









本文是自己学习的总结,仅以作分享。若有不对的地方欢迎指正。
awk:格式化文本,对文本进行较复杂格式化处理
命令模式:awk [options] 'Pattern{Action}' file
处理规则:awk处理文本时,会一行一行的进行处理。处理完当前的行再处理下一行。awk默认以换行符(\n)为标记识别每一行。awk默认以空格符为分隔符,果有多个空格,awk自动将连续的空格符理解为一个分隔符
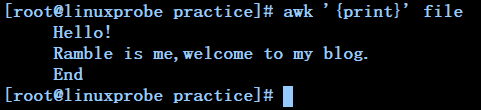
awk '{print}' file ---------------------------------------------------打印文件file的内容
df -H|awk '{print $5}' --------------------------------------------打印第5列的内容。

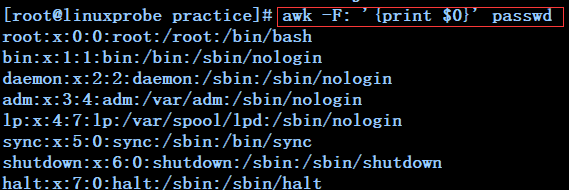
awk -F: '{print $0}' passwd -----------------------------------输出passwd文件的整行,也可以省略$0

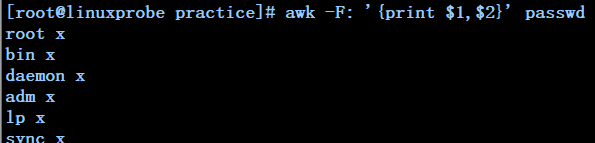
awk -F: '{print $1,$2}' passwd -------------------------------以:为分割符打印passwd文件中的第一列和第二列的内容
awk -F: '{print "user_name:"$1,"\t",$2}' passwd ------以:为分割符打印passwd文件中的第一列和第二列的内容,且在第一列内容前面加上user_name:,第一列和第二轮之间用制表符隔开

分隔符:awk中,分隔符分为两种:输入分隔符和输出分割符
F ---------------------------指定输入分隔符,默认以空格对每一行进行分割
v ---------------------------指定使用awk内部变量
FS -------------------------内部变量,指定输入分隔符
OFS -----------------------内部变量,指定输出分割符
输入分隔符(FS):默认以空格对每一行进行分割
输出分割符(OFS):awk将每一行分割后,输出在屏幕上以什么分隔符分隔每行,默以为空格对每一行进行分割
awk -v FS=':' '{print $1,$2}' passwd --------------------使用内部变量FS指定输入分隔符:处理passwd并打印第一列和第二列

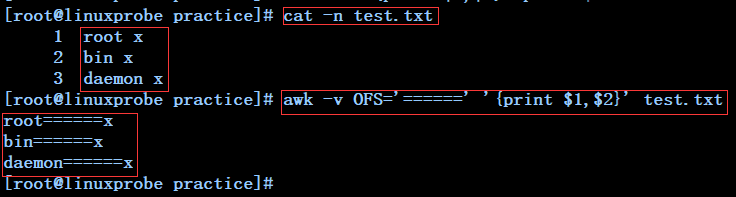
awk -v OFS='======' '{print $1,$2}' test.txt ---------使用内部变量OFS指定输出分割符======将test.txt的第一列和第二列连接在一起展示出来
awk -F: '{print $1$2}' passwd ----------------------------将passwd文件的第一列和第二列连接在一起展示,$1$2之间也可以用空格隔开

内置变量
RS --------------------------------指定输入时的换行符,默认"回车换行"
ORS ------------------------------指定输出时的换行符,默认"回车换行"
NF --------------------------------展示当前行被分割后字段的数量
NR --------------------------------展示当前处理文本每一行的 行号
FNR ------------------------------awk处理多个文件时,每个文件的行号各自独立展示
FILENAME ---------------------展示当前行对应的文件名
ARGV ----------------------------展示命令行输入的对应参数
ARGC ----------------------------展示命令行输入的对应参数的数量
例子——NR与FNR
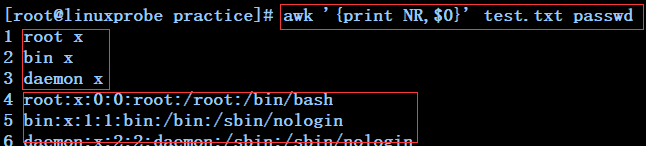
awk '{print NR,$0}' test.txt ---------------------------展示test.txt文件中每行的行号及每行的内容

awk '{print NR,$0}' test.txt passwd ---------------展示test.txt和passwd文件中的行号(先展示test.txt,再接上面的行号展示passwd每行的内容)
awk '{print FNR,$0}' test.txt passwd --------------展示test.txt和passwd文件中的行号(每个文件的行号单独计算)

