







一、查漏补缺复盘
1、python中zip()用法
应用举例
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x*w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
# 穷举法
w_list = []
mse_list = []
for w in np.arange(0.0, 4.1, 0.1):
print("w=", w)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
2、Tensor和tensor的区别
首先看下代码区别
>>> a=torch.Tensor([1,2])
>>> a
tensor([1., 2.])
>>> a=torch.tensor([1,2])
>>> a
tensor([1, 2])
- torch.Tensor()是python类,更明确地说,是默认张量类型
torch.FloatTensor()的别名,torch.Tensor([1,2])会调用Tensor类的构造函数__init__,生成单精度浮点类型的张量。 - 而
torch.tensor()仅仅是python函数:https://pytorch.org/docs/stable/torch.html torch.tensor
torch.tensor(data, dtype=None, device=None, requires_grad=False)
- 其中data可以是:list, tuple, NumPy ndarray, scalar和其他类型。
torch.tensor会从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor、torch.FloatTensor和torch.DoubleTensor。
3、计算图中的迭代取数
注意关注grad取元素规则
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0]) # w的初值为1.0
w.requires_grad = True # 需要计算梯度
def forward(x):
return x*w # w是一个Tensor
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l =loss(x,y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss
l.backward() # backward,compute grad for Tensor whose requires_grad set to True
