







1. OpenMP
OpenMP API 用户指南: https://math.ecnu.edu.cn/~jypan/Teaching/ParaComp/books/OpenMP_sun10.pdf
超算习堂 - OpenMP 编程实训: https://easyhpc.net/problem/programming_lab/2
推荐学习视频: https://www.bilibili.com/video/BV18M41187ZU/?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1Ea411X78R/?spm_id_from=333.999.0.0&vd_source=d4d8725a1a30e189fa2cd9218fa9842a
open MP入门
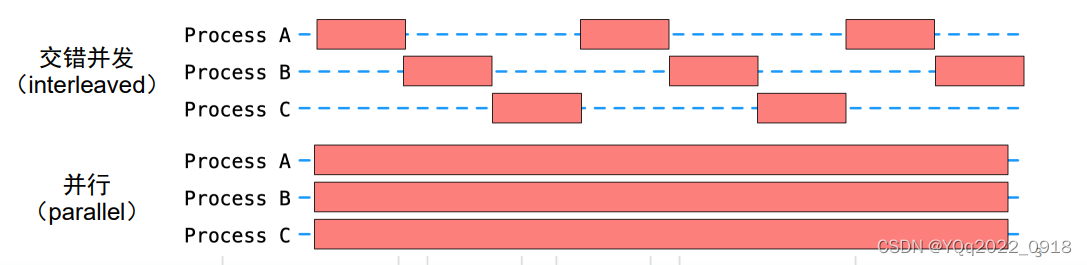
(1)什么是并行?
-
多个任务同时进行
- 交错并发(interleaved)
- 并行(parallel)
-
多任务实现方式
-
并发(concurrent):
-
多个进程或线程“同时“进行
-
交错并发:可通过系统调度由单核完成。
-
并行:需要多个运算核心同时完成
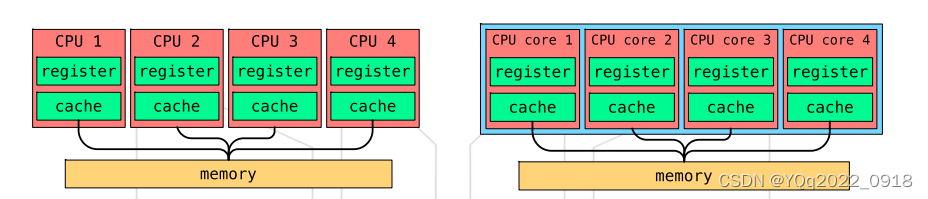
-
多处理器vs单处理器多核
- 同一芯片上的多核通信速度更快
- 同一芯片上的多核能耗更低
-
-
进程:一个执行中的程序即为一个进程
-
每个进程有独立的程序计数器(program counter)、堆(heap)、栈(stack)、数据段(data section)、代码段等。
从上到下:
stack(局部变量等)—> (相遇则内存不足) <—heap(由malloc、new等动态分配的空间)、data、text/code
-
程序运行状态由进程控制块(process control block)记录
-
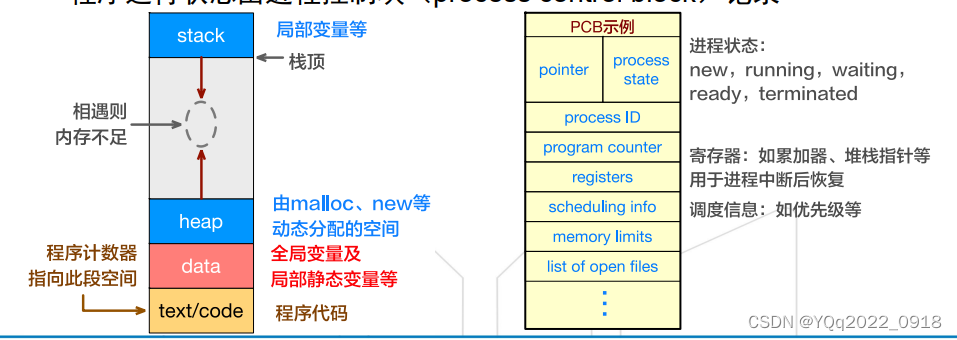
CPU在进程之间切换需要进行上下文切换
-
线程:常被称为轻量级进程(lightweight process)
-
与进程相似:每个线程有线程ID、程序计数器、寄存器(registers)、栈等。
-
与进程不同:所有线程共享代码段、数据段及其他系统资源(如文件等)
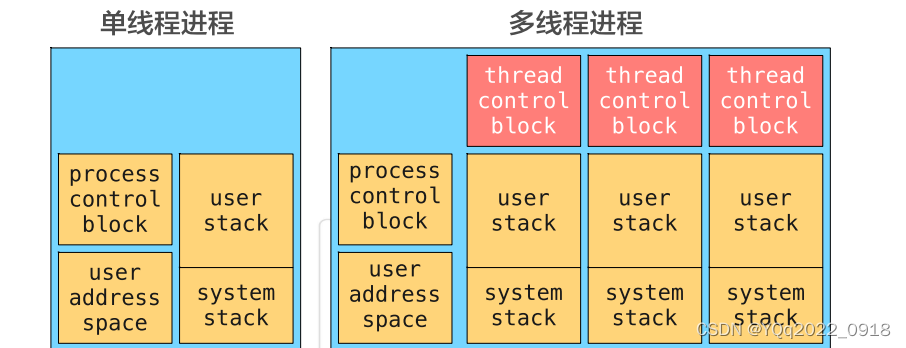
-
CPU在线程之间切换开销较小
线程的硬件调度
硬件和操作系统会自行将线程调度到CPU核心运行。
当线程数目超过核心数,会出现多个线程抢占一个CPU核心,导致性能下降。
超线程(hyper-threading)将单个CPU物理核心抽象为多个(目前通 常为2个)逻辑核心,共享物理核心的计算资源。
-
-
(2)什么是OpenMP?
