







Linux 性能工具把观察到的性能问题跟系统原理关联起来,特别是把系统从应用程序、库函数、系统调用、再到内核和硬件等不同的层级贯穿起来。
这些问题或场景。
1·流量高峰期,服务器 CPU 使用率过高报警,登录 Linux 上去 top 完,进一步定位,是系统 CPU 资源太少,或者程序并发部分有问题。
\2. 系统没有跑吃内存的程序, free 命令之后,发现系统没有内存了,哪里占用了内存。
\3. 收到 Zabbix 告警发现某台存放监控数据的数据库主机的 iowait 较高。
主要是因为性能优化是个系统工程,总是牵一发而动全身。它涉及了从程序设计、算法分析、编程语言,再到系统、存储、网络等各种底层基础设施的方方面面。每一个组件都有可能出问题,而且很有可能多个组件同时出问题。
从资源使用的视角出发,分析各种 Linux 资源可能会碰到的性能问题,包括 CPU 性能、磁盘 I/O 性能、内存性能以及网络性能。
性能优化的第一步,了解“性能指标”这个概念。
性能优化的两个核心指标——“吞吐”和“延时”。这两个指标是从应用负载的视角来考察性能,直接影响了产品终端的用户体验。跟它们对应的,是从系统资源的视角出发的指标,比如资源使用率、饱和度等。
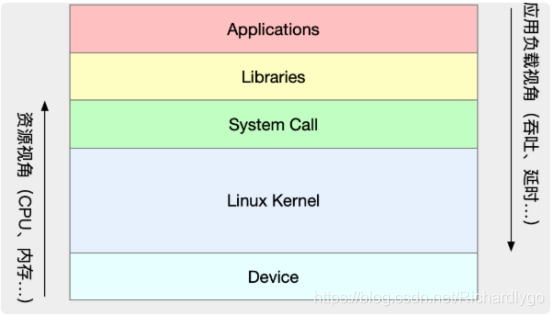
随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。而性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
找出应用或系统的瓶颈,并设法去避免或者缓解它们,从而更高效地利用系统资源处理更多的请求。
选择指标评估应用程序和系统的性能;
为应用程序和系统设置性能目标;
进行性能基准测试;
性能分析定位瓶颈;
优化系统和应用程序;
性能监控和警
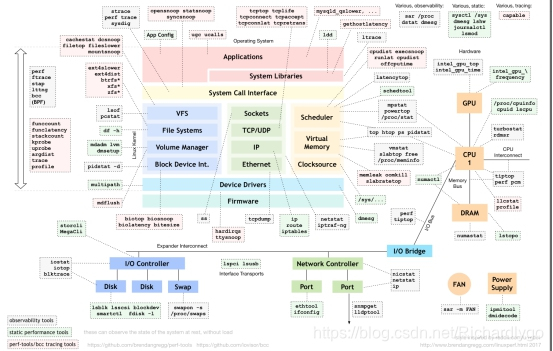
图是 Linux 性能分析最重要的参考资料之一,在 Linux 不同子系统出现性能问题后,应该用什么样的工具来观测和分析。
有监控的情况下,首先去监控大盘,有没有异常报警,如果初期还没有监控的情况按照下面步骤去系统层面有没有异常 1、系统的平均负载,使用top或者htop命令查看,平均负载体现的是系统的一个整体情况应该是cpu、内存、磁盘性能的一个综合,一般是平均负载的值大于机器cpu的核数,说明机器资源已经紧张了 2、平均负载高了以后,在top中看cpu每个核的使用情况,如果占比很高,瓶颈是cpu,什么进程导致的 3、如果cpu没有问题,看内存,用free去查看内存的是用情况,但不直接看他剩余了多少,还要结合看看cache和buffer,然后再具体是什么进程占用了过高的内存,是用top去排序 4、内存没有问题的话就要去看磁盘了,磁盘iostat去查看 5、还有就是带宽问题,一般会用iftop去查看流量情况,流量是否超过的机器给定的带宽 6、涉及到具体应用的话,就要根据具体应用的设定参数来查看,比如连接数是否查过设定值等 7、如果系统层各个指标查下来都没有发现异常,那么就要考虑外部系统了,比如数据库、缓存、存储等
发现系统变慢时,执行 top 或者 uptime 命令,来了解系统的负载情况
uptime
12:07:36 up 5 days, 19:35, 2 users, load average: 0.10, 0.10, 0.09
//当前时间up 5 days, 19:35 //系统运行时间1 user //正在登录用户数 1分钟5分钟15分钟平均负载(Load Average)。
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。
可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
平均负载最理想的情况是等于 CPU 个数。在评判平均负载时,要知道系统有几个 CPU,这可以通过 top 命令或者从文件 /proc/cpuinfo 中读取
grep 'model name' /proc/cpuinfo | wc -l
有了 CPU 个数,可以判断出,当平均负载比 CPU 个数还大的时候,系统已经出现了过载。
三个不同时间间隔的平均值,分析系统负载趋势的数据来源,能更全面、更立体地理解目前的负载状况。
当平均负载高于 CPU 数量 70% 的时候,分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
*平均负载与 CPU 使用率*
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
以三个示例分别来看这三种情况,并用 iostat、mpstat、pidstat 等工具,找出平均负载升高的根源。预先安装 stress 和 sysstat 包,如 apt install stress sysstat。
mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
每个场景都需要开三个终端,登录到同一台 Linux 机器中。默认以 root 用户运行。
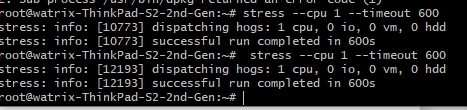
*场景一:CPU 密集型进程*
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