例子——NF
awk '{print NR,NF}' test.txt ---------------------------展示test.txt文件中每行的行号及每行被分割后字段的数量

例子——RS与ORS
awk -v RS=" " '{print NR,$0}' test.txt --------------指定空格符为输入换行符处理test.txt文件,然后依次打印每行的行号及其对应的内容(空格也算一行)
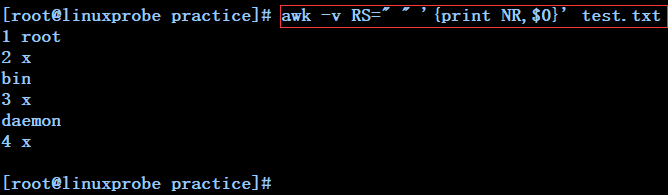
awk -v ORS="+++" '{print NR,$1}' test.txt -------指定+++为输出换行符展示test.txt文件的第一列,并显示每行的行号(此时输入换行符为默认的"回车",展示时按输入换行符计算行号)
![]()
awk -v RS=" " -v ORS="+++" '{print NR,$0}' test.txt ------指定空格符为输入换行符,+++为输出换行符展示test.txt文件每行的行号及其对应的内容

例子——FILENAME
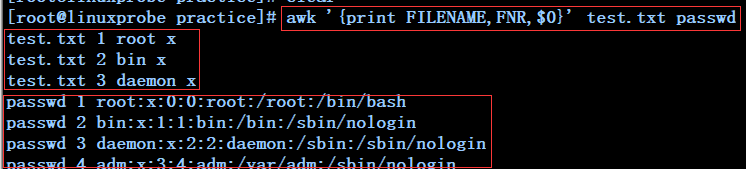
awk '{print FILENAME,FNR,$0}' test.txt passwd ----------分别展示test.txt和passwd文件中的每行对应的文件名、行号及每行的内容
例子——ARGV与ARGC
awk 'BEGIN {print "lalala",ARGV[1],ARGV[2],ARGC}' test.txt passwd ----------处理test.txt和passwd文件之前依次打印lalala及该命令传入的第一个参数test.txt和第二个参数passwd及传入参数的总个(参数个数从0开始,此处有参数有awk、test.txt、passwd共三个)
![]()
自定义变量
awk -v i="lalala" '{print i}' test.txt -------------------第一种方法用-v参数定义,后打印变量i(test.txt有多少行打印多少次)

awk -v i="lalala" 'BEGIN{print i}' --------------------第一种方法用-v参数定义,后打印变量i

awk 'BEGIN{i="lalala";j="hahaha";print i,j}' -----第二种方法定义自变量,打印变量i和j

printf
1.使用printf动作输出时文本不会自动换行,如果需要换行需要在对应的"格式替换符"%s后加入"\n"进行转义
awk '{printf "%s\n",$1}' test.txt -------------------------------------------使用printf打印test.txt的第一列

2.使用printf动作时,指定的格式与被格式化的文本之间需要用逗号隔开
awk '{printf "第一列:%s 第二列:%s\n",$1,$2}' test.txt ----------打印test.txt第一列和第二列且在第一列前加上"第一列:"、在第二列前加上"第二列:"

3.使用printf动作时,"格式"中的格式替换符必须与被各式化的文本一一对应
awk 'BEGIN{printf "%s\n%s\n%s\n%s\n%s\n",1,2,3,4,5}' ------------每行打印1个数字一直打印到5

awk -F: 'BEGIN{printf "%-10s\t %s\n","用户名称","用户ID"} {printf "%-10s\t %s\n",$1,$3}' passwd ----------制作表格。第一列名称为用户名称,第二列名称为用户ID,内容为以:分隔passwd文件后的第一列和第二列的内容填入

