按实际情况选择(此链接有效期为72H)。您也可以登录途 虎APP进入" + "“我的-待安装订单”进行预约安装。若您在服务过程中有任何疑问,请致电400-111-8868向途虎咨 询。");
request.add(new IndexRequest(index, type, "22").source(mapper.writeValueAsString(smsLogs), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs1 = new SmsLogs();
smsLogs1.setMobile("13100000000");
smsLogs1.setCorpName("盒马鲜生");
smsLogs1.setCreateDate(new Date());
smsLogs1.setSendDate(new Date());
smsLogs1.setIpAddr("10.126.2.9");
smsLogs1.setLongCode("10660000988");
smsLogs1.setReplyTotal(15);
smsLogs1.setState(0);
smsLogs1.setSmsContent("【盒马】您尾号12345678的订单已开始配送,请在您指定的时间收货不要走开 哦~配送员:" + "刘三,电话:13800000000");
smsLogs1.setProvince("北京");
smsLogs1.setOperatorId(2);
smsLogs1.setFee(5);
request.add(new IndexRequest(index, type, "23").source(mapper.writeValueAsString(smsLogs1), XContentType.JSON));
smsLogs1.setMobile("18600000001");
smsLogs1.setProvince("上海");
smsLogs1.setSmsContent("【盒马】您尾号7775678的订单已开始配送,请在您指定的时间收货不要走开 哦~配送员:" + "王五,电话:13800000001");
request.add(new IndexRequest(index, type, "24").source(mapper.writeValueAsString(smsLogs1), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs2 = new SmsLogs();
smsLogs2.setMobile("15300000000");
smsLogs2.setCorpName("滴滴打车");
smsLogs2.setCreateDate(new Date());
smsLogs2.setSendDate(new Date());
smsLogs2.setIpAddr("10.126.2.8");
smsLogs2.setLongCode("10660000988");
smsLogs2.setReplyTotal(50);
smsLogs2.setState(1);
smsLogs2.setSmsContent("【滴滴单车平台】专属限时福利!青桔/小蓝月卡立享5折,特惠畅骑30天。" + "戳 https://xxxxxx退订TD");
smsLogs2.setProvince("上海");
smsLogs2.setOperatorId(3);
smsLogs2.setFee(7);
request.add(new IndexRequest(index, type, "25").source(mapper.writeValueAsString(smsLogs2), XContentType.JSON));
smsLogs2.setMobile("18000000001");
smsLogs2.setProvince("武汉");
smsLogs2.setSmsContent("【滴滴单车平台】专属限时福利!青桔/小蓝月卡立享5折,特惠畅骑30天。" + "戳 https://xxxxxx退订TD");
request.add(new IndexRequest(index, type, "26").source(mapper.writeValueAsString(smsLogs2), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs3 = new SmsLogs();
smsLogs3.setMobile("13900000000");
smsLogs3.setCorpName("招商银行");
smsLogs3.setCreateDate(new Date());
smsLogs3.setSendDate(new Date());
smsLogs3.setIpAddr("10.126.2.8");
smsLogs3.setLongCode("10690000988");
smsLogs3.setReplyTotal(50);
smsLogs3.setState(0);
smsLogs3.setSmsContent("【招商银行】尊贵的李四先生,恭喜您获得华为P30 Pro抽奖资格,还可领100 元打" + "车红包,仅限1天");
smsLogs3.setProvince("上海");
smsLogs3.setOperatorId(1);
smsLogs3.setFee(8);
request.add(new IndexRequest(index, type, "27").source(mapper.writeValueAsString(smsLogs3), XContentType.JSON));
smsLogs3.setMobile("13990000001");
smsLogs3.setProvince("武汉");
smsLogs3.setSmsContent("【招商银行】尊贵的李四先生,恭喜您获得华为P30 Pro抽奖资格,还可领100 元打" + "车红包,仅限1天");
request.add(new IndexRequest(index, type, "28").source(mapper.writeValueAsString(smsLogs3), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs4 = new SmsLogs();
smsLogs4.setMobile("13700000000");
smsLogs4.setCorpName("中国平安保险有限公司");
smsLogs4.setCreateDate(new Date());
smsLogs4.setSendDate(new Date());
smsLogs4.setIpAddr("10.126.2.8");
smsLogs4.setLongCode("10690000998");
smsLogs4.setReplyTotal(18);
smsLogs4.setState(0);
smsLogs4.setSmsContent("【中国平安】奋斗的时代,更需要健康的身体。中国平安为您提供多重健康保 障,在奋斗之路上为您保驾护航。退订请回复TD");
smsLogs4.setProvince("武汉");
smsLogs4.setOperatorId(1);
smsLogs4.setFee(5);
request.add(new IndexRequest(index, type, "29").source(mapper.writeValueAsString(smsLogs4), XContentType.JSON));
smsLogs4.setMobile("13990000002");
smsLogs4.setProvince("武汉");
smsLogs4.setSmsContent("【招商银行】尊贵的王五先生,恭喜您获得iphone 56抽奖资格,还可领5 元打" + "车红包,仅限100天");
request.add(new IndexRequest(index, type, "30").source(mapper.writeValueAsString(smsLogs4), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
SmsLogs smsLogs5 = new SmsLogs();
smsLogs5.setMobile("13600000000");
smsLogs5.setCorpName("中国移动");
smsLogs5.setCreateDate(new Date());
smsLogs5.setSendDate(new Date());
smsLogs5.setIpAddr("10.126.2.8");
smsLogs5.setLongCode("10650000998");
smsLogs5.setReplyTotal(60);
smsLogs5.setState(0);
smsLogs5.setSmsContent("【北京移动】尊敬的客户137****0000,5月话费账单已送达您的139邮箱," + "点击查看账单详情 http://y.10086.cn/; " + " 回Q关闭通知,关注“中国移动139邮箱”微信随时查账单【中国移动 139邮箱】");
smsLogs5.setProvince("武汉");
smsLogs5.setOperatorId(1);
smsLogs5.setFee(4);
request.add(new IndexRequest(index, type, "31").source(mapper.writeValueAsString(smsLogs5), XContentType.JSON));
smsLogs5.setMobile("13990001234");
smsLogs5.setProvince("山西");
smsLogs5.setSmsContent("【北京移动】尊敬的客户137****1234,8月话费账单已送达您的126邮箱,\" + \"点击查看账单详情 http://y.10086.cn/; \" + \" 回Q关闭通知,关注“中国移动126邮箱”微信随时查账单【中国移动 126邮箱】");
request.add(new IndexRequest(index, type, "32").source(mapper.writeValueAsString(smsLogs5), XContentType.JSON));
// -------------------------------------------------------------------------------------------------------------------
client.bulk(request,RequestOptions.DEFAULT);
System.out.println("OK!");
}
}term & terms查询
term查询 :term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个
from:从哪开始查 size:返回几条结果 比如这里精确查找省份
from 与 size 之和不能超过10000