一种面向共享内存的多CPU多线程并行编程接口。
API,英文全称Application Programming Interface,翻译为“应用程序编程接口”
(OpenMP是一个应用程序接口(API) ,可以简单理解为它是一个库,支持多种指令集和操作系统)
-
OpenMP:Open Multi-Processing
-
多线程编程API
- 编译器指令(#pragma)、库函数、环境变量
- 极大地简化了C/C++/Fortran多线程编程
- 并不是全自动并行编程语言
- 其并行行为仍需由用户定义和控制
-
支持共享内存的多核系统
- 与CUDA、MPI所支持的硬件比较

-
-
#pragma
-
预处理指令
-
设定编译器状态或指定编译器完成特定动作
- 需要编译器支持相应功能,否则将被忽略
-
举例:
#pragma once
- 指定头文件只被编译一次
#pragma once
需要编译器支持、针对物理文件、需要用户保证头文件没有多份拷贝
(#pragma once一般由编译器提供保证:同一个文件不会被包含多次。这里所说的”同一个文件”是指物理上的一个文件,而不是指内容相同的两个文件。)
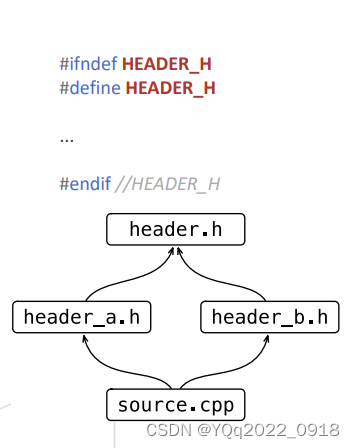
#ifndef
不需要特定编译器
不针对物理文件
需要用户保证不同文件的宏名不重复
-
-
其他#pragma指令
-
#pragma GCC poison printf(收集不安全的c函数,使用预编译属性禁止这些函数在项目源码中使用,这里是printf)
-
#pragma warning (disable : 4996)
在程序的最前面加上 #pragma warning (disable:4996) 表示为忽略改警告 。 1. #pragma warning只对当前文件有效(对于.h,对包含它的cpp也是有效的),而不是对整个工程的所有文件有效。 当该文件编译结束,设置也就失去作用。 2. #pragma warning (push) 存储当前报警设置。
-
-
OpenMp中的并行化声明由#pragma完成
-
格式:
#pragma omp construct(指令) [clause(子句) [clause]...]- 如
#pragma omp parallel for - 编译器如果不支持该指令则将直接忽略
- 如
-
其作用范围通常为一个代码区块
#pragma omp parallel for for (int i=0; i<10; ++i){ std::cout << i << std::endl; }#pragma omp parallel关键字创建多线程必须在编译时加上-fopenmp选项,否则起不到并行的效果,
g++ a.cc -fopenmp
如何使一段代码并行处理呢?omp中使用parallel制导指令标识代码中的并行段,形式为:
#pragma omp parallel
{
每个线程都会执行大括号里的代码
}
如果想将for循环用多个线程去执行,可以用for制导语句
for制导语句是将for循环分配给各个线程执行,这里要求数据不存在依赖。
使用形式为:
(1)#pragma omp parallel for
for()
(2)#pragma omp parallel
{//注意:大括号必须要另起一行
#pragma omp for
for()
}
-
-
-
OpenMP环境配置
-
Windows
- 项目属性 -> C/C++ -> Language -> Open MP Support
-
macOS/Linux
- 对于支持OpenMP的编译器(gcc 在编译时增加-fopenmp标记)
-
使用库函数
#include<omp.h>
-
查看OpenMP版本
-
使用_OPENMP宏定义
_OPENMP宏可以用来判断OpenMP是否被支持,通过它可以写出任何C语言编译器(即使不支持OpenMP)都可以编译的代码。
#include<unordered_map> #include<string> #include<cstdio> #include<omp.h> int main(int argc,char *argv[]) { std::unordered_map<unsigned,std::string>map{ {200205,"2.5"},{200805,"3.0"}, {201107,"3.1"},{201307,"4.0"}, {201511,"4.5"}}; printf("OpenMP version:%s.\n",map.at(_OPENMP).c_str()); return 0; }yang@yang-virtual-machine:~/桌面/openmp$ vim openmp.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp openmp.cpp -o openmp.out yang@yang-virtual-machine:~/桌面/openmp$ ./openmp.out OpenMP version:4.5.查看版本方法二:
yang@yang-virtual-machine:~/桌面$ echo |cpp -fopenmp -dM |grep -i open #define _OPENMP 201511
-
-
-
OpenMP Hello world
-
通过
#pragma omp parallel指明并行部分 -
无需改变串行代码
#include <stdio.h> #include <omp.h> int main() { #pragma omp parallel { printf("Hello World\n"); } return 0; }yang@yang-virtual-machine:~/桌面/openmp$ vim helloworld.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp helloworld.cpp -o hello.out yang@yang-virtual-machine:~/桌面/openmp$ ./hello.out Hello World Hello World -
在输出中添加线程编号
omp_get_thread_num()#include <stdio.h> #include <omp.h> int main() { #pragma omp parallel { int thread = omp_get_thread_num(); int max_threads = omp_get_max_threads(); printf("Hello World (Thread %d of %d)\n", thread, max_threads); } return 0; }yang@yang-virtual-machine:~/桌面/openmp$ vim hello2.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp hello2.cpp -o hello2.out yang@yang-virtual-machine:~/桌面/openmp$ ./hello2.out Hello World (Thread 0 of 2) Hello World (Thread 1 of 2)omp_get_max_threads该函数可以用于获得最大的线程数量,根据OpenMP文档中的规定,这个最大数量是指在不使用num_threads的情况下,OpenMP 可以创建的最大线程数量。 -
同一线程的多个语句是否连续执行?
