






 本文介绍了如何使用R语言进行网络爬虫,通过实例展示了如何爬取甘孜州政府网站的新闻数据。文章详细讲解了网络爬虫的基本知识,包括网页语法、R语言中的XML和RCurl包,以及网络提取策略,如正则表达式、XPATH和API。此外,还分享了一个爬取甘孜州政府新闻的完整实例,涉及到URL规律、正则表达式的运用以及处理动态网页的挑战。最后,作者提醒读者在下一期中将展示如何用正则表达式从源代码中提取所需新闻内容。
本文介绍了如何使用R语言进行网络爬虫,通过实例展示了如何爬取甘孜州政府网站的新闻数据。文章详细讲解了网络爬虫的基本知识,包括网页语法、R语言中的XML和RCurl包,以及网络提取策略,如正则表达式、XPATH和API。此外,还分享了一个爬取甘孜州政府新闻的完整实例,涉及到URL规律、正则表达式的运用以及处理动态网页的挑战。最后,作者提醒读者在下一期中将展示如何用正则表达式从源代码中提取所需新闻内容。
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定!
对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。
作者:梁凯 R语言中文社区专栏作者
知乎ID:https://www.zhihu.com/people/liang-kai-77-98
前言
众所周知巧妇难为无米之炊,数据科学也一样,没有数据所有算法模型都是一个摆设,所以这篇就是手把手教大家怎样从网络上自动收取数据(老司机都知道叫网络爬虫)。因为各种原因,如果在做分析的时候完全依赖问卷和访问数据(除开实验室里的实验数据),有时会感到数据十分匮乏,特别在互联网是一个庞大的社交网络的今天,各种数据在互联网上等待被人收集,如果手动收集将会是一个很复杂,繁杂又浪费时间的工作,并且容易出现手动录入的人为误差。那么怎么解决这个问题?最有效的办法就是设计一个网络爬虫(网络机器人)以高效率的方式帮助我们自动收集网络数据。今天为大家带来的就是一个简单但实用的例子,用R语言编写网络爬虫爬取甘孜州新闻。希望通过这个例子能够让大家了解,网络爬虫的魅力和智能化收集数据的便利性。
一、基本必备知识
用任何做爬虫必须要了解的就是网页语法,网页语言无非就是HTML,XML,JSON等,因为正是通过这些我们才能在网页中提取数据,过多的就不再描述,大家可以自行参考大量的资料,大多数语法都是树形结构,所以只要理解了,找到需要数据的位置并不是很难。动态网页的爬取要用到另外的方法,此处暂且不表。
二、R语言网络爬虫三大包
用R语言制作爬虫无非就是三个主要的包。XML,RCurl,rvest,这三个包都有不同的主要函数,是R语言最牛的网络爬虫包,关于rvest是大神Hadley Wickham开发的网络爬虫新利器,在此按照业内惯例,给大神送上单膝。rvest正在研究中,在本例中将会只涉及XML,RCurl,两个包。
三、网络提取策略选择
网络提取策略的选择是经过你把大量的网络编码解析存储在R或者本地文件夹中,通过对繁杂的网络代码查找筛选而得到想要的数据的必要策略,现今爬虫的世界,最主要的提取策略有三个。正则表达式,XPATH,和API。这三个策略各有优劣。
正则表达式
优点:
1.相比于其他策略在网页结构不正确情况下依然能用
2.在DOM解析失效的情况下能用
3.适用于各种格式的字符识别
4.处理文档较多的时候最快最方便
缺点:
1. 不能保持采集后数据原有的结构。
2. 复杂难以掌握,具有挑战性
3. 无法处理异构化的数据,当所提取的数据没有共同点时候就会显得尴尬
XPATH
优点:
1. 灵活,方便,易于编写
2. 基于文字内容搜索而不是像正则表达式基于上下文结构便于查找
3. 能够处理异构化网页
缺点:
1.当解析网页无效时,XPATH则无法使用
2.对动态网页,多样化网页提取难度大
API
优点:
1. 难度最低,几乎不用任何技术手段
2. 抓取的数据最可靠,最整洁有效
3. 数据来源透明,有效,能进行有效的数据更新
缺点:
1.使用十分有限,权限较高
2.严重依赖数据提供者和API,技术含量低
四、一个实例:爬取甘孜州政府新闻
首先需要说明的是本例子中只是一个例子,为什么选取新闻,是因为新闻是文本数据爬取的难度比表格难度大,表格可以直接用readHTMLTable读取,而且本例子中全部选用正则表达式提取数据策略,意在为大家进行深动的教学,而并非是仅仅的一个例子。其次爬取的新闻是对外公布新闻,人畜无害。
1
对象选取
本例子中选取甘孜州政府外网中国甘孜(http://www.gzz.gov.cn/),里面的新闻为例子
进入网址点击甘孜新闻
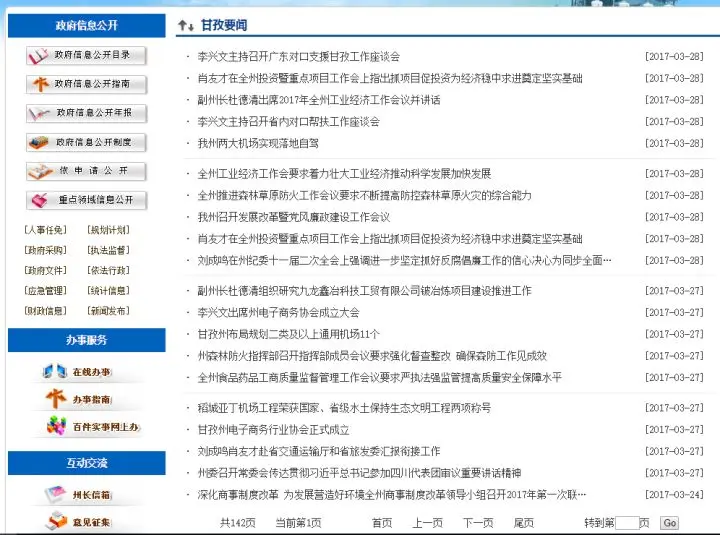
观察页面我们可以看见共142页,每页有20条新闻,我们随便打开一个,右键点击查看网页源代码

