







Go_Learning_1_常用集合
文章目录
0. 数组
0.0 声明
var a [3]int
a[0] = 1 //声明并初始化为默认零值
b := [3]int{1,2,3} //声明同时初始化
c := [2][2]int{{1,2}, {3,4}} //二维数组
func TestArrayInit(t *testing.T) {
var arr [3]int //默认为0
arr1 := [4]int{1, 2, 3, 4}
arr2 := [...]int{1, 2, 3, 4, 5} //推断长度
t.Log(arr[1], arr[2])
t.Log(arr1, arr2)
}
0.1 遍历
// for
func TestArrayTravel(t *testing.T) {
arr2 := [...]int{1, 2, 3, 4, 5}
for i := 0; i < len(arr2); i++ {
t.Log(arr2[i])
}
}
// 增强for idx是索引,e是元素值
func TestArrayTravelPlus(t *testing.T) {
arr2 := [...]int{1, 2, 3, 4, 5}
for idx, e := range arr2 {
t.Log(idx, e)
}
}
// 如果不用idx 常用_占位
for _, i := range arr2 {
t.Log(i)
}
0.2 数组截取
a[开始索引(包含), 结束索引(不包含)]
a := [...]int{1,2,3,4,5}
a[1:2] //2
a[1:3] //2,3
a[1:len(a)] //2,3,4,5
a[1:] //2,3,4,5
a[:3] //1,2,3
func TestArraySection(t *testing.T) {
arr2 := [...]int{1, 2, 3, 4, 5}
arr2Sec := arr2[:3]
// arr2sec2 := arr2[-1:] 不支持负数
t.Log(arr2Sec)
}
注意:数组如果被截取,那么新生成的就是切片
func TestArrayToSlice(t *testing.T) {
var arr = [...]int{1,2,3,4,5}
var b = arr[1:3]
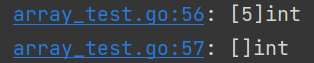
t.Log(reflect.TypeOf(arr))
t.Log(reflect.TypeOf(b))
}
1. 切片
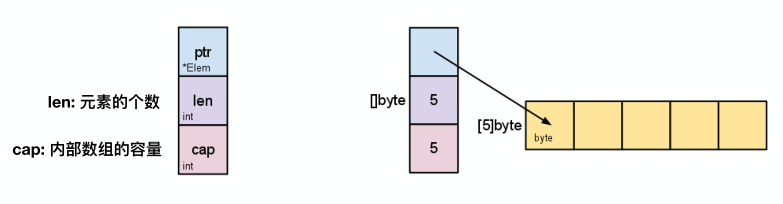
1.0 切片内部结构
类似一个结构体,第一个放数组的地址,第二个放元素的个数,第三个是内部数组的容量
1.1 切片声明
和数组的声明很类似,不同点是[]中不写内容
var s0 []int
s0 = append(s0, 1)
s1 := []int
s2 := []int{1,2,3}
s3 := make([]int, 2, 4) //cap是4,只初始化len=2长度的元素,未初始化元素不可访问
1.2 切片共享存储结构

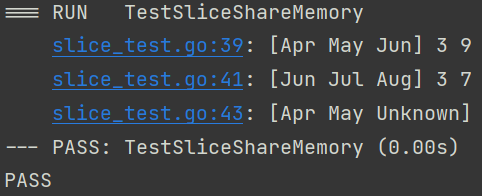
func TestSliceShareMemory(t *testing.T) {
year := []string{"", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}
Q2 := year[4:7]
t.Log(Q2, len(Q2), cap(Q2))
summer := year[6:9]
t.Log(summer, len(summer), cap(summer))
summer[0] = "Unknown" //修改summer
t.Log(Q2) //Q2的值被修改,说明共享存储空间,拿到的数据同一份
}
1.3 扩容机制
func TestSliceGrowing(t *testing.T) {
var s []int
for i := 0; i < 10; i++ {
s = append(s, i)
t.Log(len(s), cap(s))
}
}
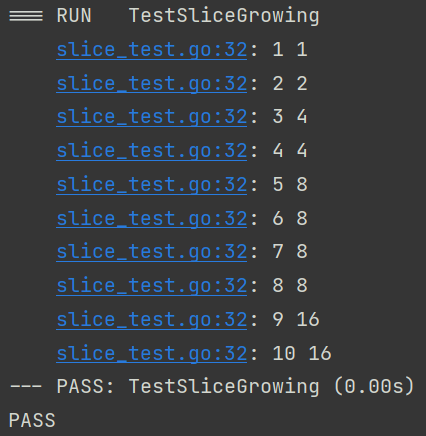
观察cap的变化
为什么是
s = append(s, i)而不是append(s, i)?因为每次的扩容是将原切片进行拷贝到一个新的切片中,不再指向原有的空间
因此如果想通过共享内存达到数据同步要小心
如上图,如果每次扩容都是增长一倍,是否内存成本过高?是否有增长因子的机制
求证:
func TestSliceGrowing(t *testing.T) {
var s []int
for i := 0; i < 1500; i++ {
t.Log(i, len(s), cap(s)) //1 2 4 8...512 1024 1280 1696
s = append(s, 1)
}
}
容量增长情况为:1 2 4 8…512 1024 1280 1696
可以看出cap规则
if len<=1024
cap×2
if len > 1024
cap = cap ×(1+1/4)
欣赏一下源码$GOROOT/src/runtime/slice.go
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
1.4 数组与切片不同
- 是否可扩容
- 数组不可扩容
- 切片可扩容
- 是否可比较
