







一、优雅的断开套接字连接
之前套接字的断开都是单方面的。
(一)基于TCP的半关闭
Linux的close函数和windows的closesocket函数意味着完全断开连接。完全断开不仅不能发送数据,从而也不能接收数据。在某些情况下,通信双方的某一方调用函数完全断开连接就很不优雅。
假设两台主机正在进行双向通信。主机A发完最后的数据,调用close函数断开了连接,之后主机A就无法接收主机B传输的数据。实际上,是完全无法调用与接收数据有关的函数。最终,由主机B传输的、主机A接收的数据也销毁了。
为了解决这种情况,“只关闭一部分数据交换中使用的流“(Half-close)的方法就出来了。断开一部分连接是指,可以传输数据但无法接收,或者可以接收数据但无法传输。
(二)套接字和流
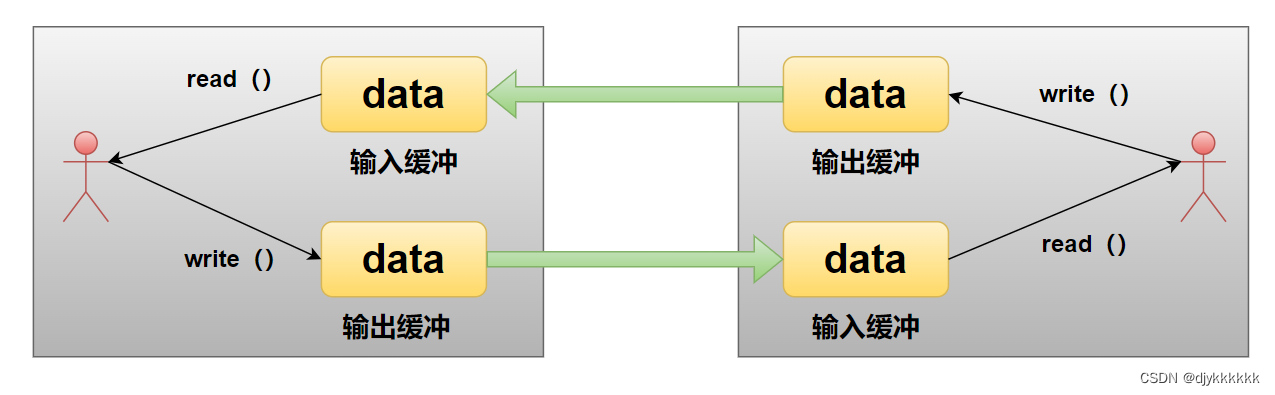
上一部分讨论的,就是断开其中1个流。
(三)shutdown函数
shutdown()函数是用于关闭套接字的函数。它可以选择性地关闭套接字的读取或写入功能,或者同时关闭两者。
函数原型如下:
int shutdown(int sockfd, int how);
参数说明:
sockfd:要关闭的套接字描述符。how:关闭方式,可以取以下值:SHUT_RD:关闭读取功能,即禁止从套接字中读取数据。SHUT_WR:关闭写入功能,即禁止向套接字写入数据。SHUT_RDWR:同时关闭读取和写入功能。
返回值:
- 成功关闭套接字返回0,失败返回-1。
shutdown()函数通常与close()函数一起使用。shutdown()函数用于关闭连接,而close()函数用于释放套接字描述符。关闭连接时,可以根据需要选择关闭读取、写入或两者功能。
示例用法:
#include <sys/socket.h>
// 关闭套接字的读取功能
shutdown(sock, SHUT_RD);
// 关闭套接字的写入功能
shutdown(sock, SHUT_WR);
// 同时关闭套接字的读取和写入功能
shutdown(sock, SHUT_RDWR);
注意事项:
- 调用
shutdown()函数后,套接字无法再进行读取或写入操作,但仍然可以通过close()函数来关闭套接字。 - 如果套接字已经关闭(通过
close()函数),则调用shutdown()函数将产生错误。 shutdown()函数只是关闭套接字的读取或写入功能,并不会真正断开连接。要完全断开连接,需要调用close()函数释放套接字描述符。- 在网络编程中,通常先调用
shutdown()函数关闭套接字的读取或写入功能,然后再调用close()函数关闭套接字。
为何要半关闭?因为close函数调用之后会发送给对方EOF,但此时无法接收到对方发送的数据。所以此时可以调用shutdown函数,只关闭服务器的输出流(半关闭),这样就可以发送EOF,同时保留了输入流,接收对方数据。
(四)基于半关闭的文件传输程序
file_server.cpp
#include <iostream>
#include <fstream>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define BUF_SIZE 1024
void error_handling(const char *message);
int main(int argc, char *argv[])
{
if (argc != 2) {
std::cout << "Usage: " << argv[0] << " <port>" << std::endl;
exit(1);
}
int serv_sock, clnt_sock;
char buffer[BUF_SIZE];
int file_size, total_recv = 0;
struct sockaddr_in serv_adr, clnt_adr;
socklen_t clnt_adr_sz;
serv_sock = socket(AF_INET, SOCK_STREAM, 0);
if (serv_sock == -1)
error_handling("socket() error");
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family = AF_INET;
serv_adr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_adr.sin_port = htons(atoi(argv[1]));
if (bind(serv_sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr)) == -1)
error_handling("bind() error");
if (listen(serv_sock, 5) == -1)
