






前些日子,一些资深Gopher,比如fasthttp[1]的作者Aliaksandr Valialkin[2]因函数迭代器[3]加入Go 1.23版本[4]而抱怨Go的演进走错了方向:朝着增加复杂性和隐式代码执行的方向发展,而没有专注于Go语言的基本设计哲学——简单性、生产力和性能。Valialkin希望Go团队能专注于一些性能打磨和优化的环节,比如使用SIMD提升一些计算场景下Go代码的性能,避免Go的某些领地被以性能和安全性著称的Rust[5]抢去!
无独有偶,在Go项目issues中,我们也能看到很多有关希望Go支持SIMD指令的issue,比如近期的一个proposal[6],就期望Go团队可以在标准库中添加simd包以支持高性能的SIMD计算,就像Rust std::simd那样。当然,早期这类issue也有很多,比如:issue 53171[7]、issue 58610[8]等。
那么什么是SIMD指令?在Go官方尚未支持simd包或SIMD计算的情况下,如何在Go中使用SIMD指令进行计算加速呢?在这篇文章中,我们就来做个入门版介绍,并以一个最简单的矩阵加法的示例来展示一下SIMD指令的加速效果。
1. SIMD指令简介
SIMD是“单指令多数据”(Single Instruction Multiple Data)的缩写。与之对应的则是SISD(Single Instruction, Single Data),即“单指令单数据”。
在大学学习汇编时,用于举例的汇编指令通常是SISD指令,比如常见的ADD、MOV、LEA、XCHG等。这些指令每执行一次,仅处理一个数据项。早期的x86架构下,SISD指令处理的数据仅限于8字节(64位)或更小的数据。随着处理器架构的发展,特别是x86-64架构的引入,SISD指令也能处理更大的数据项,使用更大的寄存器。但SISD指令每次仍然只处理一个数据项,即使这个数据项可能比较大。
相反,SIMD指令是一种特殊的指令集,它可以让处理器可以同时处理多个数据项,提高计算效率。我们可以用下面这个更为形象生动的比喻来体会SIMD和SISD的差别。
想象你是一个厨师,需要切100个苹果。普通的方式是一次切一个苹果,这就像普通的SISD处理器指令。而SIMD指令就像是你突然多了几双手,可以同时切4个或8个苹果。显然,多手同时工作会大大提高切苹果的速度。
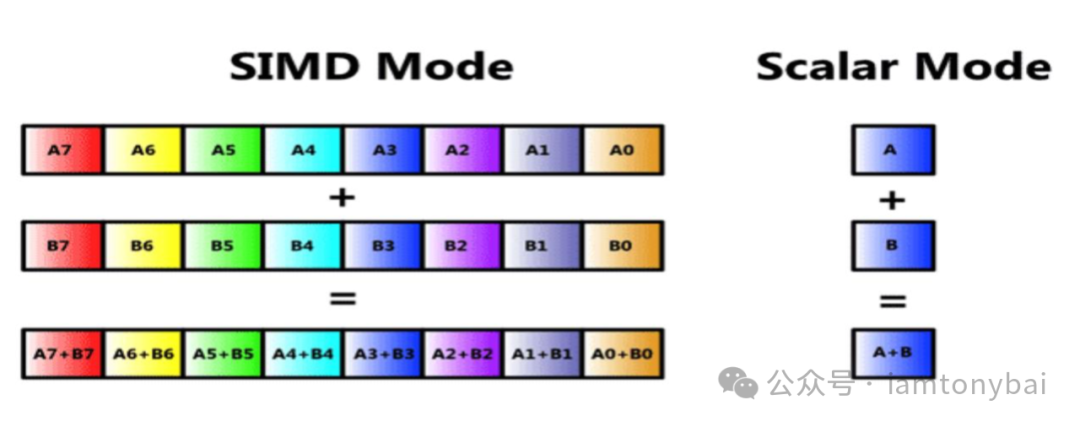
具体来说,SIMD指令的优势在于以下几点:
并行处理:一条指令可以同时对多个数据进行相同的操作。
数据打包:将多个较小的数据(如32位浮点数)打包到一个较大的寄存器(如256位)中。
提高数据吞吐量:每个时钟周期可以处理更多的数据。
这种并行处理方式特别适合于需要大量重复计算的任务,如图像处理、音频处理、科学计算等。通过使用SIMD指令,可以显著提高这些应用的性能。
主流的x86-64(amd64)和arm系列CPU都有对SIMD指令的支持。以x86-64为例,该CPU体系下支持的SIMD指令就包括MMX(MultiMedia eXtensions)、SSE (Streaming SIMD Extensions)、SSE2、SSE3、SSSE3、SSE4、AVX(Advanced Vector Extensions)、AVX2以及AVX-512等。ARM架构下也有对应的SIMD指令集,包括VFP (Vector Floating Point)、NEON (Advanced SIMD)、SVE (Scalable Vector Extension)、SVE2以及Helium (M-Profile Vector Extension, MVE)等。
注:在Linux上,你可以通过lscpu或cat /proc/cpuinfo来查看当前主机cpu支持的SIMD指令集的种类。注:Go在Go 1.11版本才开始支持AVX-512指令[9]。
每类SIMD指令集都有其特定的优势和应用场景,以x86-64下的SIMD指令集为例:
MMX主要用于早期的多媒体处理;
SSE系列逐步改进了浮点运算和整数运算能力,广泛应用于图形处理和音视频编码;
AVX系列大幅提高了并行处理能力,特别适合科学计算和高性能计算场景。
