









1、概念
-
堆排序是利用 堆进行排序的
-
堆是一种完全二叉树
-
堆有两种类型: 大根堆 小根堆
-
两种类型的概念如下:
大根堆:每个结点的值都大于或等于左右孩子结点
小根堆:每个结点的值都小于或等于左右孩子结点


完全二叉树
完全二叉树 是 一种除了最后一层之外的其他每一层都被完全填充,并且所有结点都保持向左对齐的树,向左对齐指的是:

下面这样的树不是完全二叉树:

如果给上面的大小根堆的根节点从1开始编号,则满足下面关系(下图就满足这个关系):
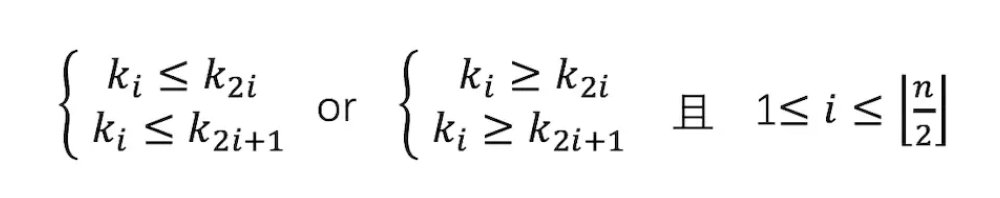
如果把这些数字放入数组中,则如下图所示:其中,上面的数字是数组下标值,第一个元素占位用。

堆排序的思想(以大根堆为例)
- 首先将待排序的数组构造出一个大根堆
- 取出这个大根堆的堆顶节点(最大值),与堆的最下最右的元素进行交换,然后把剩下的元素再构造出一个大根堆
- 重复第二步,直到这个大根堆的长度为1,此时完成排序。
下面通过图片看第二步是如何进行的



这就是构建大根堆的思想,了解了之后就可以进行编码,编码主要解决两个问题:
-
如何把一个序列构造出一个大根堆
-
输出堆顶元素后,如何使剩下的元素构造出一个大根堆
根据问题进行编码,由于数组下标是从0开始的,而树的节点从1开始,我们还需要引入一个辅助位置,Python提供的原始数据类型list实际上是一个线性表(Array),由于我们需要在序列最左边追加一个辅助位,线性表这样做的话开销很大,需要把数组整体向右移动,所以list类型没有提供形如appendleft的函数,但是在一个链表里做这种操作就很简单了,Python的collections库里提供了链表结构deque,我们先使用它初始化一个无序序列:
from collections import deque
L = deque([50, 16, 30, 10, 60, 90, 2, 80, 70])
L.appendleft(0)
总代码:
from collections import deque
def swap_param(L, i, j):
L[i], L[j] = L[j], L[i]
return L
def heap_adjust(L, start, end):
temp = L[start]
i = start
j = 2 * i
while j <= end:
# L[j] 为左右叶子节点中相对大的数字
if (j < end) and (L[j] < L[j + 1]):
j += 1
# 将根结点与叶子节点中较大的数交换
if temp < L[j]:
L[i], L[j] = L[j],L[i]
i = j
j = 2 * i
else:
break
# L[i] = temp
def heap_sort(L):
L_length = len(L) - 1
first_sort_count = L_length // 2
for i in range(first_sort_count):
heap_adjust(L, first_sort_count - i, L_length)
for i in range(L_length - 1):
L = swap_param(L, 1, L_length - i)
heap_adjust(L, 1, L_length - i - 1)
return [L[i] for i in range(1, len(L))]
def main():
L = deque([50, 16, 30, 10, 60, 90, 2, 80, 70])
# L = deque([56,30,71,18,29,93,44,75,20,65,68,34])
L.appendleft(0)
print(heap_sort(L))
if __name__ == '__main__':
main()















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