我们很容易发现这是用javascript写的网站。

而我们需要的新闻内容在源代码的下方也就是如上图所示,鉴于网页复杂,本人又喜欢正则表达式所以用正则表达式来提取信息。
2
打开R开始进行编写爬虫任务
首先必须安装几个包然后再读取
1install.packages("XML")###网络解析
2install.packages(bitops)
3install.packages("RCurl")
4install.packages("stringr")###字串符处理
5install.packages("plyr")######批量处理
6###############读取包###########
7library("XML")
8library("bitops")
9library("RCurl")
10library("stringr")
11library("plyr")
然后分析开始,首先观察我们的基本网站网址url为gzz.gov.cn/,然后打开新闻链接
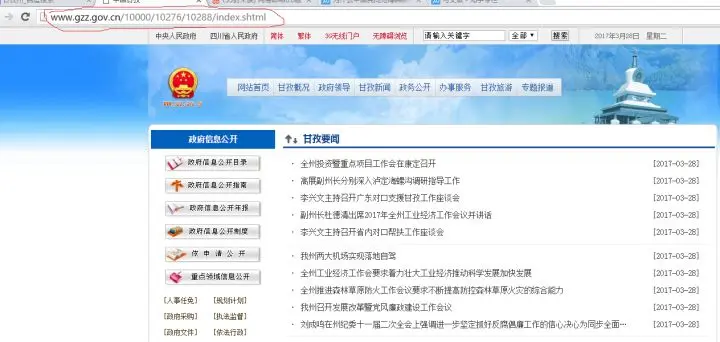
红色部分就是我们新闻链接的url网址,上图是首页让我们看看第二页和最后一页网站url是什么?第二页的网址为:gzz.gov.cn/10000/10276/
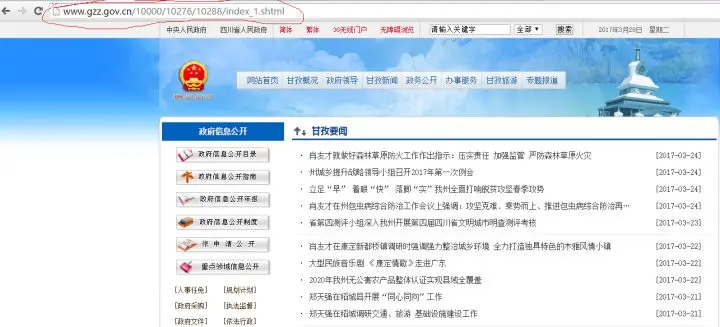
最后一页的网址为:gzz.gov.cn/10000/10276/
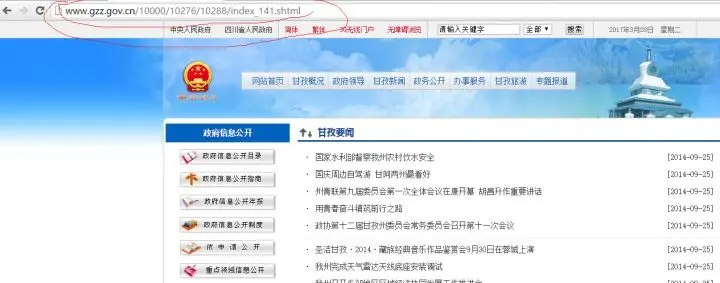
发现规律没?
手也不算从第二页开始我们就可以看出网址的变化规律为
http://www.gzz.gov.cn/10000/10276/10288/index从1到141.shtml这让我们能够很清晰的构建正则表达式。
接下来我们随便从一页中打开一个新闻,
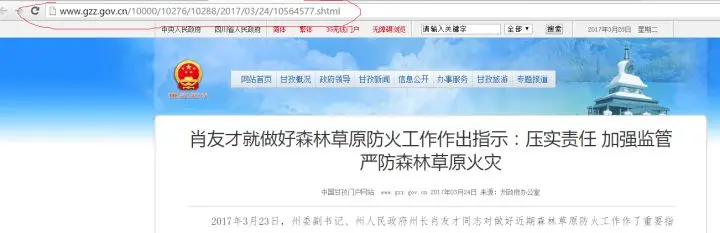
我们可以观察他的网址url为
gzz.gov.cn/10000/10276/
这也可以看作基本网站
http://www.gzz.gov.cn/ 加上
10000/10276/10288/2017/03/24/10564577.shtml的组合。
从上面的分析中我们就不难得到正则表达式了。
具体思路为除开新闻第一页,我们构建一个以