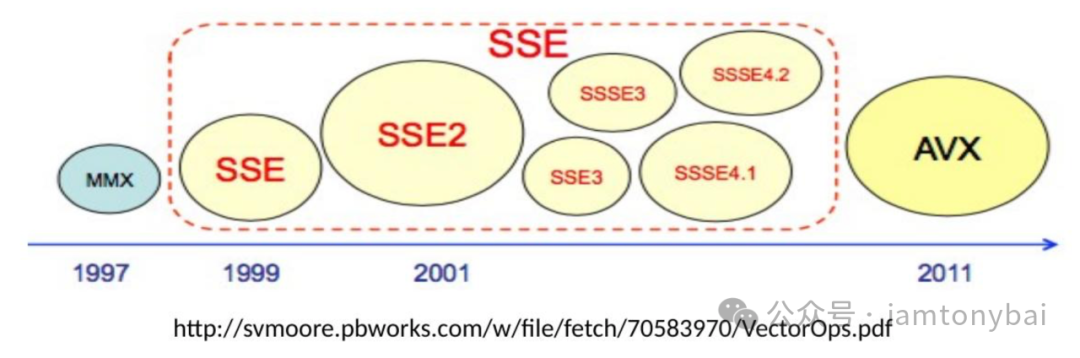
这些指令集的演进反映了处理器技术的发展和应用需求的变化。从支持64位计算的MMX到支持512位计算的AVX-512,SIMD指令的并行处理能力不断提升,更多更大的寄存器加入进来,为各种复杂的计算任务提供了强大的硬件支持。
注:SSE和AVX各自有16个寄存器,SSE的16个寄存器为XMM0-XMM15,XMM是128位寄存器,而YMM是256位寄存器。支持AVX的x86-64处理器包含16个256位大小的寄存器,从YMM0到YMM15。每个YMM寄存器的低128位是相对应的XMM寄存器。大多数AVX指令可以使用任何一个XMM或者YMM寄存器作为SIMD操作数。AVX512将每个AVXSIMD寄存器的大小从256位扩展到512位,称为ZMM寄存器;符合AVX512标准的处理器包含32个ZMM寄存器,从ZMM0~ZMM31。YMM和XMM寄存器分别对应于每个ZMM寄存器的低256位和低128位。
既然SIMD指令这么好,那么在Go中应该如何使用SIMD指令呢?接下来我们就来看看。
2. 在Go中如何使用SIMD指令
Go主要面向的是云计算领域、微服务领域,这些领域中对计算性能的要求相对没那么极致。以至于在一些对性能要求较高的场景,比如高性能计算、 图形学、数字信号处理等领域,很多gopher会遇到对Go计算性能进行优化的需求。
纯计算领域,怎么优化呢?此时此刻,Go官方并没有提供对SIMD提供支持的simd包。
一种想法是使用cgo机制在Go中调用更快的C或C++,但cgo的负担又不能不考虑,cgo不是go[10],很多人不愿意引入cgo。
另外一种想法就是再向下一层,直接上汇编,在汇编中直接利用SIMD指令实现并行计算。但手写汇编难度是很高的,手写Plan9风格、资料甚少的Go汇编难度则更高。那么有什么方法避免直接手搓汇编呢?目前看大致有这么几种(如果有更好的方法,欢迎在评论区提出你的建议):
使用c2goasm[11](https://github.com/minio/c2goasm/)转换
我们可以先用c/c++实现对应的函数功能(可以利用类似intel提供的面向simd的intrisic functions[12]),然后生成汇编代码(基于clang),再用c2goasm转换为go语言汇编。不过目前c2goasm已经public archive了,并且该方法应用受很多因素限制,比如clang版本和特定的编译选项啥的。亲测这种方法上手难度较高。
使用uber工程师Michael McLoughlin开源的avo[13]来生成go汇编
avo(https://github.com/mmcloughlin/avo)是一个go包,它支持以一种相对高级一些的Go语法来编写汇编,至少你可以不必直面那些晦涩难懂的汇编代码。但使用avo编写汇编也不是很容易的事情,你仍然需要大致知道汇编的运作原理和基本的编写规则。此外avo与汇编的能力并非完全等价,其作者声明:avo也还处于实验阶段。
使用goplus/llgo集成c/c++生态
在go中调用c的cgo机制不受待见,llgo[14]反其道而行之,将go、python、c/c++等代码统统转换为llvm中间代码进而通过clang编译和优化为可执行文件。这样就可以直接利用python、c/c++的生态,进而利用高性能的c/c++实现(比如支持SIMD指令)。目前llgo还不成熟,七牛云老板许式伟正在全力开发llgo,等llgo成熟后,这后续可能也是一种选择。
考虑到Go目前不直接支持intel intrisic functions for SIMD[15],要在Go中使用SIMD只能直接使用汇编。而在手搓汇编难度太高的情况下,通过avo生成汇编便是一条可以尝试的路径,我们可以将一些计算的核心部分用avo生成的汇编来进行加速。
接下来,我们就来通过一个矩阵加法的示例看看SIMD指令的加速效果。基于SIMD指令的矩阵加法的汇编逻辑,我们采用avo实现。
3. 第一版SIMD优化(基于SSE)
我们使用avo先来实现一版基于SSE指令集的矩阵加法。前面说过avo是一个Go库,我们无需安装任何二进制程序,直接使用avo库中的类型和函数编写矩阵加法的实现即可:
// simd-in-go/matadd-sse/pkg/asm.go
//go:build ignore
// +build ignore
package main
import (
"github.com/mmcloughlin/avo/attr"
. "github.com/mmcloughlin/avo/build"
. "github.com/mmcloughlin/avo/operand"
)
func main() {
TEXT("MatrixAddSIMD", attr.NOSPLIT, "func(a, b, c []float32)")
a := Mem{Base: Load(Param("a").Base(), GP64())}
b := Mem{Base: Load(Param("b").Base(), GP64())}
c := Mem{Base: Load(Param("c").Base(), GP64())}
n := Load(Param("a").Len(), GP64())
X0 := XMM()
X1 := XMM()
Label("loop")
CMPQ(n, U32(4))
JL(LabelRef("done"))
MOVUPS(a.Offset(0), X0)
MOVUPS(b.Offset(0), X1)
ADDPS(X1, X0)
MOVUPS(X0, c.Offset(0))
ADDQ(U32(16), a.Base)
ADDQ(U32(16), b.Base)
ADDQ(U32(16), c.Base)
SUBQ(U32(4), n)
JMP(LabelRef("loop"))
Label("done")
RET()
Generate()
}第一次看上面这段代码,你是不是觉得即便使用avo来生成矩阵加法的代码,如果你不了解汇编的编写和运行模式,你也是无从下手的。简单说一下这段代码。
首先,该文件是用于生成矩阵加法的汇编代码的,因此该asm.go并不会编译到最终的可执行文件中或测试代码中,这里利用go编译器构建约束将该文件排除在外。
main函数的第一行的TEXT函数定义了一个名为MatrixAddSIMD的函数,使用attr.NOSPLIT属性表示不需要栈分割,函数签名是:
func(a, b, c []float32)变量a, b, c分别表示输入矩阵a, b和输出矩阵c的内存地址,使用Load函数从参数中加载基地址到GP64返回的通用寄存器。n表示矩阵的长度,使用 Load函数从参数中加载长度到GP64返回的通用寄存器。
X0和X1定义了两个XMM寄存器,用于SIMD操作。
接下来定义了一个循环,在这个循环的循环体中,将通过SSE指令处理输入的矩阵数据:
MOVUPS(a.Offset(0), X0):将矩阵a的前16字节(4 个float32)加载到XMM寄存器X0。
MOVUPS(b.Offset(0), X1):将矩阵b的前16字节(4个float32)加载到XMM寄存器X1。
ADDPS(X1, X0):将X1和X0中的数据相加,结果存入X0。
MOVUPS(X0, c.Offset(0)):将结果从X0存入矩阵c的前16字节。
ADDQ(U32(16), a.Base):将矩阵a的基地址增加16字节(4个float32)。
ADDQ(U32(16), b.Base):将矩阵b的基地址增加16字节(4个float32)。
ADDQ(U32(16), c.Base):将矩阵c的基地址增加16字节(4个float32)。
SUBQ(U32(4), n):将矩阵长度n减少4。
JMP(LabelRef("loop")):无条件跳转到标签loop,继续循环。
最后调用Generate函数生成汇编代码。
下面我们就来运行该代码,生成相应的汇编代码以及stub函数:
$cd matadd-sse/pkg
$make
go run asm.go -out add.s -stubs stub.go下面是生产的add.s的全部汇编代码:
// simd-in-go/matadd-sse/pkg/add.s
// Code generated by command: go run asm.go -out add.s -stubs stub.go. DO NOT EDIT.
