








-----------远途的路固然值得探索,但当下的路也应踏实
上篇讲了大部分的排序思想,那么这篇博客呢,也是承接上篇博客的排序。围绕比较复杂的快排、归并排序来讲。
(1)快速排序:
快速排序的思想很简单:
任取一个值作为key值(比较值)。要的结果是——比key大的在右边,比key小的在左边。分成<key 的和>key的区间。并重复一样的操作。直到让每个元素在相应位置为止。
①PartSort1(hoare版)
hoare 也称 左右指针法。是最早的快排思想。

int left = 0;
int right = n - 1;
//找到key
int keyi = left;
//一趟key
while (left < right)
{
//先让right走?
while (left< right && a[right] >= a[keyi])
right--;
while (left < right && a[left] <= a[keyi])
left++;
Swap(&a[left], &a[right]);
}
//最后left 再与key值 交换 把key排到该排的位置
Swap(&a[left], &a[keyi]);
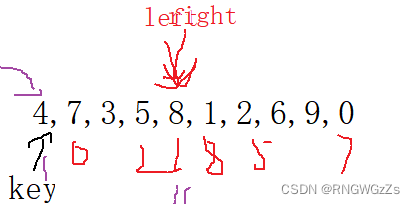
上图说明,进行一次快排,可以让key 排到自己有序序列的位置。
下面的问题是常常会犯的错误:
为什么要让right(右指针先走)?

为什么比较要+等号?前面不是已经有限制条件了吗,为什么还要加?


实现多趟快排1(递归版):

因为要递归,仅仅需要上面hoare找到返回排好的k 的分离点,此时分离点不是在keyi的下标,而是在left的下标。 把这个函数抽象出来
//hoare
int PartSort1(int* a,int left,int right)
{
//找到key
int keyi = left;
//一趟key
while (left < right)
{
//先让right走?
while (left < right && a[right] >= a[keyi])
right--;
while (left < right && a[left] <= a[keyi])
left++;
Swap(&a[left], &a[right]);
}
Swap(&a[left], &a[keyi]);
return left; //left的值和keyi发生交换 但keyi在的位置是left!!
}因为抽象出来的函数,需要left 和 right 下标 ,所以对原先QuickSort函数就要改一改参数。
void QuickSort(int* a,int left,int right)
{
int keyIndext = PartSort1(a, left, right);
//此时得到keyIndex 把原数组分为两个区间
//[left,keyIndex-1] [keyIndex+1,right]
QuickSort(a, left, keyIndex - 1);
