






Spark Streaming的Exactly-One的事务处理
“Exactly-One的事务处理”的含义: 1)不丢失数据 2)不重复处理数据
Spark Streaming + Kafka是实现只一次性事务处理的最优解决方案!
我们下面详细分析一下过程
Spark Streaming应用的运行架构大致如下:
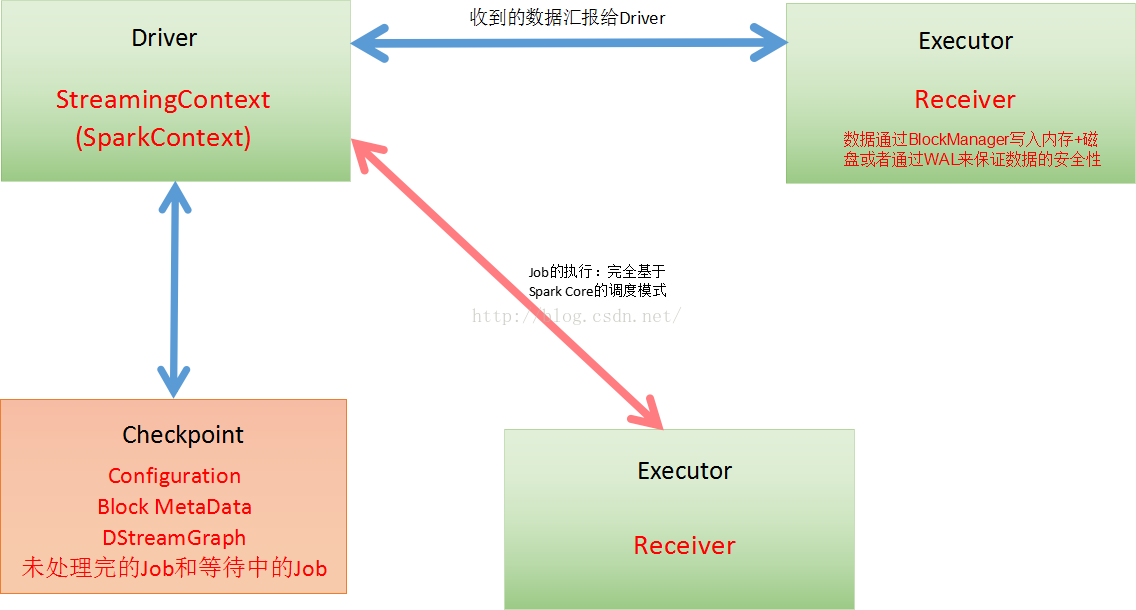
解读:
Spark Streaming应用程序启动,会分配资源,除非整个集群硬件资源奔溃,一般情况下都不会有问题。Spark Streaming程序分成而部分,一部分是Driver,另外一部分是Executor。Receiver接收到数据后不断发送元数据给Driver,Driver接收到元数据信息后进行CheckPoint处理。其中CheckPoint包括:Configuration(含有Spark Conf、Spark Streaming等配置信息)、Block MetaData、DStreamGraph、未处理完和等待中的Job。当然Receiver可以在多个Executor节点的上执行Job,Job的执行完全基于SparkCore的调度模式进行的。
在应用出问题是,Driver可以借助Checkpoint进行作业恢复
Driver处理元数据前会进行CheckPoint,Spark Streaming获取数据、产生作业,但没有解决执行的问题,执行一定要经过SparkContext。Driver级别的数据修复从Driver CheckPoint中需要把数据读入,在其内部会重新构建SparkContext、StreamingContext、SparkJob,再提交Spark集群运行。Receiver的重新恢复时会通过磁盘的WAL从磁盘恢复过来。
数据丢失的可能性
即使我们设置Receiver接收数据时的StorageLevel是磁盘级别的存储,也不能完全保证数据不被丢失,因为Receiver并不是接收一条数据写一次磁盘,而是按照数据块为单位写数据。然后将数据块的元数据信息发送给Driver,Driver的Checkpoint记录的数Block的元数据信息。当数据块写到一半的时候,或者是元数据还没有发送给Driver的时候,Executor崩溃了,就有可能造成数据丢失。
解决方案:在Receiver端引入WAL写机制
但是:WAL会影响Receiver接收数据的性能。
而且WAL也不能保证完全没有数据丢失,因为只有在Receiver接收到的数据数据积累到一定数量后才会写入WAL。没有来得及写入WAL的数据在Receiver出错时依然可能丢失。借助Kafka才是终极解决之道。
数据重复的可能性
1) 数据被重复读取(结合Kafka时):在使用Kafka的情况下,Receiver收到数据且保存到了HDFS等持久化引擎但是没有来得及进行updateOffsets,此时Receiver崩溃后重新启动就会通过管理Kafka的ZooKeeper中元数据再次重复读取数据,但是此时SparkStreaming认为是成功的,但是Kafka认为是失败的(因为没有更新offset到ZooKeeper中),此时就会导致数据重新消费的情况。
2) 数据输出多次重写
Spark Streaming在计算的时候基于Spark Core;Spark Core天生会做以下事情导致Spark Streaming的部分结果重复输出(例如数据输出后,该Task的后续程序发生错误,而任务发生错误,Spark Core会进入如下程序):
Task重试;慢任务推测(两个相同任务可能会同时执行),Stage重复;Job重试;
具体解决方案:
设置spark.task.maxFailures次数为1;
设置spark.speculation为关闭状态(因为慢任务推测其实非常消耗性能,所以关闭后可以显著提高Spark Streaming处理性能)
Spark Streaming on Kafka的话,Job失败后可以设置auto.offset.reset为“largest”的方式;















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









