







学习爬虫个人的意见是直接实战效果会很好 不要等全学完requests ,正则表达式,BeautifulSoup等再来实际操作。其实很多实战我们并不会用到requests库,BeautifulSoup,正则表达式的全部知识。全部学懂记下来再去实战会很难。不如跟着我直接就该是写爬虫吧。遇到什么问题我们再一一解决。
1 导入各种要用到的库,具体什么用法下面会讲
import re
import os
import time
import random
import requests
from bs4 import BeautifulSoup
# 这几个库是我们自己写的 后面会教你写 这里我们先导入
from packages.save import save2 我们加个header 表头 让服务器以为我们是一个真的浏览器 才会返回给我们图片数据
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
注意:每个浏览器的表头不一样。用你自己浏览器的表头就行。
这里我用的是谷歌浏览器,这里示范给你们看。
你现在在阅读我的文章,直接F12 打开开发者工具。

随便点击Name下面一个 这里我们点击第一个qton_csdn?viewmode=list 右边边下拉到最后看到
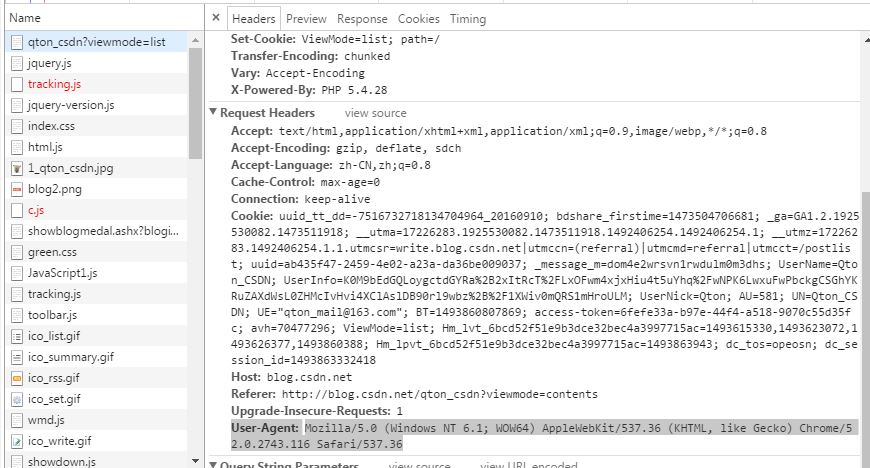
3 写好表头 我们来定义一个函数来获取一个网址的HTML 我们定义为def get_html(url,timeout=2): 这里有两个参数,url 为我们要爬取网页的网址,timeout=2 即两秒内服务器如果无返回数据我们断掉此次获取不然程序一直等下去。
代码:
def get_html(url,timeout=2):
try:
return requests.get(url,header,timeout=3)
except:
# 换表头,换ip
print('换表头,使用代理!')
time.sleep(random.randrange(1,11))
return requests.get(url,headers=get_random_header(),proxies={'http':get_random_ip()},timeout=2)
excep:代码
我们先随机停顿1到10秒 用到 time库的time.sleep 函数 random库的 random.randrange(1,11) 随机取1-11 的数 不包括11
接着我们换个表头,用我们收集来的其它浏览器的表头去获取HTML,再使用一下代理:
这里我们需要在你写爬虫代码的文件下创建一个包(这里涉及到创建函数包的问题),命名为packages,在packages下创建代码为header.py和 ip.py ip池。
header.py下代码为:
import random
headers_list=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def get_random_header():
UA=random.choice(headers_list)
header={'User-Agent':UA}
return header
from packages.header import get_random_header
def get_random_header()的作用是调用一次他的时候随机返回一个表头header
ip.py下面代码为:
import re
import random
import requests
def get_random_ip():
try:
html=requests.get('http://haoip.cc/tiqu.htm')
ip_list=re.findall(r'([\d].*?)<br/>',html.text)
ip=random.choice(ip_list)
return ip
except:
print('get_random_ip 出错!')
return None
下面给出所有代码,先自己领悟领悟。
全部代码:
1 主代码:爬取-天极.py
import re
import os
import time
import random
import requests
from bs4 import BeautifulSoup
# 这几个库是我们自己写的 后面会教你写 这里我们先导入
from packages.save import save
from packages.ip import get_random_ip
from packages.header import get_random_header
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
def get_html(url,timeout=2):
try:
return requests.get(url,header,timeout=3)
except:
# 换表头,换ip
print('换表头,使用代理!')
time.sleep(random.randrange(1,11))
return requests.get(url,headers=get_random_header(),proxies={'http':get_random_ip()},timeout=2)
def main():
for big_page in range(1,8):
all_url = 'http://pic.yesky.com/c/6_20471_%s.shtml'%big_page
big_page_html=get_html(all_url)
Soup = BeautifulSoup(big_page_html.text, 'lxml')
all_a = Soup.find('div', class_='lb_box').find_all('a')
for a in all_a:
# 取出 title url
title = a.get_text()
href = a['href']
# time.sleep(0.5)
# 创建以 title 为名的文件夹
path = str(title).strip()
try:
os.makedirs(os.path.join("F:\pic.yesky", path))
os.chdir("F:\pic.yesky\\"+path)
print(href)
except:
# print('file existed!')
time.sleep(0.1)
continue
# 查看文件夹有几页图片
try:
html = get_html(href)
except:
print('出错')
continue
html_Soup = BeautifulSoup(html.text,'lxml')
max_page = html_Soup.find_all('span')[10].get_text()
F_MAX=re.compile(r'/([0-9]*)')
# 取出文件夹每页的图片
try:
max_page=F_MAX.findall(max_page)[0]
a=int(max_page)
except:
continue
for page in range(2,a+1):