QuickSort(a, keyIndex + 1, right);
}既然是递归,那一定得有递归的终止条件>
void QuickSort(int* a,int left,int right)
{
if (left >= right) //终止条件
return;
int keyIndex = PartSort1(a, left, right);
//此时得到keyIndex 把原数组分为两个区间
//[left,keyIndex-1] [keyIndex+1,right]
QuickSort(a, left, keyIndex - 1);
QuickSort(a, keyIndex + 1, right);
}最后也就排序完成啦~
此刻有个小插曲,找key值的另外两种方法~:
①挖坑法:
什么是挖坑法呢。其实就是把key值的位置,当成坑。先从右边找小的值,填入。此时右边小的值又成为一个新的坑……

int PartSort2(int a[], int left, int right)
{
int keyIndex = GetMid(a, left, right);
std::swap(a[keyIndex], a[left]);
//比较值
int key = a[left];
//从左边填
int hole = left;
while (left < right)
{
//左边出现坑 在右边找比pivot小的值
while (left < right && a[right] >= key)
{
--right;
}
//找到了 进行左填坑 自己变为坑
a[hole] = a[right];
hole = right;
//找到了 进行右填坑 自己变为坑
while (left < right && a[left] <= key)
{
++left;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
} 
②前后指针法:
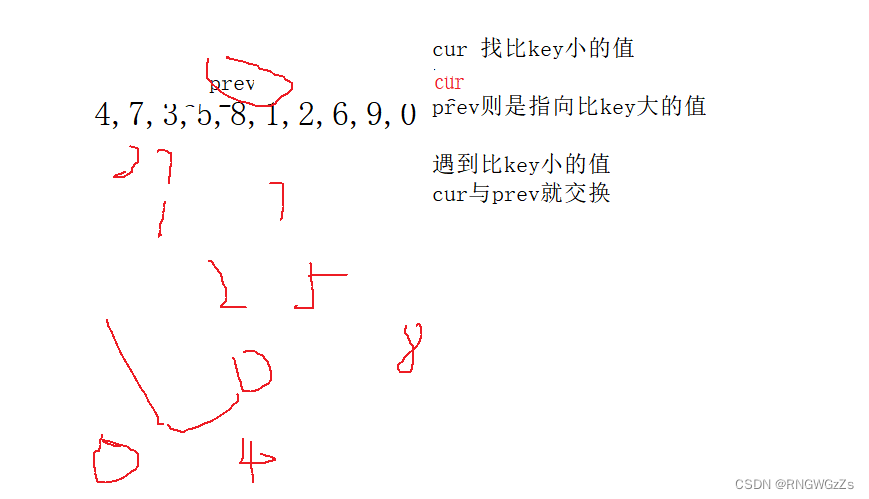
int cur = left+1;
int prev = left;
int keyi = left;
while (cur <=right)
{
if (a[cur] < a[keyi] && prev++ != cur)
{
//这里解释为什么加个条件判断..因为如果cur prev都指向同一个数,也就没必要交换。当然不加也要的
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
return prev; 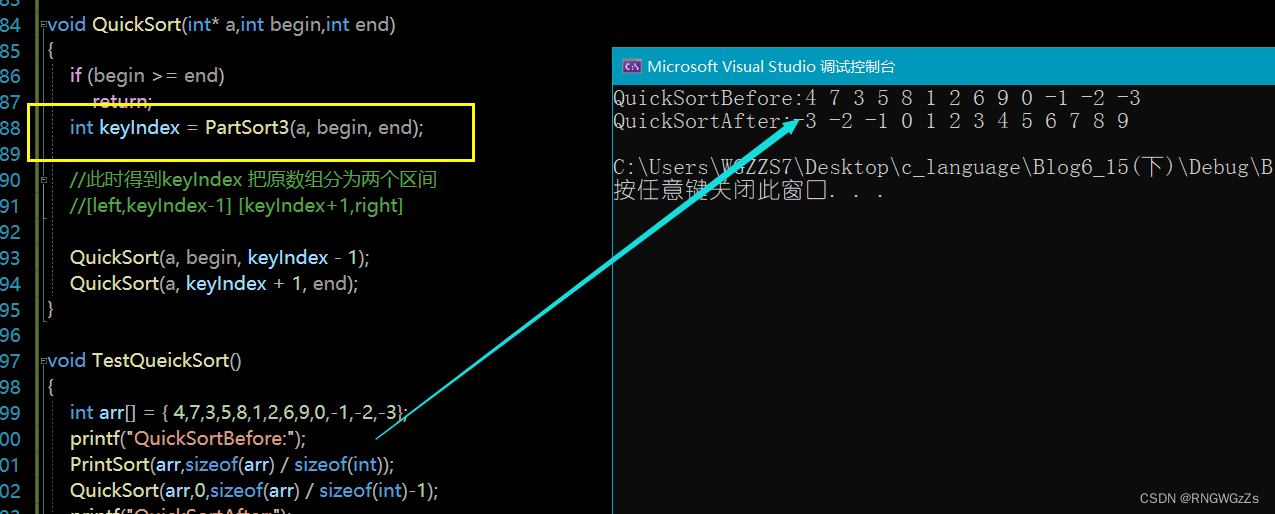
关于找key值也就告一段落。
可能有人会问,如果是升序,每次找的key都是最小的。每次排序都会从第一个到最后一个排,最坏的情况下达到的时间复杂度O(N^2),还不如直接插入排序来得直接、简洁。
针对这个问题,就有必要对快排进行一定的优化。
快速排序的优化:
①key值的该如何找?