#include "textflag.h"
// func MatrixAddSIMD(a []float32, b []float32, c []float32)
// Requires: SSE
TEXT ·MatrixAddSIMD(SB), NOSPLIT, $0-72
MOVQ a_base+0(FP), AX
MOVQ b_base+24(FP), CX
MOVQ c_base+48(FP), DX
MOVQ a_len+8(FP), BX
loop:
CMPQ BX, $0x00000004
JL done
MOVUPS (AX), X0
MOVUPS (CX), X1
ADDPS X1, X0
MOVUPS X0, (DX)
ADDQ $0x00000010, AX
ADDQ $0x00000010, CX
ADDQ $0x00000010, DX
SUBQ $0x00000004, BX
JMP loop
done:
RET这里使用的ADDPS、MOVUPS和ADDQ都是SSE指令:
ADDPS (Add Packed Single-Precision Floating-Point Values):这是一个SSE指令,用于对两个128位的XMM寄存器中的4个单精度浮点数进行并行加法运算。
MOVUPS (Move Unaligned Packed Single-Precision Floating-Point Values): 这也是一个SSE指令,用于在内存和XMM寄存器之间移动128位的单精度浮点数数据。与MOVAPS(Move Aligned Packed Single-Precision Floating-Point Values) 指令不同,MOVUPS不要求地址对齐,可以处理非对齐的数据。
除了生成汇编代码外,asm.go还生成了一个stub函数:MatrixAddSIMD,即上面汇编实现的那个函数。
// simd-in-go/matadd-sse/pkg/stub.go
// Code generated by command: go run asm.go -out add.s -stubs stub.go. DO NOT EDIT.
package pkg
func MatrixAddSIMD(a []float32, b []float32, c []float32)在matadd-sse/pkg/add-no-simd.go中,我们放置了常规的矩阵加法的实现:
package pkg
func MatrixAddNonSIMD(a, b, c []float32) {
n := len(a)
for i := 0; i < n; i++ {
c[i] = a[i] + b[i]
}
}接下来,我们编写一些单测代码,确保一下MatrixAddSIMD和MatrixAddNonSIMD的功能是正确的:
// simd-in-go/matadd-sse/matrix_add_test.go
package main
import (
"demo/pkg"
"testing"
)
func TestMatrixAddNonSIMD(t *testing.T) {
size := 1024
a := make([]float32, size)
b := make([]float32, size)
c := make([]float32, size)
expected := make([]float32, size)
for i := 0; i < size; i++ {
a[i] = float32(i)
b[i] = float32(i)
expected[i] = a[i] + b[i]
}
pkg.MatrixAddNonSIMD(a, b, c)
for i := 0; i < size; i++ {
if c[i] != expected[i] {
t.Errorf("MatrixAddNonSIMD: expected %f, got %f at index %d", expected[i], c[i], i)
}
}
}
func TestMatrixAddSIMD(t *testing.T) {
size := 1024
a := make([]float32, size)
b := make([]float32, size)
c := make([]float32, size)
expected := make([]float32, size)
for i := 0; i < size; i++ {
a[i] = float32(i)
b[i] = float32(i)
expected[i] = a[i] + b[i]
}
pkg.MatrixAddSIMD(a, b, c)
for i := 0; i < size; i++ {
if c[i] != expected[i] {
t.Errorf("MatrixAddSIMD: expected %f, got %f at index %d", expected[i], c[i], i)
}
}
}如我们预期的那样,上述单测代码可以顺利通过。接下来,我们再来做一下benchmark,看看使用SSE实现的矩阵加法性能到底提升了多少:
// simd-in-go/matadd-sse/benchmark_test.go
package main
import (
"demo/pkg"
"testing"
)
func BenchmarkMatrixAddNonSIMD(tb *testing.B) {
size := 1024
a := make([]float32, size)
b := make([]float32, size)
c := make([]float32, size)
for i := 0; i < size; i++ {
a[i] = float32(i)
b[i] = float32(i)
}
tb.ResetTimer()
for i := 0; i < tb.N; i++ {
pkg.MatrixAddNonSIMD(a, b, c)
}
}
func BenchmarkMatrixAddSIMD(tb *testing.B) {
size := 1024
a := make([]float32, size)
b := make([]float32, size)
c := make([]float32, size)
for i := 0; i < size; i++ {
a[i] = float32(i)
b[i] = float32(i)
}
tb.ResetTimer()
for i := 0; i < tb.N; i++ {
pkg.MatrixAddSIMD(a, b, c)
}
}运行这个benchmark,我们得到下面结果:
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
... ...