模式——Pattern
"模式"可以理解为"条件",即当满足条件时,模式awk才会处理匹配的行,对于不满足条件的行则不作处理。模式中可以使用各种运算符。
空模式:会匹配所有的行,每行都会执行相应的动作
awk 'NF==2 {print $0}' test.txt ----------当test.txt文件中的行满足分隔后只有两个字段,则打印匹配的行

BEGIN与END模式
BEGIN -----------------------指定处理文本之前需要执行的操作
END --------------------------指定处理完所有行之后需要执行的操作
awk 'BEGIN{print "lalala"}' --------------在处理文本之前打印lalala,由于未对文本指定操作,此时可以省略指定文本
![]()
awk 'BEGIN{print "lalala"} {print $1,$2}' test.txt --------在处理文本之前打印lalala,之后打印test.txt文件的第一列和第二列

awk '{print $1,$2} END{print "lalala"}' test.txt ------------在打印test.txt文件的第一列和第二列之后,打印lalala

awk -F: 'BEGIN{printf "%-10s%-10s\n","用户名","用户ID"} /^r/{printf "%-10s\t %s\n",$1,$3}' passwd --------制作表格。第一列名称为用户名称,第二列名称为用户ID,内容以匹配满足passwd文件中以r开头的行打印第一列和第二列

awk -F: 'BEGIN{printf "%-10s\t %s\n","用户名称","用户ID"} /^r/{printf "%-10s\t %s\n",$1,$3}' passwd -------制作表格。第一列名称为用户名称,第二列名称为用户ID,内容以匹配满足passwd文件中以r开头的行打印第一列和第二列

关系运算模式:模式中用到了关系运算符,当运算结果为真时则执行相应的动作(即满足条件),否则不匹配则不处理
awk 'NR>=3 && NR<=6 {print $0}' passwd -----------匹配passwd文件中第三行与第6行之间的所有行并打印出来(包括第三行与第六行)

正则模式:与正则表达式匹配则执行相应动作,未匹配则不处理
--posix -------------------------用于匹配包含次数的正则表达式
--re-interval ------------------用于匹配包含次数的正则表达式
语法:awk '/正则表达式/{动作}' file
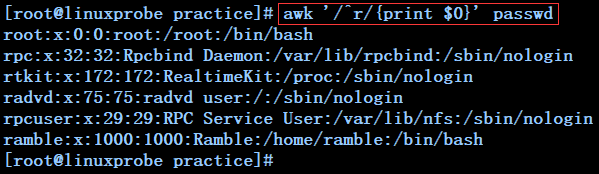
awk '/^r/{print $0}' passwd ------------------------------匹配满足passwd文件中以r开头的行并打印出来
awk '/\/bin\/bash$/{print $0}' passwd -----------------匹配满足passwd文件中以/bin/bash结尾的行并打印出来

awk '$2~/[0-9]$/ {print $2}' test.txt ---------------------匹配test.txt件中第二列中出现数字的行并打印该列
![]()
awk --posix '/ro{1,2}/{print $0}' passwd --------------匹配满足passwd文件中ro连续出现1或2次的行并打印出来

awk --re-interval '/ro{1,2}/{print $0}' passwd -------匹配满足passwd文件中ro连续出现1或2次的行并打印出来

行范围模式:打印第一次匹配到表达式1达行到最后一次匹配到表达式2之间所有的行
语法:awk '表达式1 表达式2{动作}' file
awk '/root/,/games/{print $0}' passwd ----------------匹配满足passwd文件中第一次匹配到root的行到最后一次匹配到games之间所有的行并打印出来

动作——Action:所有动作外侧必须用{}括起
输出语句类型:print和printf都属于输出语句类型动作,作用就是输出打印信息
awk -F: '{print $0}' passwd -------------------------------输出passwd文件的整行,也可以省略$0
awk '{printf "%s\n",$1}' test.txt ------------------------使用printf打印test.txt的第一列