我们不难看出,如果key值取得足够得二分,那么快排分的区间越接近二分,效率也越高。
所以就想到一个三数取中的办法,确定key值。
int GetMid(int* a, int left, int right)
{
int MidIndex = (left + right) >> 1;
if (a[left] < a[MidIndex])
{
if (a[MidIndex] < a[right])
{
return MidIndex;
}//a[MidIndex] > a[right]
else if (a[right] < a[left])
{
return left;
}
else
{
return right;
}
}
else //a[minIndex] < a[left]
{
if (a[MidIndex] > a[right])
{
return MidIndex;
}
else if (a[right] > a[left])
{
return left;
}
else
{
return right;
}
}
}三数取中的代码较为绕,但是细细去分还是能够很好的理解的。
截图一部分:

②小区间的优化:
在现如今的编译器和cpu,递归造成的性能损耗,并不那么严重。只是可能,当递归的层次足够深时,会导致栈溢出。而快排的递归排序,把它看出接近二分法的递归,建立栈帧,有很多次。
越递归到下面,建立的栈帧数量越多。但是其本身的数字群很小。
所以可以借助其他排序,来砍掉这部分冗杂的、数字量小,数量大的群体。
void InsertSort(int* a, int n)
{
for (int i = 0;i < n-1;i++)
{
int end = i;
int tmp = a[end + 1];
while (end > 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