#include <stdio.h> #include <omp.h> int main() { #pragma omp parallel { int thread = omp_get_thread_num(); printf("hello(%d) ", thread); printf("world(%d) ", thread); } return 0; }yang@yang-virtual-machine:~/桌面/openmp$ vim hello3.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp hello3.cpp -o hello3.out yang@yang-virtual-machine:~/桌面/openmp$ ./hello3.out hello(1) world(1) hello(0) world(0)有些人能输出:
hello(0) world(0) hello(4) hello(1) world(1) hello(7) hello(3) world(7) world(3) hello(6) world(6) hello(5) world(5) hello(2) world(4) world(2)
-
-
OpenMP运行机制
-
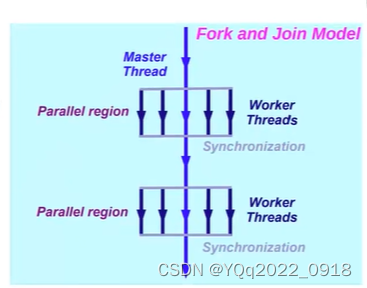
使用分叉(fork)与交汇(join)模型
- Fork:由主线程(master thread)创建一组从线程(slave threads)
- 主线程编号永远为0(thread 0)
- 不保证执行顺序
- Join:同步终止所有线程并将控制权转移回至主线程
- Fork:由主线程(master thread)创建一组从线程(slave threads)
-
(3)语法
编译器指令
#pragma omp construct [clause [clause]...]{structured block}
-
指明并行区域及并行方式
-
clause子句
-
指明详细的并行参数
– 控制变量在线程间的作用域
– 显式指明线程数目
– 条件并行
-
#pragma omp parallel num_threads(16)
{
int thread = omp_get_thread_num();
int max_threads = omp_get_max_threads();
printf(“Hello World (Thread %d of %d)\n”, thread, max_threads);
}
-
if(scalar_expression):决定是否以并行的方式执行并行区- 表达式为真 (非零):按照并行方式执行并行区
- 否则:主线程串行执行并行区
-
num_threads(int)- 用于指明线程数目
- 当没有指明时,将默认使用OMP_NUM_THREADS环境变量
- 环境变量的值为系统运算核心数目(或超线程数目)
- 可以使用
omp_set_num_threads(int)修改全局默认线程数 - 可使用
omp_get_num_threads()获取当前设定的默认线程数 num_threads(int)优先级高于环境变量
num_threads(int)不保证创建指定数目的线程 (系统资源限制)
设置线程数
- 优先级由低到高
- 什么也不做,系统选择运行线程数
- 设置环境变量
export OMP_NUM_THREADS=4 - 代码中使用库函数
void omp_set_num_threads(int) - 通过制导语句从句
num_threads(integer-expression) - if从句判断串行还是并行执行
-
并行for循环
-
将循环中的迭代分配到多个线程并行。
在并行区内对for循环进行线程划分,且for循环满足格式要求
init-expr:需要是var=lb形式,类型也有限制test-expr:限制为var relational-opb或者b relational-op varincr-expr:仅限加减法
#pragma omp parallel { int n; for (n = 0; n < 4; n++){ int thread = omp_get_thread_num(); printf("thread %d \n", thread); } }yang@yang-virtual-machine:~/桌面/openmp$ vim test1.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp test1.cpp -o test1.out yang@yang-virtual-machine:~/桌面/openmp$ ./test1.out thread 1 thread 1 thread 1 thread 1 thread 0 thread 0 thread 0 thread 0-
风格1:在并行区域加入
#pragma omp for(在并行区域内,for循环外还可以加入其他并行代码)
#pragma omp parallel { int n; #pragma omp for for (n = 0; n < 4; n++){ int thread = omp_get_thread_num(); printf("thread %d \n", thread); } } -
风格2:合并为
#pragma omp parallel for(写法更简洁)
int n; #pragma omp parallel for for (n = 0; n < 4; n++) { int thread = omp_get_thread_num(); printf("thread %d \n", thread); }yang@yang-virtual-machine:~/桌面/openmp$ vim test2.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp test2.cpp -o test2.out yang@yang-virtual-machine:~/桌面/openmp$ ./test2.out thread 0 thread 0 thread 1 thread 1 #两种风格结果一样vim test3.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp test3.cpp -o test3.out yang@yang-virtual-machine:~/桌面/openmp$ ./test3.out thread 1(n=2) thread 1(n=3) thread 0(n=0) thread 0(n=1) yang@yang-virtual-machine:~/桌面/openmp$ cat test3.cpp #include<stdio.h> #include<omp.h> int main() { #pragma omp parallel { int n; #pragma omp for for(n=0; n<4;n++){ int thread= omp_get_thread_num(); printf("thread %d(n=%d)\n", thread,n); } } return 0; }
-
-
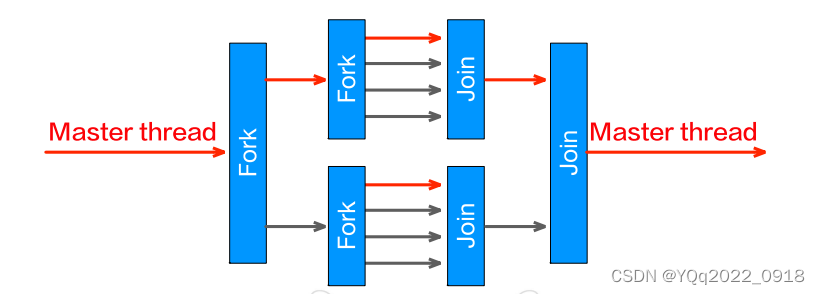
嵌套并行
-
OpenMP中的每个线程同样可以被并行化为一组线程
-
OpenMP默认关闭嵌套,需要使用
omp_set_nested(1)打开#include<stdio.h> #include<omp.h> int main() { omp_set_nested(1); #pragma omp parallel for for (int i = 0; i < 2; i++){ int outer_thread = omp_get_thread_num(); #pragma omp parallel for for (int j = 0; j < 4; j++){ int inner_thread = omp_get_thread_num(); printf("Hello World (i = %d j = %d)\n", outer_thread, inner_thread); } } }yang@yang-virtual-machine:~/桌面/openmp$ vim test4.c yang@yang-virtual-machine:~/桌面/openmp$ gcc -fopenmp test4.c -o test4.out yang@yang-virtual-machine:~/桌面/openmp$ ./test4.out Hello World (i = 0 j = 0) Hello World (i = 0 j = 0) Hello World (i = 0 j = 1) Hello World (i = 0 j = 1) Hello World (i = 1 j = 0) Hello World (i = 1 j = 0) Hello World (i = 1 j = 1) Hello World (i = 1 j = 1) -
仍然可以使用fork and join
-
-
-
不能并行的循环
-
语法限制
-
不能使用!=作为判断条件
for (int i = 0; i**!=**8; ++i){
• error: condition of OpenMP for loop must be a relational comparison (‘<’, ‘<=’, ‘>’, or ‘>=’) of loop variable ‘i’
-
循环必须为单入口单出口
- 不能使用break、goto等跳转语句