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 权重更新时,注意grad也是一个tensor
w.grad.data.zero_() # after update, remember set the grad to zero
print('progress:', epoch, l.item()) # 取出loss使用l.item,不要直接使用l(l是tensor会构建计算图)
print("predict (after training)", 4, forward(4).item())
.data等于进tensor修改,.item()等于把数拿出来
- w是Tensor(张量类型),Tensor中包含data和grad,data和grad也是Tensor。grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
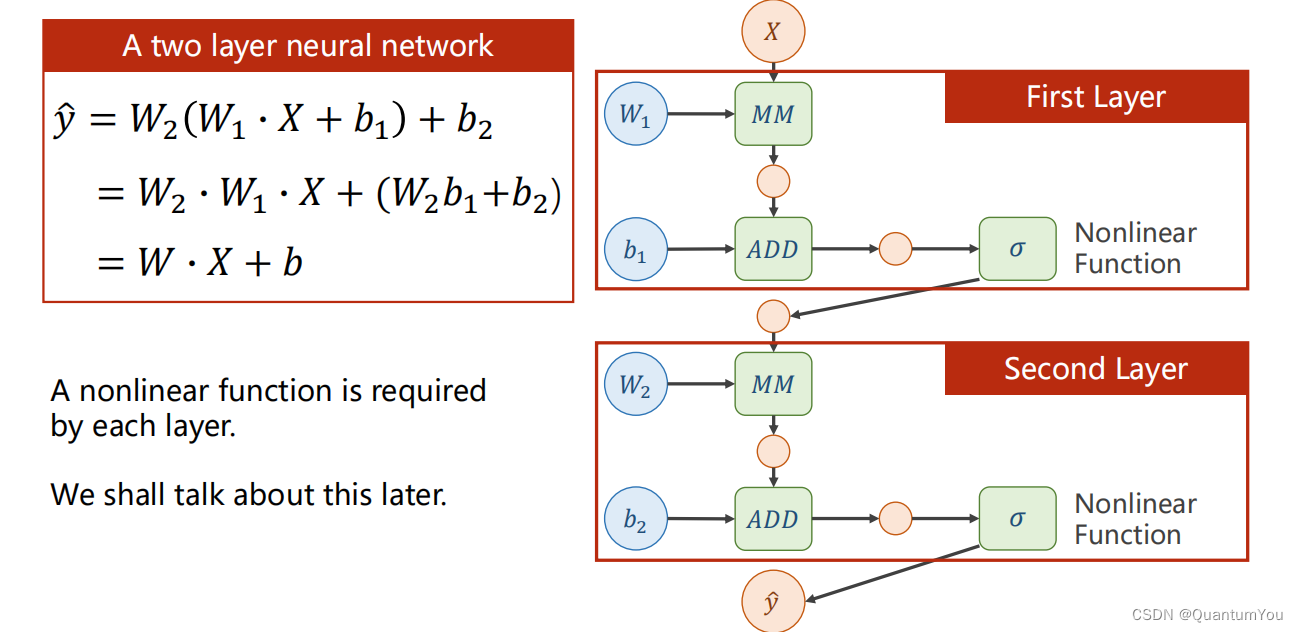
下面的 Linear(1,1 )是input1,output1


4、nn.Modlue及nn.Linear 源码理解
import torch
# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
# (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# construct loss and optimizer
# criterion = torch.nn.MSELoss(size_average = False)
criterion = torch.nn.MSELoss(reduction = 'sum')
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) # model.parameters()自动完成参数的初始化操作,这个地方我可能理解错了
# training cycle forward, backward, update
for epoch in range(100):
y_pred = model(x_data) # forward:predict
loss = criterion(y_pred, y_data) # forward: loss
print(epoch, loss.item())
optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zero
loss.backward() # backward: autograd,自动计算梯度
optimizer.step() # update 参数,即更新w和b的值
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
