









搭建宽表作用,就是为了让业务部门的数据分析人员,在日常工作可以直接提取所需指标,快速做出对应专题的数据分析。在实际工作中,数据量及数据源繁多,如果每个数据分析人员都从计算加工到出报告,除了工作效率巨慢也会导致服务器资源紧张。因此建设数据集市层,包含了该宽表层并在非工作时间做自动生成。
本文引用CDNow网站的一份用户购买CD明细数据,梳理业务需求,搭建一套数据宽表。
该CD数据包括用户ID,购买日期,购买数量,购买金额四个字段(此项目中用userid,datatime,products,amounts字段来表示)
业务逻辑参考文章:zhuanlan.zhihu.com/p/109767465
指标维度整理如下:
(实际业务场景中,由于获取的数据维度非常多,基础指标及衍生指标的加工最后有几千个指标都很正常,本次该数据集主要用于提出思路。另外,基于机器学习算法自动生成的衍生指标不在本次文章讨论范围,本次宽表指标主要是从业务角度出发,开发具备可解释性指标)

ps:指标名、统计口径、数据类型、小数位的统一非常重要
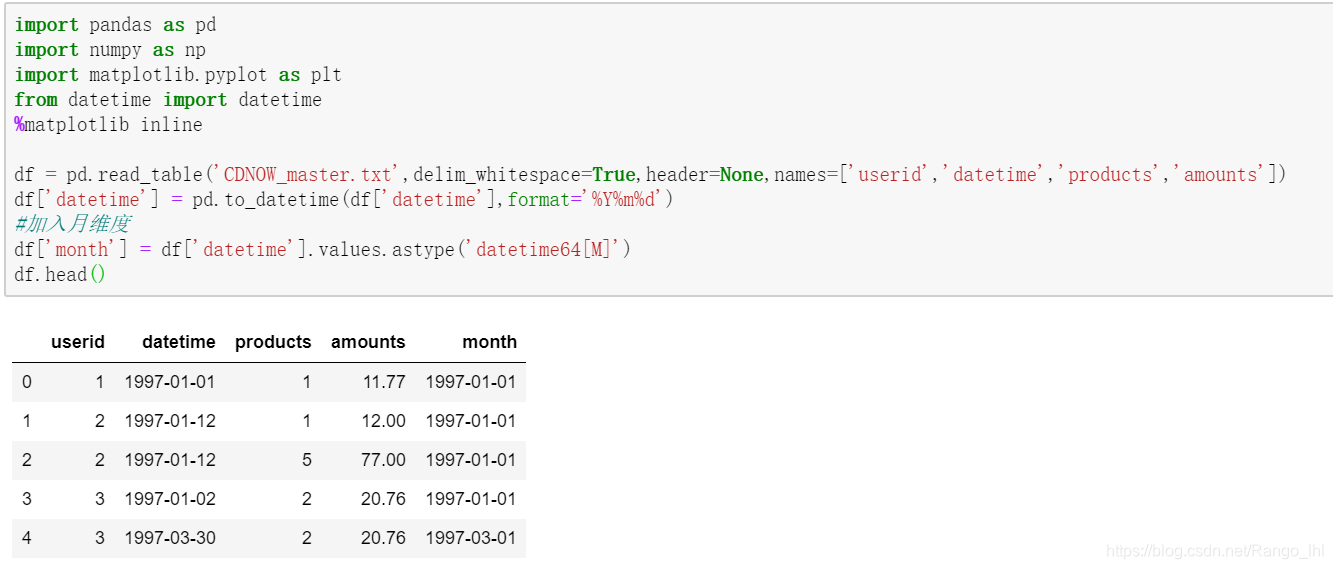
数据加载
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
df = pd.read_table('CDNOW_master.txt',delim_whitespace=True,header=None,names=['userid','datetime','products','amounts'])
df['datetime'] = pd.to_datetime(df['datetime'],format='%Y%m%d')
#加入月维度
df['month'] = df['datetime'].values.astype('datetime64[M]')
df.head()
一、时间维度
①基础指标:销售额/销量/消费次数/消费人数,可用以支撑RMF模型
#每月的总销售额/销量/消费次数
df_m_total_1 = df.pivot_table(index='month',values=['amounts','userid','products',]
,aggfunc={'amounts':'sum','userid':'count','products':'sum'})
#每月的消费人数
df_m_total_consume = pd.DataFrame(df.groupby('month')['userid'].nunique())
#合并
df_m_total = pd.merge(df_m_total_1, df_m_total_consume, on=['month'])
#修改列名
df_m_total.columns = ['m_total_amount','m_total_count','m_total_volumn','m_total_consume']
②活跃度指标:新用户/活跃用户/不活跃用户/回流用户
#每个用户每月的消费次数
pivoted_counts = df.pivot_table(index='userid',columns='month',values='datetime',aggfunc='count').fillna(0)
#1代表本月消费,0代表未消费
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
