







问题背景及其描述
背景描述戳这里主要讲述了,在泰坦尼克号的首航中,不幸与冰山相撞,导致大量乘客与船员伤亡,而没有足够的救生艇是造成这次悲剧的主要原因之一。虽说那些幸存者是比较幸运的,但很明显对于妇女、孩子以及上层阶级等这些群体的人是更可能幸存下来的。So,我们的任务就是根据提供的初始数据特征预测出哪些人更可能在这场灾难中存活下来
主要数据特征
| 特征 | 描述 |
|---|---|
| Survived | 是否存活, v∈{0,1} v ∈ { 0 , 1 } |
| Pclass | 票的类别,用以表示社会经济地位(SES), v∈{1,2,3} v ∈ { 1 , 2 , 3 } |
| Sex | 性别(male, female) |
| Age | 年龄,如果没有准确的年龄,估计为xx.5的形式, v∈R+ v ∈ R + |
| SibSp | 船上(堂)兄弟姐妹及丈夫妻子的总人数, v∈N v ∈ N |
| Parch | 船上子女及父母的总人数, v∈N v ∈ N |
| Ticket | 船票的相关信息 |
| Fare | 乘客票价, v∈R+ v ∈ R + |
| Cabin | 船舱号码 |
| Embarked | 登船港口, v∈{C,S,Q} v ∈ { C , S , Q } |
数据特征分析
主要数据大致分布情况
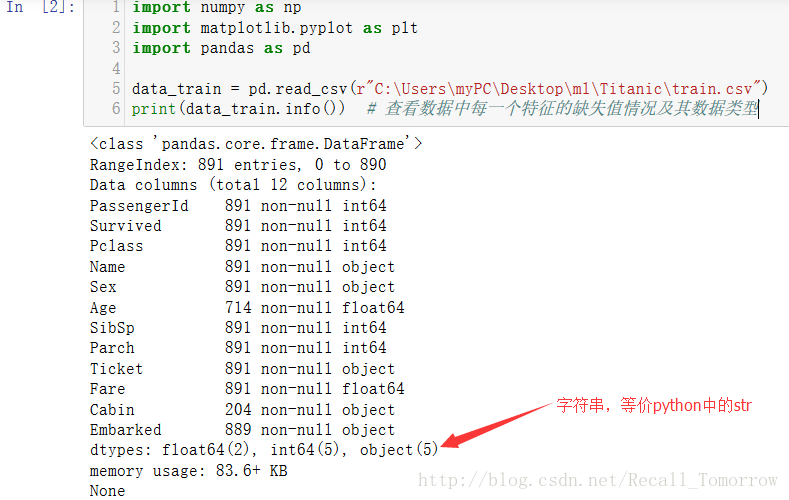
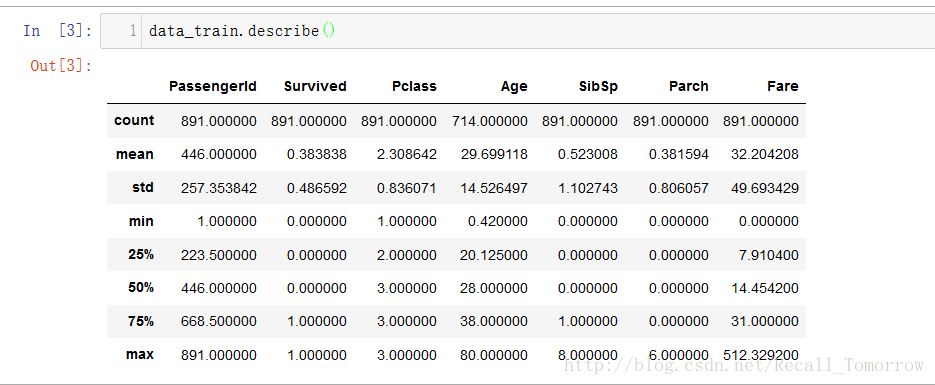
从上图我们可以清楚的看出每一个特征的数据大致分布情况,如平均数,标准差,下四分位数(Q1),中位数(Q2),上四分位数(Q3),最小(大)值等
在了解这些预备信息后,我们才能对数据有一个清晰的了解,只有这样才能进行最重要的工作
⟹
⟹
特征工程(Feature Engineering)这里是一个简要说明。
接下来我们一起看看几个特征各自不同取值下的存活分布情况
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文字符
plt.subplot2grid((4, 4), (0, 0), colspan=2, rowspan=2)
data_train.Survived.value_counts().plot(kind='bar', title='Survived')
plt.ylabel('persons')
plt.subplot2grid((4, 4), (0, 2), colspan=2, rowspan=2)
data_train.Pclass[data_train.Survived == 0].plot(kind='kde')
data_train.Pclass[data_train.Survived == 1].plot(kind='kde')
