







内容涉及excel和SPSS
课件:链接:https://pan.baidu.com/s/1RgRm0d24okUkWudKEQ7Q2g
提取码:gntv
数据分析的分类
在统计学邻域,数据分为三类:
| 描述性统计分析 | 对一组数据的各种基本特征进行分析,便于描述测量样本的各种特征,常用的方法包括对比分析、平均分析、交叉分析等,是复杂统计的基础 |
|---|---|
| 探索性数据分析 | 利用一定的分析方法返现数据中的隐藏特征规律,常用的分析方法包括相关分析、因子分析、回归分析、预测分析等,是一种高阶数据分析 |
| 验证性数据分析 | 利用分析方法验证假设的真伪准确性,比如顾客忠诚度,假设需要用购买频率、消费比例等指标来衡量,那么验证数据分析就是检验购买频率、消费比例等是否能反映出来 |
数据分析流程
确认分析目的明确分析思路数据采集数据输入数据整理数据处理数据分析数据呈现数据分析报告
数据采集
数据采集方式
公开出版物
中国统计年鉴、中国社会统计年鉴、中国人口统计年鉴、世界经济年鉴、世界发展报告
互联网
国家地方统计局网站、行业组织网站、政府机构网站、门户网站、企业网站、上市公司财报
数据库
市场调查
线下调查:电话、街头、座谈、轨迹
线上调查:线上调查问卷
数据分析职位
数据分析师需要懂管理、业务、心理学,与有关部门结合
自定义单元格格式
| 原始数据 | 单元格显示数据 | 自定义格式代码 |
|---|---|---|
| 123 | 一百二十三 | [DBNum1] |
| 123 | 查佰贰拾叁 | [DBNum2] |
| 123 | 123.00 | #0. 00 |
| 123 | 123.0 | #0.0 |
| 12. 23 | 12. 23% | 0.00% |
| 123456 | 1, 235 | #,##0 |
| 1234567890 | 人民币1, 235百万 | "人民币“#,##0,“百万” |
| 河南 | 中国移动河南分公司 | “中国移动“@"分公司” |
| 91 | 优秀 | [>90]“优秀”;[>80]"及格”;"不及格” |
| 59 | 59 | [>90][红色]0;[>80][绿色]0;[黄色]0 |
自定义单元格与TEXT函数使用:text(value,format_text)
value:数字值
format_text:设置所要的文本格式
举例:=text(b2,"[>=90] 优秀;[>=60] 及格;差")
数据分列
1.
LENB 与LEN 函数
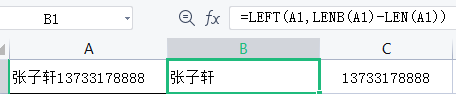
当姓名和电话号码都没有规律时,我们可以使用LENB 和LEN 函数,如图所示。
姓名公式=LEFT(A1,LENB(A1)-LEN(A1)),其中LENB(A1)代表A1单元格的字节总数
( 15),而LEN(A1)代表A1单元格的字符总数(12)。一个汉字是一个字符但是有两个字节,
所以LENB(A1)-LEN(A1)=15-12=3代表A1单元格的姓名汉字个数为3个。
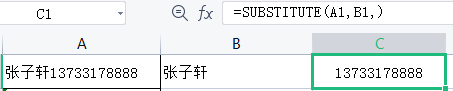
电话号码公式=SUBSTiTute(A1,B1,),即把A1单元格中 B1的部分替换为空。
2.
MIDB、SEARCHB、LENB函数
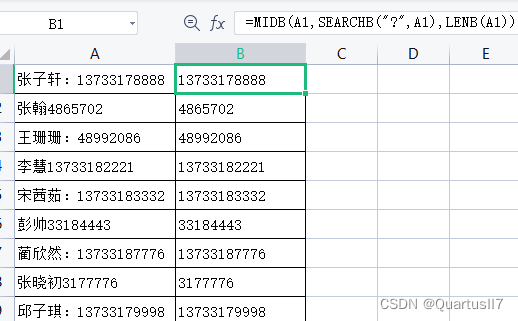
当姓名和电话号码没有规律,且姓名和电话号码中间还有不确定的其他字符时,就需要用MIDB+SEARCHB+LENB组合函数来实现,如图
电话号码公式= MIDB(A1,SEARCHB("?",A1),LENB(A1))
利用SEARCHB函数配合通配符"?"查找字符串中第1个半角字符的位置编号,再用MIDB函数提取电话号码。其中,姓名和电话号码中如果出现了全角的“:”,则也不会影响计算结果。
3.
