







首先分析一下所给题目的要求:
题目:爬取知乎首页问题及问题的回答
1) 登录后的知乎首页
2) 只需第一页的问题及相应问题的第一页回答(回答只需提取文字)
3) 使用Scrapy框架
分析:
1:所要爬取的问题来自于“登录”后的知乎首页,那么首先要解决的是“知乎的登录问题”。
2:问题只需要第一页上面的几个问题(回答也是),意味着不用去考虑知乎首页动态加载的问题,只需要获取登录后的首页所包含的问题链接,然后再对所提取的response用BeautifulSoup进行解析,提取所要的信息。回答只需要提取文字,意味着不用考虑回答中图片的下载问题。
3:要使用Scrapy框架来爬取,在看到这个题目之前,只学过request,所以还要去学一下Scrapy框架。mooc上面北理的“Python网络爬虫与信息提取”里面有Scrapy框架的部分,还有Scrapy的文档,学完之后再结合博客上的“小白进阶之Scrapy”的几篇总结,基本上可以完成这个题目。
PS:第一次用Scrapy框架(小白一枚),文章可能有不严谨的地方,欢迎指正!
Scrapy框架的小总结:
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合,是一个半成品。简单来说,框架可以帮我们处理一部分事情,比如下载模块不用我们自己写了,我们只需专注于提取数据就好了,最重要的是,框架使用了异步的模式,可以加快我们的下载速度,而不用自己去实现异步框架。
Scrapy的框架结构(5+2结构):

数据流(requests,response)的三个路径 :
第一条路径:
① :Engine从Spider处获得爬取请求(Request)
② :Engine将爬取请求转发给Scheduler,用于调度
第二条路径:
③ :Engine从Scheduler处获得下一个要爬取的请求
④ :Engine将爬取请求通过中间件发送给Downloader
⑤ :爬取网页后,Downloader形成响应(Response) 通过中间件发给Engine
⑥ : Engine将收到的响应通过中间件发送给Spider处理
第三条路径:
⑦ :Spider处理响应后产生爬取项(scraped Item) 和新的爬取请求(Requests)给Engine
⑧ :Engine将爬取项发送给Item Pipeline(框架出口)并且Engine将爬取请求发送给Scheduler
数据流的出入口:
Engine控制各模块数据流,不间断从Scheduler处 获得爬取请求,直至请求为空
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
各模块(结构)的作用:
Spider(需要用户编写配置代码):
(1)解析Downloader返回的响应(Response)
(2)产生爬取项(scraped item)
(3)产生额外的爬取请求(Request)
Item Pipelines (需要用户编写配置代码):
(1)以流水线方式处理Spider产生的爬取项
(2)由一组操作顺序组成,类似流水线,每个操 作是一个Item Pipeline类型
(3)可能操作包括:清理、检验和查重爬取项中 的HTML数据、将数据存储到数据库
Engine(不需要用户修改):
(1)控制所有模块之间的数据流
(2)根据条件触发事件
Downloader(不需要用户修改): 根据请求下载网页
Scheduler(不需要用户修改): 对所有爬取请求进行调度管理
Downloader Middleware(用户可以编写配置代码):
目的:实施Engine、Scheduler和Downloader 之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
Spider Middleware(用户可以编写配置代码):
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
具体编程分析():
对于这道题只需要编写Spider和Item Pipelines这两个模块中的文件即可。
安装好Scrapy库后,要创建一个项目,CMD进入你需要放置项目的目录 输入:
- scrapy startproject XXXX #XXXX是你的项目名称
这个命令会在对应目录中生成一些文件,也就是项目。
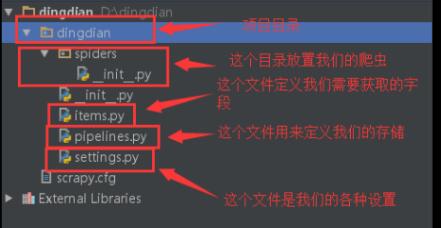
项目创建完成后:
第一件事:是在items.py文件中定义一些字段,这些字段用来临时存储你需要保存的数据。方便后面保存数据到其他地方,比如本地文本之类的。
第二件事:在spiders文件夹中编写自己的爬虫(CMD进入所生成的项目的目录,用语句:scrapygenspider[options] <name> <domain> 创建一个爬虫,或者在项目目录下spiders下直接新建一个 XXXX.py 文件即可,XXXX是该项目的爬虫)。
第三件事:在pipelines.py中存储自己的数据。
还有一件事:一般来说不是非做不可的,settings.py文件并不是一定要编辑的,只有有需要的时候才会编辑,我最后把提取的内容存为了txt文件,所以要在settings.py文件中设置。
ITEM_PIPELINES = {
'scrapy_zhihu.pipelines.ScrapyZhihuPipeline': 300,
} #在settings.py文件中找到ITEM_PIPELINES并取消注释,将里面的值赋为300。 所以我们只需要编辑:items.py,spider_name.py和pipelines.py这3个文件即可。
再明确一下其中最重要的spider_name.py文件的三个任务:
(1):生成HTTP请求request(即要访问的URL,如登录时访问的首页URL,首页中提取出来的问题URL)
(2):处理(解析)Download生成的response(即提取所需要的的信息,用BeautifulSoup对response解析)
(3):生成Item(提取的信息,return item)
知乎的登录问题:
一般不用登录的网页,爬取的时候直接把网页的链接当成request就可以,比较简单。而现在要提取的是首页的问题,那么首先必须得先登录,即spider_name.py文件中申请的request是包含了你的登录信息的。而request中的登录信息就是浏览器的cookies,那这个cookies在哪呢?
首先打开一个浏览器并登录你的知乎账号,然后按F12,右上角点击Application,找到左边一栏的Cookies,它就包含了你的登录信息(用的是Chrome浏览器)。

可以发现cookies就是一个字典(Name当成key),我们把它全部都复制下来放到一个字典里面。
- #登录用的cookis
- cookies = {
- "_xsrf" : "204e9e85-ee81-4105省略...",
- "_zap" : "18e5599a-4e8a省略...",
- "aliyungf_tc" : "AQAAAIxDfh/mF省略...",
- "capsion_ticket"
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