error_handling("listen() error");
clnt_adr_sz = sizeof(clnt_adr);
clnt_sock = accept(serv_sock, (struct sockaddr*)&clnt_adr, &clnt_adr_sz);
if (clnt_sock == -1)
error_handling("accept() error");
std::ifstream file("file.txt", std::ios::binary);
if (!file) {
error_handling("file open() error");
}
// 获取文件大小
file.seekg(0, std::ios::end);
file_size = file.tellg();
file.seekg(0, std::ios::beg);
// 发送文件大小给客户端
write(clnt_sock, &file_size, sizeof(file_size));
// 逐块读取文件内容并发送给客户端
while (!file.eof()) {
file.read(buffer, BUF_SIZE);
int read_bytes = file.gcount();
write(clnt_sock, buffer, read_bytes);
total_recv += read_bytes;
std::cout << "Sent " << total_recv << " bytes" << std::endl;
}
file.close();
close(clnt_sock);
close(serv_sock);
return 0;
}
void error_handling(const char *message)
{
std::cerr << message << std::endl;
exit(1);
}
file_client.cpp
#include <iostream>
#include <fstream>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define BUF_SIZE 1024
void error_handling(const char *message);
int main(int argc, char *argv[])
{
if (argc != 3) {
std::cout << "Usage: " << argv[0] << " <IP> <port>" << std::endl;
exit(1);
}
int sock;
char buffer[BUF_SIZE];
int file_size, total_recv = 0;
struct sockaddr_in serv_adr;
sock = socket(AF_INET, SOCK_STREAM, 0);
if (sock == -1)
error_handling("socket() error");
memset(&serv_adr, 0, sizeof(serv_adr));
serv_adr.sin_family = AF_INET;
serv_adr.sin_addr.s_addr = inet_addr(argv[1]);
serv_adr.sin_port = htons(atoi(argv[2]));
if (connect(sock, (struct sockaddr*)&serv_adr, sizeof(serv_adr)) == -1)
error_handling("connect() error");
// 接收文件大小
read(sock, &file_size, sizeof(file_size));
std::ofstream file("received_file.txt", std::ios::binary);
if (!file) {
error_handling("file open() error");
}
// 接收文件内容并写入本地文件
while (total_recv < file_size) {
int recv_bytes = read(sock, buffer, BUF_SIZE);
total_recv += recv_bytes;
file.write(buffer, recv_bytes);
std::cout << "Received " << total_recv << " bytes" << std::endl;
}
file.close();
close(sock);
return 0;
}
void error_handling(const char *message)
{
std::cerr << message << std::endl;
exit(1);
}
(五)总结
1.解释TCP中”流“的概念。UDP中是否能形成流?请说明原因?
