







前言
部署好standalone集群之后,通常都需要对集群进行测试,以便知道这个集群是否真的能用,就像搭建hadoop集群时,通常都会跑一下MR程序(通常跑的是示例代码)来验证。
测试的执行过程的日志信息,通常用监控UI界面来查看,效果是最明显的。开发者应当具备熟悉查阅spark界面的能力。下面将结合UI界面来讲解测试过程。
一、开启各类服务/进程
#hadoop集群
start-all.sh
cd /export/servers/spark-3.2.0/
#spark历史服务
sbin/start-history-server.sh
#spark集群
sbin/start-all.sh
二、使用客户端工具
如果要跑程序的话,spark有两种方式:交互式执行 和 提交脚本执行。
支持交互式的工具有pyspark、spark-shell、spark-sql等,而支持提交脚本的工具有
spark-submit (PI)。
首先进入spark的bin目录下
cd /export/servers/spark-3.2.0/bin
1、pyspark
1)启动pyspark,不同的运行模式对应的启动指令不同:
local模式
./pyspark #直接启动
./pyspark --master local[*] #以全部资源方式启动
./pyspark --master local[N] #以N个线程方式启动
standalone模式
./pyspark --master master的通讯地址
我这里就是 ./pyspark --master spark://node1:7077
补充:master的通讯地址都可以在你先前配置的spark-env.sh文件里找到
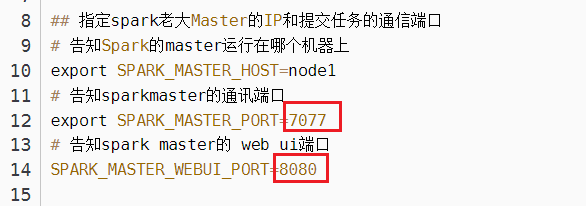
根据这个web端口,进入master的web页面,找到通讯地址,这个页面只要master进程启动了就能访问。
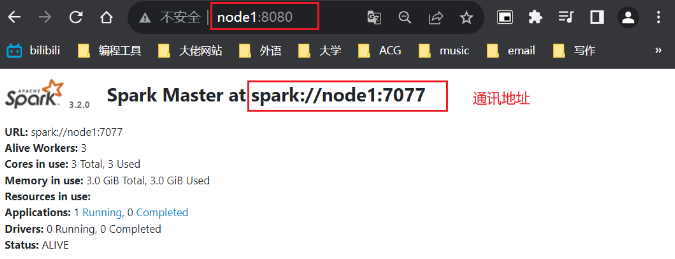
2)输入python代码,执行一些小任务
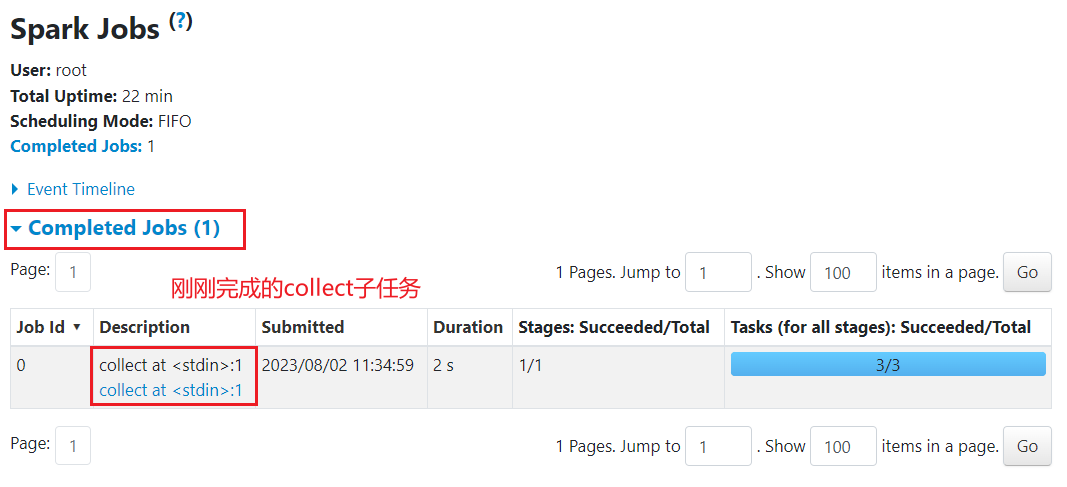
sc.parallelize([1,2,3,4,5]).map(lambda x: x*10).collect()

可以看到,代码运行成功,说明pyspark工具没有问题。另外,也可借助web页面来查看执行过程
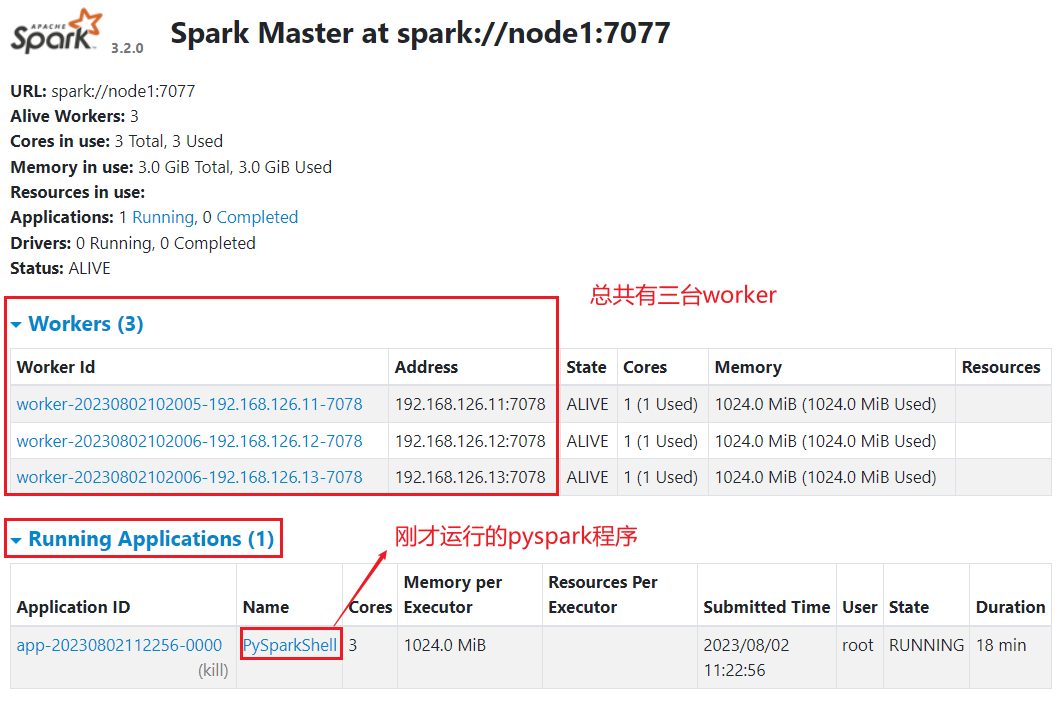
点击Application ID,进入查看详细信息
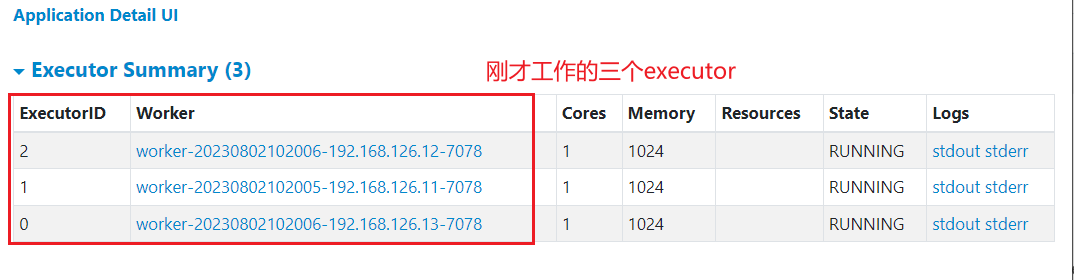
点击Application Detail UI,进一步查看信息
2、spark-shell
一样的步骤
1)启动spark-shell
