







关于提取特征向量这件事
视觉图像领域提特征向量的方式:
- 古典方式:SIFI/HOG算法
- 现代方式:VGG、ResNet、MobileNet等网络
自然语言处理文本领域提特征向量的方式:
- 较早时期:N-Grams、TF-IDF、word2vec、embedding、Fast text等
- 目前:BLSTM、Transformer、BERT等
不论图像还是文本,下游的分类、检测等具体的AI任务均需要在上游对数据进行特征向量提取。例如文本的任务:文章相似的做推荐、情感分析做分类、命名实体识别等。
从RNN到BLSTM
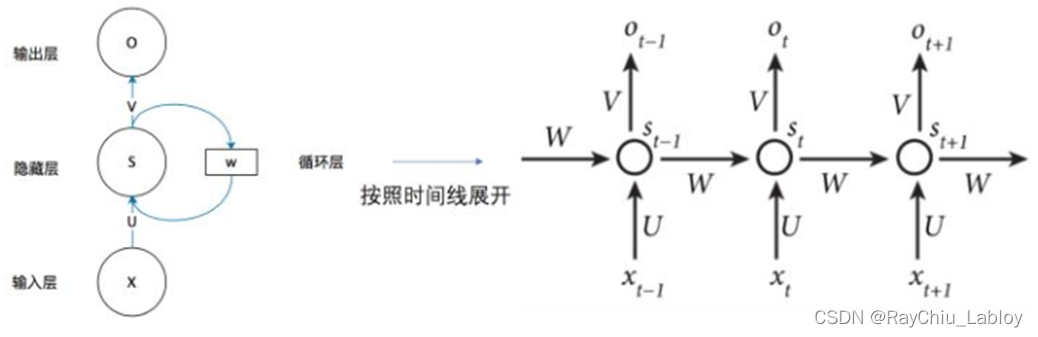
RNN循环神经网络解决了时序对数据带来的影响,但是有很大的梯度消失问题,LSTM三个门的结构减轻了这一影响,并且带来了更多的参数量,再到后来BLSTM结合CRF或者CNN就可以很好的处理一些NER的任务,虽然BLSTM比RNN在梯度消失方面好一些,但是问题还是存在,因此出现了Attention机制
从Encoder-Decoder架构到Attention机制
Seq2seq模型(序列模型)的几种任务模型拓扑结构:
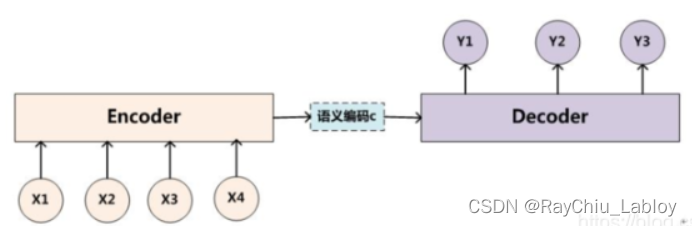
Encoder-Decoder框架属于many to many模式的,先通过编码器获得一个统一的语义编码C
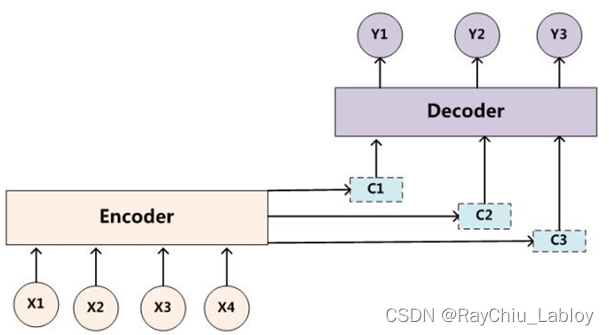
然后在解码器中使用相同的语义编码C进行数据解码,两步的公式如下:
C
=
f
(
x
1
,
x
2
,
.
.
.
,
x
m
)
y
i
=
g
(
C
,
y
1
,
x
2
,
.
.
.