- 数组比较根据元素个数,维数,每个元素切顺序都相同被认为是相同数组
- 切片只能跟nil进行比较,无法两个切片进行比较
2. Map
2.0 声明
m := map[string]int{"one":1, "two":2, "three":3}
m1 := map[string]int{}
m1["one"] = 1 //添加
m2 := make(map[string]int, 10 ) // 10是Capacity
如果确定了需要的容量就可以直接申请够用的内存空间,而不用自动增长,每次的自动增长都会进行复制,所以直接申请能减少资源的消耗
func TestMapInit(t *testing.T) {
m1 := map[int]int{1:1, 2:4, 3:9}
t.Log(m1[2])
t.Logf("len m1 = %d", len(m1))
m2 := map[int]int{}
m2[4] = 16
t.Logf("len m2 = %d", len(m2))
m3 := make(map[int]int, 10)
t.Logf("len m3 = %d", len(m3))
// t.Logf("cap m3 = %d", cap(m3)) //cap不能用于查看map
}
2.1 元素访问
- 访问的key不存在时,仍然会返回零值,不能通过返回nil来判断元素是否存在
func TestAccessElem(t *testing.T) {
m := map[int]int{}
t.Log(m[2]) // key不存在 输出-> 0
m[2] = 0
t.Log(m[2]) // key存在value是0 -> 0
v, ok := m[4]
t.Log(v, ok) // 0 false -> v返回零值,false表示key不存在
//可以通过如下方法来判断key是否存在
if v, ok := m[4]; ok {
t.Logf("The value is %d", v)
} else {
t.Log("Not existing")
}
}
2.2 遍历
用增强for循环,第一个返回值是key,第二个返回值是value
func TestMapTravel(t *testing.T) {
m := map[string]int{"one": 1, "two": 2, "three": 3}
for k, v := range m {
t.Logf("key = %s, value = %d", k, v)
}
}
------------------------------------------
=== RUN TestMapTravel
map_test.go:39: key = one, value = 1
map_test.go:39: key = two, value = 2
map_test.go:39: key = three, value = 3
--- PASS: TestMapTravel (0.00s)
PASS
但注意,map底层是hash表机制,是无序的,所以遍历出的顺序可能不按放入顺序
2.3 Map与工厂模式
- Map的value可以是一个方法
func TestMapWithFunValue(t *testing.T) {
m := map[int]func(op int) int{} // 定义一个返回值是func的map集合
m[1] = func(op int) int { return op }
m[2] = func(op int) int { return op * op }
m[3] = func(op int) int { return op * op * op }
t.Log(m[1](2), m[2](2), m[3](2))
}
-------------------------------------
=== RUN TestMapWithFunValue
map_test.go:54: 2 4 8
--- PASS: TestMapWithFunValue (0.00s)
PASS
- 与Go的Duck type接口方式一起,可以实现单一方法对象的工厂模式
Duck type:
俚语:如果一个东西像鸭子一样走路和呱呱叫,那么他可以看成是一个鸭子
计算机领域中,duck typing对应的是normal typing(对象的类型决定了对象的特性),duck typing中对象的类型不重要,只要对象有类型A的方法和属性,那它就可被当作类型A来使用
所以,在Go中,对象拥有某个接口定义的方法,就可以当作那个接口类型的实例来使用,不需要显式的声明
2.4 Map实现Set
Go内置集合中没有实现Set,可以map[type]bool
-
元素的唯一性
-
基本操作
- 添加元素
- 判断元素是否存在
- 删除元素
- 元素个数
func TestMapForSet(t *testing.T) {
mySet := map[int]bool{}
mySet[1] = true // 添加元素
mySet[2] = true
n := 1
if mySet[n] {
t.Logf("%d is existing", n)
} else {
t.Logf("%d is not existing", n)
}
t.Log(len(mySet)) // 获取独立元素个数
delete(mySet,1) // 删除元素
if mySet[n] {
t.Logf("%d is existing", n)
} else {
t.Logf("%d is not existing", n)
}
}