end--;
}
else //end 减 为-1 或tmp大的时候
{
break;
}
}
a[end + 1] = tmp;
}
}
if (begin - end > 10)
{
QuickSort(a, begin, keyIndex - 1);
QuickSort(a, keyIndex + 1, end);
}
else
{
InsertSort(a+begin,end- begin +1);
}
InsertSort 的参数设计需要多加考量。建议就是多画图。
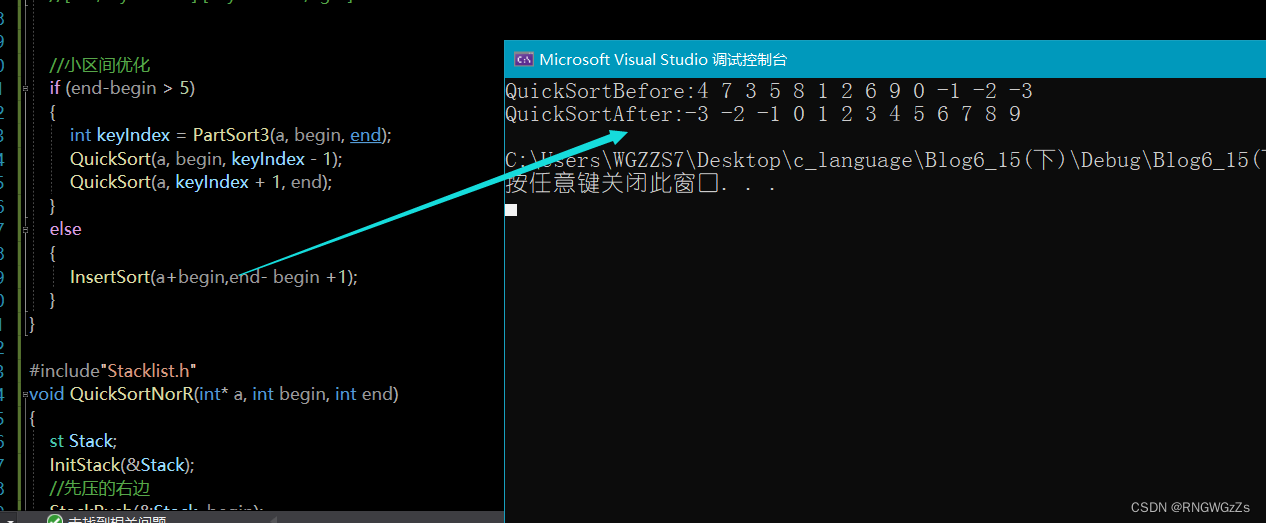
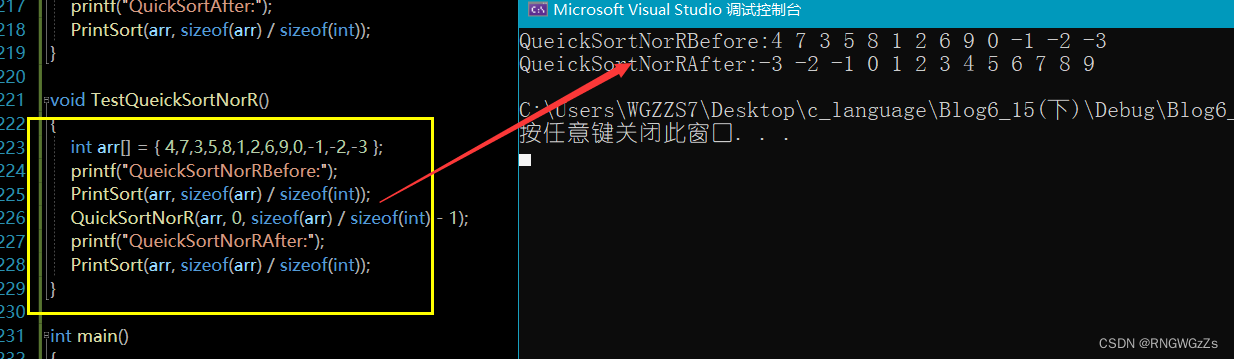
实现快排多趟2(非递归):


void QuickSortNorR(int* a, int begin, int end)
{
st Stack;
InitStack(&Stack);
//先压的右边
StackPush(&Stack, begin);
StackPush(&Stack, end);
//不为空就不出来
while (!EmptyStack(&Stack))
{
//先压 的end 就先取出begin
int right = StackTop(&Stack);
StackPop(&Stack);
int left = StackTop(&Stack);
StackPop(&Stack);
//0 ,9
//找三数
int keyi = PartSort1(a, left, right);
//压入左右区间
if (left < keyi - 1)
{
StackPush(&Stack, left);
StackPush(&Stack, keyi - 1);
}
if (keyi + 1 < end)