组合语句类型:{}属于组合语句类型动作,作用就是将多个代码组合成代码块
awk '{print $1}{print $2}' test.txt -------------每行交替打印test.txt文件中第一列和第二列内容
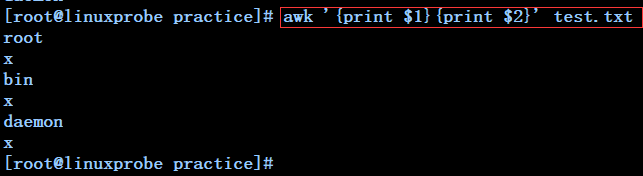
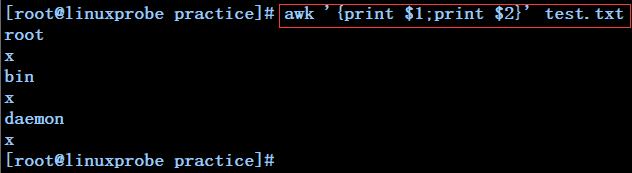
awk '{print $1;print $2}' test.txt --------------每行交替打印test.txt文件中第一列和第二列内容
控制语句类型:控制语句有多种,比如if条件语句、for与while循环控制语句等
if控制语句
if(条件){语句1;语句2;...} --------------------------------------如果if对应的{}中只有一条语句,则{}可以省略;否则不可以省略
awk '{if(NR==1)print $0}' test.txt -------------------test.txt文件中如果行号等于1则打印该行的内容(if是个动作需要一对{})

awk '{if(NR==1){print $1;print $2}}' test.txt -----test.txt文件中如果行号等于1则打印该行的第一列和第二列,每列另起一行
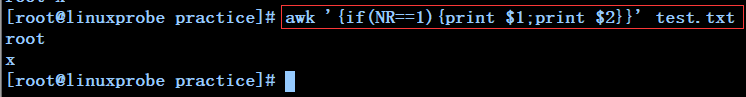
if(条件){语句1;语句2;...}else{语句1;语句2;...} -------------------------------------if-else语句格式
if(条件){语句1;语句2;...}else if{语句1;语句2;...}else{语句1;语句2;...} ------if-else if-else语句格式
awk -F: '{if($3 < 1000){print $1,"系统用户"}else{print $1,"普通用户"}}' passwd ----------------------------------------------------如果passwd文件中的第三列用户ID小于1000则打印第一列并在后面加上系统用户,否则打印第一列并在后面加上普通用户

awk '{if($2<25){print $1,"年轻人"}else if($2>=25 && $2<35){print $1,"中年人"}else{print $1,"老年人"}}' test-1.txt ------如果test-1.txt件中的第二列小于25,则打印第一列且在后面加上年轻人;如果第二列大于等于25且小于35,则打印第一列且在后面加>上中年人;如果第二列大于等于35,则印第一列且在后面加上年人

for循环控制语句
for(初始化;布尔表达式;更新){//代码语句} ------------------------------for循环
for(变量 in 数组){//代码语句} ----------------------------------------------for循环
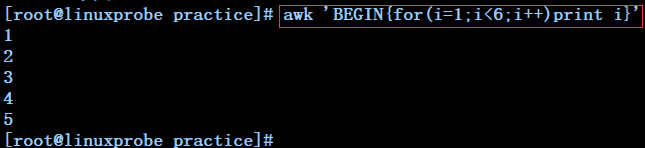
awk 'BEGIN{for(i=1;i<6;i++)print i}' -------------------每列一个数字打印1到5
while循环控制语句
while(布尔表达式){//代码语句} ---------------------------------while循环
do{//代码语句}while(条件) --------------------------------------while循环
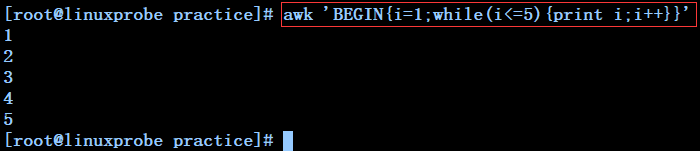
awk -v i=1 'BEGIN{while(i<=5){print i;i++}}' ------------每列一个数字打印1到5
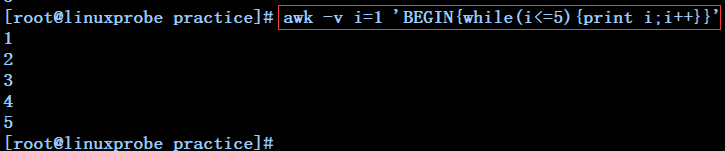
awk 'BEGIN{i=1;while(i<=5){print i;i++}}' ---------------每列一个数字打印1到5
awk 'BEGIN{i=1;do{print "test";i++}while(i<=1)}' ----i<=1时,打印test(无论是否满足while中的条件,都会打印一次test)
![]()
awk 'BEGIN{do{print "test";i++}while(i<=2)}' ---------打印3次test(i没定义,默认是0;无论是否满足while中的条件,都会打印一次test)