plt.title('Pclass')
plt.legend(('Deceased', 'Survived'))
plt.ylabel('persons')
plt.subplot2grid((4, 4), (2, 0), colspan=2, rowspan=2)
data_train.Age[data_train.Survived == 0].plot(kind='kde', title='Age')
data_train.Age[data_train.Survived == 1].plot(kind='kde')
plt.legend(('Deceased', 'Survived'))
plt.subplot2grid((4, 4), (2, 2), colspan=2, rowspan=2)
data_train.Embarked[data_train.Embarked == 'C'] = 1
data_train.Embarked[data_train.Embarked == 'S'] = 2
data_train.Embarked[data_train.Embarked == 'Q'] = 3
# print(data_train['Embarked'])
data_train.Embarked[data_train.Survived == 0].plot(kind='density', title='Embarked')
data_train.Embarked[data_train.Survived == 1].plot(kind='density', title='Embarked')
plt.legend(('Deceased', 'Survived'))
plt.show()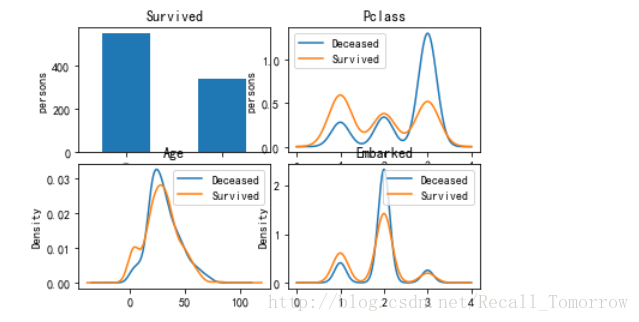
从上图我们可以清楚的看出,
1. 对于下层阶级的群体死亡率较高
2. 小孩及年长的群体更可能存活下来
3. 来自于Southampton港口的群体的死亡率相对高一些???
接下来观察一下性别(Sex)对结果的影响,
# 男性存活情况
survived_male = data_train.Survived[data_train.Sex == 'male'].value_counts()
# 女性存活情况
survived_female = data_train.Survived[data_train.Sex == 'female'].value_counts()
df = pd.DataFrame({'Male': survived_male, 'Female': survived_female})
# df
df.plot(kind='bar', title='Sex') # df.plot(kind='bar', stacked=True)