,
y
i
)
C=f(x_{1},x_{2},...,x_{m})\\ y_{i}=g(C,y_{1},x_{2},...,y_{i})
C=f(x1,x2,...,xm)yi=g(C,y1,x2,...,yi)
但是由于计算量和效率问题这种没有”注意力机制“的分心模型逐渐被拟人的注意力Attention机制所取代,
比如一句英文”Tom chase Jerry“在翻译”杰瑞“的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何引入注意力的原因。
编码器在生成语义编码C的时候会考虑词的权重:
C
汤姆
=
g
(
0.5
∗
f
(
"
T
o
m
"
)
,
0.2
∗
f
(
"
c
h
a
s
e
"
)
,
0.3
∗
f
(
"
J
e
r
r
y
"
)
C
追逐
=
g
(
0.1
∗
f
(
"
T
o
m
"
)
,
0.8
∗
f
(
"
c
h
a
s
e
"
)
,
0.1
∗
f
(
"
J
e
r
r
y
"
)
C
杰瑞
=
g
(
0.2
∗
f
(
"
T
o
m
"
)
,
0.2
∗
f
(
"
c
h
a
s
e
"
)
,
0.6
∗
f
(
"
J
e
r
r
y
"
)
C_{汤姆}=g(0.5*f("Tom"),0.2*f("chase"),0.3*f("Jerry") \\ C_{追逐}=g(0.1*f("Tom"),0.8*f("chase"),0.1*f("Jerry")\\ C_{杰瑞}=g(0.2*f("Tom"),0.2*f("chase"),0.6*f("Jerry")