{
StackPush(&Stack, keyi + 1);
StackPush(&Stack, end);
}
}
DelStack(&Stack);
}
快速排序的性能:
快排是很强悍的排序方法,在做到上面所述的三数取中、小区间优化(较大的数有明显变化)
时间复杂度可以达到:O(N*logN);
在使用栈的情况,空间复杂度为O(N);
但不具有稳定性。
(2)归并排序
基本思想:
归并排序的实现1(递归):
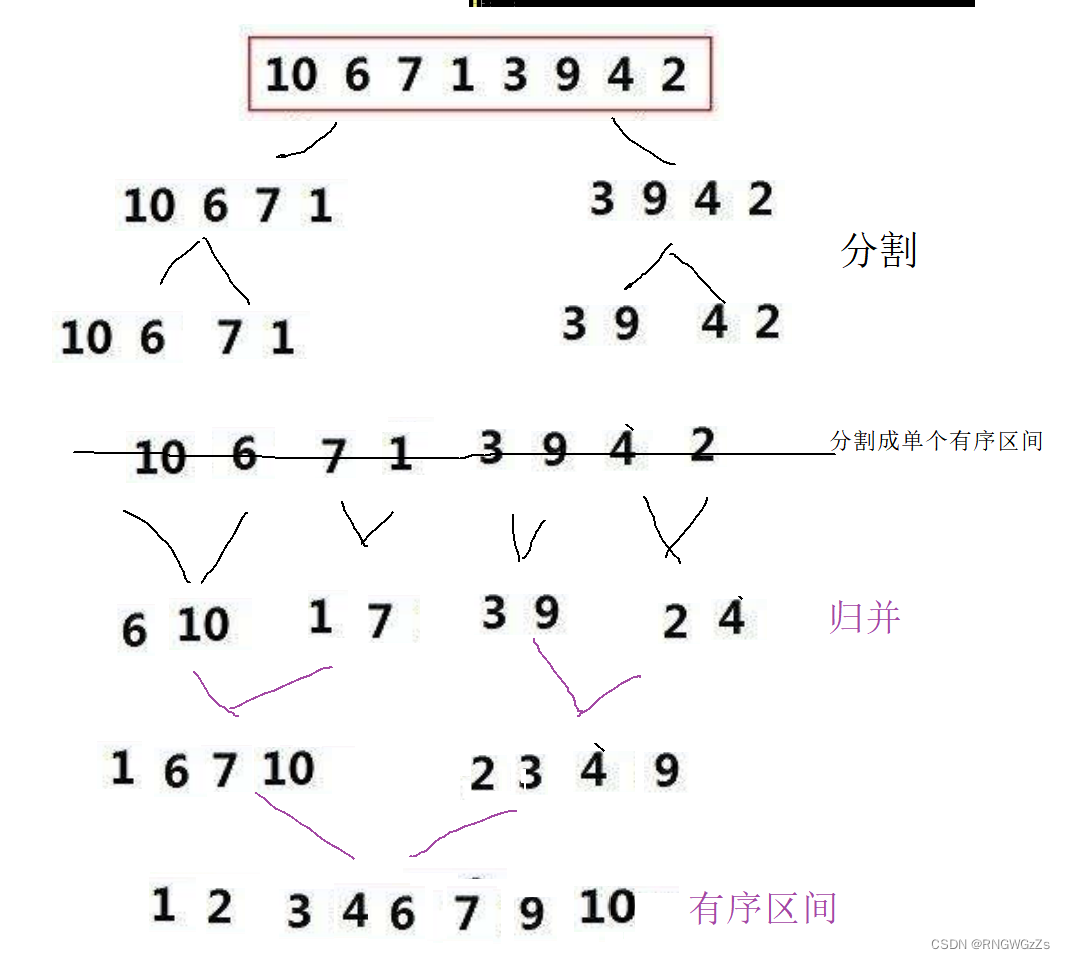
分割后的合并,需要借助新的数组来保存 合并后的值,以便于拷贝回到原区间。
void MergeSort(int* a, int begin,int end)
{
//开辟同样大小的数组
int* tmp = (int*)malloc(sizeof(int) * n);
//因为牵涉到递归,不用每次都开辟一个同样大小的空间数组
_MergeSort(a, begin,end,tmp);
free(tmp);
}
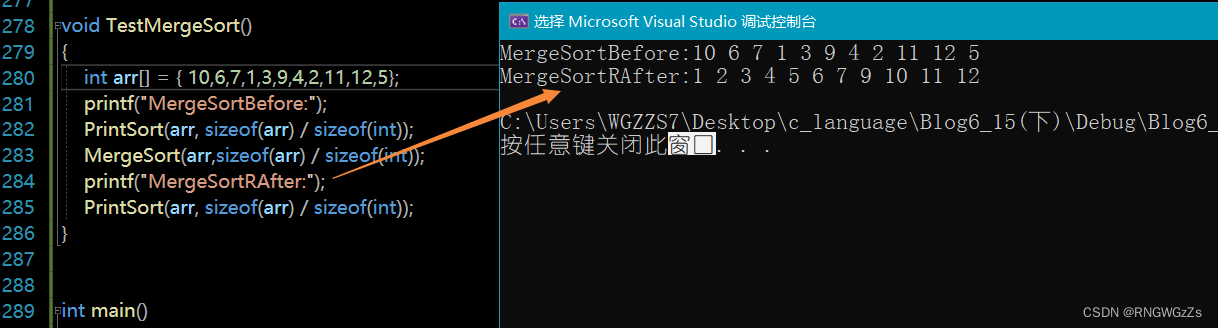
void TestMergeSort()
{
int arr[] = { 10,6,7,1,3,9,4,2 };
printf("MergeSortBefore:");
PrintSort(arr, sizeof(arr) / sizeof(int));
MergeSort(arr,0,sizeof(arr) / sizeof(int)-1); //参数这里选择传三个
printf("MergeSortRAfter:");
PrintSort(arr, sizeof(arr) / sizeof(int));
}
对子函数_MergeSort的编写,主要就分为两个大的方向。
1.分割 2.归并 并写回:
void _MergeSort(int* a, int left, int right, int* tmp)
{
//分割递归终止条件
if (left >= right)
return;
//用中数 分割
int mid = (left + right) >> 1;
//[left,mid] [mid+1,right];
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//合并
//合并就类似于合并两个有序数组
//两区间 两数组
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
//小的值拿下来
int i = left; //为什么要由left控制?因为每个区间开头就是left
while (begin1 <= end1 && begin2 <= end2) //其中一个数组终止 就结束
{
if (a[begin1] < a[begin2])
tmp[i++] = a[begin1++];
else
tmp[i++] = a[begin2++];
}
while (begin1 <= end1)
tmp[i++] = a[begin1++];
while (begin2<=end2)
tmp[i++] = a[begin2++];
//拷回去
//j从什么地方开始 从什么地方结束?
for (int j = left;j <= right;j++)
{
a[j] = tmp[j];
}
}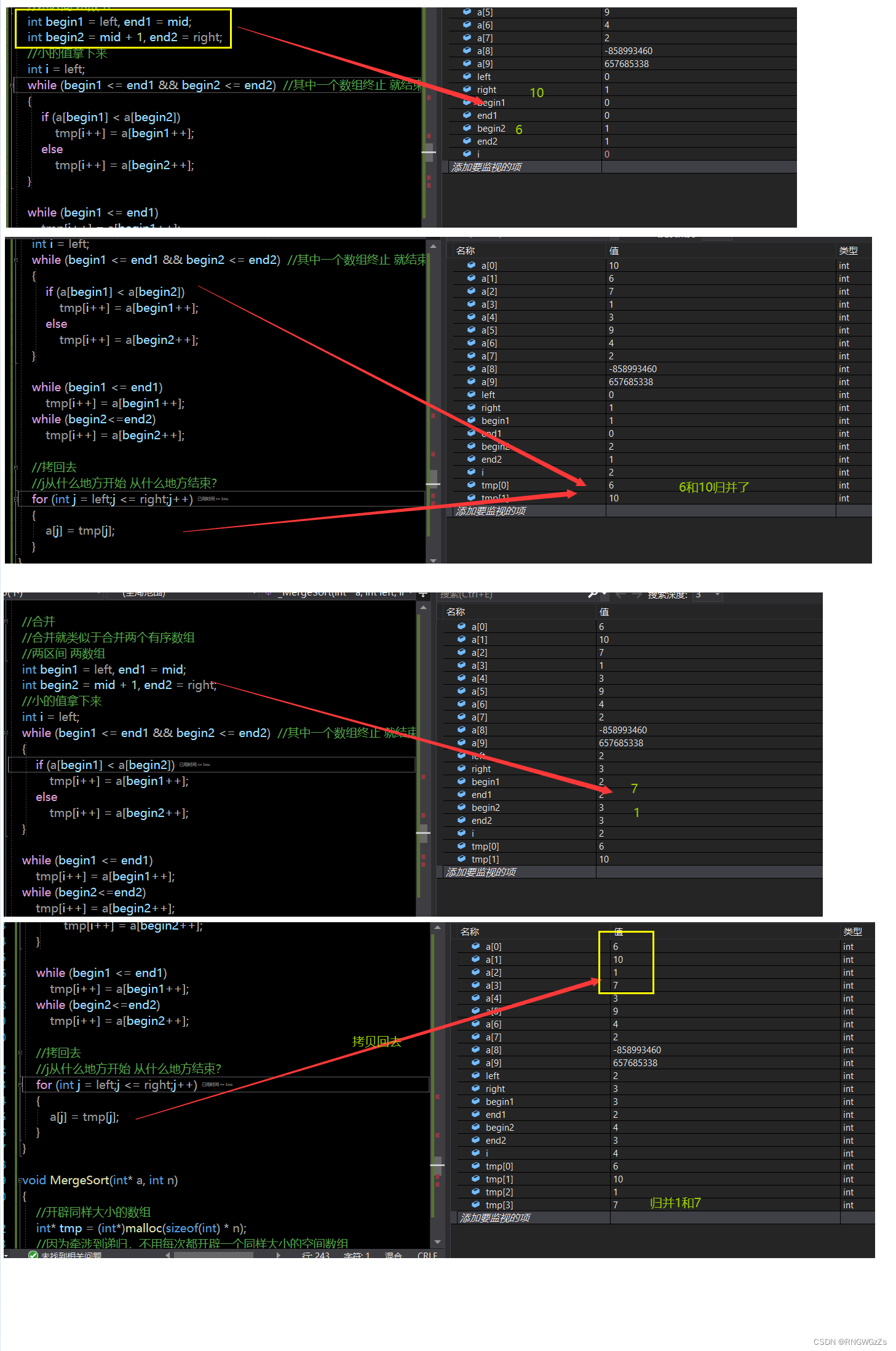
理解分割、归并的过程,通过调试是很有效的方法。希望能帮助你。

归并排序的实现2(非递归) :
什么!还有非递归?一个递归就弄得晕头转向了还来个非递归?!
是的。
因为非递归和递归版的归并的代码部分相同,所以先抽象出这个部分。