BenchmarkMatrixAddNonSIMD-8 2129426 554.4 ns/op
BenchmarkMatrixAddSIMD-8 3481318 357.4 ns/op
PASS
ok demo 3.350s我们看到SIMD实现的确性能优秀,几乎在非SIMD实现的基础上提升了一倍。但这似乎还并不足以说明SIMD的优秀。我们再来扩展一下并行处理的数据的数量和宽度,使用AVX指令再来实现一版矩阵加法,看是否还会有进一步的性能提升。
4. 第二版SIMD优化(基于AVX)
下面是基于avo使用AVX指令实现的Go代码:
// simd-in-go/matadd-avx/pkg/asm.go
//go:build ignore
// +build ignore
package main
import (
"github.com/mmcloughlin/avo/attr"
. "github.com/mmcloughlin/avo/build"
. "github.com/mmcloughlin/avo/operand"
)
func main() {
TEXT("MatrixAddSIMD", attr.NOSPLIT, "func(a, b, c []float32)")
a := Mem{Base: Load(Param("a").Base(), GP64())}
b := Mem{Base: Load(Param("b").Base(), GP64())}
c := Mem{Base: Load(Param("c").Base(), GP64())}
n := Load(Param("a").Len(), GP64())
Y0 := YMM()
Y1 := YMM()
Label("loop")
CMPQ(n, U32(8))
JL(LabelRef("done"))
VMOVUPS(a.Offset(0), Y0)
VMOVUPS(b.Offset(0), Y1)
VADDPS(Y1, Y0, Y0)
VMOVUPS(Y0, c.Offset(0))
ADDQ(U32(32), a.Base)
ADDQ(U32(32), b.Base)
ADDQ(U32(32), c.Base)
SUBQ(U32(8), n)
JMP(LabelRef("loop"))
Label("done")
RET()
Generate()
}这里的代码与上面sse实现的代码逻辑类似,只是指令换成了avx的指令,包括VMOVUPS、VADDPS等:
VADDPS (Vectorized Add Packed Single-Precision Floating-Point Values): 是AVX (Advanced Vector Extensions) 指令集中的一个指令,用于对两个256位的YMM寄存器中的8个单精度浮点数进行并行加法运算。
VMOVUPS (Vectorized Move Unaligned Packed Single-Precision Floating-Point Values): 这也是一个AVX指令,用于在内存和YMM寄存器之间移动256位的单精度浮点数数据。与MOVUPS指令相比,VMOVUPS可以处理更宽的256位SIMD数据。
由于在SSE实现的版本中做了详细说明,这里就不再赘述代码逻辑,其他单元测试与benchmark测试的代码也都完全相同,我们直接看benchmark的结果:
$go test -bench .
goos: darwin
goarch: amd64
pkg: demo
... ...
BenchmarkMatrixAddNonSIMD-8 2115284 566.6 ns/op
BenchmarkMatrixAddSIMD-8 10703102 111.5 ns/op
PASS
ok demo 3.088s我们看到AVX版的矩阵加法的性能是常规实现的5倍多,是SSE实现的性能的近3倍,在实际生产中,这将大大提升代码的执行效率。
也许还有更优化的实现,但我们已经达到了基于SIMD加速矩阵加法的目的,这里就不再做继续优化了,大家如果有什么新的想法和验证的结果,可以在评论区留言告诉我哦!
