








但问耕耘,莫问前程
上一篇呢,讲了排序中较为复杂的排序——堆排序。这一篇主要围绕,直接插入、希尔、选择、冒泡排序、计数排序总结。
(1)直接插入排序:
插入排序的实现:
直接插入排序的思想很简单,就是把前K个数看成有序,再让后K个数有序插入到K个有序序列中。
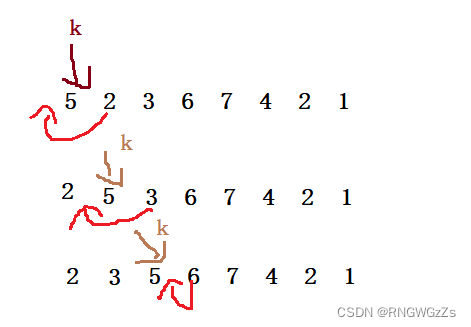
首先封装个打印排序后数组的函数和原始数组
void PrintSort(int* a, int n)
{
for (int i = 0;i < n;i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void TestInsertSort()
{
int arr[] = { 4,6,7,3,2,8,9,1,5,0 };
InsertSort(arr,sizeof(arr)/sizeof(int));
PrintSort(arr, sizeof(arr) / sizeof(int));
}在写排序代码的时候,更偏向于先写一趟排序的思想,再来写整个排序的过程。

所以在设置end位置的时候是很重要的。所以我们可以在外层套一个循环,每次移动完数据后,及时更新end。
for (int i = 0;i < n;i++)
{
int end = i; //有序的区间
int tmp = a[end + 1];
while(end>=0)
{
if (a[end] > tmp)
{
a[end+1]=a[end]; //end+1 < end end的数往后挪
end--;
}
else
{
a[end + 1] = tmp;
}
}
}
代码优化如下:
for (int i = 0;i < n-1;i++)
{
int end = i; //有序的区间
int tmp = a[end + 1];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end+1] = a[end ]; //如果小 则让end往后挪
end--;
}
else
{
break;
}
}
a[end + 1] = tmp; //再把保存的原end+1的数给到对的位置
}还有一点值得注意:
在设计外层循环的时候,一定是n-1 ,而不是n。因为当n=10,那么i=9的时候,end+1一定会越界访问元素。

一个极小的数(随机数)被end+1访问,并插在了最前面。

插入排序的性能:
可以看出,插入排序 会把数组的每个元素走一遍。所以它最坏的时间复杂度O(N^2)。例如降序。
没有多余的空间开辟,空间复杂度为O(1)。
且它是一种稳定的排序。
(2)希尔排序:
希尔排序本质上,是对直接插入排序的优化,其思想也就比直接插入排序复杂,实现起来也较为复杂。比起直接插入排序,希尔排序多个预排序的概念。
预排序:让一个数组的序列接近有序。
让间隔为gap的数 先进行预排。

为什么要设置这个gap 的概念了?
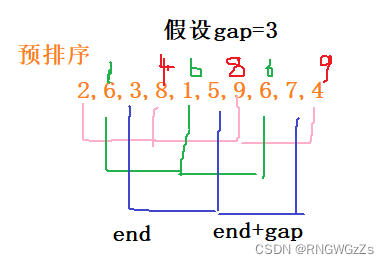
我们可以试想一下,如果没有gap,也就是每次移动一次。9在0~9里面的首位,需要挪动9次才能到末尾。但如果有gap的存在,当gap=3时,只需要三次就可以了。极大地提高了效率。

假设gap=3;
int end = 0;
int gap = 3;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
for (int i = 0;i < n-gap;i++)
{
//预排序进行的一趟预排序
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}为什么趟数的i<n-gap个?