continue、break、exit及next
continue ------------------跳出当前这次循环进行下次循环
awk 'BEGIN{for(i=1;i<6;i++){if(i==3){continue};print i}}' --------------------------每列一个数字打印1到5,不打印3
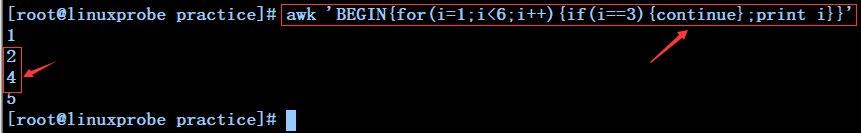
break ----------------------跳出整个循环
awk 'BEGIN{for(i=1;i<6;i++){if(i==3){break};print i}}' -------------------------------每列一个数字打印1到2(break跳出了循环)

exit ------------------------直接执行END语句,没有END语句则表示退出awk命令
awk 'BEGIN{print 1;exit;print 2}' ----------------------------------------------------------打印1后退出命令
![]()
awk 'BEGIN{print "start";exit} {print $0} END{print "over"}' test-1.txt -------打印start后执行END语句打印over

awk 'BEGIN{print "start"} {print $0;exit} END{print "over"}' test-1.txt -------打印start、test-1.txt文件的第一行后执行END语句打印over

next ----------------------不对当前行进行操作,直接处理下一行
awk '{if(NR==2){next};print $0}' test-1.txt ----------------------------------------------当行号等于2时,处理下一行,此处不打印test-1.txt文件的第二行
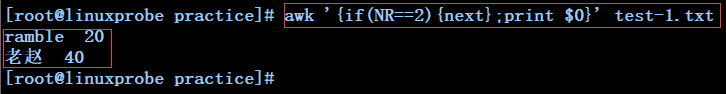
数组
1.类似Python中的列表
2.在awk中,数组下标默认从1开始,为了习惯,也可以设置从0开始
3.在awk中,不用定义数组,直接给数组中的元素赋值即可
awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";print num[1]}' ------------------------定义数组num,下标从0开始,打印下标为1的元素值
![]()
4.在awk中,数组元素值为空是合法的(空格不是表示空)
awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";num[3]="";print num[3]}' --------定义数组num,下标3的元素定义为空并打印该元素
![]()
awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";num[3]="";if(num[3]==""){print "数组的第4个元素为空"}}' --------------------------------------------------判断数组num的第4个元素为空(该方法判断不好)

awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";num[3]="";if(3 in num){print "数组的第4个元素存在就打印这句话"}}' ------------------------------------判断数组num的第4个元素为空

awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";num[3]="";if(4 in num){print "数组的第5个元素存在就打印这句话"}}' ------------------------------------判断数组num的第五个元素为空
![]()
5.在awk中,当一个元素不存在于数组中时,直接引用这个元素awk会自动在数组中创建这个元素且默认给这个元素赋值为空字符串
awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";print num[3]}' -----------------------数组num中没有下标为3的元素,此时会自动创建下标3的元素为空