import torch
from torch import nn
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
output.size() # torch.Size([128, 30])
- nn.Module 是所有神经网络单元(neural network modules)的基类
pytorch在nn.Module中,实现了__call__方法,而在__call__方法中调用了forward函数。 - 首先创建类对象m,然后通过m(input)实际上调用__call__(input),然后__call__(input)调用
forward()函数,最后返回计算结果为:[ 128 , 20 ] × [ 20 , 30 ] = [ 128 , 30 ]

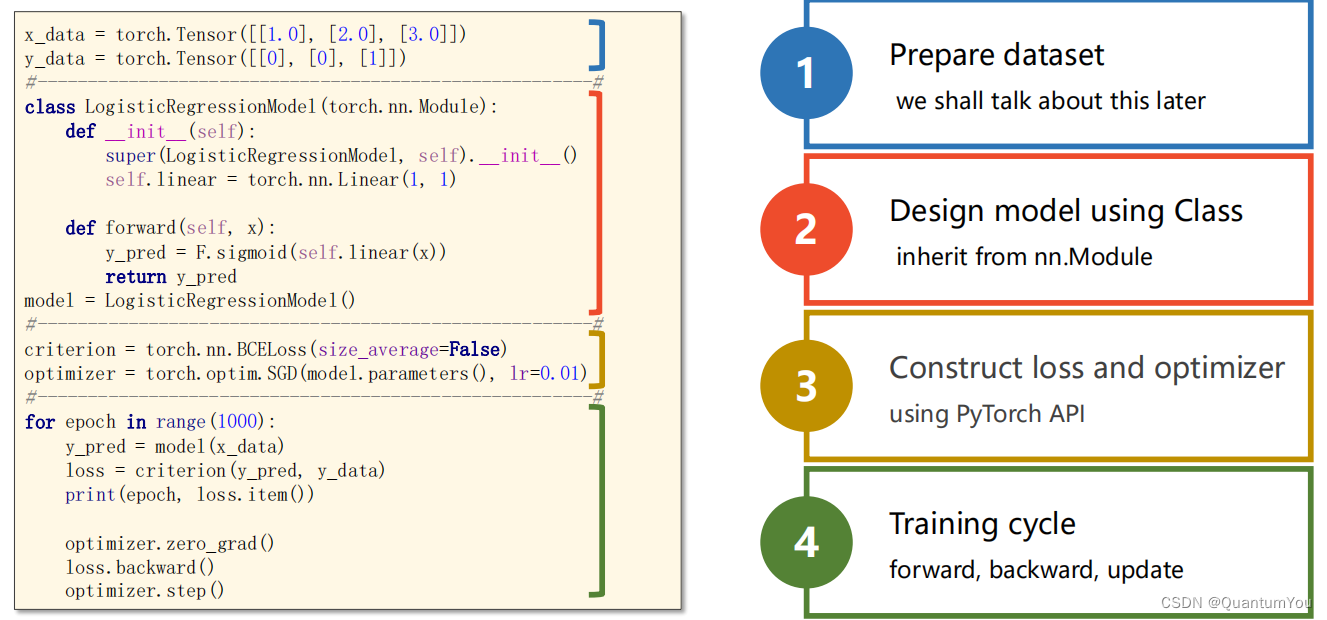
5、知识杂项思考列表
1、SGD单个样本进行梯度下降容易被噪声带来巨大干扰
2、矩阵求导理论书籍 matrix cookbook
3、前向传播是为了计算损失值,反向传播是为了计算梯度来更新模型的参数
6、KL散度初步理解
- KL散度(Kullback-Leibler divergence)是两个概率分布间差异的非对称性度量。参与计算的一个概率分布为真实分布,另一个为理论(拟合)分布,相对熵表示使用理论分布拟合真实分布时产生的信息损耗。
KL散度具有以下几个性质:
- 非负性:KL散度的值始终大于等于0,当且仅当两个概率分布完全相同时,KL散度的值才为0。
- 不对称性:KL散度具有方向性,即P到Q的KL散度与Q到P的KL散度不相等。
- 无限制性:KL散度的值可能为无穷大,即当真实分布中的某个事件在理论分布中的概率为0时,KL散度的值为无穷大。
KL散度的计算公式如下:
D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) D_{KL}(P||Q) = \sum_{i}P(i) \log \frac{P(i)}{Q(i)} DKL(P∣∣Q)=i∑P(i)logQ(i)P(i)
其中,(P)和(Q)分别为两个概率分布,(P(i))和(Q(i))分别表示在位置(i)处的概率值。当KL散度等于0时,表示两个概率分布完全相同;当KL散度大于0时,表示两个概率分布存在差异,且值越大差异越大。
- 在机器学习中,KL散度有广泛的应用,例如用于衡量两个概率分布之间的差异,或者用于优化生成式模型的损失函数等。此外,KL散度还可以用于基于KL散度的样本选择来有效训练支持向量机(SVM)等算法,以解决SVM在大型数据集合上效率低下的问题。
逻辑回归构造模板
二、处理多维特征的输入
1、逻辑回归模型流程
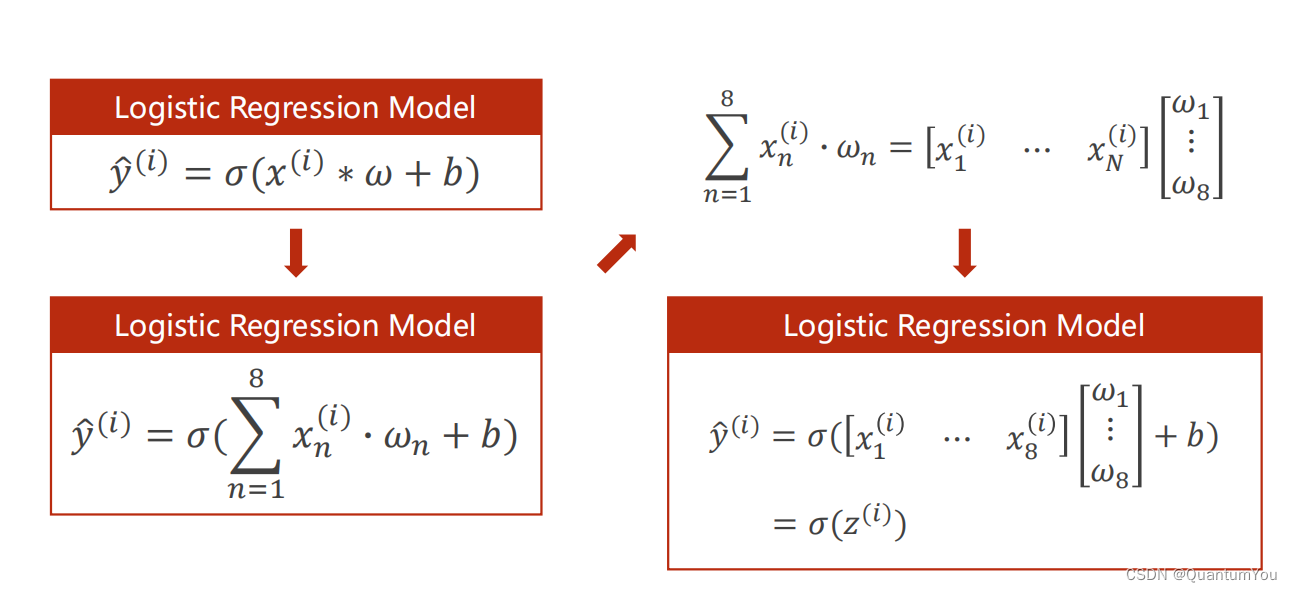
