










(有关公式、基本理论等大量内容摘自《动手学深度学习》(TF2.0版))
多层感知机是什么?
个人的理解就是:多层的神经网络+非线形的。具体说说就是至少包含一层隐含层和输出层构成多层,非线性这个概念可以通过下面的内容来学习,由激活函数实现的线性到非线形的映射。
隐藏层、多层神经网络的相关知识


通过最后一段话可以发现,对于线性的神经网络,不论是多少层都等价于单层神经网络,所以对于线性的模型,多少层都没有意义,当每层转化为非线形后,上述等价式即无法成立,可以得出,多层感知机所表示的模型(多层+非线形),不同的层次所代表的含义不同。下面将解释如何实现线性到非线形的转换,即激活函数。
激活函数

常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。
ReLU函数:只保留正数元素,并将负数元素清零
![]()
其图像:

其导数图像:

sigmoid函数:可以将元素的值变换到0和1之间
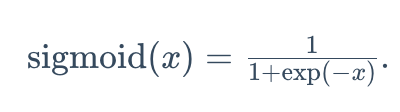
其图像:

其导数图像:

tanh函数:可以将元素的值变换到-1和1之间
![]()
其图像:

其导数图像:

多层感知机

通过上述公式可以发现引入激活函数后多层感知机并不等价与单层的感知机。
多层感知机从零开始实现
import tensorflow as tf
import numpy as np
import sys
print(tf.__version__)
#加载数据集
from tensorflow.keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
#设置神经元个数
batch_size = 256
#归一化
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
x_train = x_train/255.0
x_test = x_test/255.0
#将训练集合和测试集合转换成Dataset类型
train_iter = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)
test_iter = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(batch_size)
#定义模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = tf.Variable(tf.random.normal(shape=(num_inputs, num_hiddens),mean=0, stddev=0.01, dtype=tf.float32))
b1 = tf.Variable(tf.zeros(num_hiddens, dtype=tf.float32))
W2 = tf.Variable(tf.random.normal(shape=(num_hiddens, num_outputs),mean=0, stddev=0.01, dtype=tf.float32))
b2 = tf.Variable(tf.random.normal([num_outputs], stddev=0.1))
#定义激活函数,实现relu函数
def relu(x):
return tf.math.maximum(x,0)
#定义网络
def net(X):
X = tf.reshape(X, shape=[-1, num_inputs])
h = relu(tf.matmul(X, W1) + b1)
return tf.math.softmax(tf.matmul(h, W2) + b2)
#定义损失函数
def loss(y_hat,y_true):
return tf.losses.sparse_categorical_crossentropy(y_true,y_hat)
#定义参数
num_epochs, lr = 5, 0.5
params = [W1, b1, W2, b2]
num_epochs, lr = 5, 0.1
# 描述,对于tensorflow2中,比较的双方必须类型都是int型,所以要将输出和标签都转为int型
#定义求准确率的函数
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for _, (X, y) in enumerate(data_iter):
y = tf.cast(y,dtype=tf.int64)
acc_sum += np.sum(tf.cast(tf.argmax(net(X), axis=1), dtype=tf.int64) == y)
n += y.shape[0]
return acc_sum / n
#训练模型
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, trainer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
with tf.GradientTape() as tape:
y_hat = net(X)
l = tf.reduce_sum(loss(y_hat, y))
grads = tape.gradient(l, params)
if trainer is None:
# 如果没有传入优化器,则使用原先编写的小批量随机梯度下降
for i, param in enumerate(params):
param.assign_sub(lr * grads[i] / batch_size)
else:
# tf.keras.optimizers.SGD 直接使用是随机梯度下降 theta(t+1) = theta(t) - learning_rate * gradient
# 这里使用批量梯度下降,需要对梯度除以 batch_size, 对应原书代码的 trainer.step(batch_size)
trainer.apply_gradients(zip([grad / batch_size for grad in grads], params))
y = tf.cast(y, dtype=tf.float32)
train_l_sum += l.numpy()
train_acc_sum += tf.reduce_sum(tf.cast(tf.argmax(y_hat, axis=1) == tf.cast(y, dtype=tf.int64), dtype=tf.int64)).numpy()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
trainer = tf.keras.optimizers.SGD(lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
多层感知机的简单实现
import tensorflow as tf
from tensorflow import keras
import sys
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
#定义模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(256, activation='relu',),
tf.keras.layers.Dense(10, activation='softmax')
])
#加载数据集
fashion_mnist = keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
#加载参数
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.5),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
#模型的训练
model.fit(x_train, y_train, epochs=50,
batch_size=256,
validation_data=(x_test, y_test),
validation_freq=1)















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