TCP的流是指,两台主机通过套接字建立连接后进入可交换数据的状态,也可称为”流形成的状态“。而对于UDP来说,不存在流,因为两个SOCKET不能相互连接。
2.Linux中的close函数或者windows中的closesocket函数属于单方面断开连接的方法,有可能带来一些问题。什么是单方面断开连接?什么情况下会出现问题?
单方面的断开连接意味着套接字无法再发送数据。一般在对方有剩余数据未发送完成时,断开己方连接,会造成问题。
3.什么是半关闭?针对输出流执行半关闭的主机处于何种状态?半关闭会导致对方主机接收什么信息?
半关闭是指只完成输入和输出流中的一个。而且,如果对输出流进行半关闭,EOF无法被传送到对方主机,己方套接字无法传送数据,但可以接收对方主机传送的数据。
二、域名及网络地址
(一)域名系统
1.什么是域名
域名(Domain Name)是互联网上用于标识和定位网站、服务器或其他网络设备的字符串。它是由一串字符组成,用于代表特定的网络地址。域名的作用是将人们易于记忆的名称转换为计算机网络中的IP地址。因为在互联网上,计算机之间通过IP地址进行通信,而IP地址是一串数字,不方便记忆和使用。通过使用域名,用户可以使用易于记忆的名称来访问网站或进行其他网络操作,而无需记住复杂的IP地址。
2.DNS服务器
DNS(Domain Name System)服务器是负责将域名解析为对应的IP地址的服务器。它是互联网基础设施中非常重要的组成部分,提供了域名到IP地址之间的映射服务。
- 当用户在浏览器中输入一个域名时,例如"www.example.com",浏览器会向本地的DNS服务器发送查询请求,询问该域名对应的IP地址。本地DNS服务器首先查看自己的缓存,如果有该域名的解析结果,则直接返回给浏览器。如果缓存中没有,本地DNS服务器会向根DNS服务器发出请求。
- 根DNS服务器是全球DNS系统的顶级服务器,负责指引查询请求到达下一级的DNS服务器,它并不直接回答查询请求。
- 根DNS服务器会告知本地DNS服务器负责该顶级域名的权威DNS服务器地址,比如".com"顶级域名的权威DNS服务器。本地DNS服务器再向权威DNS服务器发送查询请求。
- 权威DNS服务器是负责管理特定域名区域的服务器,它记录了该域名下所有主机的IP地址。权威DNS服务器将查询结果返回给本地DNS服务器,然后本地DNS服务器将结果缓存,并把查询结果发送给用户的浏览器。
- 用户的浏览器接收到IP地址后,便可以发起与该IP地址对应的服务器的通信,进而访问到对应的网站或服务。
一个域名可以由多个DNS服务器负责解析,这样可以提高系统的可靠性和性能。当一个DNS服务器无法解析时,会尝试向其他可用的DNS服务器进行查询。
总结来说,DNS服务器的主要功能是将域名解析为IP地址,使用户可以使用易于记忆的域名来访问互联网上的各种服务和资源。
(二)IP地址和域名之间的转换
1.利用域名获取IP地址
2.利用IP地址获取域名
三、套接字的多种可选项
(一)套接字可选项和I/O缓冲大小
1.套接字多种可选项
套接字(Socket)是在网络编程中用于实现网络通信的一种抽象概念。它提供了一组可选项(Options),用于配置和控制套接字的行为和属性。以下是几种常见的套接字可选项:
-
SO_REUSEADDR:该选项用于设置套接字地址重用。当一个套接字关闭后,该选项可以使之前绑定的地址立即可用于新的套接字。这对于服务器程序在重启后迅速重新监听同一个端口很有用。
-
SO_KEEPALIVE:该选项用于启用或禁用套接字的保活功能。当启用时,套接字会定期发送心跳消息以检测连接是否仍然有效。如果长时间没有收到对方的响应,则认为连接已断开。
-
SO_SNDBUF和SO_RCVBUF:这两个选项分别设置套接字的发送缓冲区大小和接收缓冲区大小。通过调整缓冲区大小,可以优化数据传输的性能。
-
SO_LINGER:该选项用于设置套接字关闭的行为。当设置SO_LINGER选项并指定一个非零的超时值时,关闭套接字时会等待未发送完的数据发送完毕或超时后再关闭。如果超时值为0,则表示立即关闭套接字,不管是否还有未发送的数据。
-