- error: ‘break’ statement cannot be used in OpenMP for loop
-
(以上错误提示来自OpenMP 3.1)
-
-
数据依赖性
- 循环迭代相关(loop-carried dependence)
- 依赖性与循环相关,去除循环则依赖性不存在
- 非循环迭代相关(loop-carried dependence)
- 依赖性与循环无关,去除循环依赖性仍然存在

- 循环迭代相关(loop-carried dependence)
-
(4)同步机制
线程互动与同步
- OpenMP是多线程共享地址架构
- – 线程可通过共享变量通信
- 线程及其语句执行具有不确定性
- – 共享数据可能造成竞争条件(race condition)
- – 竞争条件:程序运行的结果依赖于不可控的执行顺序
- 必须使用同步机制避免竞争条件的出现
- – 同步机制将带来巨大开销
- – 尽可能改变数据的访问方式减少必须的同步次数
竞争条件
-
语句执行顺序造成结果不一致
-
int a[3]={3,4,5}; thread 1:a[1]=a[0]+a[1]; thread 2:a[2]=a[1]+a[2]; -
先执行 thread 1 再执行 thread 2
- a[1]=a[0]+a[1]=3+4=7; a[2]=a[1]+a[2]=7+5=12;
- a = { 3, 7, 12}
-
先执行 thread 2 再执行 thread 1
- a[2]=a[1]+a[2]=4+5=9; a[1]=a[0]+a[1]=3+4=7;
- a = { 3, 7, 9 }
-
-
高级语言的语句并非原子操作




如何保证执行结果正确
-
临界区(critical section)
-
#pragma omp critical -
指的是一个访问共用资源(例如:共用设备或是共用存储器)的 程序片段,而这些共用资源又无法同时被多个线程访问的特性
- 同一时间内只有一个线程能执行临界区内代码
- 其他线程必须等待临界区内线程执行完毕后才能进入临界区
- 常用来保证对共享数据的访问之间互斥
-

-
比照操作系统中信号量(semaphore)与P、V操作
#pragma omp critical { ... critical section; ... }Semaphore a; P(a); ... critical section; ... V(a);信号量:信号量(Semaphores)的数据结构由一个值value和一个进程链表指针L组成,信号量的值代表了资源的数目,链表指针链接了所有等待访问该资源的进程。
PV操作:通过对信号量S进行两个标准的原子操作(不可中断的操作)wait(S)和signa(S),可以实现进程的同步和互斥。这两个操作又常被称为P、V操作,其定义如下:
**P(S):**①将信号量S的值减1,即S.value=S.value-1;
②如果S.value≥0,则该进程继续执行;否则该进程置为等待状态,排入等待队列。
**V(S):**①将信号量S的值加1,即S.value=S.value+1;
②如果S.value>0,则该进程继续执行;否则释放S.L中第一个的等待进程。说明:
- S.value代表可用的资源数目,当它的值大于0时,表示当前可用资源的数量;当它的值小于0时,其绝对值表示等待使用该资源的进程个数。
- 一次P操作意味着请求分配一个单位资源,因此S.value减1,当S.value<0时,表示已经没有可用资源,请求者必须等待别的进程释放该类资源,它才能运行下去。
- 而执行一次V操作意味着释放一个单位资源,因此S.value加1;若S≤0,表示有某些进程正在等待该资源,因此要唤醒一个等待状态的进程,使之运行下去。
进程P1 ... P(S); 临界区; V(S); ...-
例子:统计随机数分步(随机产生1000个[0-20)之间的整数,统计每个数字出现的频率)
/*无临界区*/ #include<iostream> #include<cstdlib> #include<omp.h> using namespace std; int main() { int histogram[10000]; #pragma omp parallel for for(int i=0; i<1000; ++i){ int value = rand()%20; histogram[value]++; } int total = 0; for(int i = 0; i < 20; i++){ total += histogram[i]; cout<<histogram[i]<<" "; } cout<<endl<<"total: "<<total<<endl; return 0; }/*有临界区*/ #include<iostream> #include<cstdlib> #include<omp.h> using namespace std; int main() { int histogram[20]={0}; #pragma omp parallel for for(int i=0; i<1000; ++i){ int value = rand()%20; #pragma omp critical { histogram[value]++; } } int total = 0; for(int i = 0; i < 20; i++){ total += histogram[i]; cout<<histogram[i]<<" "; } cout<<endl<<"total: "<<total<<endl; return 0; }yang@yang-virtual-machine:~/桌面/openmp$ vim sjswljq.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp sjswljq.cpp -o sjsw.out yang@yang-virtual-machine:~/桌面/openmp$ ./sjsw.out 43 50 53 48 52 45 48 48 56 50 64 45 46 49 45 44 52 58 48 56 total: 1000 yang@yang-virtual-machine:~/桌面/openmp$ vim sjswljq.cpp yang@yang-virtual-machine:~/桌面/openmp$ vim sjsljq.cpp yang@yang-virtual-machine:~/桌面/openmp$ g++ -fopenmp sjsljq.cpp -o sjsy.out yang@yang-virtual-machine:~/桌面/openmp$ ./sjsy.out 43 50 53 48 52 45 48 48 56 50 64 45 46 49 45 44 52 58 48 56 total: 1000
线程多的时候可能出现:
-
无临界区输出:
25 31 26 34 40 47 24 29 44 44 31 26 41 38 32 45 26 54 45 27 total: 709 -
有临界区输出:
60 47 28 54 52 50 33 56 44 53 61 58 43 47 52 54 50 52 53 53 total: 1000
-
-
原子(atomic)操作
-
#pragma omp atomic -
保证对内存的读写更新等操作在同一时间只能被一个线程执行
- 常用来做计数器、求和等
-
原子操作通常比临界区执行更快
- 不需要阻塞其他线程
-
临界区的作用范围更广,能够实现的功能更复杂
#pragma omp parallel for for(int i=0; i<1000; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++;
-
其他同步机制
-
栅障(barrier)
-
#pragma omp barrier -
在栅障点处同步所有线程
- 先运行至栅障点处的线程必须等待其他线程
- 常用来等待某部分任务完成再开始下一部分任务
- 每个并行区域的结束点默认自动同步线程
#pragma omp parallel { function_A() #pragma omp barrier function_B(); }[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3OJOjU0H-1676586121403)(D:\学习学习活动活动\超算第三次考核\图片\栅障.png)]
-
并行随机数统计及并行求和
int total = 0; #pragma omp parallel num_threads(20) { for(int i=0; i<50; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++; } int thread = omp_get_thread_num(); #pragma omp atomic/*求和时可能其他线程还没完成统计*/ total += histogram[thread]; }int total = 0; #pragma omp parallel num_threads(20) { for(int i=0; i<50; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++; } #pragma omp barrier/*使用栅障同步线程*/ int thread = omp_get_thread_num(); #pragma omp atomic total += histogram[thread]; }结果:
yang@yang-virtual-machine:~/桌面/openmp$ vim test5.c yang@yang-virtual-machine:~/桌面/openmp$ gcc -fopenmp test5.c -o test5.out yang@yang-virtual-machine:~/桌面/openmp$ ./test5.out total=520 yang@yang-virtual-machine:~/桌面/openmp$ vim test6.c yang@yang-virtual-machine:~/桌面/openmp$ gcc -fopenmp test6.c -o test6.out yang@yang-virtual-machine:~/桌面/openmp$ ./test6.out total=1000 -
下列两段代码结果是否相同?相同
int total = 0; #pragma omp parallel num_threads(20) { for(int i=0; i<50; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++; } #pragma omp barrier int thread = omp_get_thread_num(); #pragma omp atomic total += histogram[thread]; } /*结果由上面可知:total=1000*/int total = 0; #pragma omp parallel num_threads(20) { #pragma omp for for(int i=0; i<1000; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++; } int thread = omp_get_thread_num(); #pragma omp atomic total += histogram[thread]; } /*结果是total=1000*/
-
singal&mater
-
#pragma omp single{}-
用于保证{}内的代码由一个线程完成
-
常用于输入输出或初始化
-
由第一个执行至此处的线程执行
-
同样会产生一个隐式栅障
- 可由
#pragma omp single nowait去除
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y6YWU8dg-1676586121403)(D:\学习学习活动活动\超算第三次考核\图片\single.png)]
- 可由
-
-
#pragma omp master{}-
与single相似,但指明由主线程执行
-
与使用IF的条件并行等价
#pragma omp parallel IF(omp_get_thread_num() == 0) nowait- 默认不产生隐式栅障
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YcGOA5hM-1676586121403)(D:\学习学习活动活动\超算第三次考核\图片\master.png)]
-
在下面代码中与atomic结果相同
int total = 0; #pragma omp parallel { #pragma omp for for(int i=0; i<1000; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++; } /*#pragma omp master { for(int i=0; i<20; ++i){ total += histogram[i]; } }*/ //两段结果相同 /*int thread = omp_get_thread_num(); #pragma omp atomic total += histogram[thread];*/ }
-
并行Reduction
-
指明如何将线程局部结果汇总
-
如
#pragma omp for reduction(+: total) -
支持的操作:
+, -, *, & , |, && and || -
int total = 0; #pragma omp parallel { #pragma omp for for(int i=0; i<1000; ++i){ int value = rand()%20; #pragma omp atomic histogram[value]++; } #pragma omp for reduction(+: total) for(int i=0; i<20; ++i){ total += histogram[i]; } }会造成冲突的数据是
total,我们要对total执行的操作是+,所以在使用Reduction时,我们声明类似为:reduction(+: total)。reduction执行过程:
1.fork线程并分配任务
2.每一个线程定义一个私有变量
omp_priv(同private)3.各个线程执行计算
4.所有
omp_priv和omp_in一起顺序进行 reduction,写回原变量
-
(5)变量作用域
变量作用域
-
OpenMP与串行程序的作用域不同
串行是最一般的情况,程序会按顺序执行每个任务,效率往往十分低下。
-
OpenMP中必须指明变量为shared或private
- Shared:变量为所有线程所共享
- 并行区域外定义的变量默认为shared
- Private:变量为线程私有,其他线程无法访问
- 并行区域内定义的变量默认为private
- 循环计数器默认为private
int histogram[20];/*shared*/ init_histogram(histogram); int total = 0;/*shared*/ int i, j; #pragma omp parallel for for(i=0; i<1000; ++i){/*循环计数器i为private!*/ int value = rand()%20;/*private*/ #pragma omp atomic histogram[value]++; for(j=0; j<1000; ++j){/*循环计数器j为private!*/ … } } - Shared:变量为所有线程所共享
-
-
显式作用域定义
-
显式指明变量的作用域
-
shared(var):指明变量var为shared -
default(none/shared/private)- 指明变量的默认作用域
- 如果为none则必须指明并行区域内每一变量的作用域
int a, b = 0, c; #pragma omp parallel default(none) shared(b) { b += a; } //error: variable 'a' must have explicitly specified data sharing attributes -
private(var):指明变量var为private-
int i = 10; #pragma omp parallel for private(i) for (int j=0; j<4; ++j) { printf("Thread %d: i = %d\n", omp_get_thread_num(), i); } printf("i = %d\n", i); -
输出:
Thread 0: i = 1 Thread 1: i = 0 Thread 3: i = 0 Thread 2: i = 0 i = 10
-
-
firstprivate(var):指明变量var为private,同时表明该变量使用master thread中变量值初始化。-
int i = 10; #pragma omp parallel for firstprivate(i) for (int j=0; j<4; ++j) { printf("Thread %d: i = %d\n", omp_get_thread_num(), i); } printf("i = %d\n", i); -
输出:
Thread 0: i = 10 Thread 3: i = 10 Thread 2: i = 10 Thread 1: i = 10 i = 10
-
-
lastprivate(var):指明变量var为private,同时表明结束后一层迭代将结果赋予该变量。-
int i = 10; #pragma omp parallel for lastprivate(i) for (int j=0; j<4; ++j) { printf("Thread %d: i = %d\n", omp_get_thread_num(), i); } printf("i = %d\n", i); -
输出:
Thread 0: i = 1 Thread 3: i = 0 Thread 1: i = 0 Thread 2: i = 0 i = 0
-
-
数据并行与任务并行
-
数据并行:同样指令作用在不同数据上,前述例子均为数据并行。
-
任务并行:线程可能执行不同任务
-
#pragma omp sections -
每个section由一个线程完成
-
同样有隐式栅障(可使用nowait去除)
-
#pragma omp parallel #pragma omp sections { #pragma omp section task_A(); #pragma omp section task_B(); #pragma omp section task_C(); } //or #pragma omp parallel sections { #pragma omp section task_A(); #pragma omp section task_B(); #pragma omp section task_C(); } -