C汤姆=g(0.5∗f("Tom"),0.2∗f("chase"),0.3∗f("Jerry")C追逐=g(0.1∗f("Tom"),0.8∗f("chase"),0.1∗f("Jerry")C杰瑞=g(0.2∗f("Tom"),0.2∗f("chase"),0.6∗f("Jerry")
这种模式成了以下模式:
y
1
=
f
(
C
1
)
y
2
=
f
(
C
2
,
y
1
)
y
3
=
f
(
C
3
,
y
1
,
y
2
)
y_{1}=f(C_{1})\\y_{2}=f(C_{2},y_{1}) \\y_{3}=f(C_{3},y_{1},y_{2})
y1=f(C1)y2=f(C2,y1)y3=f(C3,y1,y2)
如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
那么用下图可以较为便捷地说明注意力分配概率分布值的通用计算过程。

小结一下Attention计算流程
- 先求Attention weights
- 再根据Attention weights求不同的Context Vector
- 再加权求和得出不用的输出 y i y_{i} yi
从Self-Attention到Transformer
咱们拿放大镜看看构造先。。
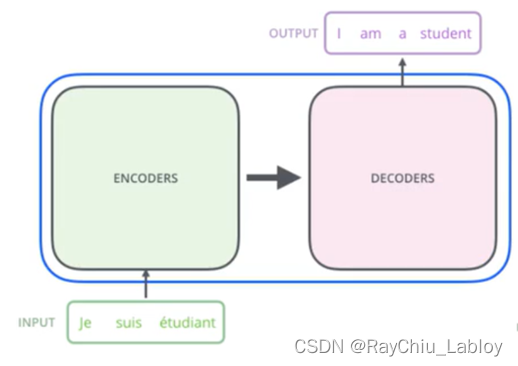
看到整体结构也是编解码的结构,然后放大看看,
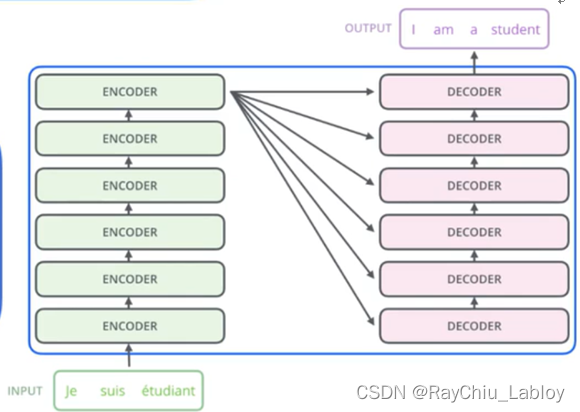
哦,6个编码器,6个解码器,再放大,看其中一层,
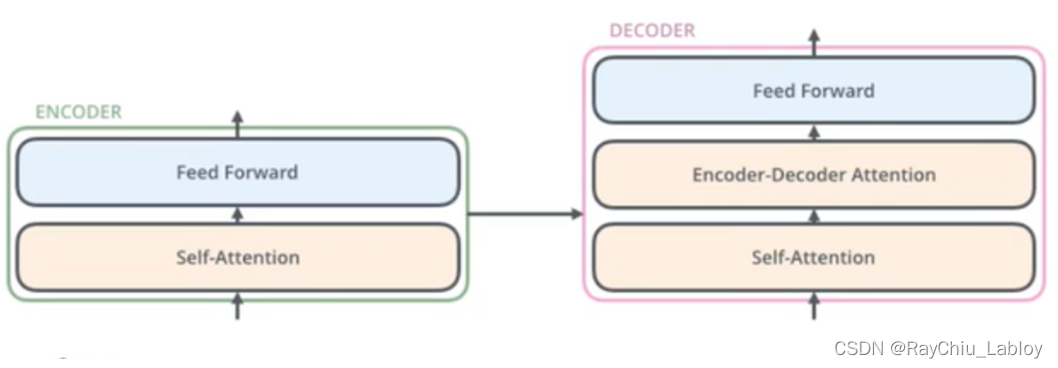