TCP_NODELAY:该选项用于禁用或启用Nagle算法。当禁用Nagle算法时,套接字将立即发送所有数据,而不会进行数据的合并和延迟发送。
这只是一些常见的套接字可选项,实际上还有更多可选项可以用于配置和控制套接字的行为。具体可选项的使用方法和效果可以参考相关编程语言的文档或网络编程库的文档。
2.getsockopt & setsockopt
getsockopt和setsockopt是用于获取和设置套接字选项(socket options)的函数。这两个函数通常在网络编程中使用,用于配置和控制套接字的各种属性和行为。
getsockopt函数用于获取套接字选项的当前值。它的原型如下:
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
其中,sockfd是套接字描述符,level表示选项的协议层,optname表示具体的选项名称,optval是一个指向存放选项值的缓冲区的指针,optlen是optval的大小。
setsockopt函数用于设置套接字选项的值。它的原型如下:
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
参数含义与getsockopt类似。不同之处在于,optval是一个指向包含要设置的选项值的缓冲区的指针,optlen表示optval的大小。
通过调用getsockopt和setsockopt函数,可以对套接字进行各种配置。例如,可以设置套接字的超时时间、缓冲区大小、重用地址选项等。具体可用的选项名称和取值范围取决于所使用的套接字库和操作系统。
需要注意的是,不同的编程语言和套接字库可能提供了不同的接口和函数名称,但基本的功能是相似的。因此,在具体的编程环境中,可以查阅相关文档以了解如何使用getsockopt和setsockopt函数进行套接字选项的获取和设置操作。
3.SO_SNDBUF & SO_RCVBUF
SO_SNDBUF和SO_RCVBUF是用于设置套接字发送缓冲区大小和接收缓冲区大小的选项。
SO_SNDBUF选项用于设置套接字的发送缓冲区大小,即发送数据时套接字可以暂存的最大数据量。该选项可以影响发送数据的性能和吞吐量。较大的发送缓冲区可以容纳更多的待发送数据,减少了频繁的发送调用,提高了发送效率。但是,过大的发送缓冲区也可能会增加内存消耗。
设置SO_SNDBUF选项需要调用setsockopt函数,并指定level为SOL_SOCKET,optname为SO_SNDBUF。示例代码如下(使用C语言):
int send_buffer_size = 8192; // 设置发送缓冲区大小为8192字节
setsockopt(sockfd, SOL_SOCKET, SO_SNDBUF, &send_buffer_size, sizeof(send_buffer_size));
SO_RCVBUF选项用于设置套接字的接收缓冲区大小,即接收数据时套接字可以暂存的最大数据量。该选项可以影响接收数据的性能和吞吐量。较大的接收缓冲区可以容纳更多的接收数据,减少了频繁的接收调用,提高了接收效率。但是,过大的接收缓冲区也可能会增加内存消耗。
设置SO_RCVBUF选项需要调用setsockopt函数,并指定level为SOL_SOCKET,optname为SO_RCVBUF。示例代码如下(使用C语言):
int recv_buffer_size = 8192; // 设置接收缓冲区大小为8192字节
setsockopt(sockfd, SOL_SOCKET, SO_RCVBUF, &recv_buffer_size, sizeof(recv_buffer_size));
值得注意的是,实际的缓冲区大小可能会受到操作系统和套接字库的限制。在设置缓冲区大小时,应该遵循合理的范围,根据应用程序的需求和系统资源进行调整。需要同时设置发送和接收缓冲区大小时,可以分别调用setsockopt函数进行设置。
(二)SO_REUSEADDR
1.发生地址分配错误(Binding Error)
当尝试在套接字上绑定地址时,可能会发生地址分配错误(Binding Error)。这种错误通常意味着操作系统无法将所请求的地址分配给套接字。
地址分配错误可能有多种原因,以下是一些常见的情况:
-
地址已被占用:如果所请求的地址已经被其他套接字或进程占用,那么绑定操作将失败并返回地址分配错误。这可能是由于同一地址和端口已经被另一个套接字绑定,或者是由于程序在之前运行中没有正确释放该地址。
-
权限不足:如果当前用户没有足够的权限来绑定所请求的地址,那么将会发生地址分配错误。在某些操作系统中,只有超级用户(root用户)才有权利绑定低于1024的特殊端口号。
-
防火墙设置:防火墙或安全策略可能会限制对某些地址或端口的访问,从而导致无法进行绑定操作。请确保防火墙配置允许所需的地址和端口的访问。
-
地址格式错误:如果提供的地址格式不正确或无效,绑定操作将失败并引发地址分配错误。请确保使用正确的地址格式,并正确地解析主机名或IP地址。
处理地址分配错误的方法可能因情况而异:
- 可以尝试更换地址和端口号,确保它们是可用且未被其他进程占用的。
- 确保程序在使用完套接字后正确地关闭并释放相关资源,这样可以避免出现地址被锁定或无法再次绑定的情况。
- 检查权限设置并确保当前用户具有足够的权限来进行绑定操作。
- 检查防火墙和网络安全策略,并相应地配置以允许所需的地址和端口的访问。
如果问题仍然存在,可能需要根据具体的错误消息和环境进行更详细的故障排除和调试。
2.Time-wait 状态
TIME_WAIT状态是TCP协议中的一个状态,它在连接关闭后仍然存在一段时间。当TCP连接的一方主动关闭连接时,会进入TIME_WAIT状态,以确保在网络上所有的数据都能完全传输完成。
在TIME_WAIT状态下,套接字不能立即重新使用相同的本地地址和端口号来建立新的连接。这是为了防止旧的重复分节被误认为是新的连接的分节。通常,TIME_WAIT状态的持续时间为2倍的MSL(Maximum Segment Lifetime)。
TIME_WAIT状态的作用有以下几个方面:
-
确保可靠性:TIME_WAIT状态可以确保在网络中的所有分节都被正确发送和接收。这样可以避免旧的分节被误认为是新的连接的分节。
-
允许延迟分节到达:在TIME_WAIT状态下,如果对方还有未处理的分节,它们可以继续到达并被正确处理。
-
允许最后的ACK分节到达:在TIME_WAIT状态下,对方可能会重新发送ACK分节,以确保连接的正常关闭。
需要注意的是,TIME_WAIT状态可能会对系统资源产生一定的负担。如果程序频繁地打开和关闭连接,则可能耗尽可用的本地端口号。在某些情况下,可以通过设置SO_REUSEADDR选项来允许立即重用处于TIME_WAIT状态的地址,以便更快地重新建立连接。
对于开发者来说,应注意以下几点:
- 避免频繁关闭和重新打开连接,尽量重用现有的连接。
- 在程序设计中,合理设置连接的生命周期,避免不必要的TIME_WAIT状态的产生。
- 理解并适当处理TIME_WAIT状态带来的影响,例如通过调整操作系统的相关参数或使用SO_REUSEADDR选项。
3.地址再分配
地址再分配是指在网络编程中,将一个已经使用过的地址重新分配给另一个套接字使用。
通常情况下,当一个套接字关闭后,其所使用的本地地址会进入TIME_WAIT状态一段时间。在这个时间内,该地址无法立即被其他套接字重新使用。这是为了确保之前的连接的所有数据都能够完全传输完成,并防止新的连接误认为是旧连接的分节。
然而,在某些情况下,可能需要在TIME_WAIT状态结束之前能够立即重新分配相同的本地地址。这时可以使用SO_REUSEADDR选项来实现地址再分配。
设置SO_REUSEADDR选项后,处于TIME_WAIT状态的套接字地址就可以立即被其他套接字绑定和使用。这对于服务器程序在重启后快速重新监听同一个端口非常有用。
以下是使用C++示例代码来设置SO_REUSEADDR选项进行地址再分配:
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
// 设置SO_REUSEADDR选项
int reuseaddr = 1;
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &reuseaddr, sizeof(reuseaddr));
// 绑定地址和端口
// ...