6.在awk中,默认会把数字下标转换成字符串,本质上awk中的数组是一个用字符串作为下标的“关联数组”
awk 'BEGIN{num["ai"]="lala";num["ci"]="dudu";num["bi"]="huhu";print num["ci"]}' --------定义数组num,印下标为ci的元素值
![]()
7.在awk中,删除元素或整个数组都用delete
awk 'BEGIN{num["ai"]="lala";num["ci"]="dudu";num["bi"]="huhu";delete num["ci"]}' ------定义数组num,删除下标为ci的元素值
![]()
awk 'BEGIN{num["ai"]="lala";num["ci"]="dudu";num["bi"]="huhu";delete num}' --------------删除数组
![]()
8.在awk中,获取数组中的元素可以用循环语句
awk 'BEGIN{num[0]="lala";num[1]="dudu";num[2]="huhu";num[3]="";for(i=0;i<=5;i++){print i,num[i]}}' -----从下标为0开始打印到下标为5的num中的下标及其对应的元素,没有对应下标的元素则自动创建对应下标的空元素

awk 'BEGIN{num["ai"]="lala";num["ci"]="dudu";num["bi"]="huhu";for(i in num){print i,num[i]}}' ---------------打印unm中所有的下标及其对应的元素

9.在awk中,当数组中的下标为字符串时,元素输出的顺序与元素在数组中的顺序是不同的。这是因为关联数组导致的
10.在awk中,如果字符串参与运算,其将被当做数字0参与运算
11.在awk中,对一个不存在的元素进行自加运算后,这个元素的值就等于自加的次数。如:自加x次,元素的值就被赋值为x
awk 'BEGIN{print unm["la"];unm["la"]++;unm["la"]++;print unm["la"]}' ----------------------------打印数组unm中下标为la的元素(没有则新增为空),然后自增两次再打印,此时结果是该下标对应的元素被赋值2

awk '{count[$1]++} END{for(i in count){print i,count[i]}}' test.txt --------------------------------------将test.txt文件中的第一列取出作为数组count的下标,然后对该数组中的下标进行自加运算(由于字符串自加被视为0,第一次加法时对应下标的值被赋为1,之后每遇到一次该下标都会在原数值基础上加1),最后打印每个下标及对应的数值(这里表示下标出现的次数)

awk -F: '{count[$7]++} END{for(j in count){print j,count[j]}}' passwd --------------------------------以:为分隔符,打印passwd文件中第7列元素及其出现的次数

awk -F: '{for(i=1;i<=NF;i++){count[$i]++}} END{for(j in count){print j,count[j]}}' passwd ------以:为分隔符,每行打印passwd文件中所有元素及其出现的次数

内置函数
rand -------------生成一个随机6位数小数,单独使用时数值将固定不变
srand -----------配合rand函数使用,使其返回值随机
int ----------------截取整数部分的数值
sub --------------在指定的范围内查找指定的字符(可以是数组),并将其替换为指定的字符串(单次替换)
gsub ------------在指定的范围内查找指定的字符(可以是数组),并将其替换为指定的字符串(全局替换)
length ----------获取指定字符串的长度
index -----------查找指定字符串在文本中每行最后一次匹配到的位置并输出位置返回值,返回值为0表示该行没有指定字符串
split -------------将指定的字符串按照指定的分隔符分割,然后将分割后的每段赋值到数组的元素中,达到动态创建数组(数组下标从1开始)
asort ------------根据数组中元素的值进行排序,排序后的数组下标将被重置,其下标将从1开始
asorti -----------根据数组中下标的字母将数组进行排序(下标为数字时用for循环即可)
例子——rand、srand及int
awk 'BEGIN{print rand()}' ------------------------------------------生成一个固定不变的随机6位数小数
![]()
awk 'BEGIN{srand();print rand()}' -------------------------------生成一个随机6位数小数
![]()
awk 'BEGIN{srand();print int(100*rand())}' -------------------生成一个随机的二位数整数

例子——gsub、sub及length
awk '{gsub("e","E",$0);print $0}' test.txt ----------------------将test.txt文件中的e替换成E输出

awk '{sub("m","M",$0);print $0}' test.txt ----------------------将test.txt文件中每行的第一个m替换成M输出

awk '{print $1,length($1)}' test.txt -------------------------------打印test.txt文件中第一列并显示每行元素的长度