MIDB、SEARCHB、LENB这些带B的函数和MID、SEARCH、LEN这些不带B的函数的区别在哪里呢?
MIDB、 SEARCHB、 LENB函数会将每个双字节字符按2计数,而MID、SEARCH、 LEN函数会将每个字符按1计数,如下图所示。
同样将“张子轩”的“子”提取出来,MIDB函数需要从第3个字符开始提取2位,而MID函数只需从第2个字符开始提取1位,因为张子轩的字节数(LENB)是6字节,而字符数(LEN)是3个。带B与不带B结合可以实现全角字符与半角字符的分离。
数据提取
1.
一列变多列
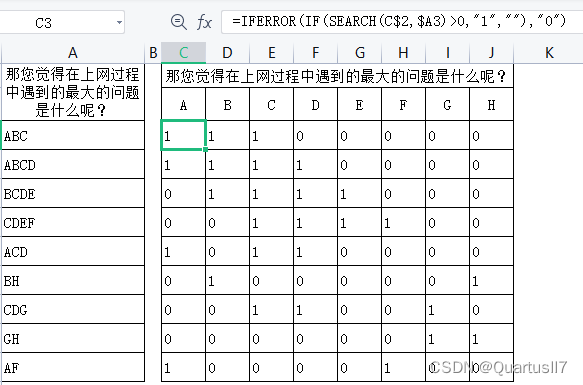
有一道多选题,共有A、B、C、 D、E、F、G、H这8个答案,由于没有采用二分法或
多重分类法录入,录入结果如左图中的A列所示,给数据处理和分析带来了不便。现需
进行数据整理,将A列转换为A、B、C、D、E、F、 G、H分别对应的8列,如果A列中出
现了答案,则在对应答案下方显示“1”;如果没有出现,则显示“0”。整理后的结果与二分
法录入的结果一致,如右图的C~J列所示。
公式=IFERROR(IF(SEARCH(C$2,$A3)>0,"1",""),"0")
首先search函数:指定字符串在原始字符串中首次出现的位置:search(要查找的文本,在哪里查找,从第几个字符开始查找(可忽略))
if函数判断,有输出1,没有为错误值
iferror函数将错误值转换为“0”:iferror(被检查的值,被检查的值为错误时返回值)
2.
提取不规则数据最后一部分内容
index语法:https://www.wps.cn/learning/course/detail/id/116.html?chan=pc_win_function
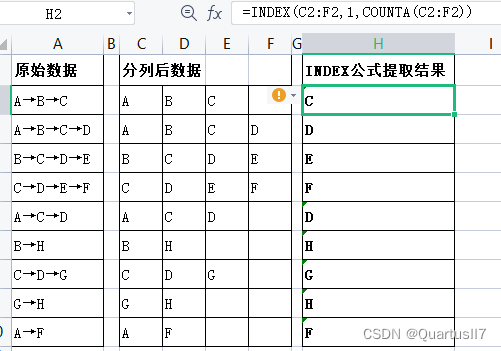
3.
提取部分内容,保留部分内容
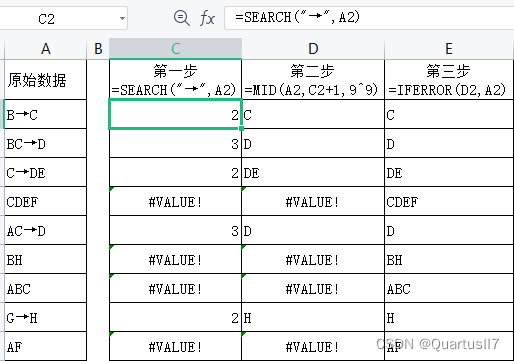
现有一列数据, 如果有箭头,则提取箭头后面的内容(箭头前后的字符长度不固定);如果没有箭头,则保留原内容; 如果单元格为空白,则保留空白,如图所示。
第一步,利用C2=SEARCH(“→”,A2)查找“→”为单元格的第几个字符。
第二步,利用D2=MID(A2,C2+1,9^9)将“→"后面的内容提取出来。
第三步,使用IFERROR函数将错误值转换为A列对应的单元格。
公式: =IFERROR(MID(A2,SEARCH(“→”,A2)+1,9^9),A2)
语法
MID(text,start_num,num_chars)
Text 是包含要提取字符的文本字符串。
Start_num 是文本中要提取的第一个字符的位置。文本中第一个字符的 start_num 为 1,以此类推。
Num_chars 指定希望 MID 从文本中返回字符的个数。
说明
■ 如果 start_num 大于文本长度,则 MID 返回空文本 ()。
■ 如果 start_num 小于文本长度,但 start_num 加上 num_chars 超过了文本的长度,则 MID 只返回至多直到文本末尾的字符。
■ 如果 start_num 小于 1,则 MID 返回错误值 #VALUE!。
■ 如果 num_chars 是负数,则 MID 返回错误值 #VALUE!。
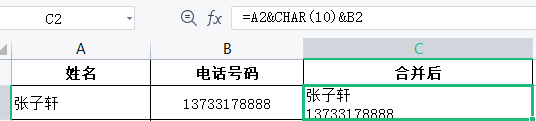
数据合并
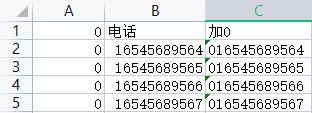
快速填充:将c2:c5单元格区域的单元格格式设置为文本格式,在c2单元格中输入016545689564,单机c3单元格,按住CTRL+E组合键,建议接受完成快速填充
快速填充的其他场景
数组特征合并数据
公式=E14:E19&F14:F19,按下shift+ctrl+enter组合键


