






内容简介:先简单介绍Base64,然后对其算法进行分析。
前言
Base64 是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64 就是一种基于64个可打印字符来表示二进制数据的方法。一般 Base64 编码后的数据具有不可读性,需要解码后才能阅读原数据。但这种编解码算法是公开的(部分公司会实现自己的变种算法),也相对简单,所以 Base64 严格意义上不能用于加解密工作,即它的安全性不高。但这种编码方法在传输数据时非常有用,可以有效的防止被人直接看到明文。
Base64的特殊场景
前言中提到,Base64 是基于64个可打印字符来进行编码的,但现实中存在很多使用场景,有的场景中标准64字符不一定全部适用。本文主要介绍标准、URL和MIME三种场景。
标准场景
标准模式中,64字符表如下图所示(来自Wikipedia):
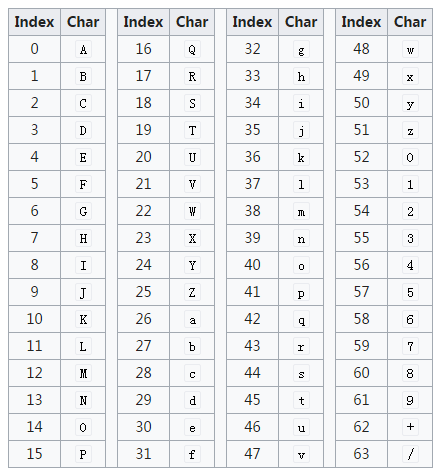 可以看到64个字符由:A~Z、a~z、0~9以及 + 、 / 组成。
可以看到64个字符由:A~Z、a~z、0~9以及 + 、 / 组成。
URL场景
标准的 Base64 并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
MIME场景
MIME介绍
在MIME场景中,Base64编码后的数据每行不超过76个字符,还会在行末添加“\r”和“\n”(CR/LF)。
Base64的算法规则
简单来说,Base64 的规则就是把3个8Bit字节转化为4个6Bit字节(3 * 8 = 4 * 6)。那6个Bit怎么算成一个字节呢,就需要高位补两个0,这样就凑成了8Bit。然后,新构成的8Bit二进制数就可以在表中找到对应的字符。如果待处理数据长度(字节数)不是3的倍数,则会有1个字节或者2个字节的剩余,这就导致无法直接转成4个字节,所以需要补充“=”号(最多两个“=”号)。
 原文“Man”,找到每个字符对应的二进制,然后每6个Bit进行处理,高位补00,然后在表中找到新字符。可以看出,编码后的字符串长度约是原字符串的4/3。
原文“Man”,找到每个字符对应的二进制,然后每6个Bit进行处理,高位补00,然后在表中找到新字符。可以看出,编码后的字符串长度约是原字符串的4/3。
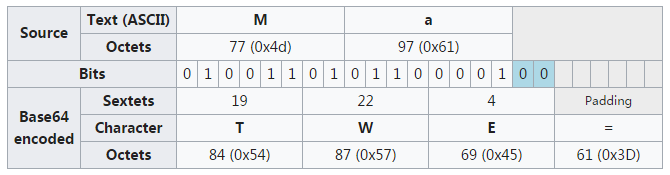 当原串字节长度不是3的倍数时,编码后需要补充“=”号来凑够4个字节。这里看到,最后的“a”只剩下了“0001”不够6Bit,所以在地位补充了两个0。
当原串字节长度不是3的倍数时,编码后需要补充“=”号来凑够4个字节。这里看到,最后的“a”只剩下了“0001”不够6Bit,所以在地位补充了两个0。
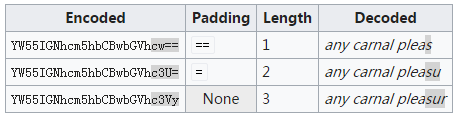
 这里也是,不够6Bit就在地位补0。这里说明下,为什么最多补充两个“=”号,因为一个8Bit会构成两个新字符,也就是说,4个新字符中最多缺少2个字符,所以最多需要补充2个“=”号。
这里也是,不够6Bit就在地位补0。这里说明下,为什么最多补充两个“=”号,因为一个8Bit会构成两个新字符,也就是说,4个新字符中最多缺少2个字符,所以最多需要补充2个“=”号。
以上是 Base64 的编码规则,至于解码,则是对应的逆过程。主要是注意对“=”号的处理。
Base64的实现
在Android中可以使用 java.util.Base64和 android.util.Base64两个类,它们的实现类似,这里只分析 java.util.Base64。
// 标准模式的编解码
public static Encoder getEncoder()
public static Decoder getDecoder()
// URL模式的编解码
public static Encoder getUrlEncoder()
public static Decoder getUrlDecoder()
// MIME模式的编解码
public static Encoder getMimeEncoder()
public static Decoder getMimeDecoder()编码过程中的核心方法是: privateintencode0(byte[]src,intoff,intend,byte[]dst),分析如下:
private int encode0(byte[] src, int off, int end, byte[] dst) {
// 判断是否是URL模式
char[] base64 = isURL ? toBase64URL : toBase64;
int sp = off;
int slen = (end - off) / 3 * 3; // 3的倍数长度
int sl = off + slen; // 3的倍数长度位置
if (linemax > 0 && slen > linemax / 4 * 3)
slen = linemax / 4 * 3; // MIME模式特殊处理
int dp = 0;
while (sp < sl) {
// 最后一段可能不够3的倍数
int sl0 = Math.min(sp + slen, sl);
// 处理完3的倍数长度的字节
for (int sp0 = sp, dp0 = dp ; sp0 < sl0; ) {
// 取出三个字节
// 第一个字节左移16位,整个就变成了24个位
// 然后依次加入连续的2个字节
int bits = (src[sp0++] & 0xff) << 16 |
(src[sp0++] & 0xff) << 8 |
(src[sp0++] & 0xff);
// 每6位处理一次,0x3f=00111111,即高位补00
dst[dp0++] = (byte)base64[(bits >>> 18) & 0x3f];
dst[dp0++] = (byte)base64[(bits >>> 12) & 0x3f];
dst[dp0++] = (byte)base64[(bits >>> 6) & 0x3f];
dst[dp0++] = (byte)base64[bits & 0x3f];
}
int dlen = (sl0 - sp) / 3 * 4; // 长度变成原来的4/3
dp += dlen;
sp = sl0; // 原数据中新的起始坐标
// MIME模式,每行最长76字符,行末需要增加 \r\n
if (dlen == linemax && sp < end) {
for (byte b : newline){
dst[dp++] = b;
}
}
}
// 原数据长度不是3的倍数,有剩余,需要补充=号
// 最多补两个=号
if (sp < end) { // 1 or 2 leftover bytes
int b0 = src[sp++] & 0xff;
dst[dp++] = (byte)base64[b0 >> 2];
if (sp == end) {
dst[dp++] = (byte)base64[(b0 << 4) & 0x3f];
if (doPadding) {
dst[dp++] = '=';
dst[dp++] = '=';
}
} else {
int b1 = src[sp++] & 0xff;
dst[dp++] = (byte)base64[(b0 << 4) & 0x3f | (b1 >> 4)];
