






 本文深入探讨MapReduce框架下的Combiner和Partitioner组件应用,通过具体案例解析如何优化数据处理流程,减少网络传输负担,提升程序执行效率。
本文深入探讨MapReduce框架下的Combiner和Partitioner组件应用,通过具体案例解析如何优化数据处理流程,减少网络传输负担,提升程序执行效率。
文章目录
1. Combiner概述
假设有如下场景:
如果有10亿的数据,Mapper会生成一个10亿的key/value键值对在网络间进行传输,但如果我们的需求是求数据的最大值,则只需要Mapper输出它的最大值即可,这样做不仅可以减轻网络压力,同样可以大幅度的提升程序效率。
在MapReducer框架中,Combiner就是为了 避免map任务和reduce任务之间的数据传输而设置的,Hadoop允许用户针对map task的输出指定一个合并函数。即为了减少传输到Reduce中的数据量。主要是为了消减Mapper的输出数量,从而减少网络带宽和Reducer上的负载。我们可以把Combiner操作看成是一个在每个单独的节点上先做一次Reducer操作,其输入及输出的参数和Reducer是一样的。
2. Combiner的应用
2.1 Combiner的执行过程
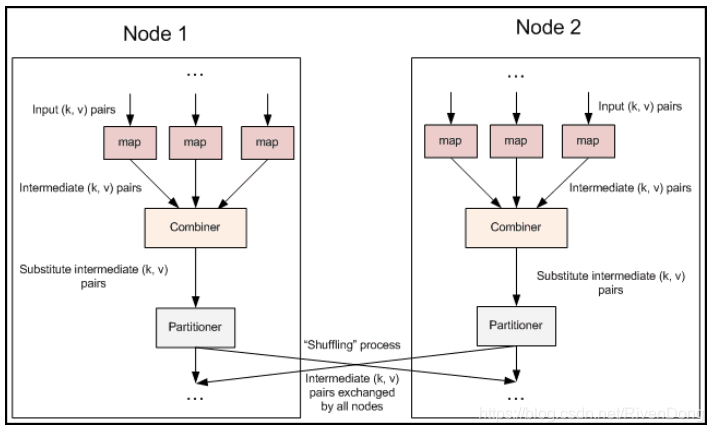
我们可以在Map输出之后添加一步Combiner操作,先进行一次聚合,再由Reduce来处理,进而使得传输的数据减少,提高执行效率。
2.2 执行代码
package com.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class WordCountCombinerApp {
private static final String INPUT_PATH = "hdfs://master001:9000/wordcount.txt";
private static final String OUTPUT_PATH = "hdfs://master001:9000/output1";
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String[] strs = value.toString().split(" "); // 将字符串按空格进行划分
for(int i=0;i<strs.length;i++){
context.write(new Text(strs[i]), one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value: values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
//提升代码的健壮性
final FileSystem fileSystem = FileSystem.get(URI.create(INPUT_PATH), conf);
if(fileSystem.exists(new Path(OUTPUT_PATH))){
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "WordCount");
//run jar class 主方法
job.setJarByClass(WordCountCombinerApp.class);
//设置map
job.setMapperClass(TokenizerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Combiner处理类,其逻辑是可以直接使用Reducer
job.setCombinerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置input format
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
//设置output format
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
//提交job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
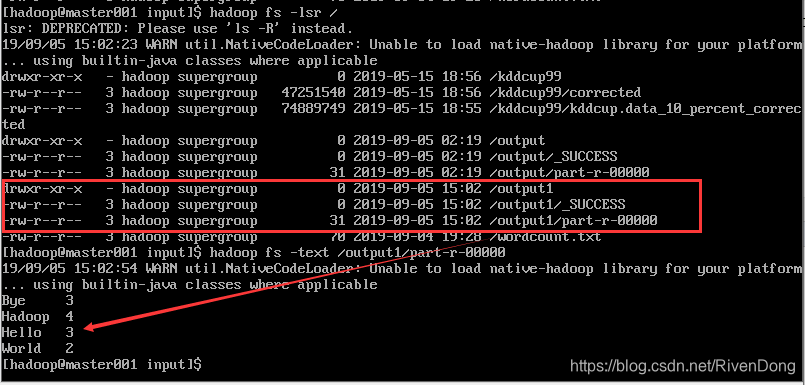
2.3 效果截图
3. Partitioner概述
在计算时,有时需要把最终的输出数据分到不同的文件中,由于我们知道最终的输出数据是来自于Reducer任务,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。然而Reducer的数据来自于Mapper任务,换句话说Mapper是要进行数据划分的,对于不同的数据分配给不同的Reducer任务,Mapper任务划分数据的过程叫做Partition,负责实现划分数据的类叫做Partitioner。
