







一.集成学习(Ensemble)介绍
集成学习也称为模型融合(Model Ensemble)。是一种有效提升机器学习效果的方法。
不同于传统的机器学习方法在训练集上构建一个模型,集成学习通过构建并融合多个模型来完成学习任务。
首先我们通过下图的一个例子来介绍集成的基本概念,下图是一个二分类问题。
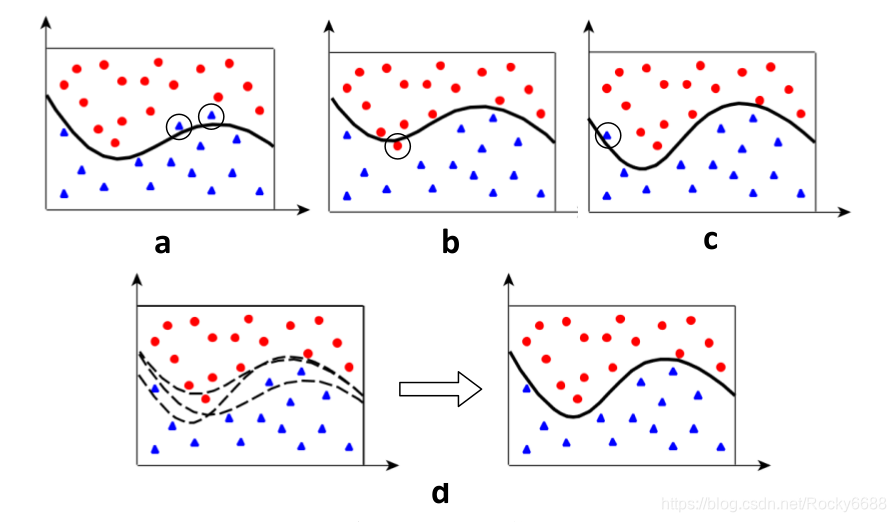 图中的数据均是测试数据,a、b、c分别是三个不同模型在测试集上的分类结果。需要注意的是,一般在做集成的时候,相同模型结构的不同参数是比较常见的情况(同质模型融合(Homogeneous Model Ensemble))。但是不能死板,我们也可以把不同模型甚至完全不同的算法做集成学习(异质模型融合(Heterogeneous Model Ensemble))。
图中的数据均是测试数据,a、b、c分别是三个不同模型在测试集上的分类结果。需要注意的是,一般在做集成的时候,相同模型结构的不同参数是比较常见的情况(同质模型融合(Homogeneous Model Ensemble))。但是不能死板,我们也可以把不同模型甚至完全不同的算法做集成学习(异质模型融合(Heterogeneous Model Ensemble))。
上图中每个模型的错误分类的样本都用圆圈标了出来,可以看到每个模型大体都是准确的,但是错误的情况也会存在。这种情况下,我们可以考虑用集成的方法:将3个不同模型的记过进行综合考虑,因为错误分类毕竟是少数,所以最终的结果的可靠性就会增加。
上图d模型就是进行集成学习的结果,可以看到效果变好了。这里采用的方法是多数投票(majority vote):对3个模型分类结果中多数的结果作为最终结果。除了多数投票,在实际应用中常见的方法还有取均值或者中值,但是基本思想都是一样的。“三个臭皮匠,赛过诸葛亮”。
以上,集成学习主要包含两个步骤:
- 训练若干个单模型(Signle Model),也称作基学习器(Base Learner)。这些单模型可以是决策树、神经网络或者是其他类型的算法。
- 模型融合,相应的方法有平均法、投票法和学习法等等。我们不单单可以进行一级模型融合,我们也可以进行多级模型融合,或者是一级模型和二级模型的混合融合类。
集成学习的泛化能力要比单模型强得多,这也是集成学习能够被人们广泛研究和应用的原因。集成学习可以整合多个"弱"模型最终得到一个"强"模型。
集成法是通过多个模型的结果综合考虑给出最终的结果,虽然准确率和稳定性都会提高,但是训练多个模型的计算成本也是非常高的,如果训练10个左右的模型,则计算成本高了一个量级。
二.融合方法
1.平均法
2.投票法
3.Bagging
独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果。
其中Dropout可以认为是一种极端的Bagging,每个模型都在单独的数据上训练,同时,通过和其他模型对应参数的共享,从而实现模型参数的高度正则化。
4.Stacking
Stacking的基本思路是:通过一个模型来融合若干个单模型的预测结果,目的是降低单模型的泛化误差。
单模型被称为一级模型,Stacking融合模型被称为二级模型或元模型。
5.Boosting(集成增强学习)
集成多个模型,每个模型都在尝试增强(Boosting)整体的效果。
三.Bagging和Boosting的区别
1.样本选择
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2.样例权重
Bagging:使用均匀取样,每个样例的权重相等。
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3.预测函数
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4.并行计算
Bagging:各个预测函数可以并行生成。
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
5.variance和bias
Bagging是减少variance。
Boosting是减少bias。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











