







 本文记录了学习《大数据基础》过程中,使用Linux系统操作Hadoop和Spark Shell的步骤,包括启动Hadoop和Spark Shell,创建HDFS目录,上传文件,读取文件并进行行数统计,筛选特定内容,进行词频统计,降序排列,保存到HDFS,文件合并,下载到本地,并展示最终结果。
本文记录了学习《大数据基础》过程中,使用Linux系统操作Hadoop和Spark Shell的步骤,包括启动Hadoop和Spark Shell,创建HDFS目录,上传文件,读取文件并进行行数统计,筛选特定内容,进行词频统计,降序排列,保存到HDFS,文件合并,下载到本地,并展示最终结果。
刚学这本书,记录一下Linux系统一些操作,方便以后自己回顾学习。
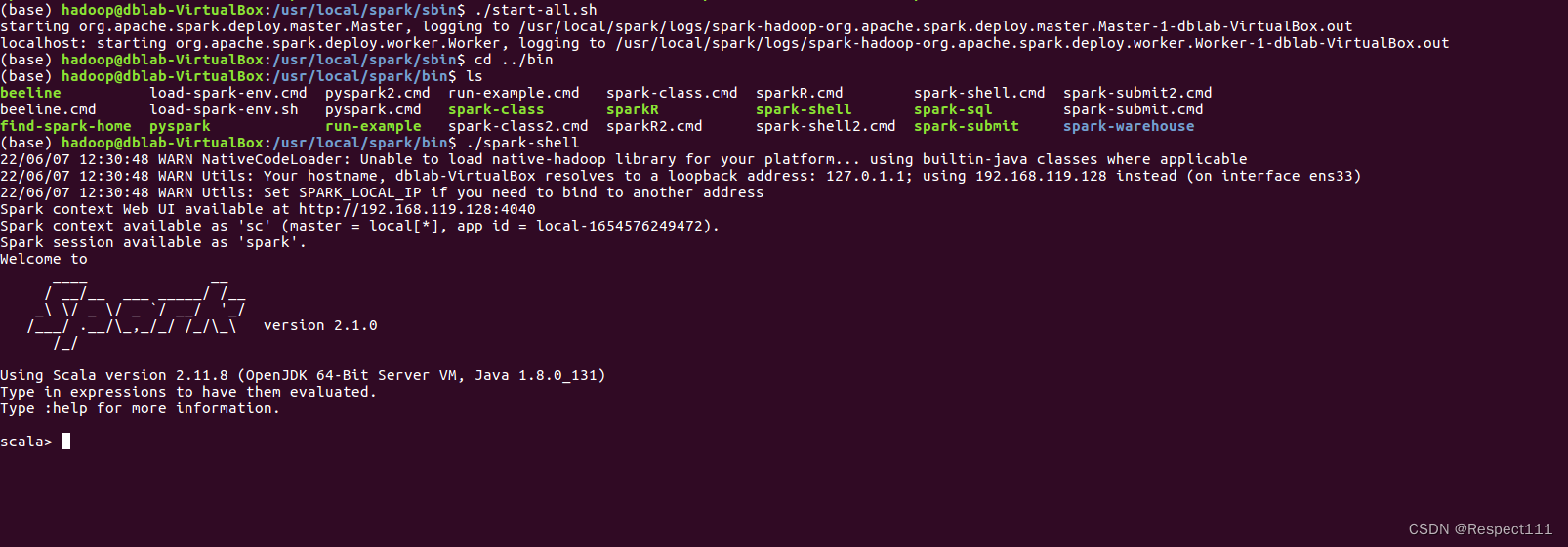
1、首先启动hadoop

2、启动spark shell
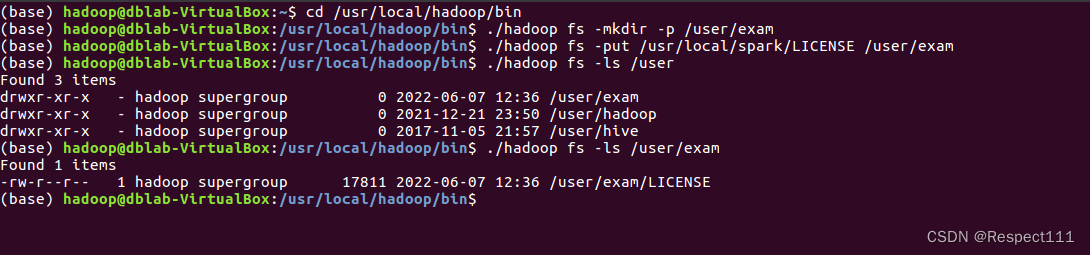
3、 在hdfs中创建多级目录/user/exam
并将/usr/local/spark中的LICENSE上传到hdfs中的user/exam中并检查是否已上传
4、然后继续在spark-shell界面操作
用spark-shell命令读取hdfs中user/exam/LICENSE文件并读取行数(这里网上有一些版本,最后运行了(“hdfs:///)需要三个斜线的是正确的。)
299行

5、 筛选出只包含(BSD)的行并输出行数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