MapReduce默认的Partitioner是HashPartitioner。默认情况下,Partitioner先计算key的散列值(通常为md5值),然后通过Reducer个数执行取模运算:key.hashCode%(reducer个数)。这种方式不仅能够随机地将整个key空间平均分发给每个Reducer,同时也能确保不同Mapper产生的相同key能被分发到同一个Reducer。
4. Partitioner的应用
4.1 需求分析
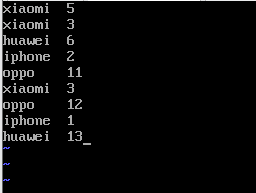
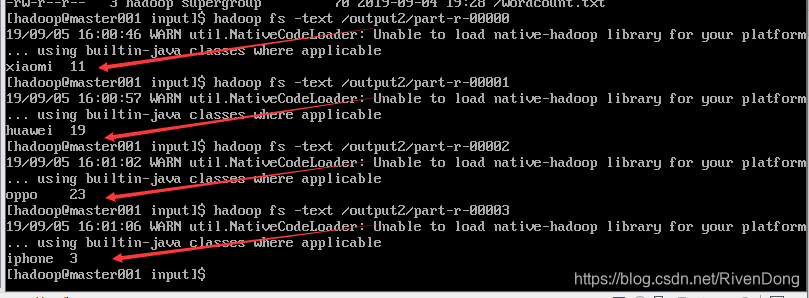
分别统计:小米、华为、oppo、苹果,这四种手机的销售情况,每种类型手机统计数据单独存放在一个结果中。
4.2 上传测试文件
创建一个名为mobilephone的文件:
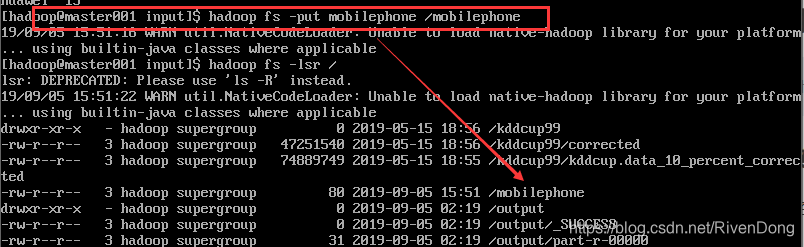
上传到HDFS:
4.3 执行代码
package com.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class PartitionerApp {
private static final String INPUT_PATH = "hdfs://master001:9000/mobilephone";
private static final String OUTPUT_PATH = "hdfs://master001:9000/output2";
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
String[] strs = value.toString().split("\t"); // 将字符串按空格进行划分
context.write(new Text(strs[0]), new IntWritable(Integer.parseInt(strs[1])));
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value: values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
public static class MyPartitioner extends Partitioner<Text, IntWritable>{
//转发给4个不同的reducer
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
if(key.toString().equals("xiaomi"))
return 0;
else if(key.toString().equals("huawei"))
return 1;
else if(key.toString().equals("oppo"))
return 2;
else
return 3;
}
}
public static void main(String[] args) throws Exception{
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration conf = new Configuration();
//提升代码的健壮性
final FileSystem fileSystem = FileSystem.get(URI.create(INPUT_PATH), conf);
if(fileSystem.exists(new Path(OUTPUT_PATH))){
fileSystem.delete(new Path(OUTPUT_PATH), true);
}
Job job = Job.getInstance(conf, "PartitionerApp");
//run jar class 主方法
job.setJarByClass(PartitionerApp.class);
//设置map
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置partitioner
job.setPartitionerClass(MyPartitioner.class);
//设置4个reducer,每个分区一个
job.setNumReduceTasks(4);
//设置input format
FileInputFormat.addInputPath(job, new Path(INPUT_PATH));
//设置output format
FileOutputFormat.setOutputPath(job, new Path(OUTPUT_PATH));
//提交job
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.4 效果截图
输出了四个part文件:part-r-00000、part-r-00001、part-r-00002、part-r-00003
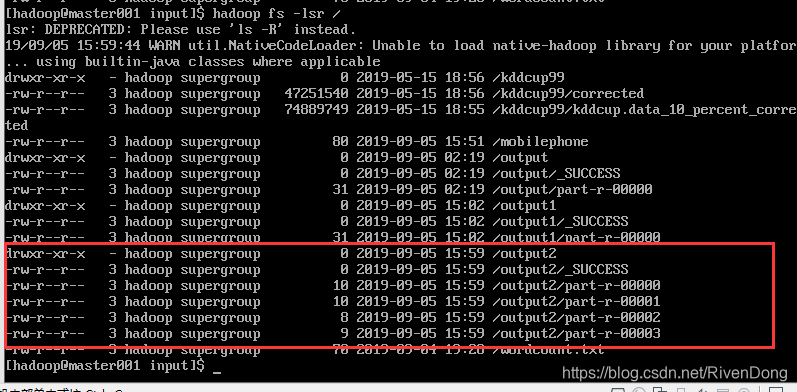
分别查看四个文件,如下结果:

















 2063
2063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