2、Mini-Batch (N samples)
在数学上转化为矩阵运算,转化为向量形式利于GPU进行并行运算

self.linear torch.nn.Linear (8,1)输入为8,输出为1
说明:
-
1、乘的权重(w)都一样,加的偏置(b)也一样。b变成矩阵时使用广播机制。神经网络的参数w和b是网络需要学习的,其他是已知的。
-
2、学习能力越强,有可能会把输入样本中噪声的规律也学到。我们要学习数据本身真实数据的规律,学习能力要有泛化能力。
-
3、该神经网络共3层;第一层是8维到6维的非线性空间变换,第二层是6维到4维的非线性空间变换,第三层是4维到1维的非线性空间变换。

-
4、本算法中
torch.nn.Sigmoid()将其看作是网络的一层,而不是简单的函数使用
torch.sigmoid、torch.nn.Sigmoid和torch.nn.functional.sigmoid的区别
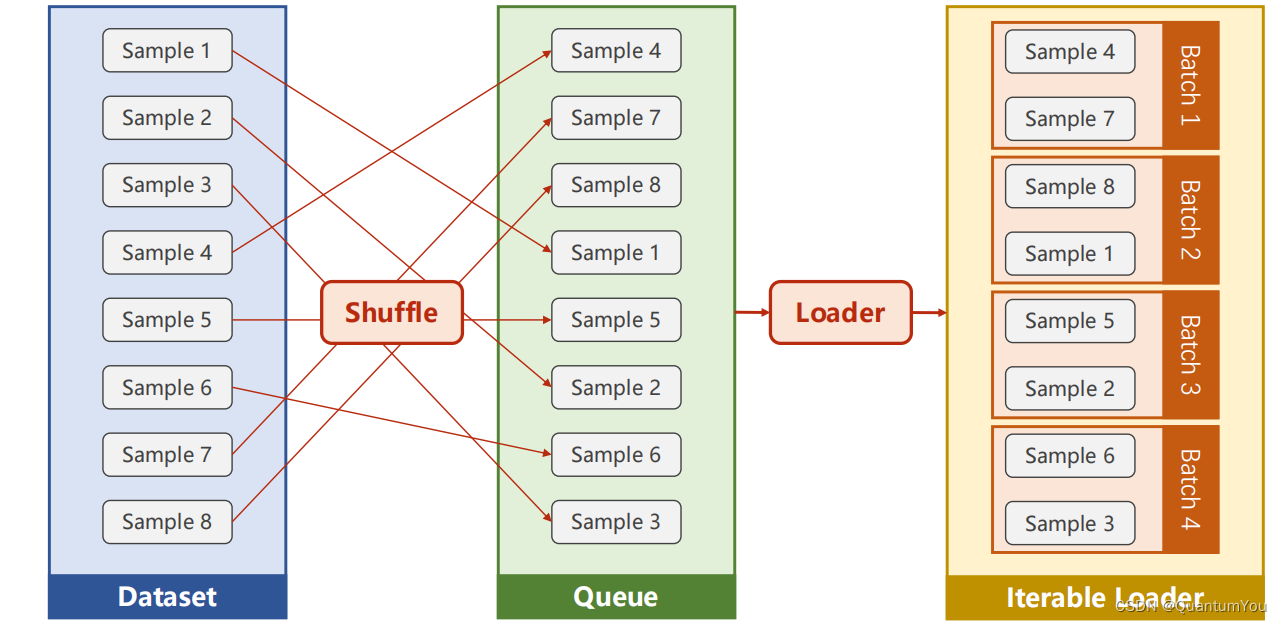
三、加载数据集
- DataLoader 主要加载数据集
说明:
-
1、DataSet 是抽象类,不能实例化对象,主要是用于构造我们的数据集
-
2、DataLoader 需要获取DataSet提供的索引[i]和len;用来帮助我们加载数据,比如说做shuffle(提高数据集的随机性),batch_size,能拿出Mini-Batch进行训练。它帮我们自动完成这些工作。DataLoader可实例化对象。
-
3、__getitem__目的是为支持下标(索引)操作
1、Python 魔法方法介绍
- 在Python中,有一些特殊的方法(通常被称为“魔法方法”或“双下划线方法”)是由Python解释器预定义的,它们允许对象进行某些特殊的操作或重载常见的运算符。这些魔法方法通常以双下划线(
__)开始和结束。
- 初始化方法:
__init__(self, ...)
在创建对象时自动调用,用于初始化对象的状态。
class MyClass:
def __init__(self, value):
self.value = value
- 字符串表示方法:
__str__(self)和__repr__(self)
用于定义对象的字符串表示。__str__用于在print函数中,而__repr__用于在repr函数中。
class MyClass:
def __init__(self, value):
self.value = value
def __str__(self):
return f"MyClass({
self.value})"
def __repr__(self):
return f"MyClass({
self.value})"
- 比较方法:如
__eq__(self, other)、__lt__(self, other)等
用于定义对象之间的比较操作。