awk '{for(i=1;i<=NF;i++){print $i,length($i)}}' test.txt ------打印test.txt文件中所有以空格为分隔符的每段元素及其长度
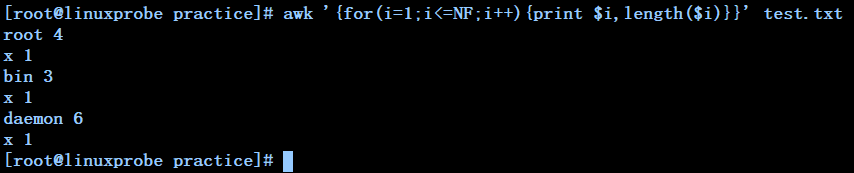
例子——index与split
awk '{print index($0,"oo")}' test.txt -----------------------------获取oo在test.txt文件中每行的位置

awk -v ts="lala:lulu:dudu" 'BEGIN{split(ts,su,":");for(i in su){print su[i]}}' ------------------定义变量ts,将ts按照:分割后生成su数组,之后打印数组中的元素

awk -v ts="qq la du" 'BEGIN{arrlen=split(ts,ar);for (i=1;i<=arrlen;i++){print i,ar[i]}}' ------定义变量ts,将ts分割后用split生成ar数组,然后将split的返回值赋给变量arrlen,之后根据变量arrlen打印数组中的下标及其对应的元素

例子——asort与asorti
awk 'BEGIN{t["a"]=5;t["b"]=3;t["c"]=4;asort(t);for(i in t){print i,t[i]}}' --------------------------------------------定义数组t,用asort将t中的值进行排序后打印其下标与下标对应的值
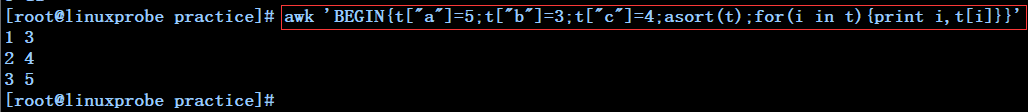
awk 'BEGIN{t["a"]=5;t["b"]=3;t["c"]=4;len=asort(t,new_t);for(i=1;i<=len;i++){print i,new_t[i]}}' ---------定义数组t,用asort将t中的值进行排序后的数组用新定义数组new_t接收,并用变量len接收asort的返回值,然后打印new_t数组中的下标与其对应的值(这样做原数组不变)

awk 'BEGIN{t["z"]=5;t["d"]=3;t["g"]=4;len=asorti(t,new_t);for(i=1;i<=len;i++){print i,new_t[i]}}' ---------定义数组t,用asorti将t中的下标进行排序,生成由t的下标组成的新的数组new_t,并用变量len接收asorti的返回值,然后打印new_t数组中的下标与其对应的值

awk 'BEGIN{t["b"]=5;t["d"]=3;t["g"]=4;len=asorti(t,new_t);for(i=1;i<=len;i++){print i,new_t[i],t[new_t[i]]}}'--------在上面一句代码的基础上新增打印根据t数组的下标打印该数组的元素值

三元运算
在awk中,如果省略了模式对应的动作,,当前行满足模式时,默认动作为打印整行,即{print $0}
在awk中,0或者空字符串表示假,非0非空表示真
格式1:条件? 结果1:结果2 -------------------------------条件成立,执行结果1,否则执行结果2
格式2:表达式1? 表达式2:表达式3 -------------------表达式1为真,执行表达式2,否则执行表达式3
awk -F: '{user_type=$3<1000? "系统用户":"普通用户";print $1,user_type}' passwd -------如果passwd文件中的第三列用户ID小于1000则打印第一列并在后面加上系统用户,否则打印第一列并在后面加上普通用户

awk -F: '{$3<1000? a++:b++} END{print a,b}' passwd ------------------------------------------------如果passwd文件中的第三列用户ID小于1000则定义变量a,匹配到一行后a将自增;如果大于等于1000,则定义b,匹配到一行后b将自增。最后打印a和b。即表示统计passwd文件中系统用户和普通用户的数量并打印
![]()
awk 'i=!i' passwd --------------------------------------------打印passwd文件中的奇数行(awk处理第一行时,变量i初始化,此时其值为空,空表示假,对假取反变为真,i为真条件成立,打印第一行;接下来处理第二行,此时i为真,对i取反,i为假条件不成立,故对第二行不做处理跳到第三行...直到处理完passwd文件)

awk '!(i=!i)' passwd -----------------------------------------打印passwd文件中的偶数行(原理与上一句代码一样)
















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









