






- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
本周任务:
1.根据TensorFlow代码,编写相应的pytorch代码
2.了解残差结构
3.是否可以将残差模块融入C3中
一、理论知识
1.CNN算法发展
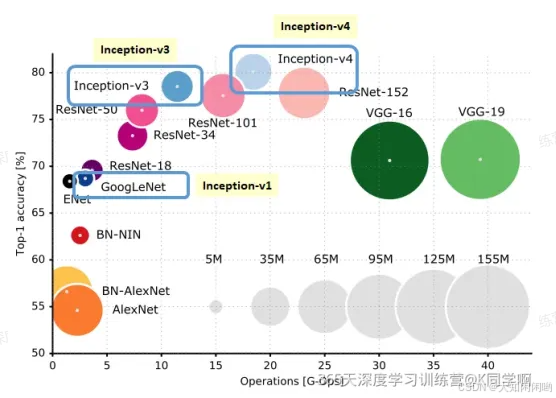
借用网上插图,在这张图列出了一些有里程碑意义、经典卷积神经网络。
评估网络的性能,一个维度是识别精度,另一个维度是网络复杂度 (计算量)。
从图上可以看到:
1.2012年,AlexNet在ImageNet图像分类竞赛中提出的一种经典的卷积神经网络。AlexNet是首个深层卷积神经网络,同时引入ReLU激活函数、局部归一化、数据增强和Dropout处理。
2.VGG-16和VGG-19依靠多层卷积+池化层堆叠的网络,其性能在当时还不错,但计算量巨大。
3.GoogleNet提出并联卷积结构,且在每个通路中使用不同大小同卷积核的网络、
4.ResNet首次提出残差概念,可以方便扩展为18-101层。
5.DenseNet是一种具有前级特征重用、层间直连、结构递归扩展等特点的卷积网络。
2.残差网络的由来
ResNet主要解决深度卷积网络在深度加深时候的“退化”问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失、爆炸,这个问题Szegedy提出BN层后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过小或过大的情况。但是作者发现加了BN后再加大深度仍然不容易收敛,其提到了第二个问题--准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降即不是梯度消失引起的也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的错误率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的优化器,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
作者在文中证明了只要有合适的网络结构,更深的网络肯定会比较浅的网络效果要好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。=
原文链接:https://blog.csdn.net/weixin_46620278/article/details/139161645
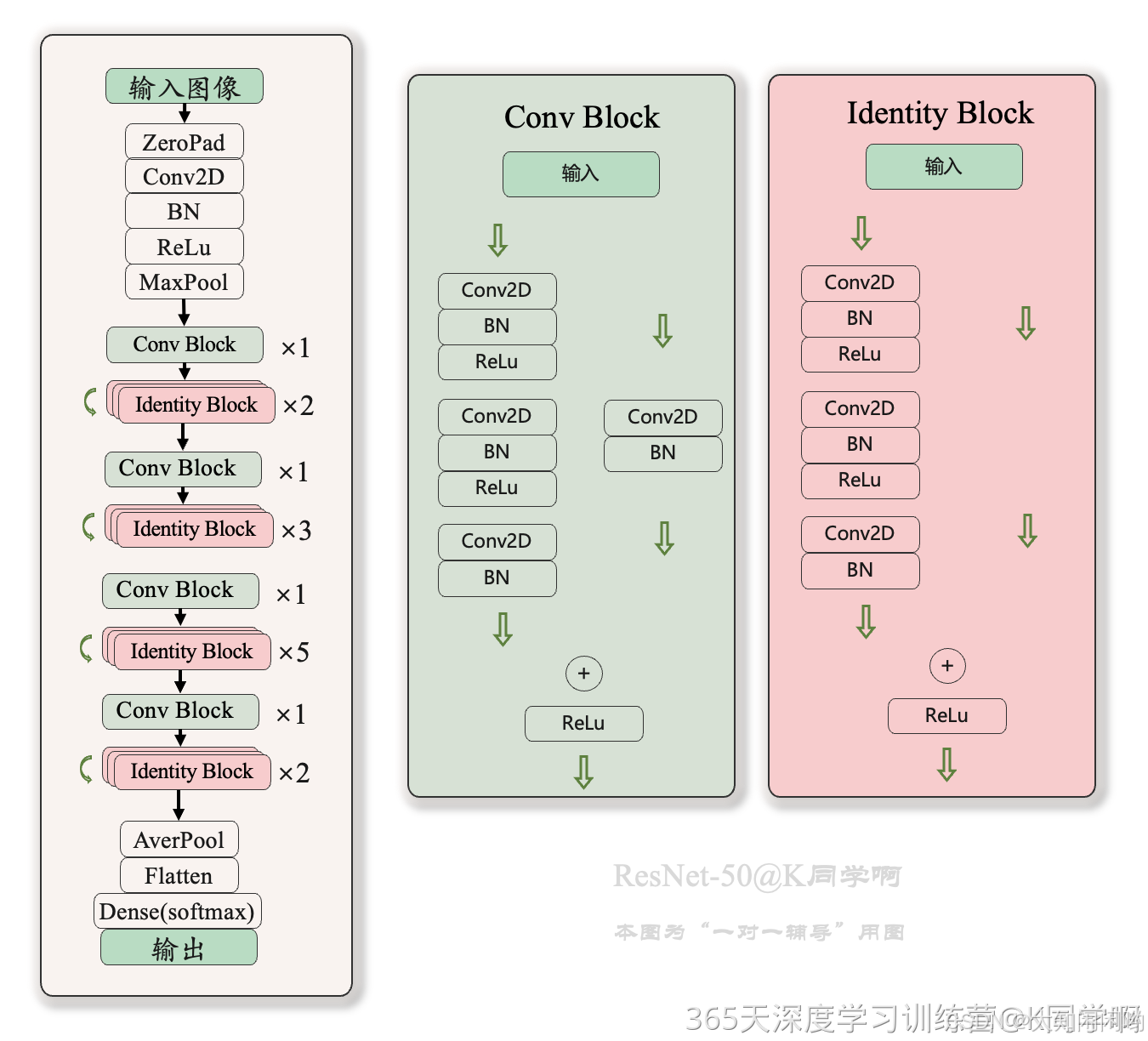
3.ResNet-50介绍
ResNet-50有两个基本块,Conv Block 和 Identity Block。
 二、前期工作
二、前期工作
语言环境 python3.8
编译器 pycharm
深度学习环境pytorch
数据集 学习链接提供
代码:依靠学习资料和网上博客写的。
1.设置GPU
#导入所需要的包
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
import torch.nn.functional as F
import matplotlib.pyplot as plt
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
import torch.utils.data as data
from PIL import Image
import copy
import numpy as np
#一、导入数据
'''
1.1 设置GPU
'''
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)结果输出:

2. 导入数据
'''
1.2 导入数据
'''
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = './第8天/bird_photos/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
def count_images(folder):
count = 0
for item in folder.iterdir():
if item.is_file():
count += 1
if item.is_dir():
count += count_images(item)
return count
image_count = count_images(data_dir)
print("图片总数为:", image_count)
classNames = [str(path).split('\\')[1] for path in data_paths]
#利用split()函数对data_paths中的每个文件路径执行分割操作,获取各个文件所属的类别名称并储存在classNames中
# 4类天气,各300张图片
print(classNames)结果输出:

三、数据预处理
1.加载数据
#二、数据预处理
'''
2.1 加载数据
'''
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder('./第8天/bird_photos/',transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)2.划分数据集
'''
2.2 划分数据集
'''
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)3.可视化数据
'''
2.3 可视化数据
'''
batch_size = 8
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
image_folder = './第8天/bird_photos/Cockatoo/' #指定图像文件夹路径
image_files = [f for f in os.listdir(image_folder) if f.endswith((".jpg", ".png", ".jpeg"))]
fig, axes = plt.subplots(2, 4, figsize=(16, 6))
for ax, img_file in zip(axes.flat, image_files):
img_path = os.path.join(image_folder, img_file)
img = Image.open(img_path)