sections构造:
将并行区内的代码块划分为多个section分配执行
可以搭配parallel合成为parallel sections构造
每个section由一个线程执行
- 线程数大于section数目:部分线程空闲
- 线程数小于section数目:部分线程分配多个section
-
(6)线程调度
线程调度
-
当迭代数多于线程数时,需要调度线程
-
某些线程将执行多个迭代
-
#pragma omp parallel for schedule(type,[chunk size])- type包括static、dynamic、guided、auto、runtime
- 默认为static
#include<stdio.h> #include<omp.h> int main() { #pragma omp parallel for num_threads(4) for (int i=0; i<6; ++i) { int thread = omp_get_thread_num(); printf("thread %d\n", thread); } return 0; }thread 0 thread 0 thread 2 thread 3 thread 1 thread 1
-
-
-
Static调度:调度由编译器静态决定
-
#pragma omp parallel for schedule(type,[chunk size]) -
每个线程轮流获取 chunk size 个迭代任务
-
默认chunk size 为 n/threads(没有指定时)

-
线程的负载可能不均匀

-
-
Dynamic调度
- 在运行中动态分配任务
- 迭代任务依然根据chunk size划分成块
- 线程完成一个chunk后向系统请求下一个chunk
- 默认chunk size 为1
-
Guided调度
- 与dynamic类似
- 但分配的chunk大小在运行中递减
- 最小不能小于chunk size参数
-
Auto(编译器决定策略)与 runtime(由环境变量指定策略
OMP_SCHEDULE)- – “Note that keywords auto and runtime aren’t adequate.”
-
总的来说
auto和runtime其实最后都是在static,dynamic,guided中挑选一个策略。
OpenMP陷阱
- 当#pragma指令无法为编译器理解时 – 不会报错!
- 如
#pragma omg parallel不会报错
openmp小结
-
软硬件环境
- CPU多线程并行库
- 编译器指令、库函数、环境变量
- CPU多线程并行库
-
基本语法
#pragma omp construct [clause [clause]...]{structured block}- 指明并行区域:
#pragma omp parallel - 循环:
#pragma omp (parallel) for - 嵌套:
omp_set_nested(1) - 常用函数:
omp_get_thread_num();num_threads(int); - 同步:
#pragma omp critical/atomic/barrier、nowait - 变量作用域:
default(none/shared/private),shared(),private(),firstprivate(),last private() - 调度:
schedule(static/dynamic/guided, [chunk_size])
-
常用库函数:
// 设置并行区运行的线程数 void omp_set_num_threads(int) // 获得并行区运行的线程数 int omp_get_num_threads(void) // 获得线程编号 int omp_get_thread_num(void) // 获得openmp wall clock时间(单位秒) double omp_get_wtime(void) // 获得omp_get_wtime时间精度 double omp_get_wtick(void) -
collapse(n):应用于n重循环,合并(展开)循环- 将多重循环展开到第n重
- 待展开的循环之间必须没有依赖关系
- 展开后的顺序与串行顺序一致
- 相当于增大外层循环的次数,有助于schedule
-
ordered:声明有潜在的顺序执行部分-
使用
#pragma omp ordered标记顺序执行代码(搭配使用) -
ordered区内的语句任意时刻仅由最多一个线程执行
-
#pragma omp parallel for [clauses…] ordered//说明并行区中有顺序执行的部分 { … //并行执行1 #pragma omp ordered {…} //顺序执行 … //并行执行2 } -
orderd加的位置不对,可能导致并行失效
-
硬件的内存模型

一些例子
#pragma omp parallel num_threads(8)
{
int tid = omp_get_thread_num();
int num_threads = omp_get_num_threads();
#pragma omp for ordered
for (int i = 0; i < num_threads; i++) {
// do something
// #pragma omp ordered
// #pragma omp critical
std::cout << "Hello from thread " << tid << std::endl;
}
}
#no synchronization
Hello from thread 0Hello from thread
Hello from thread 4
Hello from thread Hello from thread Hello from thread 7
Hello from thread 1
2
Hello from thread 5
6
3
# ordered
Hello from thread 0
Hello from thread 1
Hello from thread 2
Hello from thread 3
Hello from thread 4
Hello from thread 5
Hello from thread 6
Hello from thread 7
# critical
Hello from thread 5
Hello from thread 4
Hello from thread 1
Hello from thread 7
Hello from thread 6
Hello from thread 3
Hello from thread 2
Hello from thread 0
#include <iostream>
#include <omp.h>
int main() {
#pragma omp parallel num_threads(8)
{
int tid = omp_get_thread_num();
int num_threads = omp_get_num_threads();
int max_threads = omp_get_max_threads();
printf("Hello from thread %d of %d. max= %d\n", tid, num_threads,max_threads);
}
return 0;
}
/*输出:
Hello from thread 1 of 8. max= 2
Hello from thread 7 of 8. max= 2
Hello from thread 6 of 8. max= 2
Hello from thread 5 of 8. max= 2
Hello from thread 4 of 8. max= 2
Hello from thread 3 of 8. max= 2
Hello from thread 2 of 8. max= 2
Hello from thread 0 of 8. max= 2
*/
for (int i = 0; i < N; i++) {
for (int j = i; j < N; j++) {
double sum = 0;
for (int k = 0; k < N; k++) {
sum += A[i * N + k] * A[j * N + k];
}
B[i * N + j] = sum;
B[j * N + i] = sum;
}
}
#pragma omp parallel for schedule(runtime)
for (int i = 0; i < N; i++) {
for (int j = i; j < N; j++) {
double sum = 0;
for (int k = 0; k < N; k++) {
sum += A[i * N + k] * A[j * N + k];
}
B[i * N + j] = sum;
B[j * N + i] = sum;
}
}
# export OMP_SCHEDULE="dynamic"
size: 1024
sequence time: 1.46233
omp time: 0.133192
# export OMP_SCHEDULE="static"
size: 1024
sequence time: 1.47874
omp time: 0.219114
//串行
for(int i=0;i<N;i++)
{
for(int j =0; j <N;j++)
