







今天一位小伙伴问我关于SQL查询效率以及索引的东西。
我说只要尽量命中索引即可。特别是聚集索引。思前想后,好像总有什么不对!
于是又做了一番资料查询,发现索引不是那么简单,即使是命中索引也是没那么简单。
突然有些感慨,当个DBA不容易啊。
1.复合索引
先说说复合索引,相信大家都知道。两个或更多列上的索引就被称作复合索引。
最近在做某酒店的项目。拿这个举个例子:
Order表名,
其中包含列:GuestSrcCode(客源代码),HotelID(酒店编号)
tips:客源代码只有几种情况(散客,会员,中介,团队),酒店编号有很多
a.列顺序
在创建复合索引时,顺序是需要仔细斟酌的。
在创建复合索引时,顺序是需要仔细斟酌的。
a.1:当创建一个客源代码--酒店编号的索引时
create index non_clu_GuestSrcAndHotelID on [order] (GuestSrcCode,HotelID)
我们查询如下sql
这里我们尽量将查询少量的数据(避免书签查找)
,便于看出列顺序的问题
sql1: select * from [Order] where GuestSrcCode='GS04'
执行计划如下:
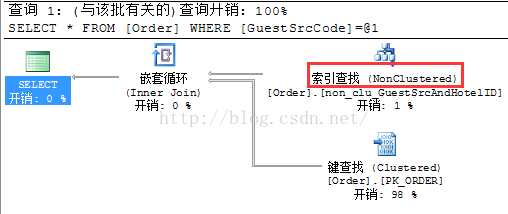
sql2: select * from [Order] where HotelID='023023'
执行计划如下:
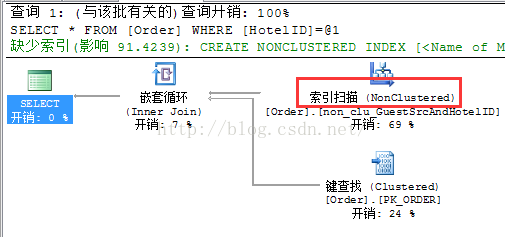
可以看到当条件只有HotelID时,没有用到上面我们建的索引。
a.1:当创建一个酒店编号--客源代码的索引时(反过来)
sql1: select * from [Order] where GuestSrcCode='GS04'
执行计划如下:
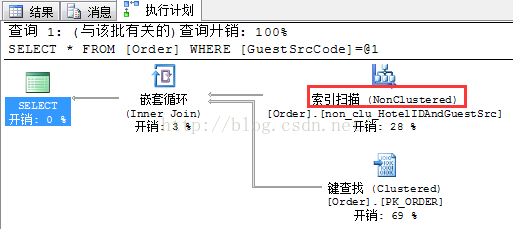
sql2: select * from [Order] where HotelID='023023'
执行计划如下:
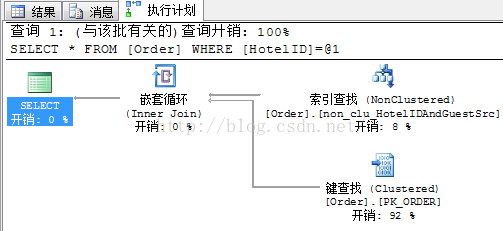
可以看到当条件只有
GuestSrcCode时,没有用到上面我们建的索引。
同样的例子做过好多,结果大概了解了。
列顺序总结:
创建复合索引时,主要是看第一列的,比如abc和acb是效果是差不多的。
如何看出将哪一个用作第一列。。。你就把这第一列当成单索引建立好了。。。
b.书签查找
很多时间我们会发现,咱们条件里使用了某索引,但是查看执行计划,还是使用的是聚集索引扫描。。。。
这时候一般都是发生的书签查找。
当在索引统计信息(索引表中)中发现
查找的数据的很多时,
Sql查询优化器就会放弃使用该索引,而去使用聚集索引扫描。
这时候可以使用覆盖索引来避免。
eg
: create index non_clu_GuestSrcAndHotelID on [order] (GuestSrcCode,HotelID)
include(ContactName)
--一般查询订单会同时将联系人查询出来















 2682
2682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