ax.imshow(img)
ax.axis('off')
plt.tight_layout()
plt.show()结果输出:

ResNet50(
(conv1): Sequential(
(0): ZeroPad2d((3, 3, 3, 3))
(1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2))
(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): MaxPool2d(kernel_size=(3, 3), stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer1): Sequential(
(0): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(layer2): Sequential(
(0): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(layer3): Sequential(
(0): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(3): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(4): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(5): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(layer4): Sequential(
(0): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(1024, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(shortcut): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): ResNetblock(
(blockconv): Sequential(
(0): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(avgpool): AvgPool2d(kernel_size=(7, 7), stride=(7, 7), padding=0)
(fc): Linear(in_features=2048, out_features=4, bias=True)
)
四、构建ResNet-50网络模型
4.1构建基本残差块
class ResNet50(nn.Module):
def __init__(self, block, num_classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Sequential(
nn.ZeroPad2d(3),
nn.Conv2d(3, 64, kernel_size=7, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d((3, 3), stride=2)
)
self.in_channels = 64
# ResNet50中的四大层,每大层都是由ConvBlock与IdentityBlock堆叠而成
self.layer1 = self.make_layer(ResNetblock, 64, 3, stride=1)
self.layer2 = self.make_layer(ResNetblock, 128, 4, stride=2)
self.layer3 = self.make_layer(ResNetblock, 256, 6, stride=2)
self.layer4 = self.make_layer(ResNetblock, 512, 3, stride=2)
self.avgpool = nn.AvgPool2d((7, 7))
self.fc = nn.Linear(512 * 4, num_classes)
# 每个大层的定义函数
def make_layer(self, block, channels, num_blocks, stride=1):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, channels, stride))
self.in_channels = channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out4.2ResNet类构建
class ResNet50(nn.Module):
def __init__(self, block, num_classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Sequential(
nn.ZeroPad2d(3),
nn.Conv2d(3, 64, kernel_size=7, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d((3, 3), stride=2)
)
self.in_channels = 64
# ResNet50中的四大层,每大层都是由ConvBlock与IdentityBlock堆叠而成
self.layer1 = self.make_layer(ResNetblock, 64, 3, stride=1)
self.layer2 = self.make_layer(ResNetblock, 128, 4, stride=2)
self.layer3 = self.make_layer(ResNetblock, 256, 6, stride=2)
self.layer4 = self.make_layer(ResNetblock, 512, 3, stride=2)
self.avgpool = nn.AvgPool2d((7, 7))
self.fc = nn.Linear(512 * 4, num_classes)
# 每个大层的定义函数
def make_layer(self, block, channels, num_blocks, stride=1):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, channels, stride))