哦,编码器先是一个Self-Attention层,后跟一个Feed Forward层,解码器先是一个Self-Attention层,后跟一个Encoder-Decoder Attention层,再接一个Feed Forward层,然后再放大,
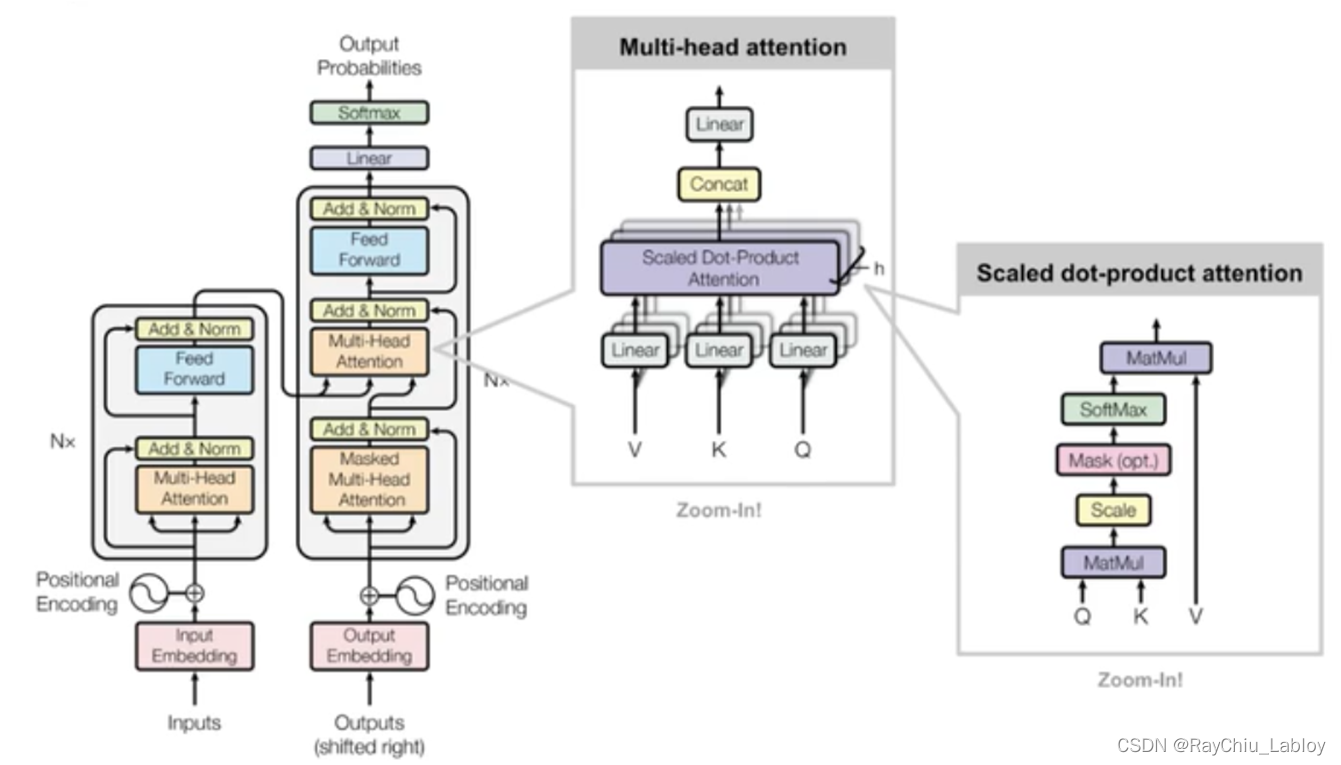
左侧是编解码总体结构,中间是多头注意力机制剖析图,右侧是自注意力机制计算图。
Self-Attention
自注意力机制是注意力机制的特例,擅长捕捉数据或特征的内部相关性。
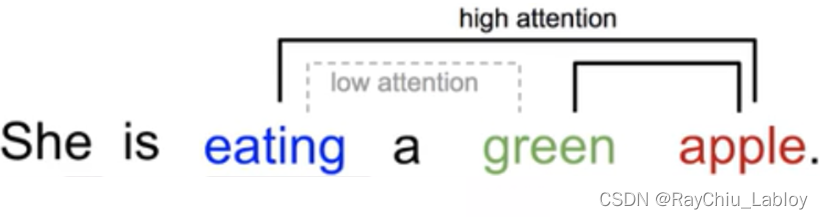
self attention就是Q,K,V来自于同一个序列,自注意力机制的计算过程:
- 将输入单词转化成嵌入向量;
- 根据嵌入向量得到q,k,v三个向量;
- 为每个向量计算一个score:score =q . k ;
- 为了梯度的稳定,Transformer使用了score归一化,即除以 ;
- 对score施以softmax激活函数;
- softmax点乘Value值v,得到加权的每个输入向量的评分v;
- 相加之后得到最终的输出结果z :z= v。
接下来我们详细看一下self-attention,其思想和attention类似,但是self-attention是Transformer用来将其他相关单词的“理解”转换成我们正在处理的单词的一种思路,我们看个例子: The animal didn’t cross the street because it was too tired 这里的it到底代表的是animal还是street呢,对于我们来说能很简单的判断出来,但是对于机器来说,是很难判断的,self-attention就能够让机器把it和animal联系起来,接下来我们看下详细的处理过程。