非递归版,和递归版,无非只差别在,分割区间上。需要手动分割
void _MergeSortNorR(int* a,int begin1,int end1,int begin2,int end2,int* tmp)
{
int i = left; //为什么要由left控制?因为每个区间开头就是left
while (begin1 <= end1 && begin2 <= end2) //其中一个数组终止 就结束
{
if (a[begin1] < a[begin2])
tmp[i++] = a[begin1++];
else
tmp[i++] = a[begin2++];
}
while (begin1 <= end1)
tmp[i++] = a[begin1++];
while (begin2 <= end2)
tmp[i++] = a[begin2++];
//拷回去
//j从什么地方开始 从什么地方结束?
for (int j = left;j <= right;j++)
{
a[j] = tmp[j];
}
}
所以在设计,非递归版归并的子函数时,参数较多。
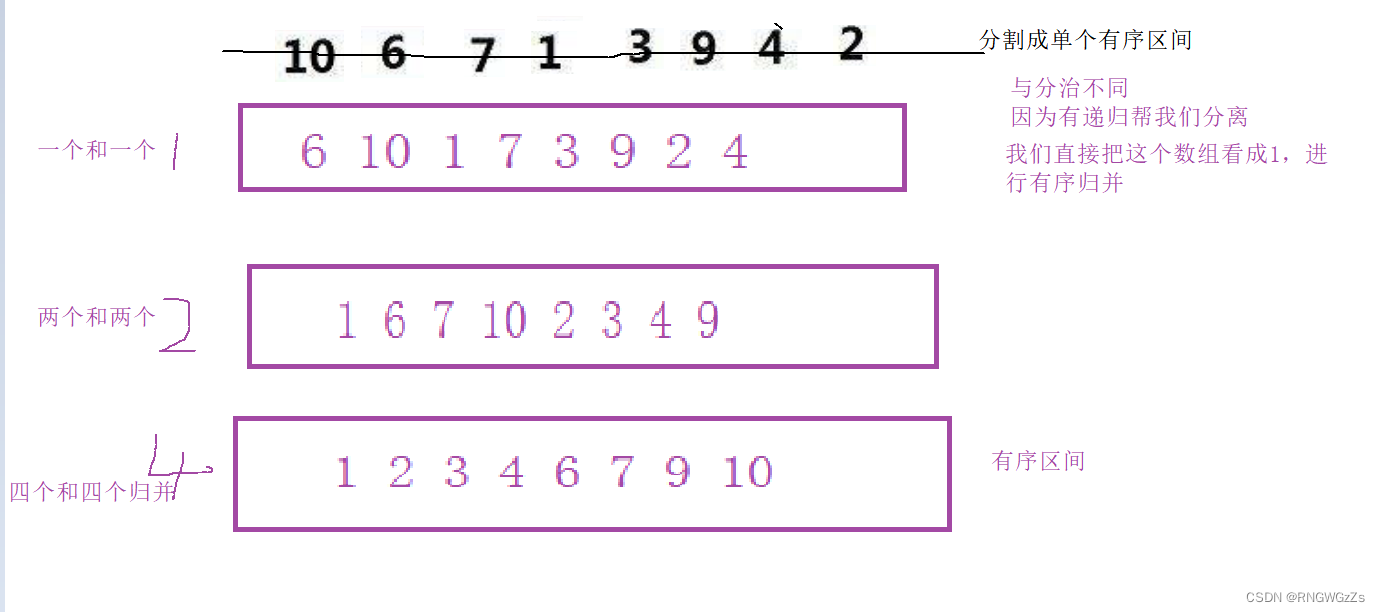
所以我们引入了gap的概念,作为归并的序列有几个。

根据gap的大小,即这次归并要归多少个数~算出gap和下标的关系。
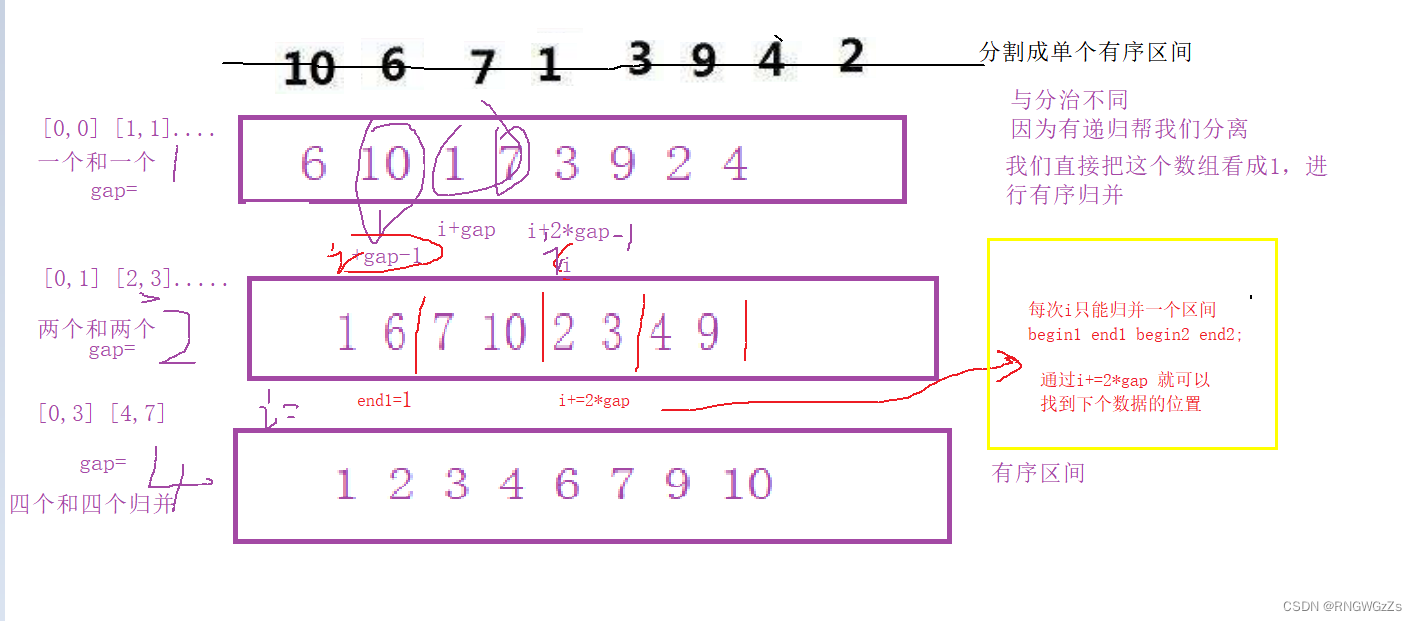 当然这不是最终的代码,此代码仍然有会出现bug的情况。
当然这不是最终的代码,此代码仍然有会出现bug的情况。
void MergeSortNorR(int* a, int n)
{
int* tmp =(int*)malloc(sizeof(int)*n);
int gap = 1;
while (gap < n)
