






前言
只有自己封装库的时候,才知道造轮子有多累。之前使用Python的时候,基本都只需要import,随便哪个功能都有人写好轮子用。不过造轮子也有好处,可以了解一些比较基础的知识。
其实aardio也有很多已经造好的轮子可以用,只是因为只有作者在维护,而且没有一个活跃的社区,所以很多方面有些缺失,比如爬虫方面。但是aardio写一些小工具确实很方便,打包成exe也比较小,所以我来造这个轮子。
文中使用到的aardio库都可以到github下载:https://github.com/kanadeblisst00/aardio-extlibs
需求说明
之前写的一个视频号下载工具为了给公众号涨粉,对接了公众号后台,需要给后台发送消息获取使用码才能使用。开始使用码有效期是一天,后面改成了七天。
但有些人还是觉得有点麻烦,想让我弄成永久。我就怕改成永久后,很多人白嫖完就取关了,那对我也没什么好处。所以想用每个人的openid作为永久使用码,只要填一次,软件启动时会连接我的服务器验证这个openid对应的用户有没有取关。
这样对于用户而言就不需要去公众号后台发送消息这一步骤,可以省点事。不过这对我而言倒是增加了不少工作量。那首先需要一个获取公众号粉丝的openid列表的程序。
功能介绍
虽然微信公众平台开放了API,但是很多接口订阅号都用不了,比如获取粉丝列表,不过我们可以在后台看到,那用爬虫也能实现。下面是大概的界面内容:
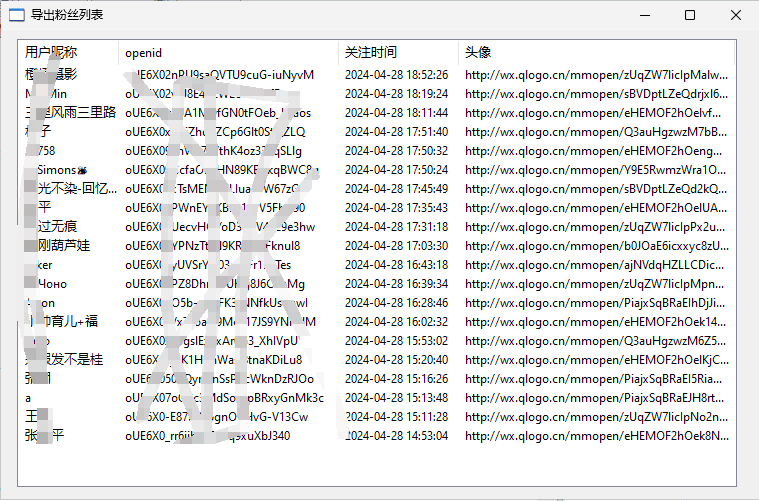
界面只会显示当前页的内容,如果想看全部的数据,可以到当前文件夹下的公众号粉丝.csv里查看。采集的所有数据都会保存到里面(注意:如果还在采集你就打开的话,采集程序将无法保存到里面而失败)
打包后的程序也很小,只有2M多。如果用upx压缩一下会更小,但是压缩后更容易报毒,所以我现在基本都不压缩了。