第一步 ,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果(上边编解码总体结构中可以看到input后先进行了embedding),这三个矩阵
W
Q
、
W
K
、
W
V
W^{Q}、W^{K}、W^{V}
WQ、WK、WV以及后边要说到的
W
0
W^{0}
W0是需要训练的参数。
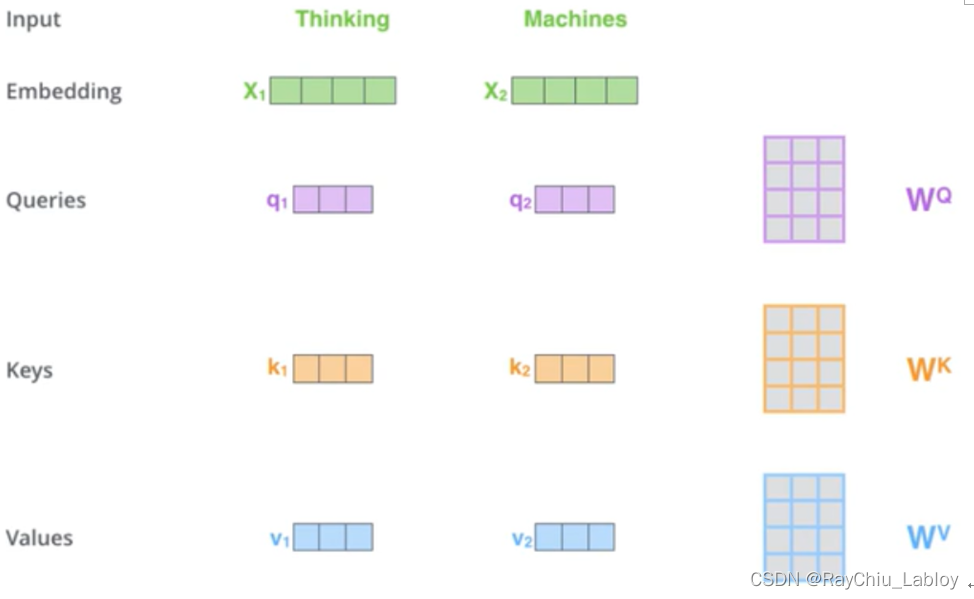
计算过程举例:
q
1
=
X
1
∗
W
Q
,
q
2
=
X
2
∗
W
Q
,
k
1
=
X
1
∗
W
K
.
.
.
q_{1}=X_{1}*W^{Q}, q_{2}=X_{2}*W^{Q}, k_{1}=X_{1}*W^{K}...
q1=X1∗WQ,q2=X2∗WQ,k1=X1∗WK...
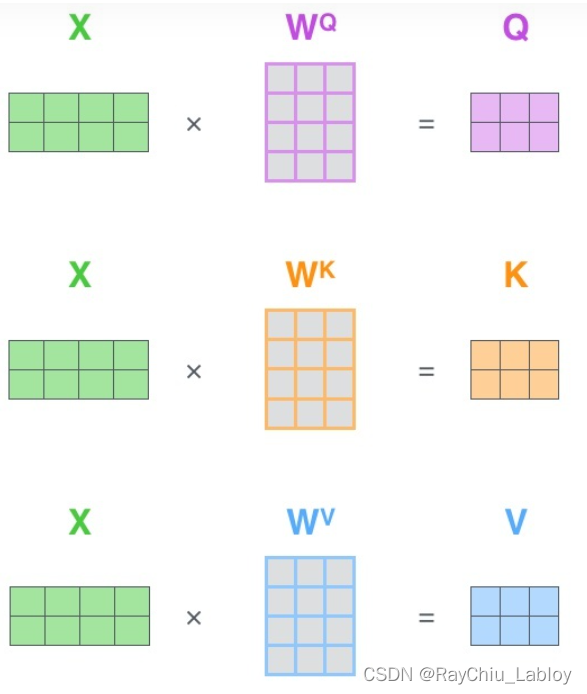
那么Query、Key、Value这三个向量又是什么呢?这三个向量对于attention来说很重要,当你理解了下文后,你将会明白这三个向量扮演者什么的角色。
第二步 权重计算流程:
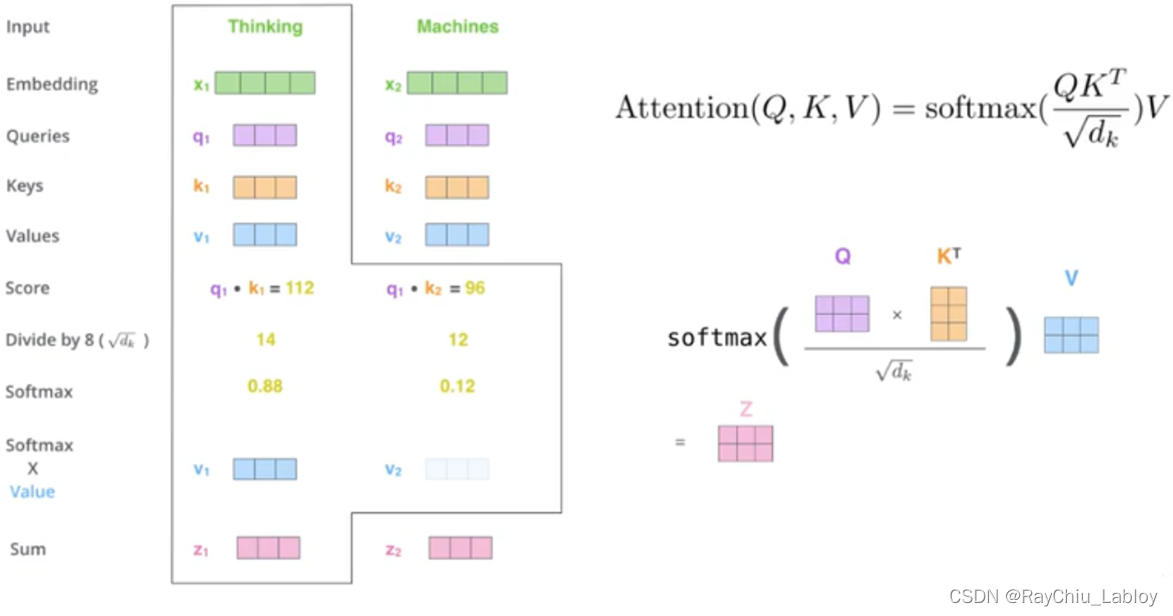
先Q和K相乘,然后除以8,经过Softmax后再与V相乘,这里计算的过程都是矩阵相乘,特点就是快,公式如上图右侧,这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention,可以对应到上边编解码总体结构中最右侧的部分。