./spark-shell --master spark://node1:7077

2)输入scala代码,执行一些小任务
sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()

可以看到,代码运行成功,说明spark-shell工具没有问题。
3、spark-submit
我们利用spark-submit ,将spark里预写好的示例代码,提交到集群运行。如这里提交的任务是计算圆周率,参数为100。
bin/spark-submit --master spark://node1:7077 /export/servers/spark-3.2.0/examples/src/main/python/pi.py 100

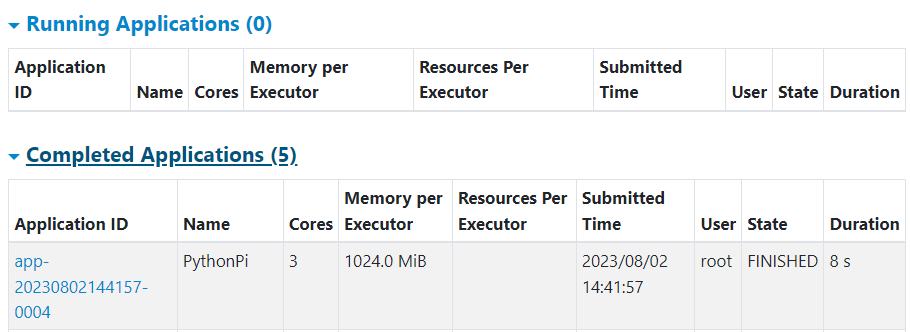
可以看到,在计算任务完成之后,PythonPi程序结束了,没有显示在Running Applications上了。同理,我们也就无法用node:4040打开这个任务的监控界面(因为任务完成了)。
4、历史服务器
可以使用历史服务器来查看历史记录,默认端口为:18080
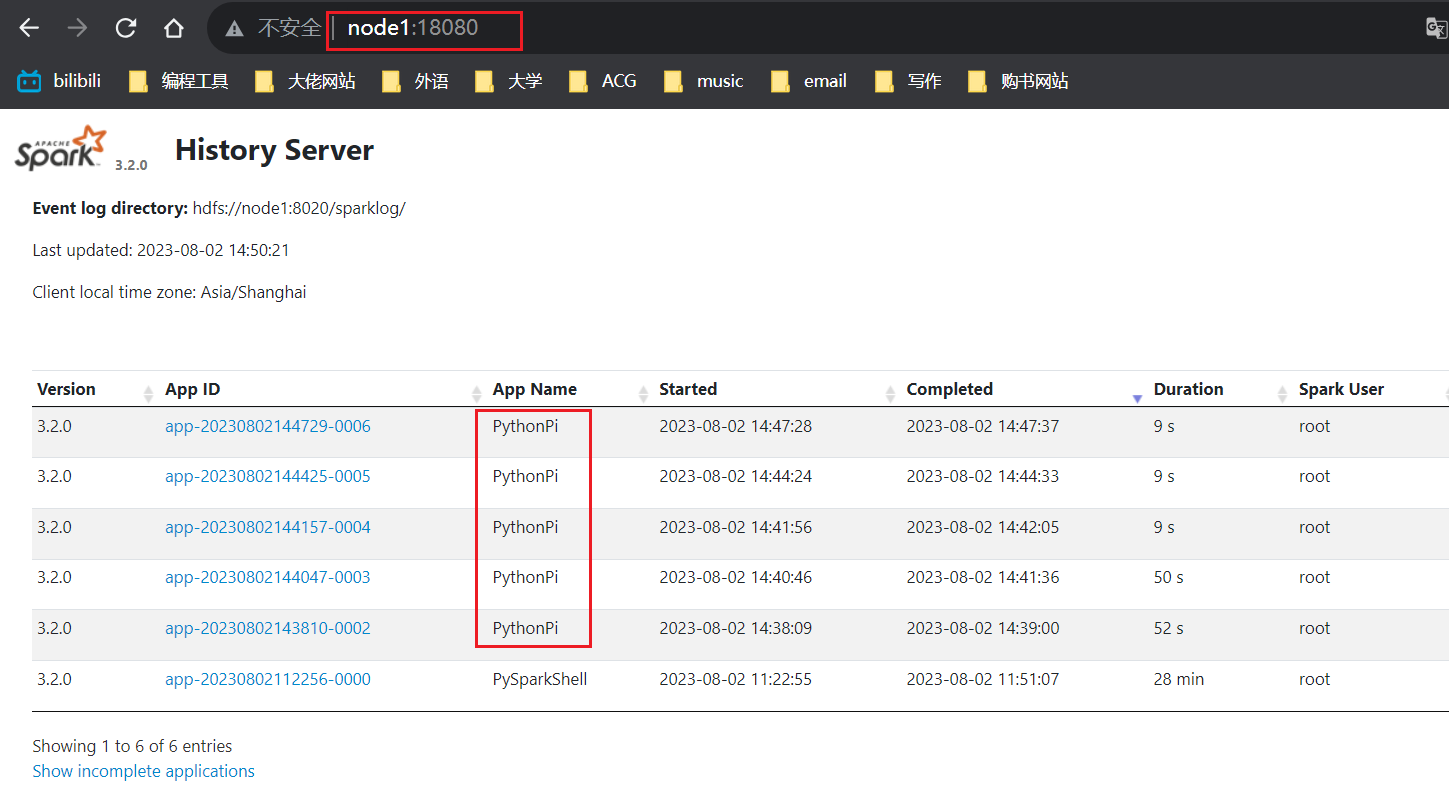
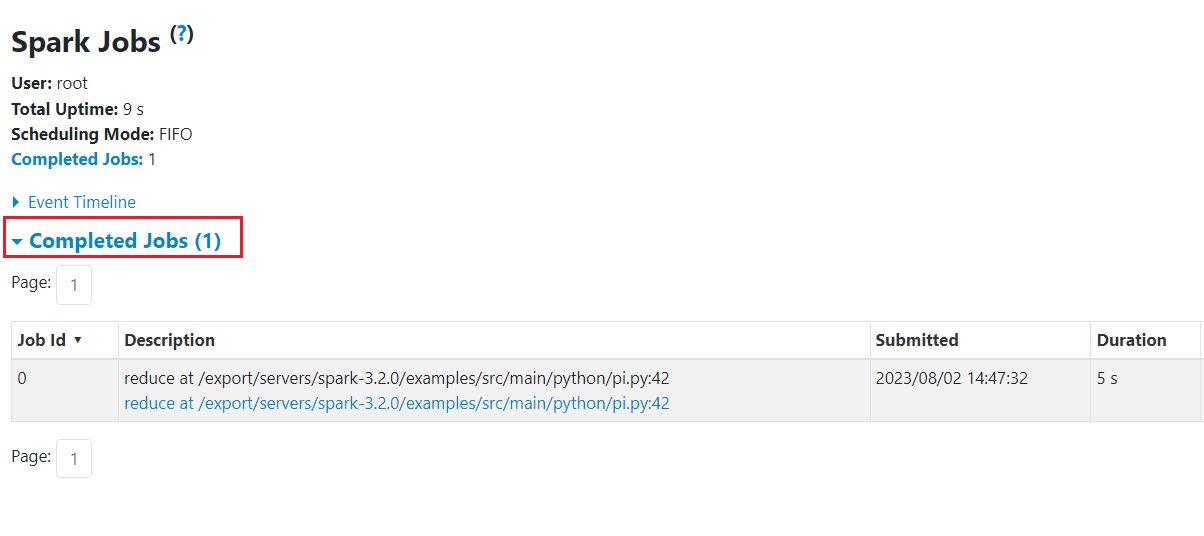
点击App ID,可以看到与4040端口相似的信息
三、总结补充
1、监控页面
- 4040是一个Application运行过程中临时绑定的端口,用于查看当前任务的状态。因此当程序运行结束时,4040会被注销,无法继续查看。此外,当同时运行多个Application时,4040会顺延到4041,4042……
- 8080是standalone模式下master进程所在的端口,用于查看master的状态,这个是一个守护进程,程序运行结束后,它仍然存在。
- 18080默认是历史服务器的端口,由于4040在程序运行完后会被注销,但我们又想查看某个程序的运行状态,可以通过18080去查看。前提是你开启了spark的历史服务。
2、spark程序的层级结构
结论:Application——Job——stage——Task
3、standalone原理
master和worker分别以独立进程的形式存在,Driver以线程的形式运行在master中,executor以线程的形式运行在worker中,它们共同构成了spark集群。master负责整个集群的资源管理,worker负责单个机子的资源管理,driver负责提交任务并控制任务执行流程,executor负责执行具体任务(Task)。
其它文章:
Spark环境搭建部署全流程,看这一篇就够了















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