plt.ylabel('persons')
plt.show()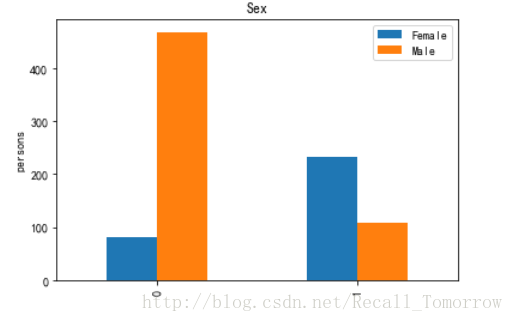
同样我们可以看出男性的死亡率明显高于女性。。。
当然这些只是初步的数据分析,实际情况远不止如此。。。
让我们看看原始的数据集,
print(data_train)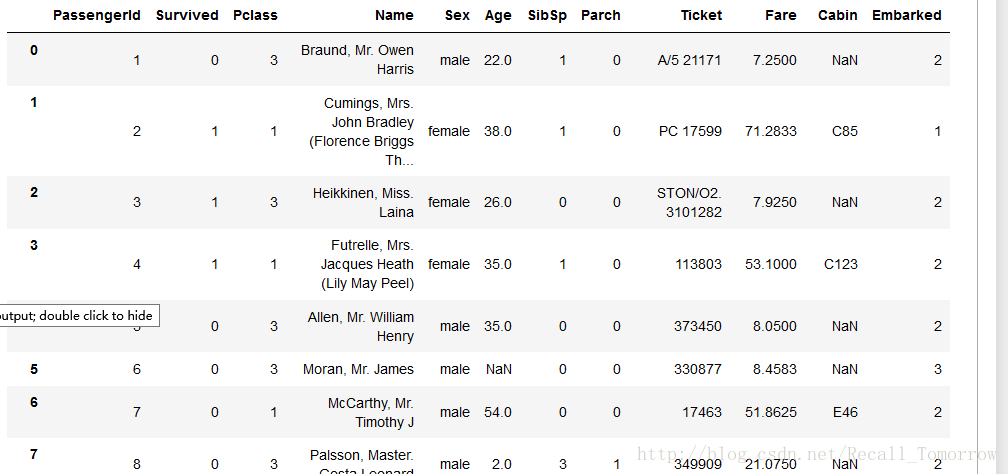
数据简单预处理
这里就不一一描述了,只是简单的描述一下所做的事情,至于完整实现可以戳这里,当然了,都有详细的注释。。。
下面将是简单特征工程(Feature Engineering)部分,没有涉及特征抽取(Feature Extraction)
1. Age: 从上可知这个feature的缺失值比较多,我们的处理的方式是,通过其他的几个features来进行预测(我使用的是随机森林回归算法)
2. Cabin:同样这个feature的缺失值也较多,而我的处理方案是简单的二值化(Binarization),即有值就为1,否则(NaN)为0
3. 对Pclass以及Embarked这两个features进行Dummy化(离散型类别,这样可以消除类别间的相关信息)
4. 对Age和Fare这两个特征进行标准化
对这些特征进行初步的处理后,得到预处理数据集(部分非全部),
print(dataset_training_dummies)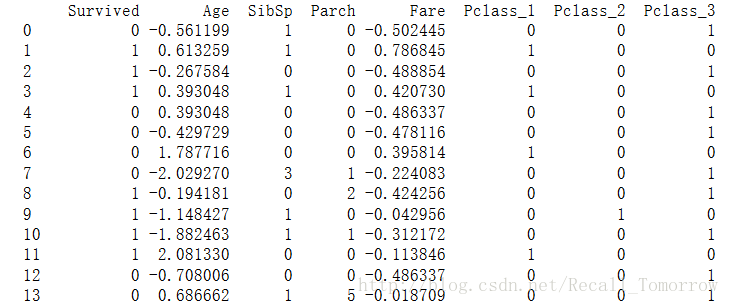
代码
本例的完整代码已上传至GitHub中,欢迎查看。。。
最后我要说的是,前面的这些工作只是冰山一角,因为我们只是构建了一个初始的Model,后面的模型Analysis以及Evaluation
⟹
⟹
Optimization才是关键
下面做一下交叉验证(Cross-validation)
from sklearn import model_selection
training_data = dataset_training_dummies[:, 1:]
training_target = dataset_training_dummies[:, 0:1]
lr = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-5)
print(model_selection.cross_val_score(lr, training_data, training_target, cv=4))

另外,还有就是可以将训练的Model的系数与每一个特征的相关性得到lr.coef_进而进一步分析数据特征,得到组合特征等,也可通过Model Ensemble的方式提高性能等等。。。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