col = ['1997-01-01', '1997-02-01', '1997-03-01', '1997-04-01',
'1997-05-01', '1997-06-01', '1997-07-01', '1997-08-01',
'1997-09-01', '1997-10-01', '1997-11-01', '1997-12-01',
'1998-01-01', '1998-02-01', '1998-03-01', '1998-04-01',
'1998-05-01', '1998-06-01']
def active_status(data): #data是df_purchase的一行
status=[]
for i in range(18): #一共有18个月,判断每一个月的消费情况,也可以使用len(df_purchase.columns)
#若本月没有消费
if data[i]==0:
if len(status)>0:#之前有记录
if status[i-1]=='m_unreg': #一直没有注册,看作未注册用户
status.append('m_unreg') #未注册用户
else:
status.append('m_unactive') #这个月没消费,之前消费过
else:#之前没有记录
status.append('m_unreg') #第一个月没有消费,未注册
#若本月消费
else:
if len(status)==0:#之前没有记录
status.append('m_new') #第一次消费
else:#之前有记录
if status[i-1]=='m_unactive':
status.append('m_return') #前几个月不活跃,现在又消费了,回流
elif status[i-1]=='m_unreg':
status.append('m_new') #判断第一次消费
else:
status.append('m_active') #一直在消费
return pd.Series(status,index = col)
pivoted_status = df_purchase.apply(active_status,axis = 1)
#用NaN替代m_unreg,以便后续计算不包含这些数据,未注册不考虑
purchase_stats_ct=pivoted_status.replace({'m_unreg':np.NaN}).apply(lambda x:x.value_counts())
#分层图
purchase_stats_ct.fillna(0).T.plot.area()
#每月活跃情况数量
df_active_level = purchase_stats_ct.T.fillna(0)
#每月活跃情况数量占比
df_active_level_por = pd.DataFrame(purchase_stats_ct.fillna(0).T.apply(lambda x:x/x.sum(),axis = 1))
③复购类指标:每月购买两次以上的客户数/购买一次的客户数
#购买两次以上标为1,一次为0,无购买记录为空
user_df2=pivoted_counts.applymap(lambda x : 1 if x > 1 else np.NaN if x == 0 else 0)
#汇总转置
user_df3 = user_df2.apply(lambda x:x.value_counts()).T
#修改列名