http://www.gzz.gov.cn/10000/10276/10288/index从1到141.shtml的网页,在每一页上得到他们的links也就是类似与上面的例子
10000/10276/10288/2017/03/24/10564577.shtm,相当于每一页每条新闻的链接,让后用正则表达式直接进入每条新闻解析网站找到我们想要的新闻文本。
具体代码如下:
1rurl<-"http://www.gzz.gov.cn/10000/10276/10288/index"
2####这个是新闻页面的标准网址##
3baseurl<-"http://www.gzz.gov.cn"
4###########这个是基本网址#########
5page<-NULL
6page[1]<-str_c(rurl,".shtml")
7#######上面是用正则表达式表现首页####
8a<-c(1:141)
9page[2:142]<-str_c(rurl,"_",a,".shtml")
10########在这里我们要用正则表达式来表现从第二页开始新闻页面的网址#######
11p<-lapply(p, getHTMLLinks)
12########上面的代码里lapply函数是最便捷的函数如果要用for函数不仅费时而且费事,所以我建议如果没有必要就用sapply,lapply,apply等函数来替代,再有getHTMLLinks函数是获取页面内所有links的函数###########
让我们来看看代码运行的效果我们随便,打开一个来看看

发现每当解析一页新闻页面时我们总是得到大多links链接,但是我们并不是想要全部links,我们只需要我们所需要的新闻部分,通过观察我们可以发现新闻在link为42到61这二十个links之间,除开最后一页142页只有16个新闻外别的都有二十条新闻也就是二十条链接
所以我们可以写出代码:
1for(iin1:141){
2p[[i]]<-p[[i]][42:61]
3}
4p[[142]]<-p[[142]][42:57]
5
6entireurl<-lapply(p,function(p)str_c(baseurl,p))
7###############这里就是所有新闻链接的地址一共142页前141页每页20条,最后一页每页16条,所以一共得到20乘以141再加上16条链接总共2836条##############
运行代码我们可以得到(查看最后3页的链接)