{
x_seq[i] +=A[i* N +j]*b[j];
}
}
//正确并行
#pragma omp parallel for
for(int i;i<N;i++)
{
double tmp=0;
for(int j=0;j<N;j++)
{
tmp+=A[i*N+j]*b[j];
}
x_omp[i]=tmp;
}
//错误并行
//不同核心对同一cache line的同时读写会造成严重的冲突,导致该级缓存失效
#pragma omp parallel for
for(int i=0;i<N;i++)
{
for(int j=0;j<N;j++)
{
x_omp_fs[i]+=A[i*N+j]*b[j];
}
}
yang@yang-virtual-machine:~/桌面/openmp$ ./fs.out
size: 16384
sequence time: 0.797457
simple omp time: 0.384088
false sharing time: 0.532769
yang@yang-virtual-machine:~/桌面/openmp$ ./fs.out
size: 16384
sequence time: 1.00921
simple omp time: 0.407889
false sharing time: 0.502701
for(int i=0;i<N;i++)
{
ans_seq +=b[i]*b[i];
}
ans_seq= sqrt(ans_seq);
#pragma omp parallel for reduction(+ : ans_omp)
for(int i=0;i<N;i++)
{
ans_omp +=b[i]*b[i];
}
ans_omp= sqrt(ans_omp);
#pragma omp parallel for
for(int i=0;i<N;i++)
{
#pragma omp atomic
// #pragma omp critical
ans_omp_sync +=b[i]*b[i];
}
ans_omp_sync= sqrt(ans_omp_sync);
yang@yang-virtual-machine:~/桌面$ ./vector.out
size: 33554432
sequence result: 3344.45
omp result: 3344.45
omp sync result: 3344.45
sequence time: 0.128534
omp time: 0.0634244
omp sync time: 1.71575
yang@yang-virtual-machine:~/桌面$ ./vector.out
size: 33554432
sequence result: 3344.56
omp result: 3344.56
omp sync result: 3344.56
sequence time: 0.126461
omp time: 0.0629478
omp sync time: 2.34646
yang@yang-virtual-machine:~/桌面$ ./vector.out
size: 33554432
sequence result: 3344.52
omp result: 3344.52
omp sync result: 3344.52
sequence time: 0.126658
omp time: 0.0629643
omp sync time: 1.59414
//下面的循环无法正确执行
#pragma omp parallel for
for(k=0;k<100;k++)
{ x=array[k];
array[k]=do_work(x);
}
//正确的方式
//1.直接声明为私有变量
#pragma omp parallel for private(x)
for(k=0;k<100;k++)
{ x=array[k];
array[k]=do_work(x);
}
//2.在parallel 结构中声明变量,这样的变量是++++++++私有的
#pragma omp parallel for
for(k=0;k<100;k++)
{
int x;
x=array[k];
array[k]=do_work(x);
}
超算习堂-OpenMP编程实训
OpenMP介绍
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
#pragma omp parallel for
for (i = 0; i < 10; i++) {
printf("i = %d\n", i);
}
return 0;
}
fork/join并行执行模式的概念
#include <stdio.h>
#include <time.h>
void foo()
{
int cnt = 0;
clock_t t1 = clock();
int i;
for (i = 0; i < 1e8; i++) {
cnt++;
}
clock_t t2 = clock();
printf("Time = %ld\n", t2 - t1);
}
int main(int argc, char* argv[])
{
clock_t t1 = clock();
int i;
#pragma omp parallel for
for (i = 0; i < 2; i++) {
foo();
}
clock_t t2 = clock();
printf("Total time = %ld\n", t2 - t1);
return 0;
}
/*warning: format '%d' expects argument of type 'int', but argument 2 has type 'clock_t' {aka 'long int'}*/
#没有并行
Time = 321759
Time = 320960
Total time = 642780
#并行
Time = 717205
Time = 719696
Total time = 761560
parallel指令的用法
#pragma omp parallel [for | sections] [子句[子句]…] { /*并行部分*/ }
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
#pragma omp parallel num_threads(6)
{
printf("Thread: %d\n", omp_get_thread_num());
}
return 0;
}
for 指令的使用方法
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
#pragma omp parallel
{
int i, j;
#pragma omp for
for (i = 0; i < 5; i++)
printf("i = %d\n", i);
#pragma omp for
for (j = 0; j < 5; j++)
printf("j = %d\n", j);
}
return 0;
}
sections和section指令的用法
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
#pragma omp parallel sections
{
#pragma omp section
printf("Section 1 ThreadId = %d\n", omp_get_thread_num());
#pragma omp section
printf("Section 2 ThreadId = %d\n", omp_get_thread_num());
#pragma omp section
printf("Section 3 ThreadId = %d\n", omp_get_thread_num());
#pragma omp section
printf("Section 4 ThreadId = %d\n", omp_get_thread_num());
}
return 0;
}
private 子句的用法
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i = 20;
#pragma omp parallel for private(i)
for (i = 0; i < 10; i++)
{
printf("i = %d\n", i);
}
printf("outside i = %d\n", i);
return 0;
}
/*private()在for的后面*/
firstprivate子句的用法
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int t = 20, i;
#pragma omp parallel for firstprivate(t)
for (i = 0; i < 5; i++)
{
t += i;
printf("t = %d\n", t);
}
printf("outside t = %d\n", t);
return 0;
}
lastprivate子句的用法
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int t = 20, i;
#pragma omp parallel for firstprivate(t), lastprivate(t)
for (i = 0; i < 5; i++)
{
t += i;
printf("t = %d\n", t);
}
printf("outside t = %d\n", t);