通过JAVA操作 看一下上图的结构,在java中操作,最终我们要获取到 hists ——> hits ——> _source中的数据
public class DemoThree {
RestHighLevelClient client = ESClient.getClient();
String index = "sms-logs-index";
String type = "sms-logs-type";
/**
* 使用term方式查询
* @throws IOException
*/
@Test
public void TermQuery() throws IOException {
//获取request对象
SearchRequest request = new SearchRequest(index);
request.types(type);
//指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0);
builder.size(3);
builder.query(QueryBuilders.termQuery("province","北京"));
request.source(builder);
//执行查询
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//获取_source的数据,并展示
SearchHit[] hits = response.getHits().getHits();
for (SearchHit searchHit: hits) {
Map<String, Object> result = searchHit.getSourceAsMap();
System.out.println(result);
}
}
}
terms查询
和term查询一样,搜索前不会再对搜索词进行分词,但是可以查询多个
@Test
public void TermsQuery() throws IOException {
//获取Request对象
SearchRequest request = new SearchRequest(index);
request.types(type);
//指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0);
builder.size(10);
builder.query(QueryBuilders.termsQuery("province","山西","北京"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> result = hit.getSourceAsMap();
System.out.println(result);
}
}match查询
match查询属于高层查询,它会根据查询字段类型的不同,采用不同的查询方式。
- 查询的如果是日期或者数值,它会把基于字符串查询的内容转换为日期或者数值对待。
- 如果查询的内容是不能被分词的内容(keyword),match查询不会对你指定的查询关键字进行分词。
- 如果查询的内容是可以被分词的内容(text),match会将指定的查询内容根据一定方式进行分词,去分词库中匹配指定的内容。
macth_all查询 : 查询全部内容,不指定任何查询条件
/**
* matchAll
* @throws IOException
*/
@Test
public void matchAllQuery() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchAllQuery());
// 默认只显示10条数据,想查询更多,需要设置size
//builder.size(20);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> result = hit.getSourceAsMap();
System.out.println(result);
}
}match查询
/**
* match查询
* @throws IOException
*/
@Test
public void matchQuery() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("smsContent","收获安装"));
// 默认只显示10条数据,想查询更多,需要设置size
//builder.size(20);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> result = hit.getSourceAsMap();
System.out.println(result);
}
}布尔match查询
布尔match就是里面加上query和operator这两个进行指定信息;query用于指定查询内容;operator用于指定是and还是or
/**
* booleanMatch查询
* @throws IOException
*/
@Test
public void booleanMatchQuery() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
//Operator.AND Operator.OR
builder.query(QueryBuilders.matchQuery("smsContent","中国 健康").operator(Operator.AND));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> result = hit.getSourceAsMap();
System.out.println(result);
}
}multi_match查询:查询为能在多个字段上反复执行相同查询提供了一种便捷方式
/**
* multiMatch查询
* @throws IOException
*/
@Test
public void MultiMatchQuery() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
//多字段
builder.query(QueryBuilders.multiMatchQuery("北京","province","smsContent"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> result = hit.getSourceAsMap();
System.out.println(result);
}
}id & ids 查询
在kibana中操作如下

