






目录
一、KNN
K-近邻算法用作基本分类与回归,其中k是指选择样本集中前k个最相似的数据集,最后从k个最相似的数据集中选出出现次数最多的分类。
二、距离度量
前k个最相似的数据集,这个最相似指的是特征最相似,也就是说k-近邻算法是根据特征比较,得到特征最相似的数据的分类标签,然后找出出现频率最高的标签。那么如何做到特征比较呢?其实就是计算一个样本与另一个样本之间的距离,这个距离就是利用距离公式计算来的。下图第一个公式是两个特征时使用的,第二个是两个特征以上时使用的。
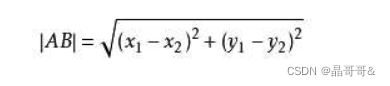
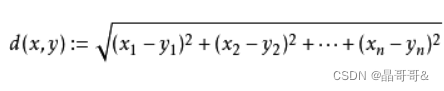
三、实战项目(判断电影类型):主要练习k-近邻算法的实现
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
| 电影1 | 1 | 101 | 爱情片 |
| 电影2 | 5 | 89 | 爱情片 |
| 电影3 | 108 | 5 | 动作片 |
| 电影4 | 115 | 8 | 动作片 |
这个项目中有两个特征:打斗镜头和接吻镜头
1.准备数据集
import numpy as np
'''
主要就是获取特征矩阵和标签列表
'''
def CreatdataSet():
#创建特征矩阵
dataSet=np.array([[1,101],[5,89],[108,5],[115,8]])
#创建标签
labels=['爱情片','爱情片','动作片','动作片']
return dataSet,labels
if __name__=='__main__':
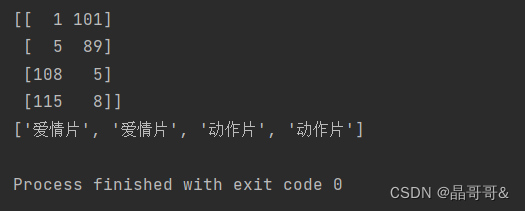
dataSet,labels=CreatdataSet()
print(dataSet)
print(labels)执行的结果是:
2.k-近邻算法
(1)利用距离公式写算法:
'''
参数说明:
inX--指测试集
dataSet--指训练集
labels--指分类标签
k--指找前k个最相似数据
返回值:返回前k个最相似中出现次数最多的标签
'''
def classify0(inX,dataSet,labels,k):
#获取训练集数据集的行数
dataSetsize=dataSet.shape[0]
#训练集数据(矩阵)减去测试集数据(一维)
diffMat=np.tile(inX,(dataSetsize,1))-dataSet
#将减去的后的数据平方
double_diffMat=diffMat**2
#将平方后的数据相加
sum_data=double_diffMat.sum(1)
#相加后再开平方
result_data=sum_data*0.5
#返回result_data中从小到大排序的索引值
sortedDistIndices=result_data.argsort()
classCount={}
for i in range(k):
#提取前k个元素的类别,通过排好序的索引值
voteIlabel=labels[sortedDistIndices[i]]
#计算每个类别的次数
classCount[voteIlable]=classCount.get(voteIlabel,0)+1
#将字典排序,按字典的值排序:key=operator.itemgetter(1)
#按字典的键记性排序:key=operator.itemgetter(0)
sortedClassCount=sotred(classCount.items(),
key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别
return sortedClassCount[0][0]
(2)不会的知识点:
A.numpy的tile()函数
例子:a=np.array([0,1,2])
result=np.tile(a,(2,1)) #表示将a在x轴上复制为1倍,即保持不变,在y轴上复制为2倍
结果为:
[[0,1,2],
[0,1,2]]
B.列表(矩阵)的sum()
对于列表--->sum(list)将列表中的所有数相加即可
对于矩阵--->x=np.array([[1,2],[3,4]])
sum(1) #按行相加(行内部相加)
例如:np.sum(a,axis=1)或这样写x.sum(1)
结果为:[3,7]
sum(0)#按列相加,列内部相加
例如:np.sum(x,axis=0)或这样写x.sum(0)
结果为:[4,6]
sum()还有一个关键字,确定是否保持几维特性
例如:np.sum(x,axis=1,keepdims=True)
结果为:[[3],[7]]
C.nump模块中的argsort()函数
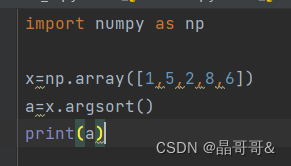
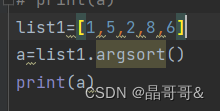
第一种用法:将数组中的元素从小到大排序后的索引值构成的数组返回(注:列表中没有argsort()),原数组不受影响
使用效果如下:
错误结果示范:

第二种用法:若为二维数组,要区分是按行还是按列排序
np.argsort(x,axis=0)#按列排序
np.argsort(x,axis=1)#按行排序
第三中用法:升序排列还是降序排列
默认为升序排列,若想要降序排列在数组前加‘-’符号,例如:np.argsort(-x)
第四种用法:通过索引值获得排序后的数组
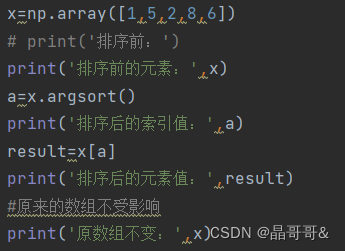

D.字典中的ge(key,dufault)方法
返回字典中指定键key的值,若不存在,返回指定的默认值default
E.字典的排序方法sorted()
sorted(dict.items(),key=operator.itemgetter(0或1),reverse=True或False)
解析:python3中用items()代替python2中的iteritems()
operator.itemgetter(0)根据字典的键进行排序
operator.itemgetter(1)根据字典的值进行排序
reverse用来确定是否进行降序排列
下面是算法的运行结果:
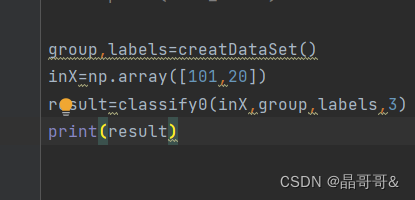
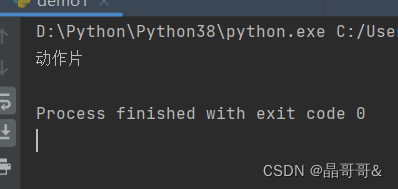
批注:我学习的博主Jack Cui,网址:Jack Cui | 关注人工智能及互联网的个人网站 (cuijiahua.com)
我就是看他的学习记录学习的,详细学习内容可进入他的网站学习。我写文章主要目的是为了再次熟悉代码和记录不会的知识点。















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