class MyClass:
def __init__(self, value):
self.value = value
def __eq__(self, other):
if isinstance(other, MyClass):
return self.value == other.value
return False
- 算术运算符方法:如
__add__(self, other)、__sub__(self, other)等
用于定义对象之间的算术运算。
class MyClass:
def __init__(self, value):
self.value = value
def __add__(self, other):
if isinstance(other, MyClass):
return MyClass(self.value + other.value)
return NotImplemented
- 容器方法:如
__len__(self)、__getitem__(self, key)、__setitem__(self, key, value)等
-
用于定义对象作为容器(如列表、字典等)时的行为。
-
每个魔法方法是python的内置方法。方法都有对应的内置函数,或者运算符,对这个对象使用这些函数或者运算符时就会调用类中的对应魔法方法,可以理解为重写这些python的内置函数
2、Epoch,Batch-Size,Iteration区别

eg:
10,000 examples --> 1000 Batch-size --> 10 Iteration
1、需要mini_batch 就需要import DataSet和DataLoader
2、继承DataSet的类需要重写init,getitem,len魔法函数。分别是为了加载数据集,获取数据索引,获取数据总量。
3、DataLoader对数据集先打乱(shuffle),然后划分成mini_batch。
4、len函数的返回值 除以 batch_size 的结果就是每一轮epoch中需要迭代的次数。
5、inputs, labels = data中的inputs的shape是[32,8],labels 的shape是[32,1]。也就是说mini_batch在这个地方体现的
在windows 下 wrap 和 linux 下 fork 代码优化

3、加载相关数据集的实现
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
#shape本身是一个二元组(x,y)对应数据集的行数和列数,这里[0]我们取行数,即样本数
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