对应的在java中通过id查询
@Test
public void idSearch() throws IOException {
GetRequest request = new GetRequest(index,type,"21");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsMap());
}ids查询 类似mysql中的 where id in(id1,id2.....)
@Test
public void idsSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.idsQuery().addIds("21","22","23"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}prefix查询
通过一个关键字去指定一个Field的前缀,从而查询到指定的文档

@Test
public void prefixSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.prefixQuery("corpName","途虎"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}fuzzy查询
模糊查询 通过kibana可以看到,虽然把 "盒马鲜生" 写错了,但是也可以查到 prefix_length表示前多少个字符不能出错

@Test
public void fuzzySearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.fuzzyQuery("corpName","盒马先生").prefixLength(2));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}wildcard查询
通配查询,查询时在字符串中指定通配符* 和 占位符 ?
@Test
public void wildCardSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.wildcardQuery("corpName","中国*"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}range查询
范围查询,只针对数值类型,对某一个field进行大于或者小于的指定
@Test
public void rangeSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
//gt > gte >= lt < lte <=
builder.query(QueryBuilders.rangeQuery("fee").gt(5).lte(10));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}regexp查询:通过正则表达式匹配内容
上文提到的 prefix、fuzzy、wildcard以及这里的regexp查询效率都比较低,要求效率比较高时尽量避免使用。
@Test
public void regexpSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.regexpQuery("mobile","180[0-9]{8}"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}深分页scroll查询
- 将用户指定的关键进行分词
- 将词汇到分词库中进行检索,得到多个文档的id
- 把文档id存放在es上下文中
- 根据指定的size检索指定的数据,拿完数据的文档id,会从上下文中移除
- 如果需要下一页数据,会直接从es上下文中找后续内容
- 循环4和5
初始搜索请求和随后的每个滚动请求都返回 scroll_id。虽然_scroll_id在请求之间可能会改变,但它并不总是改变——在任何情况下,应该只使用最近接收到的 scroll_id。

