







HDFS(Hadoop Distributed File System),Hadoop分布式文件系统。适用于一次写入,多次读取的场景。
1、优缺点
(1)优点
- 高容错性:通过增加副本的形式来提高容错性。在一个节点上,副本最多只有一个,某节点挂了之后,若可用节点依旧大于等于副本数量,则会自动增加一个副本到其他节点。
- 适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据;
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大。
(2)缺点
- 不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
- 无法高效的对大量小文件进行存储。
- 存储大量小文件的话,它会占用N ameN ode大量的内存来存储文件目录和块信息。这样是不可取的,因为NamneNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
- 不支持并发写入、文件随机修改。
- 一个文件只能有一一个写,不允许多个线程同时写;
- 仅支持数据append (追加), 不支持文件的随机修改。
2、架构简介
参考官网
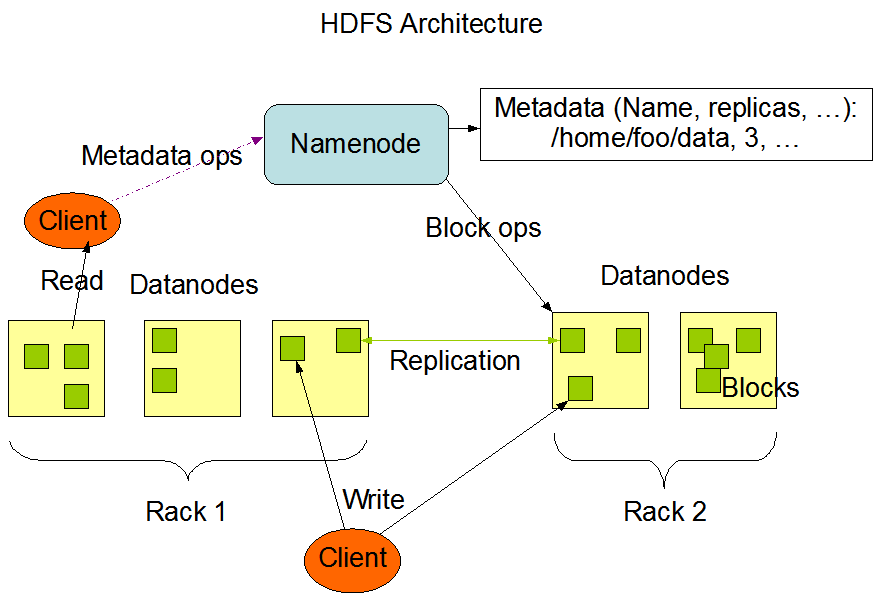
HDFS 具有主/从架构。HDFS 集群由单个 NameNode 组成,这是一个管理文件系统命名空间并控制客户端对文件的访问的主服务器。此外,还有许多 DataNode,通常集群中每个节点一个,用于管理附加到它们运行的节点的存储。HDFS 公开了一个文件系统命名空间,并允许将用户数据存储在文件中。在内部,一个文件被分成一个或多个块,这些块存储在一组 DataNode 中。NameNode 执行文件系统命名空间操作,例如打开、关闭和重命名文件和目录。它还确定块到 DataNode 的映射。DataNode 负责处理来自文件系统客户端的读取和写入请求。DataNodes 还执行块创建、删除。(翻译自官方)
简单点讲,在 HDFS 中,NameNode(NN)就是 master 的角色,它的主要功能包括下面几个方面
- 管理 HDFS 的名称空间
- 配置副本策略
- 管理数据块(Block)的映射信息
- 处理客户端的读写请求
而 DataNode 就是 slave 的角色,NameNode 下达命令后交于 DataNode 执行
- 存储实际数据块
- 执行数据块的读写操作
Client 即客户端,有以下几个主要功能
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个个的 Block,然后进行上传;
- 与 NameNode 交互,获取文件的位置信息;
- 与 DataNode 交互,读取或者写入数据;
- Client提供一些命令来管理 HDFS,比如 NameNode 格式化;
- Client可以通过一些命令来访问 HDFS,比如对 HDFS 增删查改操作;
SecondaryNameNode(图中没有画出来),并非 NameNode 的热备。当 NmeNode 挂掉的时候, 它并不
能马上替换 NameNode 并提供服务。
- 辅助ameNode.分担其工作量,比如定期合并 FsImage,并推送 NameNode;
- 在紧急情况下,可辅助恢复 NameNode
3、文件块
HDFS 旨在跨大型集群中的机器可靠地存储非常大的文件,它将每个文件存储为一系列块,复制文件的块以实现容错。每个文件的块大小和复制因子是可配置的。
HDFS 中的文件在物理上是分块存储(Block) ,块的大小可以通过配置参数 dfs .blocksize 来规定,默认大小在Hadoop2.x/3.x版本中是128M(与磁盘的传输速率相近),1.x版本中是64M。
数据块不能设置得太大,也不能设置得太小,块太小,则相应的数量会增多,会增加块开始位置的寻址时间;而如果块设置得太大,则磁盘传输数据时间会明显大于定位这个块开始位置所需的时间,导致程序在处理这个块数据时非常慢。
块的大小设置主要取决于磁盘的传输速率。
每一个块在创建的时候,都有一个校验和,这些块的校验和会存储在相同命名空间中的单独掩藏文件中。客户端检索文件内容时,它会验证从每个 DataNode 接收到的数据是否与存储在关联校验和文件中的校验和匹配。如果没有,那么客户端可以选择从另一个具有该块副本的 DataNode 检索该块。
4、副本
副本的放置对于 HDFS 的可靠性和性能至关重要。通常在设置副本策略的时候,需要综合考虑带宽等因素。
当复制因子为 3 时,HDFS 的放置策略是,如果 writer 在 datanode 上,则将一个副本放在本地机器上,否则在与 writer 相同机架的随机 datanode 上,另一个副本在节点上在不同的(远程)机架中,最后一个在同一远程机架中的不同节点上。如果复制因子大于 3,则随机确定第 4 个和后续副本的放置,同时保持每个机架的副本数低于上限(基本上是 (副本 - 1) / 机架 + 2)。
三种常见的故障类型是 NameNode 故障、DataNode 故障和网络分区。
DataNode 与 NameNode 之间通过心跳检查来进行维护。NameNode 会将最近没有收到心跳的 DataNode 标记为死亡,后续的 IO 请求都不会转发到死亡的 DataNode,同时,DataNode 故障势必会导致某些文件块的副本数低于设定值,这时候就由 NameNode 来决定是否需要进行副本复制。
心跳检测的超时时间最好在10分钟以上,避免 DataNode 状态波动引起 NameNode 的复制风暴。















 5363
5363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