url_photo=href.replace('.shtml','_%s.shtml'%page)
# print('图片页面URL',url_photo)
try:
img_html=get_html(url_photo)
except:
continue
img_Soup=BeautifulSoup(img_html.text,'lxml')
try:
url_photo=img_Soup.find('div',class_='l_effect_img_mid').find('img')['src']
img=get_html(url_photo)
except:
continue
# 保存
try:
f=open(str(page)+'.jpg','wb')
f.write(img.content)
f.close()
# print(url_photo)
except:
print('保存出错')
continue
#一个文件夹结束停顿
time.sleep(1)
'''
# 保存
try:
f=open(str(page)+'.jpg','wb')
f.write(img.content)
f.close()
print(url_photo)
except:
print('保存出错')
continue
#一个文件夹结束停顿
time.sleep(2)
'''
if __name__ == '__main__':
main()
2 packages包应放在 爬取-天极代码童文件下,如图:
packages 下创建 header.py ip.py save.py 三个代码 如图:
header.py下代码:
import random
headers_list=[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def get_random_header():
UA=random.choice(headers_list)
header={'User-Agent':UA}
return headerip.py下代码:
import re
import random
import requests
def get_random_ip():
try:
html=requests.get('http://haoip.cc/tiqu.htm')
ip_list=re.findall(r'([\d].*?)<br/>',html.text)
ip=random.choice(ip_list)
return ip
except:
print('get_random_ip 出错!')
return None
save.py下代码:
import urllib.request
from urllib.error import HTTPError
def save(url,name):
print(url,name)
try:
urllib.request.urlretrieve(url,'下载\\%s.jpg'%name)
print(name,'saving...')
except HTTPError as e:
print('读取错误!',e)
return None
except:
print('save 错误')
return None附上爬取http://www.mzitu.com 网站全部图片的代码:
import re
import os
import time
import random
import requests
from bs4 import BeautifulSoup
from packages.save import save
from packages.ip import get_random_ip
from packages.header import get_random_header
header = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
def get_html(url,timeout=2):
try:
return requests.get(url,header,timeout=3)
except:
# 换表头,换ip
print('换表头,使用代理!')
return requests.get(url,headers=get_random_header(),proxies={'http':get_random_ip()},timeout=2)
def main():
all_url = 'http://www.mzitu.com/all'
start_html = requests.get(all_url, headers=header)
Soup = BeautifulSoup(start_html.text, 'lxml')
all_a = Soup.find('div', class_='all').find_all('a')
for a in all_a:
# 取出 title url
title = a.get_text()
href = a['href']
# print(href)
# 创建以 title 为名的文件夹
path = str(title).strip()
try:
os.makedirs(os.path.join("F:\Scraping", path))
os.chdir("F:\Scraping\\"+path)
except:
# print('file existed!')
# time.sleep(0.1)
exit()
continue
# 查看文件夹有几页图片
try:
html = get_html(href)
except:
print('出错')
continue
html_Soup = BeautifulSoup(html.text,'lxml')
max_page = html_Soup.find_all('span')[10].get_text()
# 取出文件夹每页的图片
try:
a=int(max_page)
except:
continue
for page in range(1,a+1):
url_photo=href+'/%s'%page
try:
img_html=get_html(url_photo)
except:
continue
img_Soup=BeautifulSoup(img_html.text,'lxml')
try:
url_photo=img_Soup.find('div',class_='main-image').find('img')['src']
img=get_html(url_photo)
except:
continue
# 保存
try:
f=open(str(page)+'.jpg','wb')
f.write(img.content)
f.close()
print(url_photo)
except:
print('保存出错')
continue
#一个文件夹结束停顿
time.sleep(2)
if __name__ == '__main__':
main()














 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









