







采集下拉词数据
闲来无事,采集一下百度下拉数据
1 进行对应的网页分析
下拉数据属于动态的数据,鼠标点击输入框出现,划出输入框消失
所以先找到对应的数据包 就要进行抓包操作
1.1 抓包操作
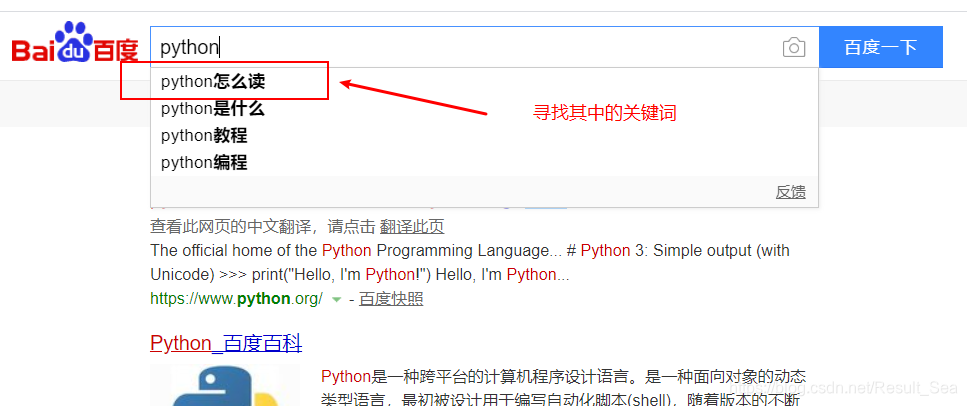
发现其中的关键词,并复制
打开浏览器的开发者模式(快捷键F12)并点击这个搜索按钮
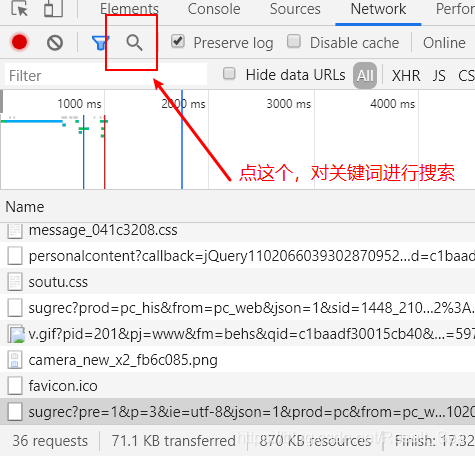
打开这个搜索按钮以后,进行粘贴操作 并且按下回车!
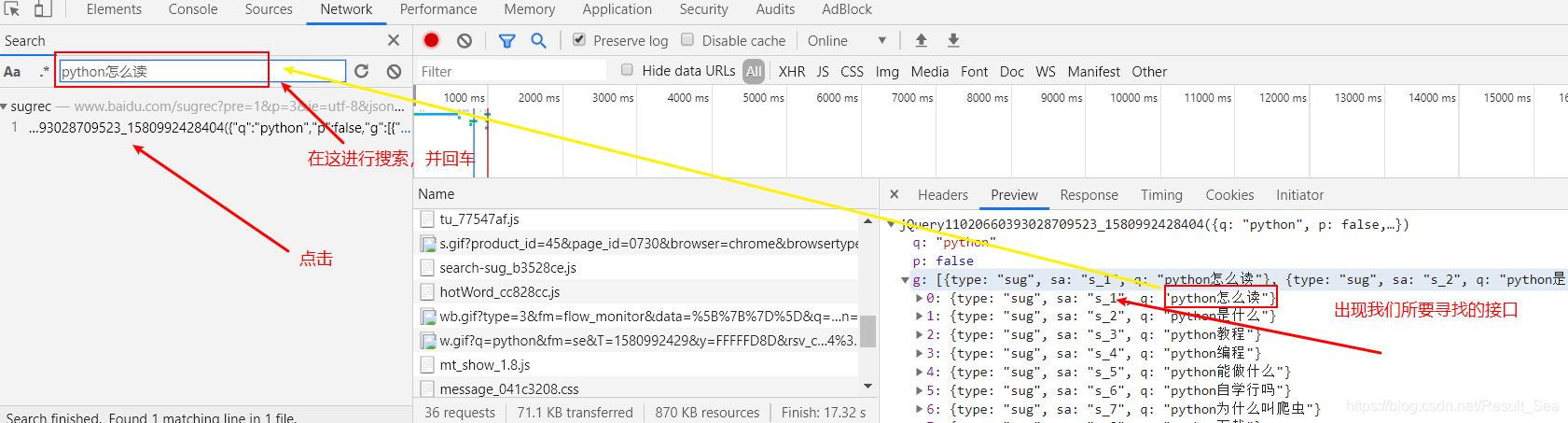
由图可知,只搜索到一个包,在查看这个包内容之前,应该就有90%的把握就是这个包了 点开查看(没错 就是这个包了)
小细节:Preview是渲染之后的结果 Response是写代码请求的结果
接下来我们就上代码
# -*- coding: UTF-8 -*-
import json
import requests
from faker import Faker
def get_aim(file_name):
"""从文件里获取想要的关键词"""
with open(file_name, mode='r', encoding='utf-8') as file:
keys = file.read()
return keys
def aim_letter(aim):
"""获取到网页的json数据并保存到txt文件"""
url = f'https://m.baidu.com/sugrec?pre=1&p=3&ie=utf-8&json=1&prod=wise&from=wise_web&sugsid=128699,138809,114177,135846,141002,138945,140853,141677,138878,137978,141200,140173,131246,132552,137743,138165,107315,138883,140259,141754,140201,138585,141650,138253,140114,136196,140325,140579,133847,140793,140066,134046,131423,137703,110085,127969,140957,141581,140593,140865,139886,138426,138941,141190,140596&net=&os=&sp=null&rm_brand=0&callback=jsonp1&wd{aim}&sugmode=2&lid=12389568409845924354&sugid=1990018821100998871&preqy=java&_=1580993331416'
headers = {
'User-Agent': Faker().user_agent(),
'Host': 'm.baidu.com',
'Referer': 'https://m.baidu.com/ssid=4348023d/s?word={aim}&ts=3254538&t_kt=0&ie=utf-8&rsv_iqid=2845402975&rsv_t=daabpEKSG2wGueEO%252FnXSVz2dj3oGTk5cF1suYK9xduVIBAnyA5yo&sa=ib&rsv_pq=2845402975&rsv_sug4=5130&tj=1&inputT=2405&sugid=1990018821100998871&ss=100'
}
res = requests.get(url, headers=headers)
# 由于获取到的数据不是标准的json数据要进行字符串的删减
result = json.loads(res.text.replace('jsonp1', '').strip('()'))
# 保存到txt文件
with open(f'百度下拉词.txt', mode='a', encoding='utf-8') as file:
for key in result['g']:
file.write(key + '\n')
def main():
"""进行整合,并捕捉错误"""
name = input('请输入文件的名字:')
start_time = time.time()
try:
letter = get_aim(name).split('\n')
# 利用线程池加快爬取速度
with concurrent.futures.ThreadPoolExecutor(max_workers=100) as executor:
for l in letter:
executor.submit(get_data, l)
except:
print('请检查文件名是否存在或者文件名是否错误!!')
else:
# 提示用户完成并打印运行时间时间
print('*' * 30 + f'<{name}> 百度相关词 已完成' + '*' * 30)
finally:
print(time.time() - start_time)
if __name__ == '__main__':
main()
在此 要感谢我的晨哥!!!哈哈

















 4612
4612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









