







RocksDB
RocksDB是一个可嵌入的持久性key-value存储。它是一个日志结构的数据库,并针对快速存储进行了优化。RocksDB可以作为内嵌式数据库来使用,也可以作为自研数据库的底层存储引擎来使用,其主要的数据结构是LSM tree,保证了读写效率。业界采用RocksDB作为存储引擎的有:MyRocks 、华为云云数据库mongodb、百度开源图数据库HugeGraph、国产开源分布式数据库TiDB等等。
数据模型
RocksDB的数据模型是带版本号的K-V存储。每个对DB的修改都会有一个全局排序并且单调递增的序列号。对于每个key,RocksDB保留操作的历史。
混合(Hybrid)Key-Value存储:数据首先保存在内存中,当满足一定条件后数据持久存储。

RocksDB提供:
Get()——读取数据的接口
Put()——写入数据的接口
Delete()——删除数据的接口
Merge()——读后写,通过日志的方式记录,然后通过Compaction来清理日志
……
存储引擎
基础架构

上图是Rocksdb的基础架构。Rocksdb中引入了ColumnFamily(列族, CF)的概念,所有的读写操作都需要先指定列族。
Write-Ahead-Log File,预写日志,用于记录那些未被成功提交的数据操作,然后在重启时进行数据的恢复。
Memtable,内存数据结构,用以存储最近更新的DB更新操作。
ImmuTable,当一个 Memtable 写满了之后,就会变成ImmuTable,只读不可写。Memtable空间写满后,会触发一次写出更新操作到SST文件的操作。当一个 Memtable 写满了之后,就会变成只读的ImmuTable ,RocksDB 在后台会通过一个 flush 线程将这个 Memtable刷写到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。
SST File,SST文件是一段排序好的表文件,它是实际持久化的数据文件。里面的数据按照Key进行排序能方便对其进行二分查找。在SST文件内,还额外包含以下特殊信息:
- Bloom Filter,用于快速判断目标查询key是否存在于当前SST文件内。
- Index / Partition Index,SST内部数据块索引文件快速找到数据块的位置。
Block Cache,纯内存存储结构,存储SST文件被经常访问的热点数据。
ManiFest,负责记录系统某个时刻SST文件的视图。
Current,负责记录当前最新的Manifest文件名。
注: 每个ColumnFamily有自己的Memtable, SST文件,所有ColumnFamily共享WAL、Current、Manifest文件。
存储机制
RocksDB 是基于 LSM-Tree 的,存储机制大概如下:

首先,任何的写入都会先写到 WAL,然后再写入MemTable。
当一个 MemTable 写满了之后,就会变成 ImmuTable,RocksDB 在后台会通过一个 flush 线程将这个 Memtable刷写到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 Compaction 策略(去除相同key的多条记录)将其放到 Level 1 层,以此类推。
这里关键就是 Compaction,如果没有 Compaction,那么写入是非常快的,但会造成读性能降低,同样也会造成很严重的空间放大,即过期旧数据没有及时地被清理的问题。
传统LSM-Tree 能将离散的随机写请求都转换成批量的顺序写请求(WAL + Compaction),以此提高写性能。但也带来了一些问题:
- 读放大(Read Amplification)。LSM-Tree 的读操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次 I/O。特别是 range query 的情况,影响很明显。
- 空间放大(Space Amplification)。因为所有的写入都是顺序写(append-only)的,不是 in-place update ,所以过期数据不会马上被清理掉。
因此,RocksDB 通过后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据),但也因此带来了写放大的问题。
- 写放大(Write Amplification)。实际写入 SSD的数据大小和程序要求写入数据大小之比。正常情况下,SSD观察到的写入数据多于上层程序写入的数据。写放大太严重会大大缩短 SSD 的使用寿命。
为了平衡写入、读取、空间这些问题,RocksDB提供对应的参数,我们可以针对不同的使用场景调整参数,体现了RocksDB灵活与应用范围广泛的优势。对 RocksDB 的调优本质上是在这三个因子之间取得平衡。
应用实例 —— Mongo on RocksDB
RocksDB可以作为内嵌式数据库来使用,也可以作为自研数据库的底层存储引擎来使用。
从MongoDB 3.2版本开始,官方便将WiredTiger(采用B Tree的存储方式,适合顺序读)作为默认存储引擎并一直应用至今,基于RocksDB引擎则陷入沉寂。如今,基于RocksDB的新的MongoDB在华为云上已 “复活”。
RocksDB引擎凭借特性丰富,社区活跃,应用范围广泛,且支持更为良好的硬件存储性能等特点,更适用于云场景(读写操作频繁、普遍使用SSD、对数据持久化要求较高)。而MongoDB作为一款优秀的NoSQL数据库,支持海量存储,查询能力丰富以及优秀的性能和可靠性,深受国内外用户和企业的认可。
云数据库Mongo on RocksDB在华为云上应运而生,完全兼容MongoDB接口。
优势
基于RocksDB的MongoDB继承了RocksDB的下列特点:
-
由于RocksDB采用了优化的LSM算法,平均写性能良好。
-
RocksDB支持多点快照的特性, 利用该特性,能实现独特的快照/时间漫游功能,即客户能够读取数据库历史上的某个时间点的数据,具体可参考下方的内容。
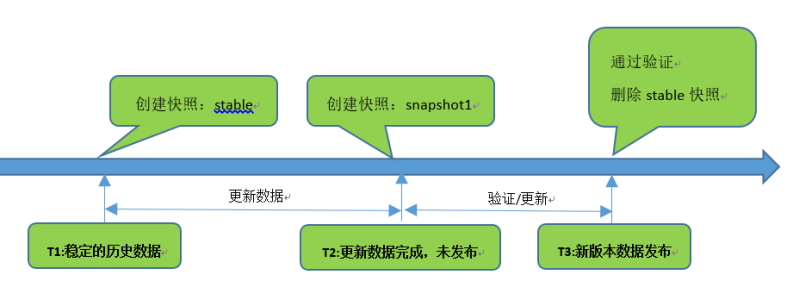
(1)创建名称为Stable的快照,终端用户默认访问T1时间点“稳定的历史数据”。
(2) 客户维护工程师开始更新数据,直到时间点T2,数据维护完成,未验证,不对外发布。
(3)到达T3时间点,数据更新完成,新版本数据发布,释放快照,终端用户访问最新版本数据。
通过新开发的Snapshot创建快照命令,该命令调用了RocksDB的API,RocksDB会自动捕获在创建的时间点的DB一致性视图,并保持在内存中。客户在T1和T2分别创建快照,无论数据如何变化,当用户切换到某快照视图时,应用查到的都只有对应时间点版本的数据,从而即简单又快捷的满足了需求。
-
更灵活的Compact操作。
Compact命令是MongoDB下发给存储引擎的关键命令,其主要作用是让存储引擎对集合数据和索引进行碎片整理。MongoDB对集合数据做删除操作时,会对删除数据打一个标记,而并非真正对集合数据做删除,等异步线程在后台慢慢删除,这么做好处是大规模的数据删除操作并不会对IO有巨大影响。Compact操作就是通过重写集合和索引数据,真正的释放磁盘空间给操作系统。
在云场景下,由于SSD硬盘的普遍使用,让RocksDB引擎的特点更充分的发挥,适合应用在低成本,大量数据频繁操作的应用场景,例如:网络游戏,物联网,车联网,大数据计算等众多领域。
劣势
- 当存储数据量大,Level层数较多时,扫描不同层会带来一定程度的读放大;(不适合读取大规模的数据)
- 为解决读放大、优化读而导致写放大;(需要权衡、调参)
- 数据顺序写入,非in-place update,为保证视图一致性,被remove的数据不会立刻清理,其次Level SST基本每层都会有冗余数据,这些都会导致空间放大。
适用场景
- 对写性能要求很高(通常写多读少),同时有较大内存来缓存SST块以提供快速读的场景;
- SSD等对写放大比较敏感以及磁盘等对随机写比较敏感的场景;
- 适用于云场景,SSD普遍使用的情况。
参考资料
RocksDB Overview · facebook/rocksdb Wiki · GitHub
欢迎使用RocksDB RocksDB中文网 | 一个持久型的key-value存储
LSM-Tree 的写放大写放大、读放大、空间放大RockDB 写放大简单分析参考文档















 2511
2511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