查询下一页数据

删除scroll在上下文中的数据

通过java操作代码
@Test
public void scrollSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
//指定scroll信息
//指定scroll生存时间
request.scroll(TimeValue.MINUS_ONE);
//指定查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.size(4);
builder.sort("fee", SortOrder.DESC);
builder.query(QueryBuilders.matchAllQuery());
request.source(builder);
//获取返回结构scrollId,source
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
String scrollId = response.getScrollId();
System.out.println("-----首页-----");
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
while (true){
//循环 创建SearchScrollRequest 指定scrollId
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
//指定scrollId生存时间
scrollRequest.scroll(TimeValue.MINUS_ONE);
//执行查询获取返回结果
SearchResponse searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);
//判断是否查询到了数据,输出
SearchHit[] hits = searchResponse.getHits().getHits();
if (hits != null && hits.length > 0){
System.out.println("----下一页----");
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsMap());
}
}else{
//判断没有查到数据,退出循环
System.out.println("----结束----");
break;
}
}
//创建clearScrollRequest
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
//指定scrollId
clearScrollRequest.addScrollId(scrollId);
//删除
ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
System.out.println("删除scroll:"+clearScrollResponse.isSucceeded());
}
复合查询
bool查询
复合过滤器,将多个查询条件,以一定的逻辑组合在一起
- must 所有的条件,用must组合在一起,表示And的意思
- must_not must_not中的条件全部都不匹配,表示Not的意思
- should 所有的条件用should组合在一起,表示 Or 的意思

@Test
public void boolSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.should(QueryBuilders.termQuery("province","武汉"));
boolQueryBuilder.should(QueryBuilders.termQuery("province","北京"));
boolQueryBuilder.mustNot(QueryBuilders.termQuery("operatorId","2"));
boolQueryBuilder.must(QueryBuilders.matchQuery("smsContent","中国"));
boolQueryBuilder.must(QueryBuilders.matchQuery("smsContent","平安"));
builder.query(boolQueryBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}boosting查询
boosting查询可以帮助我们影响查询后的score
- positive:只有匹配上positive的内容,才会被放入结果集中
- negative:如果匹配上positive并且也匹配上negative,就可以降低这样的文档分数
- negative_boost:指定系数,必须小于1
关于查询时,分数如何计算:
- 搜索的关键字在文档中出现频次越高则分数越高
- 指定的文档内容越短,则分数越高
- 搜索时,指定的关键字被分词,被分词的内容与分词库匹配的个数越多,则分数越高

@Test
public void boostingSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
BoostingQueryBuilder boostingQueryBuilder = QueryBuilders.boostingQuery(
QueryBuilders.matchQuery("smsContent", "收获安装"),
QueryBuilders.matchQuery("smsContent", "刘红")
).negativeBoost(0.5f);
builder.query(boostingQueryBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}filter查询
filter根据查询条件去查询文档,不计算分数,会对经常被过滤的数据进行缓存
先看一下kibana中

@Test
public void filterSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.filter(QueryBuilders.termQuery("corpName","盒马鲜生"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("fee").lte("5"));
builder.query(boolQueryBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}高亮查询
用户输入的关键字,以一定的特殊样式展示,es会提供一个highlight属性,和query同级别
- fragment_size:指定高亮数据展示多少个字符
- fields:指定哪几个field高亮显示
- pre_tags:指定前缀标签 举个例子<font color="red">
- post_tags:指定后缀标签 举例</font>

@Test
public void highLightSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("smsContent","盒马"));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("smsContent",10).preTags("<font color='orange'>").postTags("</font>");
builder.highlighter(highlightBuilder);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getHighlightFields().get("smsContent"));
}
}聚合查询
去重计数统计
Cardinality 即不重复的字段有多少(相当于sql中的distinct)
@Test
public void cardinality() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation( AggregationBuilders.cardinality("agg").field("province"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Cardinality cardinality = response.getAggregations().get("agg");
System.out.println(cardinality.getValueAsString());
}范围统计
统计一定范围内出现的文档个数,比如:针对某一个field的值在0-100,200-300之间文档出现的个数分别是多少。
范围统计可以针对普通的数值,针对时间类型,针对ip类型都可以做相应统计 (range、date_range、ip_range)