self.in_channels = channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out4.3模型实例化
model = ResNet50(block=ResNetblock, num_classes=len(classNames)).to(device)
print(model)五、模型训练
5.1 编写训练函数
'''
5.1 编写训练函数
'''
def train(dataloader, model, optimizer, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_acc, train_loss = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_acc, train_loss5.2编写测试函数
'''
5.2 编写测试函数
'''
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss5.3设置损失函数和学习率
'''
5.3 设置损失函数和学习率
'''
loss_fn = nn.CrossEntropyLoss() #交叉熵函数
learn_rate = 1e-3
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)5.4正式训练
'''
5.4 正式训练
'''
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
# 开始训练
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, opt, loss_fn)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = opt.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,
epoch_test_acc * 100, epoch_test_loss, lr))
print('Done')六、结果可视化
#六、结果可视化
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()Epoch: 1, Train_acc:41.8%, Train_loss:1.689, Test_acc:46.9%, Test_loss:1.662, Lr:1.00E-03
Epoch: 2, Train_acc:50.2%, Train_loss:1.253, Test_acc:42.5%, Test_loss:2.033, Lr:1.00E-03
Epoch: 3, Train_acc:62.6%, Train_loss:1.031, Test_acc:59.3%, Test_loss:1.138, Lr:1.00E-03
Epoch: 4, Train_acc:65.5%, Train_loss:0.919, Test_acc:77.9%, Test_loss:0.628, Lr:1.00E-03
Epoch: 5, Train_acc:70.8%, Train_loss:0.770, Test_acc:69.0%, Test_loss:0.854, Lr:1.00E-03
Epoch: 6, Train_acc:69.7%, Train_loss:0.801, Test_acc:73.5%, Test_loss:0.667, Lr:1.00E-03
Epoch: 7, Train_acc:73.2%, Train_loss:0.695, Test_acc:71.7%, Test_loss:0.706, Lr:1.00E-03
Epoch: 8, Train_acc:70.4%, Train_loss:0.781, Test_acc:59.3%, Test_loss:2.476, Lr:1.00E-03
Epoch: 9, Train_acc:75.9%, Train_loss:0.638, Test_acc:83.2%, Test_loss:0.554, Lr:1.00E-03
Epoch:10, Train_acc:76.8%, Train_loss:0.617, Test_acc:62.8%, Test_loss:0.913, Lr:1.00E-03
Epoch:11, Train_acc:74.6%, Train_loss:0.700, Test_acc:84.1%, Test_loss:0.472, Lr:1.00E-03
Epoch:12, Train_acc:78.3%, Train_loss:0.655, Test_acc:79.6%, Test_loss:0.576, Lr:1.00E-03
Epoch:13, Train_acc:74.6%, Train_loss:0.646, Test_acc:77.0%, Test_loss:0.948, Lr:1.00E-03
Epoch:14, Train_acc:80.8%, Train_loss:0.546, Test_acc:72.6%, Test_loss:0.917, Lr:1.00E-03
Epoch:15, Train_acc:76.1%, Train_loss:0.592, Test_acc:85.0%, Test_loss:0.443, Lr:1.00E-03
Epoch:16, Train_acc:83.2%, Train_loss:0.438, Test_acc:87.6%, Test_loss:0.378, Lr:1.00E-03
Epoch:17, Train_acc:86.3%, Train_loss:0.385, Test_acc:76.1%, Test_loss:0.460, Lr:1.00E-03
Epoch:18, Train_acc:83.4%, Train_loss:0.412, Test_acc:81.4%, Test_loss:0.501, Lr:1.00E-03
Epoch:19, Train_acc:86.5%, Train_loss:0.411, Test_acc:85.0%, Test_loss:0.413, Lr:1.00E-03
Epoch:20, Train_acc:87.4%, Train_loss:0.343, Test_acc:88.5%, Test_loss:0.397, Lr:1.00E-03
Done
七、总结
这周比较忙,网络很经典,需要更好的学习。自己的代码能力还是太弱。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