在这里我们可以看见最后一页的链接为NA,这是怎么回事呢?嘿嘿,先不要急,说好了这是教育贴,没有轻易让你得到正确答案。
在上面的代码中我们直接网页url中得到了网页,但是我们却忘了去解析每一个网页。对,在R语言中还必须解析网页,网页解析需要靠RCurl包里的getURL函数,
于是我们修改我们的代码:
1rurl<-"http://www.gzz.gov.cn/10000/10276/10288/index"
2baseurl<-"http://www.gzz.gov.cn"
3getlinklist<-function(rurl,baseurl){
4page<-NULL
5page[1]<-str_c(rurl,".shtml")
6a<-c(1:141)
7page[2:142]<-str_c(rurl,"_",a,".shtml")
8
9p<-lapply(page[1:142], getURL)
10########注意这里是我们新添加的代码,它的意义就是解析每一个新闻页面的url######
11p<-lapply(p, getHTMLLinks)
12
13for(iin1:141){
14p[[i]]<-p[[i]][42:61]
15}
16p[[142]]<-p[[142]][42:57]
17
18entireurl<-lapply(p,function(p)str_c(baseurl,p))
我们再来运行代码试试,得到:

为保险我们再来检查看看他有没有NA
1which(is.na(entireurl))
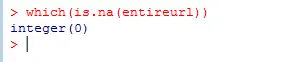
可以看出现在已经没有NA这个元素,我们可以放心接着下一步了。
在此之前我们先把上面的代码写成一个函数
1getlinklist<-function(rurl,baseurl){
2page<-NULL
3page[1]<-str_c(rurl,".shtml")
4a<-c(1:141)
5page[2:142]<-str_c(rurl,"_",a,".shtml")
6
7p<-lapply(page[1:142], getURL)
8
9
10p<-lapply(p, getHTMLLinks)
11
12for(iin1:141){
13p[[i]]<-p[[i]][42:61]
14}
15p[[142]]<-p[[142]][42:57]
16
17entireurl<-lapply(p,function(p)str_c(baseurl,p))
18
19}
20rurl<-"http://www.gzz.gov.cn/10000/10276/10288/index"
21baseurl<-"http://www.gzz.gov.cn"
22entirelinks<-getlinklist(rurl,baseurl)
我们现在已经得到了所有新闻的链接url,接下来我们就要对每一条链接用readLines函数进行处理,在R中显示源代码。
1entirelinksnew<-unlist(entirelinks)
2#######在我们上一条函数中我们得到的结果是以一个list格式返回的结果,在这里我们要把它转化,便于处理#######
3parsefile<-list(NULL)
4length(parsefile)<-length(entirelinksnew)
5###########这里要建立一个list为了便于储存输出结果,因为lapply函数的输出格式就是list格式##
6getfile<-function(entirelinksnew){
7parsefile<-lapply(entirelinksnew, readLines)
8}
9getfile(entirelinksnew)
10###数量太多这里我们尝试前条新闻的解析看看效果#####

WTF!!!???试了几次都是这个样,难道是反爬虫程序?不急,理论上所有网页都可以爬取,我们换一种方法,把每个URL都下载下来再解析
1setwd("F:\\123")####设定你的下载路径###
2for(iin1:2836) {
3
4download.file(entirelinksnew[i],paste('a',i,'.kk','.html',sep=''),mode="wb")
5
6Sys.sleep(0)
7
8}
9#####这里要注意批量下载需要技巧,那就是用paste或者str_c函数构造不同的文件名#####
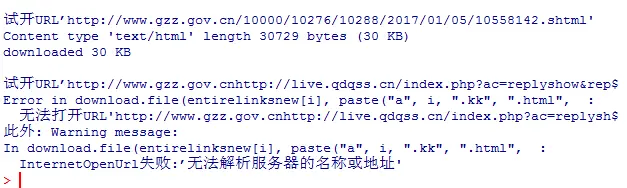
又遇到解析失败,到底什么原因呢?我们查看下文件

下到文件236就断了,我们检查下文件236的url,然后看看怎么回事?