根据上面的规律,当gap越小,也就越接近于有序,那么当gap=1的时候,也就是直接插入排序了。
这里对gap 的变量理解有两种:

第一种:

第二种:

最后:
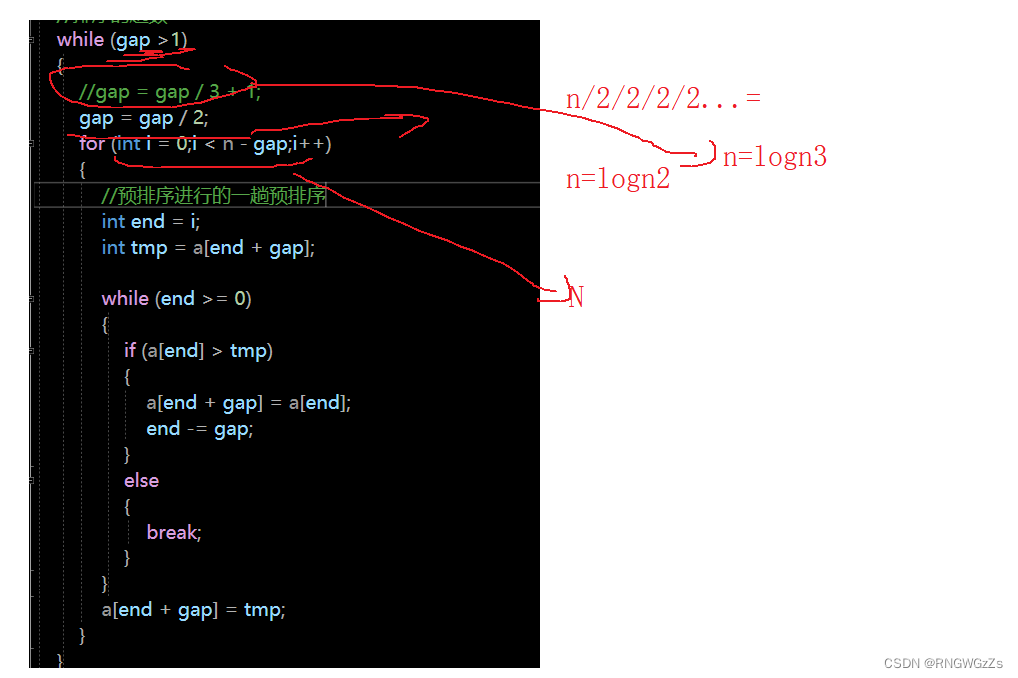
int gap = n;
//gap情况下的排序
while (gap >1)
{
//gap = gap / 3 + 1;
gap = gap / 2;
//排序的趟数
for (int i = 0;i < n - gap;i++)
{
//预排序进行的一趟预排序
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}希尔排序的性能:
官方给的希尔排序的时间复杂度为O(N^1.3~N^2);
但就我而言,我认为希尔排序的时间复杂度为O(N*㏒₂N~N*log₃N)。
但希尔排序的不稳定,因为你不知道预排序的时候,相同数的相对位置有什么变化。
(3)选择排序:

int left = 0;
int right = n - 1;
while (left < right)
{
int minIndex = left;
int maxIndex = left;
//每次left都有变动 用i的区间 来控制left 和 right!!
for (int i = left;i <=right;i++)
{
if (a[i] < a[minIndex])
{
minIndex = i;
}
if (a[i] > a[maxIndex])
{
maxIndex = i;
}
}
Swap(&a[minIndex], &a[left]);
//这里需要注意
Swap(&a[maxIndex], &a[right]);
++left;
--right;
}因为比较简单也就不过多分析,
不过在找数组最大、最小值到时候,外层循环的i一定要跟着left走!
但是此时的代码仍然存在问题!

//加上个修正就行了
Swap(&a[minIndex], &a[left]);
//这里需要注意
if (maxIndex == left)
{
maxIndex=minIndex;
}
Swap(&a[maxIndex], &a[right]);
选择排序的性能:
选择排序犹豫它 排序要遍历整个数组,效率极低,所以在实际中很少用。
时间复杂度达到O(N^2); 且不稳定。
(4)冒泡(交换)排序:
冒泡排序是初学者 首先接触到的排序方式。
基本思想:

//总共执行多少趟?
for (int i = 0;i < n;i++)
{
//每趟冒泡交换的次数 i为控制每趟排序的个数
for (int j = 0;j < n - 1-i;j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], &a[j + 1]);
}
}
}当然,可以对冒泡排序做一个优化。也就是当已经是有序(升序)的情况下,也就不用再交换。