5. 小结
在这篇文章中,我们探讨了在Go语言中使用SIMD指令进行计算加速的方法。尽管Go官方目前还没有直接支持SIMD的包,但我们通过使用avo库生成汇编代码的方式,成功实现了基于SSE和AVX指令集的矩阵加法优化。
我们首先介绍了SIMD指令的基本概念和优势,然后讨论了在Go中使用SIMD指令的几种可能方法。接着,我们通过一个具体的矩阵加法示例,展示了如何使用avo库生成基于SSE和AVX指令集的汇编代码。
通过benchmark测试,我们看到基于SSE指令的实现相比常规实现提升了约1.5倍的性能,而基于AVX指令的实现则带来了约5倍的性能提升。这充分说明了SIMD指令在并行计算密集型任务中的强大优势。
虽然直接使用SIMD指令需要一定的汇编知识,增加了代码的复杂性,但在一些对性能要求极高的场景下,这种优化方法仍然是非常有价值的。我希望这篇文章能为Go开发者在进行性能优化时提供一些新的思路和参考。
当然,这里展示的只是SIMD优化的一个简单示例。在实际应用中,可能还需要考虑更多因素,如数据对齐、边界条件处理等。大家可以在此基础上进行更深入的探索和实践。
本文涉及的源码可以在这里[16]下载 - https://github.com/bigwhite/experiments/blob/master/simd-in-go
本文部分源代码由deepseek coder v2[17]实现。
6. 参考资料
Intel Intrinsics Guide[18] - https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
Go Wiki: AVX512[19] - https://go.dev/wiki/AVX512
A Manual for the Plan 9 assembler[20] - http://doc.cat-v.org/plan_9/4th_edition/papers/asm
From slow to SIMD: A Go optimization story[21] - https://sourcegraph.com/blog/slow-to-simd
Efficient and performance-portable vector software[22] - https://github.com/google/highway
并行处理-SIMD[23] - https://www.slidestalk.com/u231/simd_computer
玩转SIMD指令编程[24] - https://zhuanlan.zhihu.com/p/591900754
参考资料
[1]
fasthttp: https://tonybai.com/2021/04/25/server-side-performance-nethttp-vs-fasthttp
[2]Aliaksandr Valialkin: https://github.com/valyala
[3]函数迭代器: https://tonybai.com/2024/06/24/range-over-func-and-package-iter-in-go-1-23/
[4]Go 1.23版本: https://tonybai.com/2024/05/30/go-1-23-foresight/
[5]Rust: https://tonybai.com/tag/rust
[6]近期的一个proposal: https://github.com/golang/go/issues/67520
[7]issue 53171: https://github.com/golang/go/issues/53171
[8]issue 58610: https://github.com/golang/go/issues/58610
[9]Go 1.11版本才开始支持AVX-512指令: https://go.dev/wiki/AVX512
[10]cgo不是go: https://dave.cheney.net/2016/01/18/cgo-is-not-go
[11]c2goasm: https://github.com/minio/c2goasm/
[12]intrisic functions: https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
[13]avo: https://github.com/mmcloughlin/avo
[14]llgo: https://github.com/goplus/llgo
[15]intel intrisic functions for SIMD: https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
[16]这里: https://github.com/bigwhite/experiments/blob/master/simd-in-go
[17]deepseek coder v2: https://chat.deepseek.com/coder
[18]Intel Intrinsics Guide: https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
[19]Go Wiki: AVX512: https://go.dev/wiki/AVX512
[20]A Manual for the Plan 9 assembler: http://doc.cat-v.org/plan_9/4th_edition/papers/asm
[21]From slow to SIMD: A Go optimization story: https://sourcegraph.com/blog/slow-to-simd
[22]Efficient and performance-portable vector software: https://github.com/google/highway
[23]并行处理-SIMD: https://www.slidestalk.com/u231/simd_computer
[24]玩转SIMD指令编程: https://zhuanlan.zhihu.com/p/591900754
[25]Gopher部落知识星球: https://public.zsxq.com/groups/51284458844544
[26]链接地址: https://m.do.co/c/bff6eed92687
推荐阅读:
想要了解Go更多内容,欢迎扫描下方👇关注公众号,扫描 [实战群]二维码 ,即可进群和我们交流~
- 扫码即可加入实战群 -


分享、在看与点赞Go 















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