return 0;
}
threadprivate子句的用法
threadprivate子句可以将一个变量复制一个私有的拷贝给各个线程,即各个线程具有各自私有的全局对象。
#include <stdio.h>
#include <omp.h>
int g = 0;
#pragma omp threadprivate(g)
int main(int argc, char* argv[])
{
int t = 20, i;
#pragma omp parallel
{
g = omp_get_thread_num();
}
#pragma omp parallel
{
printf("thread id: %d g: %d\n", omp_get_thread_num(), g);
}
return 0;
}
thread id: 1 g: 1
thread id: 2 g: 2
thread id: 3 g: 3
thread id: 0 g: 0
shared子句的用法
在并行部分进行写操作时,要求共享变量进行保护,否则不要随便使用共享变量,尽量将共享变量转换为私有变量使用。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int t = 20, i;
#pragma omp parallel for shared(t)
for (i = 0; i < 10; i++)
{
if (i % 2 == 0)
t++;
printf("i = %d, t = %d\n", i, t);
}
printf("\nt = %d\n", t);
return 0;
}
/*并行完t=23、24、25*/
reduction子句的用法
reduction(operator:list)
支持的操作:
+, -, *, & , |, && and ||reduction子句可以对一个或者多个参数指定一个操作符,然后每一个线程都会创建这个参数的私有拷贝,在并行区域结束后,迭代运行指定的运算符,并更新原参数的值。私有拷贝变量的初始值依赖于redtution的运算类型。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i, sum = 10;
#pragma omp parallel for reduction(+: sum)
for (i = 0; i < 10; i++)
{
sum += i;
printf("%d\n", sum);
}
printf("sum = %d\n", sum);
return 0;
}
copyin子句的用法
copyin子句可以将主线程中变量的值拷贝到各个线程的私有变量中,让各个线程可以访问主线程中的变量。
copyin的参数必须要被声明称threadprivate,对于类的话则并且带有明确的拷贝赋值操作符。#pragma omp parallel for copyin(g)
#include <stdio.h>
#include <omp.h>
int g = 0;
#pragma omp threadprivate(g) /*copyin的参数必须要被声明称threadprivate*/
int main(int argc, char* argv[])
{
int i;
#pragma omp parallel for
for (i = 0; i < 4; i++)
{
g = omp_get_thread_num();
printf("thread %d, g = %d\n", omp_get_thread_num(), g);
}
printf("global g: %d\n", g);
#pragma omp parallel for copyin(g)
for (i = 0; i < 4; i++)
printf("thread %d, g = %d\n", omp_get_thread_num(), g);
return 0;
}
static
当parallel for没有带schedule时,大部分情况下系统都会默认采用static调度方式。假设有n次循环迭代,t个线程,那么每个线程大约分到n/t次迭代。这种调度方式会将循环迭代均匀的分布给各个线程,各个线程迭代次数可能相差1次。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
#pragma omp parallel for schedule(static)
for (i = 0; i < 10; i++)
{
printf("i = %d, thread %d\n", i, omp_get_thread_num());
}
return 0;
}
size参数的用法
最小迭代次数。
#pragma omp parallel for schedule(static, 3)
dynamic子句指令的用法
#pragma omp parallel for schedule(dynamic)
omp_get_num_procs
返回调用函数时可用的处理器数目。
omp_get_num_threads
返回当前并行区域中的活动线程个数,如果在并行区域外部调用,返回1。
omp_get_thread_nun
返回当前的线程号。
omp_set_num_threads
设置进入并行区域时,将要创建的线程个数。
omp_in_parallel
可以判断当前是否处于并行状态
函数原型int omp_in_parallel();
是1,否0
omp_get_max_threads
该函数可以用于获得最大的线程数量,根据OpenMP文档中的规定,这个最大数量是指在不使用num_threads的情况下,OpenMP可以创建的最大线程数量。需要注意的是这个值是确定的,与它是否在并行区域调用没有关系。
OpenMP中互斥锁的用法
Openmp中有提供一系列函数来进行锁的操作,一般来说常用的函数的下面4个
void omp_init_lock(omp_lock*) 初始化互斥锁
void omp_destroy_lock(omp_lock*) 销毁互斥锁
void omp_set_lock(omp_lock*) 获得互斥锁
void omp_unset_lock(omp_lock*) 释放互斥锁
#include <stdio.h>
#include <omp.h>
static omp_lock_t lock;
int main(int argc, char* argv[])
{
int i;
omp_init_lock(&lock);
#pragma omp parallel for
for (i = 0; i < 5; ++i)
{
omp_set_lock(&lock);
printf("%d+\n", omp_get_thread_num());
printf("%d-\n", omp_get_thread_num());
omp_unset_lock(&lock);
}
omp_destroy_lock(&lock);
return 0;
}
/*初始化->获得->释放->销毁*/
omp_test_lock
与互斥锁的相关的函数,用来尝试获得锁。可以看作是omp_set_lock的非阻塞版本。
#include <stdio.h>
#include <omp.h>
static omp_lock_t lock;
int main(int argc, char* argv[])
{
int i;
omp_init_lock(&lock);
#pragma omp parallel for
for (i = 0; i < 5; ++i)
{
if (omp_test_lock(&lock))
{
printf("%d+\n", omp_get_thread_num());
printf("%d-\n", omp_get_thread_num());
omp_unset_lock(&lock);
}
else
{
printf("fail to get lock\n");
}
}
omp_destroy_lock(&lock);
return 0;
}
omp_set_dynamic
该函数可以设置是否允许在运行时动态调整并行区域的线程数。
void omp_set_dynamic(int)
参数为0时,动态调整被禁用。
当参数为非0值时,系统会自动调整线程以最佳利用系统资源。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
omp_set_dynamic(1);
#pragma omp parallel for
for (i = 0; i < 4; i++)
{
printf("%d\n", omp_get_thread_num());
}
return 0;
}
omp_get_dynamic
该函数可以返回当前程序是否允许在运行时动态调整并行区域的线程数。
函数原型:int omp_get_dynamic()
当返回值为非0时表示允许系统动态调整线程。
当返回值为0时表示不允许。
#include <stdio.h>
#include <omp.h>
int main(int argc, char* argv[])
{
int i;
printf("%d\n", omp_get_dynamic());
omp_set_dynamic(1);
#pragma omp parallel for
for (i = 0; i < 4; i++)
{
printf("%d\n", omp_get_dynamic());
}
return 0;
}














 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