 冒泡排序的性能:
冒泡排序的性能:
冒泡排序比较的对数为n-1,n-2,n-3......2,1,成等差数列
因此冒泡排序的时间复杂度也较高O(N^2):
但具有稳定性!!
(5)计数排序:
基本思想:
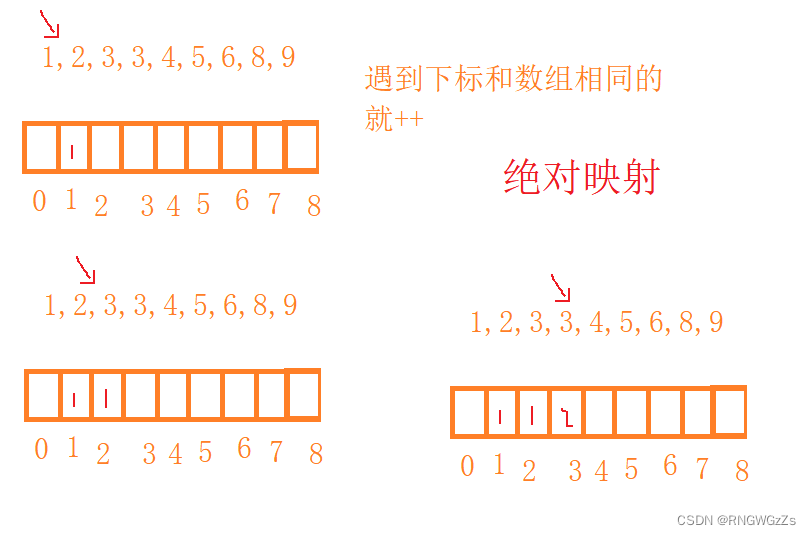
计数排序的思想很简单,开辟一个和原数组同样大的数组,并以此作为原数组对应位置数的映射。
最后依次写回数组。

int max = a[0];
int min = a[0];
//确定最大值和最小值 找到范围range
for (int i = 0;i < n;++i)
{
if (a[i] > a[max])
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min + 1;
//+1? 0~9个数 9-0=9; 但事实上有10个数
//开辟计数数组
int* Count = (int*)malloc(sizeof(int) * range);
memset(Count, 0, sizeof(int) * range);完成找到range和开辟数组后,就开始计数。
//计数
for (int i = 0;i <n;i++)
{
//在下标a[i]-min 的处 ++;
Count[a[i] - min]++;
}
//控制原数组的起始位置
int i = 0;
//拷回
for (int j = 0;j <range ;j++)
{
while (Count[j]--) //记录有多少个同样的数
{
a[i++] = j + min;
}
}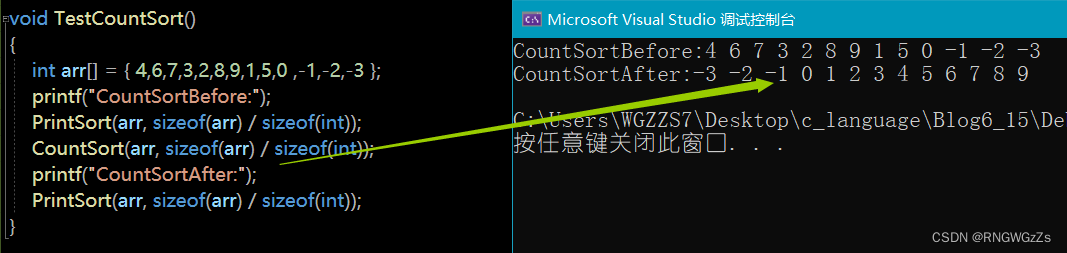

计数排序的性能:
计数排序的时间复杂度可以达到O(N+range),是一种很厉害的排序。
空间复杂度也在O(range);

当然,计数排序的局限性在于很适用于,大范围 数据密集的情况下;
第二篇的排序内容也就讲完了~
感谢你阅读,祝你好运~
















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