return 0;
}
请注意,虽然SO_REUSEADDR选项可以允许地址再分配,但仍需注意以下几点:
- 在设置SO_REUSEADDR选项之前,确保套接字已经创建。
- 使用SO_REUSEADDR选项时,应谨慎处理连接的生命周期,以避免出现意外的连接复用。
- 还可能需要根据操作系统和网络环境的不同,对其他参数或选项进行适当的调整,以实现完全的地址再分配。
总而言之,地址再分配可以通过设置SO_REUSEADDR选项来实现,在合适的情况下,可以提高程序的效率和可用性。但在使用时仍需谨慎考虑与设计,并确保正确处理套接字的生命周期。
(三)TCP_NODELAY
1.Nagle算法
Nagle算法是一种用于减少小数据包传输的网络优化算法。它在TCP协议中起作用,旨在减少网络拥塞和提高网络性能。
Nagle算法的原理如下:
- 当发送应用程序有小量数据需要发送时,Nagle算法会将这些数据收集到一个缓冲区中,并等待一定时间(通常是200毫秒)。
- 如果在等待时间内,发送应用程序有更多的数据要发送,那么这些数据会被追加到之前的数据后面。
- 在等待时间结束后,Nagle算法会将缓冲区中的数据封装成一个TCP分节并发送出去。
Nagle算法的目的是在发送方尽可能地减少小数据包的数量,以避免网络中的拥塞。通过将小数据包合并成较大的数据块进行传输,可以有效地利用网络带宽,降低网络延迟,提高传输效率。
然而,Nagle算法也存在一定的副作用。由于需要等待一定时间或者达到一定的数据量才进行发送,这会导致一些交互式应用程序的延迟增加。特别是对于需要实时响应的场景(如实时游戏、语音/视频通话等),Nagle算法可能不适合,因为它会引入一定的传输延迟。
在实际的网络编程中,可以通过设置TCP_NODELAY选项来启用或禁用Nagle算法。禁用Nagle算法后,数据将立即发送,适用于对实时性要求较高的应用程序。例如,在C++中使用setsockopt函数可以设置TCP_NODELAY选项:
int flag = 1;
setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, (char*)&flag, sizeof(int));
总的来说,Nagle算法是一种优化网络传输的算法,在某些场景下可以提高网络性能,但在对实时性要求较高的应用程序中需要谨慎使用。
2.禁用Nagle算法
要禁用Nagle算法,以便立即发送小数据包而不等待缓冲区填满或超时等待时间,可以通过设置TCP_NODELAY选项来实现。禁用Nagle算法后,数据将立即发送,适用于对实时性要求较高的应用程序。
在网络编程中,可以通过以下示例代码使用setsockopt函数来禁用Nagle算法(使用C++语言):
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/tcp.h>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
// 禁用Nagle算法
int flag = 1;
setsockopt(sockfd, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(flag));
// 进行其他操作...
return 0;
}
上述代码中,通过设置TCP_NODELAY选项为1来禁用Nagle算法。这样,套接字上的数据将立即发送,而不需要等待缓冲区填满或超时等待时间。
需要注意的是,禁用Nagle算法可能会导致网络拥塞和传输效率降低,因此在选择是否禁用Nagle算法时需要根据具体的应用场景进行权衡和考量。对于对实时性要求较高的应用程序,禁用Nagle算法可能是一个合理的选择;而对于需要减少小数据包传输的应用程序,则可能需要启用Nagle算法以减少网络拥塞。
正确使用Nagle算法或禁用Nagle算法需要根据具体的需求和网络环境进行评估,并根据实际情况进行适当的配置。














 3292
3292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