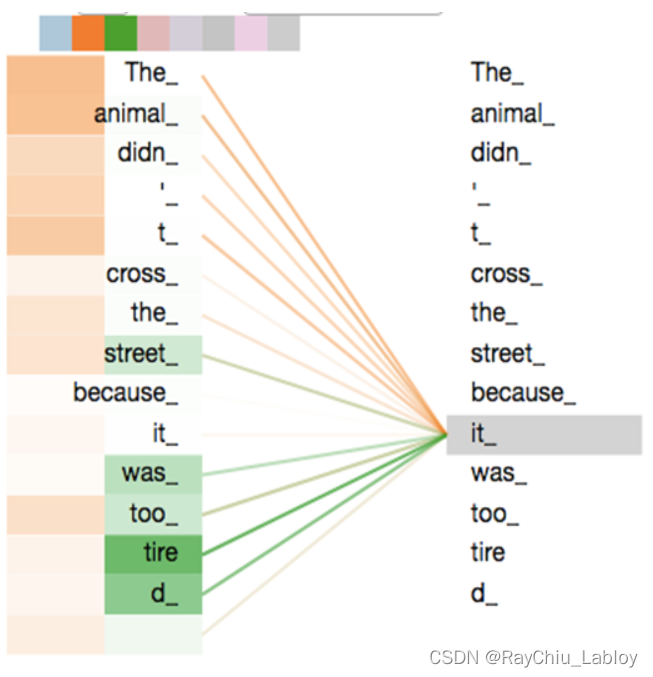
以上就是self-attention的计算过程,下边是两个句子中it与上下文单词的关系热点图,很容易看出来第一个图片中的it与animal关系很强,第二个图it与street关系很强。这个结果说明注意力机制是可以很好地学习到上下文的语言信息。

Multi Head
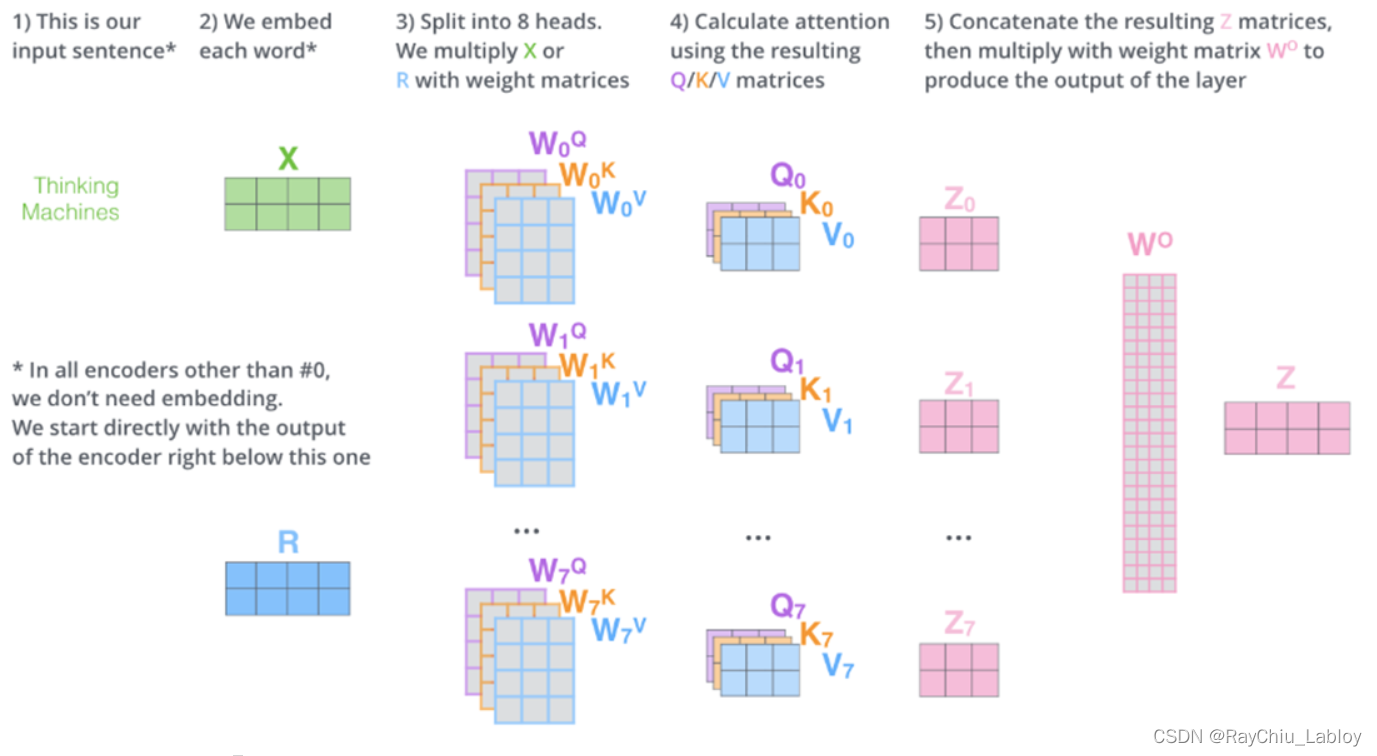
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
W
0
w
h
e
r
e
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
MultiHead(Q,K,V)=Concat(head_{1},...,head_{h})WW^{0}\\where head_{i}=Attention(QW^{Q}_{i},KW^{K}_{i},VW^{V}_{i})
MultiHead(Q,K,V)=Concat(head1,...,headh)WW0whereheadi=Attention(QWiQ,KWiK,VWiV)
最后我们来观察一下Multi-Head Attention的效果,已经其背后的含义。下面的第一张图片只展示了两次的Multi-Head Attention,我们还可以尝试来解释。黄色的注意力机制敏锐了步骤到了it这个代词所指代的对象,是animal;而绿色的注意力机制貌似是错误的,因为直接指向了一个动词tire。但细细琢磨,这似乎也有一定的道理,因为动词tire是服务于主语animal,而it在这里恰好指代的就是主语animal。