dst[dp++] = (byte)base64[(b1 << 2) & 0x3f];
if (doPadding) {
dst[dp++] = '=';
}
}
}
return dp;
}解码过程中的核心方法是: privateintdecode0(byte[]src,intsp,intsl,byte[]dst),分析如下:
private int decode0(byte[] src, int sp, int sl, byte[] dst) {
int[] base64 = isURL ? fromBase64URL : fromBase64;
int dp = 0;
int bits = 0;
int shiftto = 18; // pos of first byte of 4-byte atom
while (sp < sl) {
int b = src[sp++] & 0xff;
if ((b = base64[b]) < 0) {
if (b == -2) { // padding byte '='
// = shiftto==18 unnecessary padding
// x= shiftto==12 a dangling single x
// x to be handled together with non-padding case
// xx= shiftto==6&&sp==sl missing last =
// xx=y shiftto==6 last is not =
if (shiftto == 6 && (sp == sl || src[sp++] != '=') ||
shiftto == 18) {
throw new IllegalArgumentException(
"Input byte array has wrong 4-byte ending unit");
}
break;
}
if (isMIME) // skip if for rfc2045
continue;
else
throw new IllegalArgumentException(
"Illegal base64 character " +
Integer.toString(src[sp - 1], 16));
}
bits |= (b << shiftto); // 通过或操作拼接字节
shiftto -= 6;
if (shiftto < 0) { // 这里再通过左移操作完成最后的计算
dst[dp++] = (byte)(bits >> 16);
dst[dp++] = (byte)(bits >> 8);
dst[dp++] = (byte)(bits);
shiftto = 18;
bits = 0;
}
}
// reached end of byte array or hit padding '=' characters.
if (shiftto == 6) { // 处理两个=号
dst[dp++] = (byte)(bits >> 16);
} else if (shiftto == 0) { // 处理一个=号
dst[dp++] = (byte)(bits >> 16);
dst[dp++] = (byte)(bits >> 8);
} else if (shiftto == 12) {
// dangling single "x", incorrectly encoded.
throw new IllegalArgumentException(
"Last unit does not have enough valid bits");
}
// anything left is invalid, if is not MIME.
// if MIME, ignore all non-base64 character
while (sp < sl) {
if (isMIME && base64[src[sp++]] < 0)
continue;
throw new IllegalArgumentException(
"Input byte array has incorrect ending byte at " + sp);
}
return dp;
}要想很好地理解上面的两个方法,可以使用上面“算法规则”那一小节的例子,通过debug来一步一步分析。android.util.Base64中,主要注意一下初始化。
/**
* Default values for encoder/decoder flags.
* 默认模式,不够长度会补充=号,每行最长76字符,自动换行
*/
public static final int DEFAULT = 0;
/**
* Encoder flag bit to omit the padding '=' characters at the end
* of the output (if any).
* 不补充=号
*/
public static final int NO_PADDING = 1;
/**
* Encoder flag bit to omit all line terminators (i.e., the output
* will be on one long line).
* 不自动换行
*/
public static final int NO_WRAP = 2;
/**
* Encoder flag bit to indicate lines should be terminated with a
* CRLF pair instead of just an LF. Has no effect if {@code
* NO_WRAP} is specified as well.
* 每行行末添加\r\n
*/
public static final int CRLF = 4;
/**
* Encoder/decoder flag bit to indicate using the "URL and
* filename safe" variant of Base64 (see RFC 3548 section 4) where
* {@code -} and {@code _} are used in place of {@code +} and
* {@code /}.
* URL安全模式
*/
public static final int URL_SAFE = 8;
/**
* Flag to pass to {@link Base64OutputStream} to indicate that it
* should not close the output stream it is wrapping when it
* itself is closed.
*/
public static final int NO_CLOSE = 16;Base64的示例请移步:https://github.com/zjxstar/AndroidSamples/tree/master/SecuritySample
参考资料
百度百科;
Wikipedia;
--END--
识别二维码,关注我们
















 6690
6690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