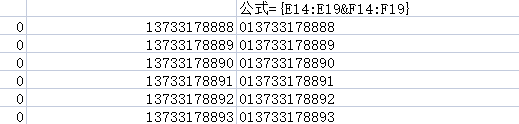
符合条件的合并为一个单元格


符合条件单元格对应内容合并
现有一组学员成绩,需要将每个学员成绩为空白的科目统计出来,并用“、”隔开。首先,根据要求,利用IF函数,如果单元格为空格,则输出结果为科目名称十“、”;如果单元格不为空格,则输出结果为空值,所有F函数计算出来的结果用CONCATENATE函数合并。
在K2单元格中输入公式“= CONCATENATE(IF(B2=“”,B$1&"、“iFIC2=”.C$1&、",IF(D2=",D$1&’、"),IF(E2="),E$1&"、",IF(F2=“F$1&、”,F(G2=",G$1&"、”"),
IF(H2=",H$1&’、”".IF(12=“1$1&、”).IF(U2=“J$1&、””,。完成缺考科目的合并。
然后left(k2,len(k2)-1)

1.下拉菜单:
主要说二级下拉菜单:
步骤:(1)选择I1:I2单元格区域定义名称“上网”,选择i3:i10单元格区域-右键-【定义名称】-输入“不上网”(2)选择c2:c10,【数据验证】(wps中数据-有效性)-【允许】-【序列】,在【来源】数据框中输入公式=indirect($a2),确定.。选择D2:D10,【数据验证】-【允许】-【序列】在【来源】数据框中输入公式=indirect($B2),确定。(3)C、D列可以根据A\B列的结果选择
2.身份证号:
选择区域-【数据】-【数据验证】-【验证条件】-【自定义】,在【公式】数值中输入公式=or(len(A2)=15,len(A2)=18),确定。
3.重复输入限制:
选择区域-【数据】-【数据验证】-【验证条件】-【自定

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









