






决策树
算法思想:
决策树,从本质上讲就是将已有数据集根据一些特定的规则进行分类,类似于编程中的if-else语句,逐级判断,一级一级的将所有数据进行划分,就像一棵树,从起点到划分的终点之间的环节称为枝干,终点集合称为子叶,子叶即是一个类别标签。当生成树之后,对于新数据只要按照特征值进行if判断,从枝干分类到子叶也就得到自己所属类别。
算法实现过程:
决策树的重点和难点是树的生成过程。可以认为所有的数据初始时候都在树的主干或根节点处,树生成的第一步就是如何划分出枝干,进而划分出子叶。划分枝干的过程是以数据集的所有特征来划分的,即if当前数据某一特征值是否满足特征值的要求,这样就得到了分支。这里就引出了第一个问题,数据集有很多的特征,每次划分到底该选哪个特征呢?是随机选的吗?(肯定不能这么随意啦,当然要选择出一个使整个划分结果最好的特征,后面会解释特征值如何选取,这也是决策树的难点)。说完枝干接着说子叶,什么时候可以划分出子叶?两种情况,1.当某个分支不能再继续划分出其他分支的时候,也就是该分支下所有数据都有同样的属性,这样就得到了子叶,从而确定了类别标签,无需再进行划分。2.所有特征都作为划分依据把数据集划分完成后,没有可以再进行划分的依据了,这样也就到达了子叶,但是这时子叶中可能并不都是相同的属性,因为它们本来并不是子叶,只是没有划分枝干的特征了,这时候我们可以统计该子叶中各种类别的个数,以个数最多的属性代表这一子叶的类别标签。以上就是构建决策树所需的枝干和子叶了。下面用伪代码的形式描述一下决策树的生成过程。
伪代码函数createBranch():
检测数据集中的每一个子集是否属于同一个分类:
If so return 类别标签
else
寻找划分数据集的最好特征
划分数据集
创建节点分支
for 每个划分的子集
调用createBranch()并增加返回结果到分支节点中
return 分支节点
接下来具体介绍特征的选择方法,比较选择不同特征的优劣需要引入一个能量化的概念——信息熵。
信息的定义:如果某一待分类事物可以划分到多个类别当中,则符号Xi的信息定义为:
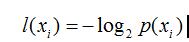
其中P(Xi)是事物属于Xi的概率。
信息熵的定义:
对分类系统来说,类别C是变量,它可能的取值是C1,C2,……,Cn,而每一个类别出现的概率是P(C1),P(C2),……,P(Cn),因此n就是类别的总数。此时分类系统的熵就可以表示为:
信息熵也就是所有信息的加权之和!
回到选择特征的话题,我们先计算出数据集在未进行分类初始时候的信息熵 ,然后遍历所有特征进行分类,对每一次分类后的数据集计算其信息熵,该熵值和初始信息熵的值做差值计算,差值最大的,也即熵减小最多的就是最好的特征值。
(未完待续。。)















 3539
3539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