-------------------------------------
=== RUN TestMapForSet
map_test.go:57: 1 is existing
map_test.go:61: 2
map_test.go:66: 1 is not existing
--- PASS: TestMapForSet (0.00s)
PASS
3. 字符串
- string是数据类型,不是引用或者指针类型
- string是只读的byte slice,len函数可以拿到它所包含的byte数
- string的byte数组可以存放任何数据
3.0 Unicode和UTF-8
- Unicode是一种字符集(code point)
- UTF-8是Unicode的存储实现(转换成字节序列的规则)
func TestString(t *testing.T) {
var s string
t.Log(s) // 初始化是默认零值""
s = "hello"
t.Log(len(s))
// s[1] = '3' //string是不可变的byte slice
s = "\xE8\xB1\xAA" //可以存储任何二进制数据
t.Log(s)
t.Log(len(s)) //len(s)拿到的是byte个数 -> 3
s = "贾"
t.Logf("%x", s) // 贾的utf-8 hex编码->e8b4be
c := []rune(s)
t.Log(len(c))
// unsafe.Sizeof()查看该变量在内存中占几个字节
t.Log("rune size: ", unsafe.Sizeof(c)) // 3个8位二进制 -> 24
t.Logf("贾 Unicode %x", c[0]) // 8d3e
}
---------------------------------
=== RUN TestString
string_test.go:15:
string_test.go:17: 5
string_test.go:20: 豪
string_test.go:21: 3
string_test.go:23: e8b4be
string_test.go:26: 1
string_test.go:27: rune size: 24
string_test.go:28: 贾 Unicode 8d3e
--- PASS: TestString (0.00s)
PASS
有关编码相关参考:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
| 字符 | “贾” |
|---|---|
| Unicode | 0x8D3E |
| UTF-8 | 0xE8B4BE |
| string/[]byte | [0xE8,0xB4,0xBE] |
func TestStringToRune(t *testing.T) {
s := "中华人民共和国"
for _,c := range s{
t.Logf("%[1]c %[1]d", c) // %[1]c %[1]d 都用第一个参数进行c和d进行格式化
}
}
--------------------------------
=== RUN TestStringToRune
string_test.go:34: 中 20013
string_test.go:34: 华 21326
string_test.go:34: 人 20154
string_test.go:34: 民 27665
string_test.go:34: 共 20849
string_test.go:34: 和 21644
string_test.go:34: 国 22269
--- PASS: TestStringToRune (0.00s)
PASS
3.1 常用方法
func TestStringFun(t *testing.T) {
str := "J,R,H"
parts := strings.Split(str, ",")
for _, part := range parts {
t.Log(part)
}
t.Log(strings.Join(parts, "-"))
}
--------------------------
=== RUN TestStringFun
string_fun_test.go:18: J
string_fun_test.go:18: R
string_fun_test.go:18: H
string_fun_test.go:20: J-R-H
--- PASS: TestStringFun (0.00s)
PASS
3.2 类型转换
func TestConv(t *testing.T) {
s := strconv.Itoa(10) // Itoa int to ascii
t.Log("str:", s)
str := "404230"
if i, err := strconv.Atoi(str); err == nil { //Atoi ascii to int,返回两个参数
t.Logf("%[1]T, %[1]d", i)
}
}
--------------------------
=== RUN TestConv
string_fun_test.go:25: str: 10
string_fun_test.go:28: int, 404230
--- PASS: TestConv (0.00s)
PASS















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