user_df3.columns=['m_buy_one','m_buy_mul']
④回购类指标:回购人数
#某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。比如,
#我1月消费用户1000,他们中有400个2月依然消费,回购率是40%。
def purchase_return(data):
status=[]
for i in range(17):
if data[i]==1:
if data[i+1]==1:
status.append(1)
if data[i+1]==0:
status.append(0)
else:
status.append(np.nan)
status.append(np.nan) #定义最后一个月的数据
return pd.Series(status,index = col)
pivoted_purchase_return= df_purchase.apply(purchase_return,axis=1)
#占比图
(pivoted_purchase_return.sum() / pivoted_purchase_return.count()).plot(figsize=(10,4))
#复购人数加总
pivoted_purchase_return2 = pd.DataFrame(pivoted_purchase_return.apply(lambda x:x.sum()))
#修改列名
pivoted_purchase_return2.columns=['m_repurchase']
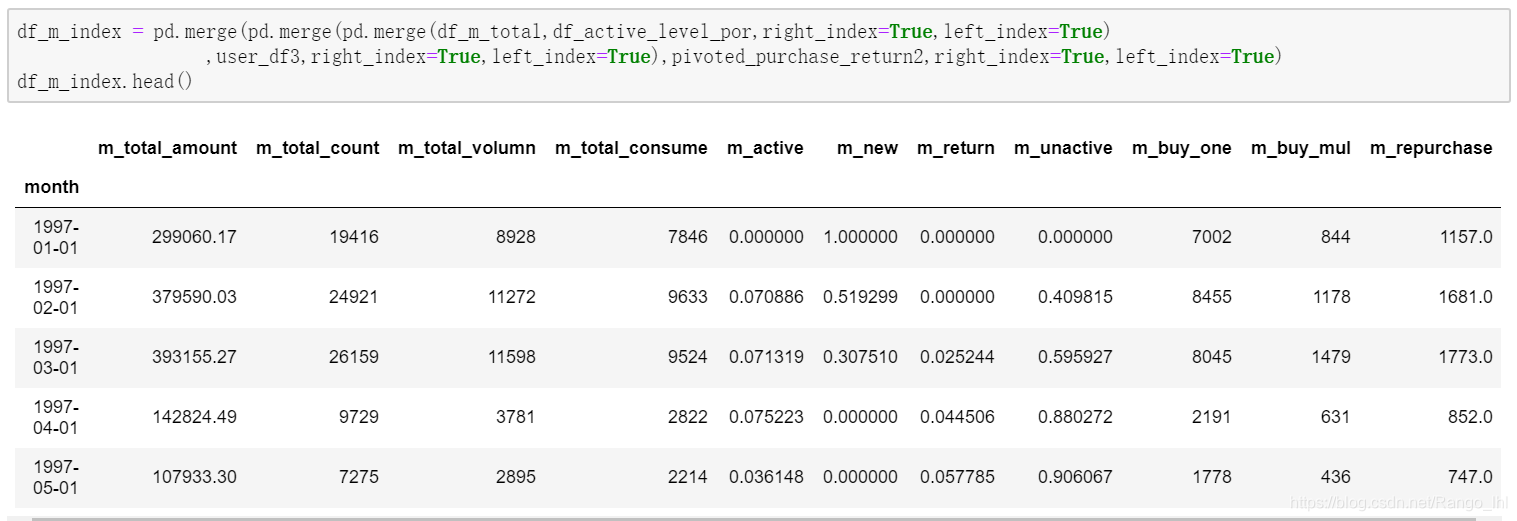
⑤指标合并
df_m_index = pd.merge(pd.merge(pd.merge(df_m_total,df_active_level_por,right_index=True,left_index=True)
,user_df3,right_index=True,left_index=True),pivoted_purchase_return2,right_index=True,left_index=True)
df_m_index.head()
二、用户维度
消费总额/消费次数/消费量/首次消费时间/最近一次消费时间/消费间隔
df_user = df.pivot_table(index='userid',values=['datetime','products','amounts']
,aggfunc={'datetime':['max','min'],'products':['sum','count'],'amounts':'sum'})
df_user['gap'] = (df_user['datetime']['max']-df_user['datetime']['min'])/np.timedelta64(1,'D')
df_user.columns=['u_total_amount','u_datetime_max','u_datetime_min','u_total_count','u_total_volumn','u_datetime_gap']
df_user.head()

学习交流,有任何问题还请随时评论指出交流。














 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