我们可以看到我们打开的链接并不等于我们所知道的链接,试着打开页面
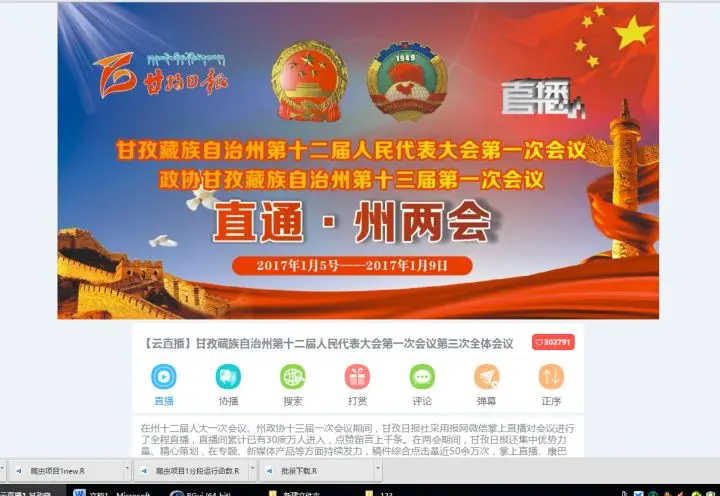

我们可以知道原来是云直播搞的鬼,这个无法解析是因为网站不是做的而是由转载的。所有这类的网页地址末尾都不是以shtml结尾,所以我们写一个正则表达式来判断哪些是不合格的url:
1entirelinksnew<-entirelinksnew[grepl("\\.shtml$", entirelinksnew)]
2###########只保留结尾为shtml的url
上面的grepl("\\.shtml$", entirelinksnew)代码就是找出所有结尾为shtml的url。而别的就可以省略了。

我们可以看出去掉了6条结尾不是shtml1的url,然后我们再来尝试运行代码
1parsefile<-list(NULL)
2length(parsefile)<-length(entirelinksnew)
3
4getfile<-function(entirelinksnew){
5parsefile<-lapply(entirelinksnew, readLines)
6}
7a<-getfile(entirelinksnew)

哈哈,经过一系列的改进代码我们终于把2830条新闻源代码读入到R内了,让我们看看情况
1summary(a)
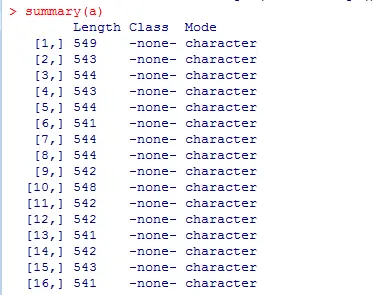
非常完美的就把想要的结果储存到R了。
那么再试试下载
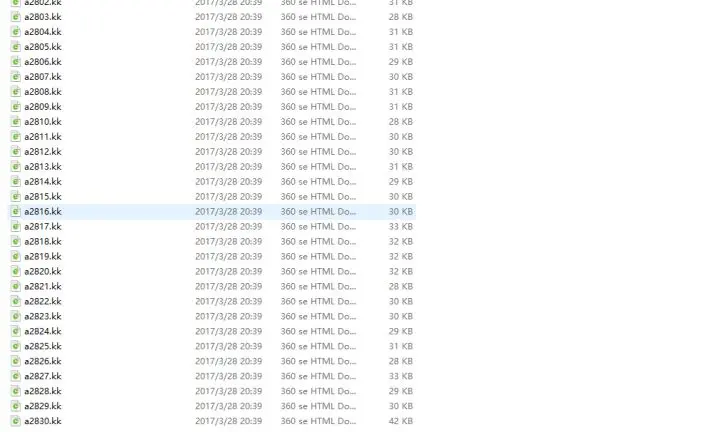
2830条html文件就下载到我们电脑里了。
写
在最后
接下来我们就要尝试用正则表达式来提取2830条网页源代码中我们所需要的新闻了。本期就结束了,欢迎大家看下一期。我会用最详细的手法来教会大家网络爬虫withR。谢谢大家,不足之处也请多多指教。谢谢!

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