{
//注每次循环i 仅能归并一个
for (int i = 0;i < n;i += 2*gap) //i+=2*gap; 下一个区间
{
//取出每个gap的区间
int begin1 = i, end1 = i + gap - 1, begin2 = i + gap, end2 = i + 2 * gap - 1;
_MergeSortNorR(a, begin1, end1, begin2, end2, tmp);
}
gap *= 2; // 控制每次归并的个数
}
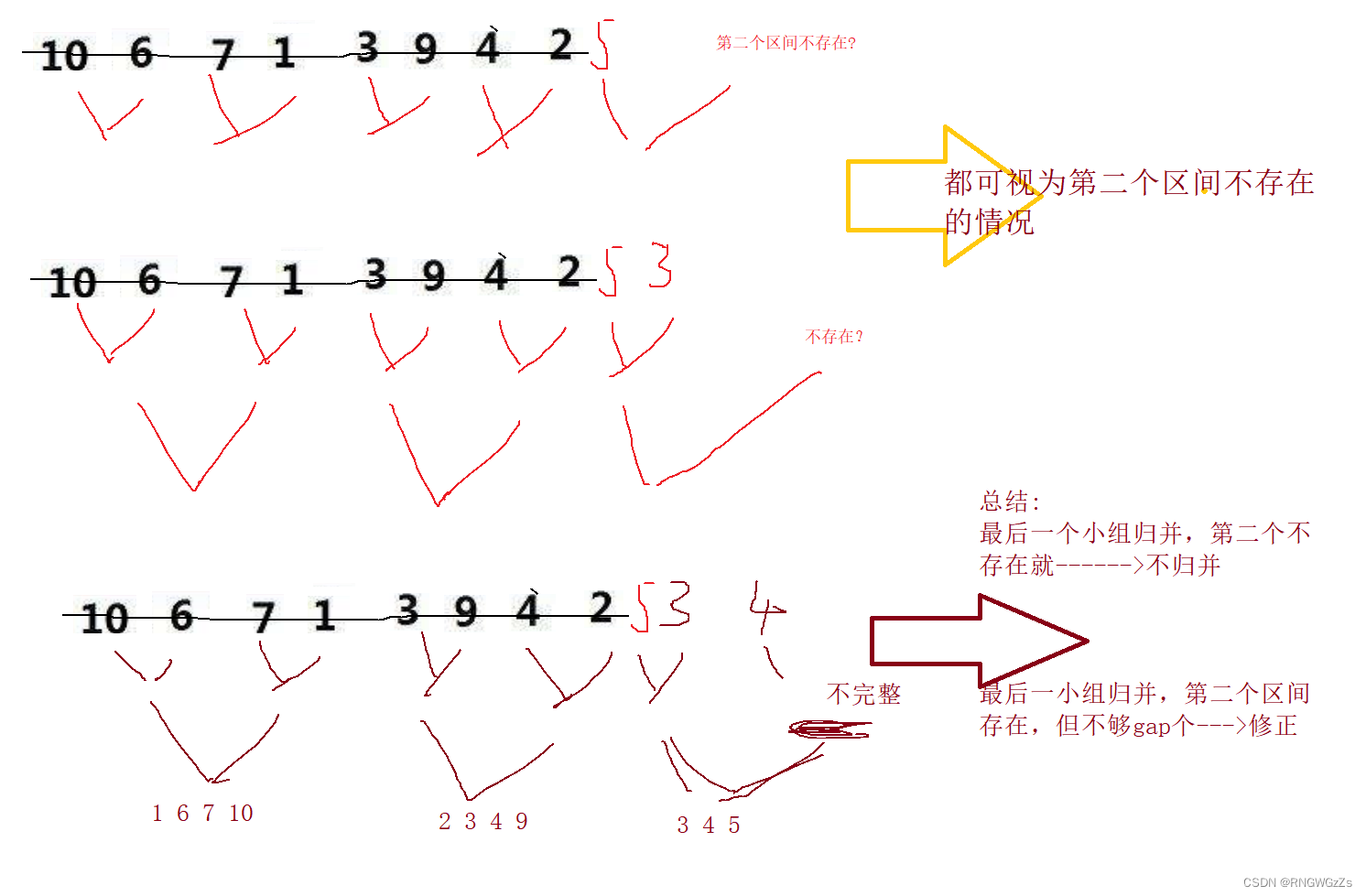
}特殊情况:
void MergeSortNorR(int* a, int n)
{
int* tmp =(int*)malloc(sizeof(int)*n);
int gap = 1;
while (gap < n)
{
//注每次循环i 仅能归并一个
for (int i = 0;i < n;i += 2*gap) //i+=2*gap;
{
//取出每个gap的区间
int begin1 = i, end1 = i + gap - 1, begin2 = i + gap, end2 = i + 2 * gap - 1;
//如果第二个区间不存在
if (begin2 >=n)
{
break; //也就不归并了
}
//如果是第二区间缺少 造成越界
if (end2 >=n)
{
//修正
end2 = n - 1;
}
_MergeSortNorR(a, begin1, end1, begin2, end2, tmp);
}
gap *= 2;
}
}
最后也完成了~
感谢你的阅读,祝你好运~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