开源地址
代码是完全开源的,你可以在github下载。如果需要编译好的软件可以公众号后台发送获取粉丝列表
https://github.com/kanadeblisst00/CrawlBizUsers
采集思路
微信公众平台后台的接口都没有加密,只要抓个包就能请求,
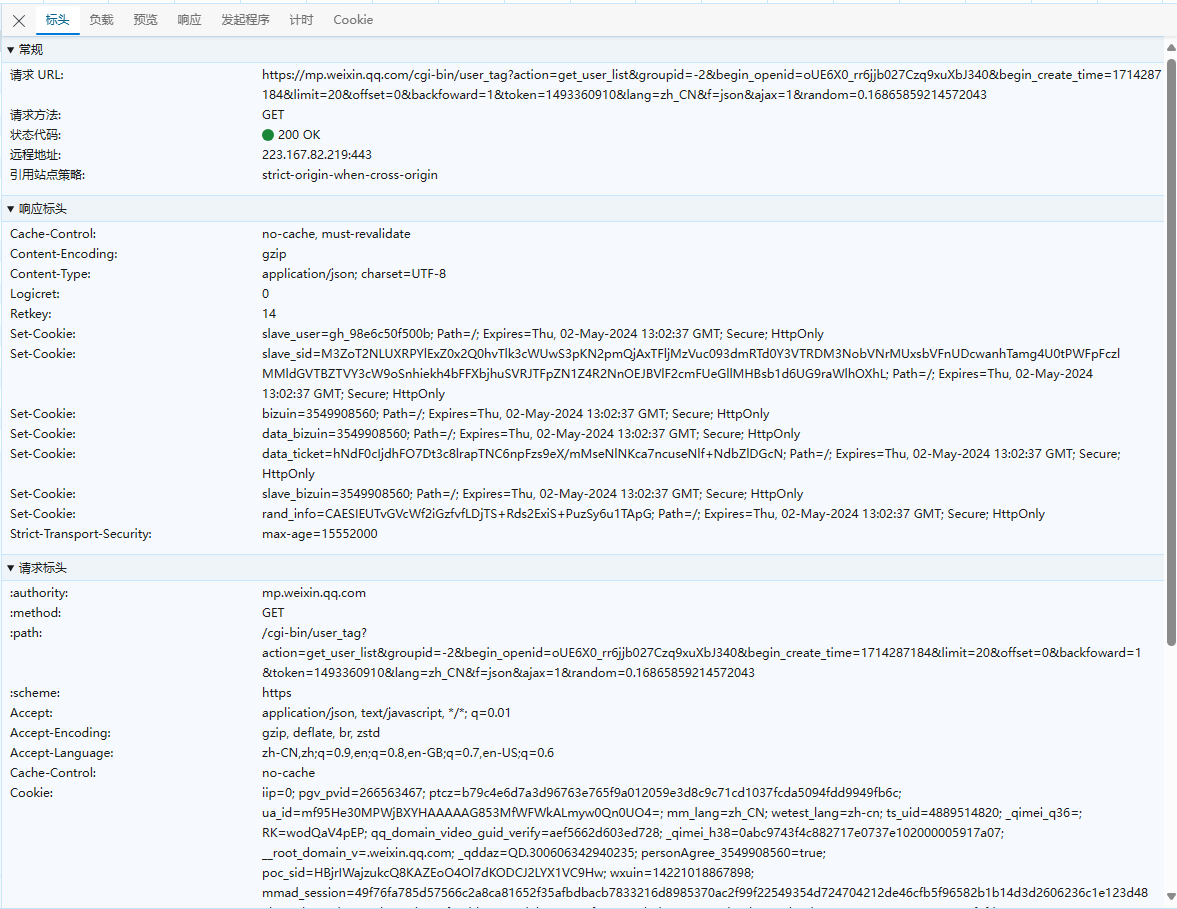
用我封装好的kirequests库请求如下:
import kirequests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
}
var session = kirequests.session(headers,,cookies);
var url = "https://mp.weixin.qq.com/cgi-bin/user_tag"
var params = {
"action": "get_user_list",
"groupid": -2,
"limit": 20,
"offset": 0,
"token": token,
"lang": "zh_CN",
"f": "json",
"backfoward": 1,
"ajax": 1,
"random": "0." + ..string.random(16, "0123456789"),
"begin_openid": "xxxxxxxxxx",
"begin_create_time": 11111
}
var resp = session.get(url,params);
var datas = resp.json()获取cookies
采集比较麻烦的是cookies的获取方式。看一些项目获取cookies的基本都是让用户自己填,有的方便一点的会自动获取浏览器的cookies。
如果让用户自己填的话会提高使用门槛,如果获取用户浏览器的cookies又比较麻烦,Python有现成的库可以做到,aardio还要自己实现,而且获取用户cookies这种也比较敏感。
所以我这里直接开一个浏览器,然后访问微信公众平台的登录页面,让用户扫码登录,然后获取cookies后自动关闭浏览器,开始采集。这样用户只需要一个扫码的过程。
开启浏览器
aardio中开启浏览器有非常多种方式,具体可以看范例-》Web界面:
这里我选择web.view来做,这个比较轻量(因为用的系统API,类似安卓的Via那种模式),它是基于微软的WebView2,win10和win11系统基本都自带了这个东西。后面我要实现的浏览器驱动程序(类似Python的drissionpage)也是用的这个来实现。
import web.view;
var webView = web.view(winform);
var url = "https://mp.weixin.qq.com";
webView.go(url);如果是已经登录的请求,url会跳转到https://mp.weixin.qq.com/cgi-bin/home,所以这里只需要循环判断一下链接有没有变成这个
var doJavasciptCode = function(webView, code){
var jscode = "(function(){"+code+'\n})()';
var result;
webView.doScript(jscode, function(r){
result = r;
}
)
while(!result){
win.delay(10);
}
return result;
}
var getLoctionHref = function(webView){
return doJavasciptCode(webView, "return document.location.href;");
}
var curUrl = getLoctionHref(webView);
while(!string.find(curUrl, "@https://mp.weixin.qq.com/cgi-bin/home")){
win.delay(500);
curUrl = getLoctionHref(webView);
}然后开始获取cookies,获取到的cookies格式是一个数组,数组每个元素都是一个cookie字典,有name、value等字段。直接将它传给kirequests即可,不需要做什么处理
var getCookiesArray = function(webView){
var result = webView.cdp("Network.getCookies");
var cookies = result.cookies;
return cookies
}
var cookies = getCookiesArray(webView);
var session = kirequests.session(,,cookies);然后只需要一直翻页就能获取全部的公众号粉丝列表了
清除cookies
如果采集完数据,想要删除webview的cookies,可以删除C:\Users\用户名\AppData\Local\aardio\webview2\user-data下面的文件夹,这个就是webview默认的缓存目录














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