@Test
public void rangeCountSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(AggregationBuilders.range("agg").field("fee")
.addUnboundedTo(5)
.addRange(5,10)
.addUnboundedFrom(10));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Range agg = response.getAggregations().get("agg");
for (Range.Bucket bucket : agg.getBuckets()) {
String key = bucket.getKeyAsString();
Object from = bucket.getFrom();
Object to = bucket.getTo();
long docCount = bucket.getDocCount();
System.out.println(String.format("key:%s,from:%s,to:%s,docCount:%s",key,from,to,docCount));
}
}统计聚合查询

@Test
public void extendedSearch() throws IOException {
SearchRequest request = new SearchRequest(index);
request.types(type);
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.aggregation(AggregationBuilders.extendedStats("agg").field("fee"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
ExtendedStats agg = response.getAggregations().get("agg");
double max = agg.getMax();
double min = agg.getMin();
System.out.println(String.format("max:%s,min:%s",max,min));
}更多的聚合查询可以去查看官方文档

地图经纬度搜索
es支持两种类型的地理数据
- geo_point 支持经纬度
- geo_shape 支持点、线、圆、多边形、多面体等
#创建一个索引,指定一个name,location
PUT /map
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"map": {
"properties": {
"name": {
"type": "text"
},
"location": {
"type": "geo_point"
}
}
}
}
}#添加测试数据
PUT /map/map/1
{
"name": "合肥野生动物园",
"location": {
"lon": 117.174075,
"lat": 31.840982
}
}
PUT /map/map/2
{
"name": "大蜀山",
"location": {
"lon": 117.183561,
"lat": 31.847116
}
}该组中的查询方式有:
geo_shape :查找具有与指定几何形状相交,包含在其中或不与指定几何形状相交的几何形状的文档geo_bounding_box: 查找具有落入指定矩形的地理位置的文档。geo_distance :查找地理点在中心点指定距离内的文档。(比如点外卖,选3km以内卖家)geo_polygon :查找具有指定多边形内的地理点的文档。
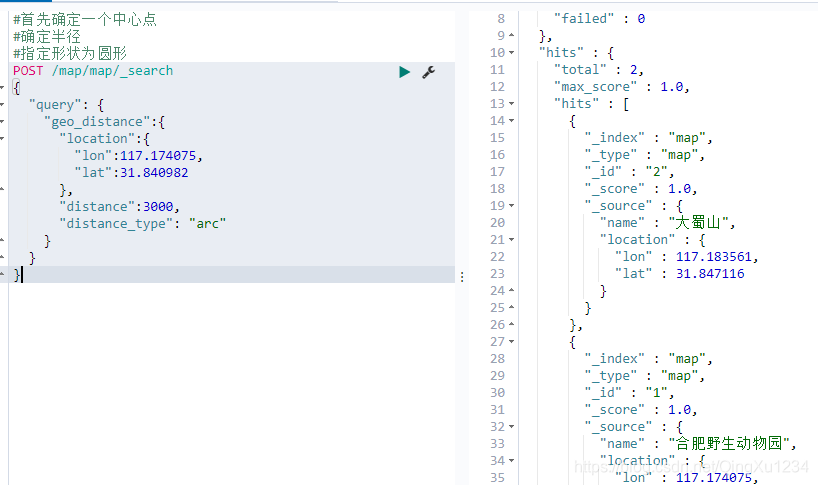
使用java操作
@Test
public void geoSearch() throws IOException {
SearchRequest request = new SearchRequest("map");
request.types("map");
SearchSourceBuilder builder = new SearchSourceBuilder();
GeoDistanceQueryBuilder location = QueryBuilders.geoDistanceQuery("location");
location.point(31.840982,117.174075);
location.distance("3000");
builder.query(location);
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
















 8303
8303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