Masked
参考:https://blog.csdn.net/zhaohongfei_358/article/details/125858248
Decoder在输出的时候是一个字一个字的输出的,比如“机器学习真好玩”,Decoder的输入是“机器学习”时,“习”字只能看到前面的“机器学”三个字,所以此时对于“习”字只有“机器学习”四个字的注意力信息。
但是,例如最后一步传的是“机器学习真好玩”,还是不能让“习”字看到后面“真好玩”三个字,所以要使用mask将其盖住,这又是为什么呢?原因是:如果让“习”看到了后面的字,那么“习”字的编码就会发生变化。
Transformer
Scaled dot product Attention就是self-attention
Multi head Attention就是Scaled dot product Attention的堆积
Transformer就是Multi head Attention的堆积
Transformer的优点:
- Transformer 与 RNN /LSTM 等不同,它可以比较好地并行训练。
- Transformer 与 CNN 不同(有一些是基于CNN的Seq2seq模型),尽管CNN也可以进行并行训练,但是它的内存占用很大,相反 Transformer 的矩阵维度较少。更重要的是,Transformer 可以处理变长的序列样本,而CNN不行。
备注:其实归根结底,这是 Self-Attention 相较于 RNN / LSTM / CNN 等传统模型的优点(因为Transformer是基于Self-Attention的) - Transformer 不像 RNN / LSTM / CNN 等模型一样,需要较强的 domain knowledge (领域知识),其几乎可以对任意非结构化数据(图片、文本、音频)成立。这个其实也很好理解,例如CNN是专门进行图像处理设计的,需要对图像的本质有很深刻的理解。
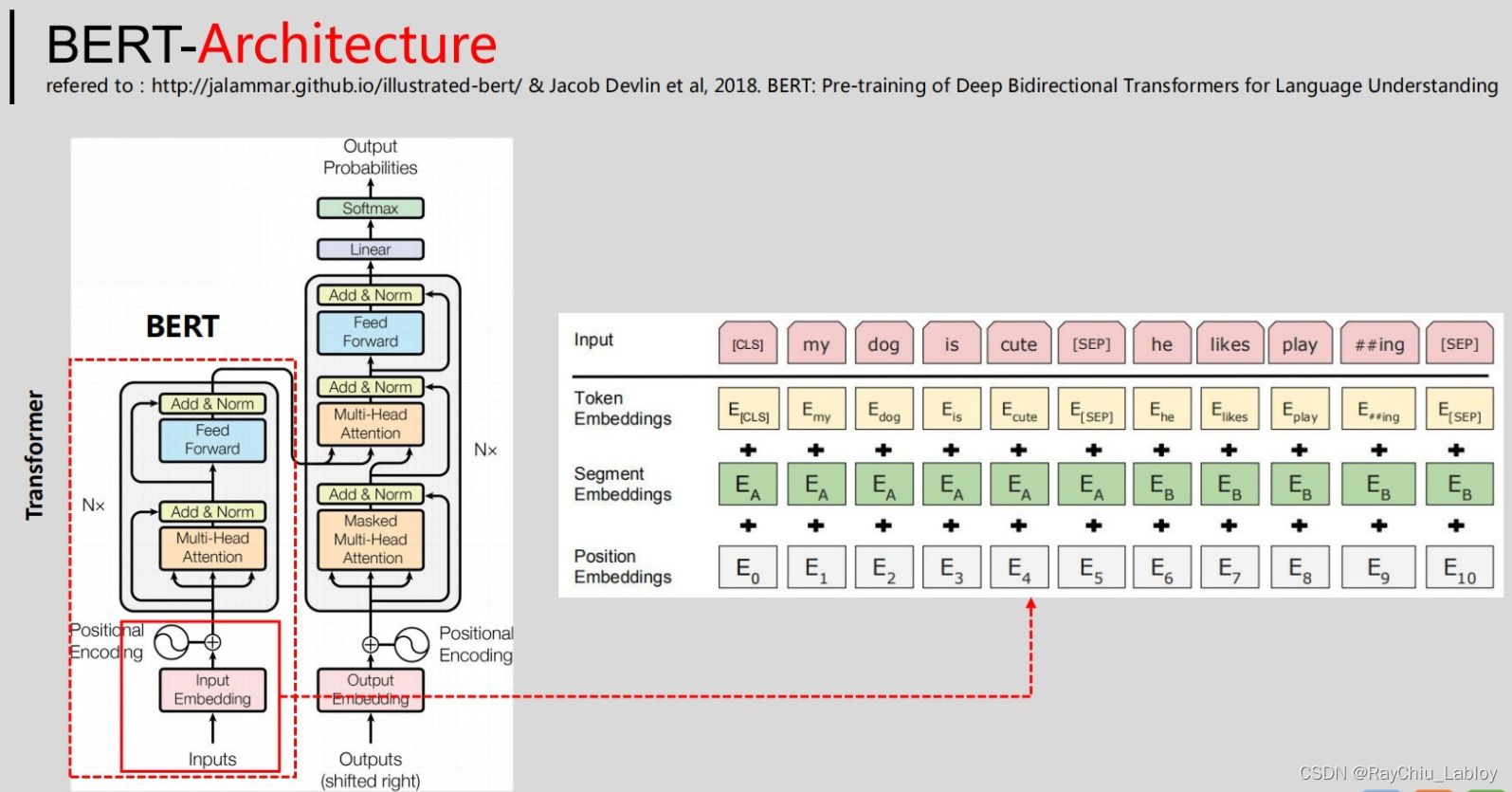
BERT
参考:https://zhuanlan.zhihu.com/p/365656960
参照下图,简单地,可以将BERT模型看做是Transformer的编码器部分,即我们可以用BERT模型来提取序列的特征,BERT因其强大的表示能力在迁移学习中得到非常广泛的应用。
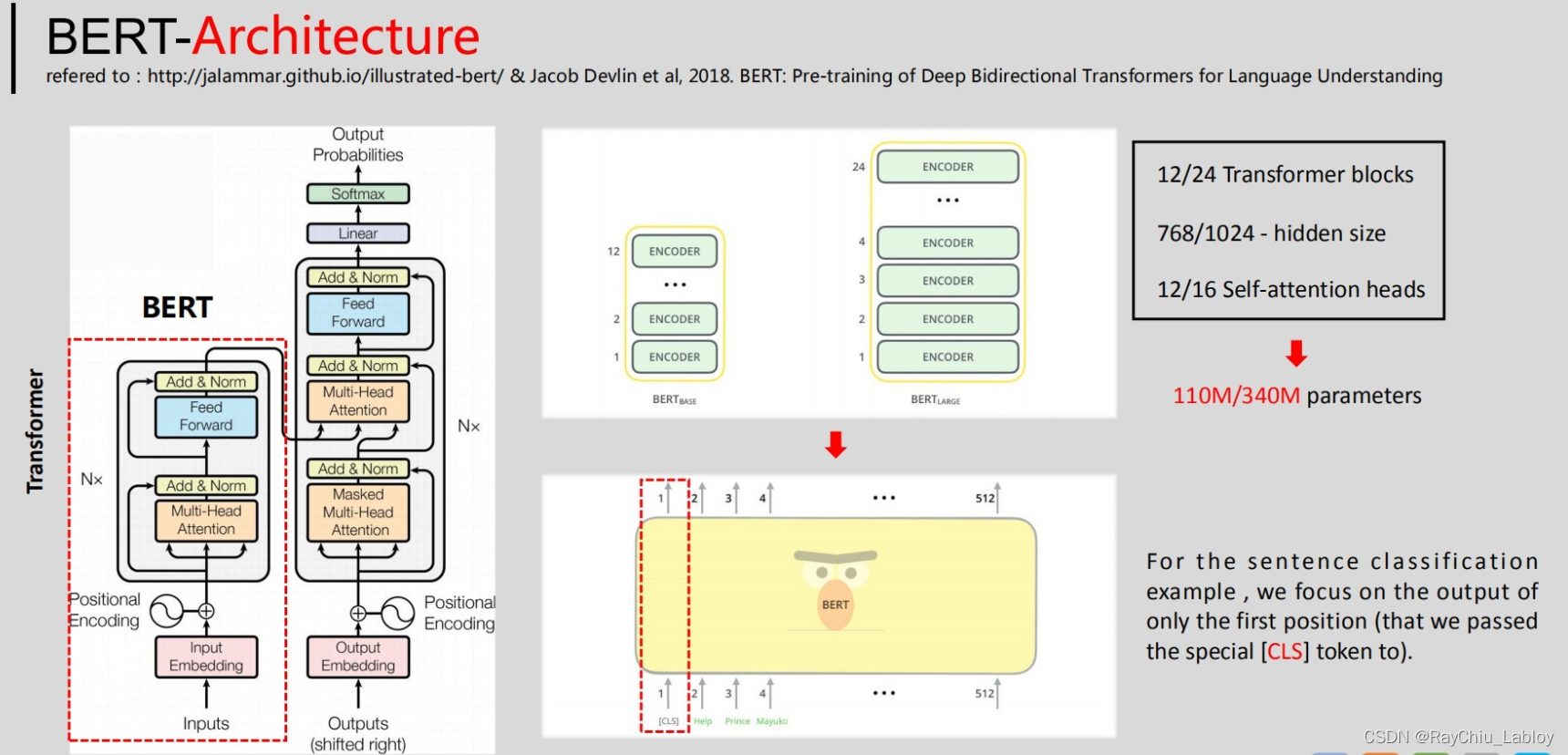
从结构上看,BERT模型与Transformer的区别在于其包含12个(base款)或24个(large款)Transformer block;另外,BERT中隐藏层输出的向量维度也大于Transformer;在自注意力机制中,BERT采用了12个(base款BERT)或16个(large款)head;
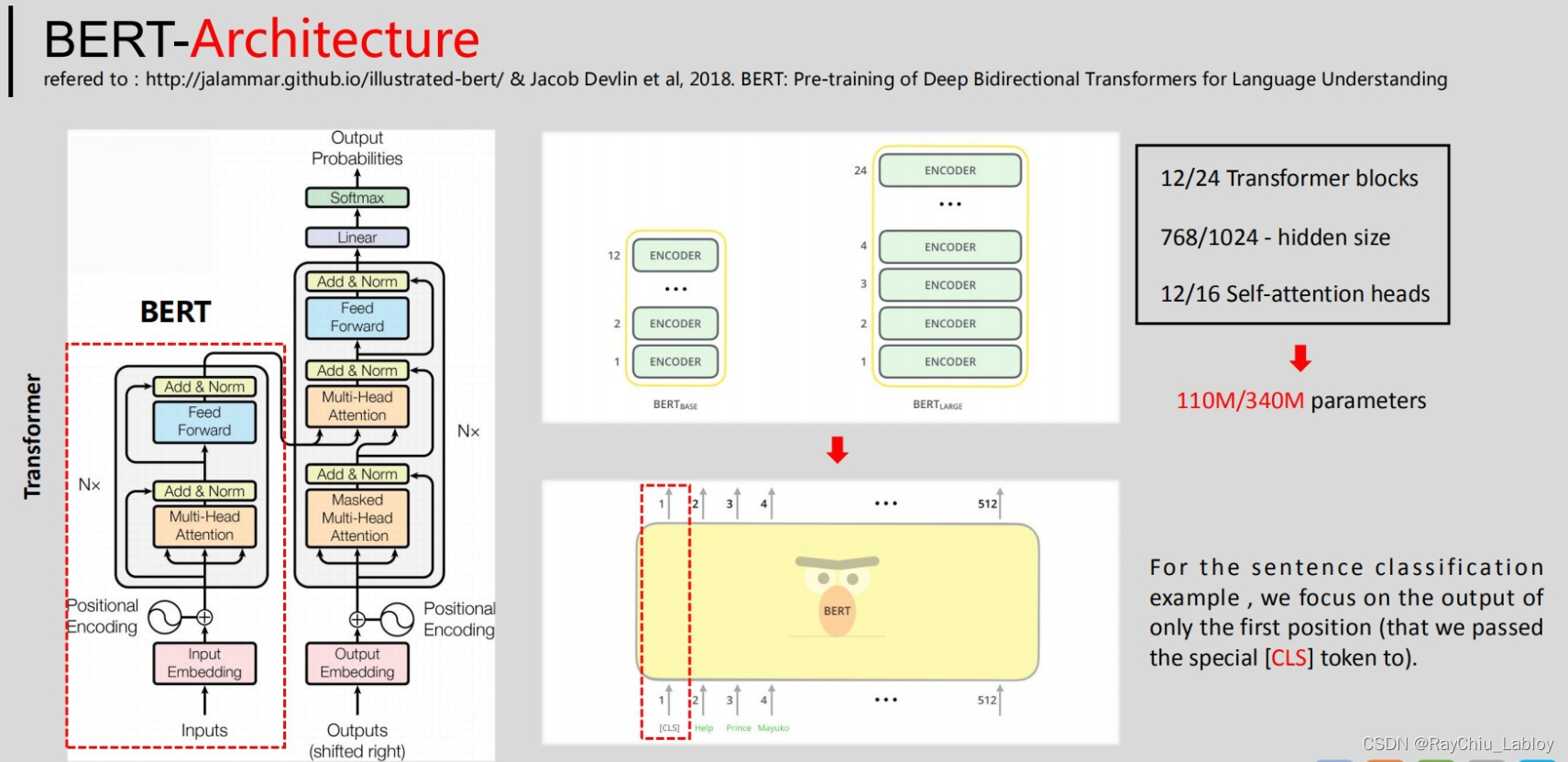
此外,在输入上,BERT与Transformer也有所不同,参照上图,BERT模型的输入向量中包含segment embeddings,其用来区分不同的句子。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









