







写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试方法,力求让读者在获得心仪offer的同时,增强技术基本面。也欢迎大家提出宝贵的优化建议,一起交流学习💪
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
WeThinkIn最新福利放送:大家只需关注WeThinkIn公众号,后台回复“简历资源”,即可获取包含Rocky独家简历模版在内的60套精选的简历模板资源,希望能给大家在AIGC时代带来帮助。
大家好,我是Rocky。
又到了定期阅读《三年面试五年模拟》文章的时候了!本周期共更新了60多个AIGC面试高频问答,依旧干货满满!诚意满满!
《三年面试五年模拟》系列文章帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的60+AIGC面试高频问答已经全部同步到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第十八式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年7月8号-2024年7月21号更新的部分经典&干货面试知识点和面试问题,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
当然的,本项目中的内容难免有疏漏与错误之处,欢迎大家在文末评论进行补充优化,Rocky将及时更新完善到Github上!
希望《三年面试五年模拟》能陪伴大家度过整个AI行业的职业生涯,并且让大家能够持续获益。
So,enjoy:
正文开始
目录先行
AI绘画基础:
-
Imagen模型有什么特点?
-
哪些经典的GAN模型跨过了周期,在AIGC时代继续落地使用?
AI视频基础:
- AIGC时代的主流AI视频生成流程有哪些?
深度学习基础:
-
为什么Transformer需要进行Multi-head-Attention?
-
softmax在transformer中起到什么作用?
机器学习基础:
-
耦合和解耦的思想如何在机器学习中实践?
-
介绍一下自回归模型的概念
Python编程基础:
-
介绍一下Python中耦合和解耦的代码设计思想
-
Python中的函数参数有哪些类型与规则?
模型部署基础:
-
英伟达显卡中Volatile-GPU-Util代表什么含义?
-
有哪些设计高效CNN架构的方法与经验?
计算机基础:
-
介绍一下Linux系统中的Shell脚本
-
介绍一下AI行业中规范的AI服务启动Shell脚本
开放性问题:
-
AI算法工程师的核心竞争力是什么?
-
AI算法工程师的宏观职业发展路径是什么样的?
AI绘画基础
【一】Imagen模型有什么特点?
Imagen是AIGC时代AI绘画领域的第一个多阶段级联大模型,由一个Text Encoder(T5-XXL)、一个文生图 Pixel Diffusion、两个图生图超分Pixel Diffusion共同组成,让Rocky想起了传统深度学习时代的二阶段目标检测模型,这也说明多模型级联架构是跨周期的,是有价值的,是可以在AIGC时代继续成为算法解决方案构建的重要一招。
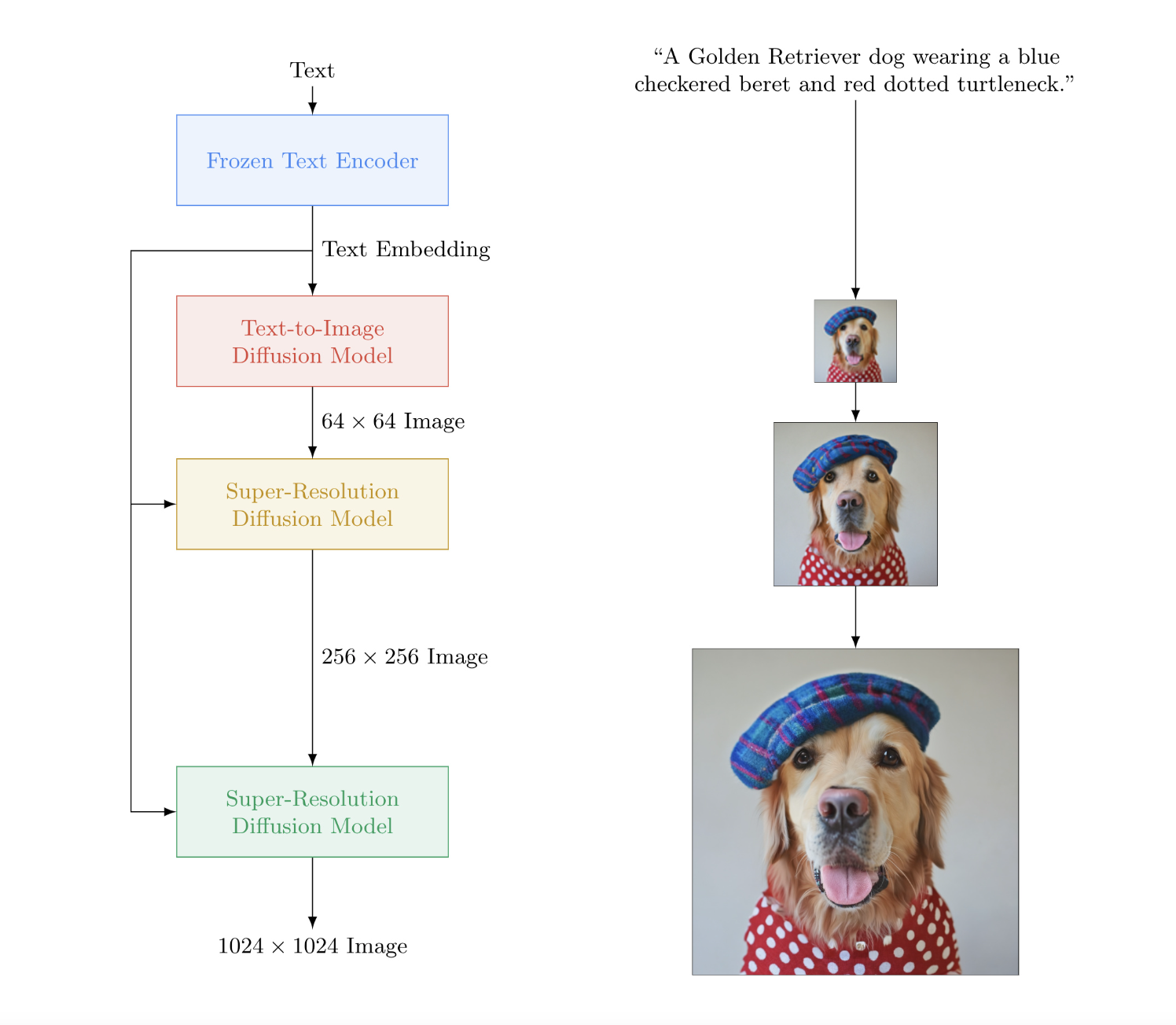
同时Imagen是AI绘画领域第一个使用大语料预训练语言模型T5-XXL作为Text Encoder的AI绘画大模型。论文中认为在文本编码器部分下功夫比在生成模型上下功夫效果要好,即使文本编码器部分的T5-XXL是纯文本语言模型,也比加大加深生成模型参数效果要好。
不过Imagen也有他的局限性,在扩散模型部分还是选用经典的64x64分辨率的U-Net结构。选择小模型可以缓解Diffusion迭代耗时太长,导致生成过慢的问题,生成小图像再超分确实是加速生成最直观的方法。但是也注定了无法生成比较复杂内容和空间关系的大图像。
【二】哪些经典的GAN模型跨过了周期,在AIGC时代继续落地使用?
GAN作为传统深度学习时代的主流生成式模型,在AIGC时代到来后,终于“退居二线”,成为Stable Diffusion模型的得力助手。Rocky认为这是GAN最好也是最合适的落地方式,所以Rocky持续梳理总结了在AIGC时代继续繁荣的GAN模型,为大家指明GAN快速学习入门的新路线:
- GAN优化:原生GAN、DCGAN、CGAN、WGAN、LSGAN等
- 图像生成:bigGAN、GigaGAN等
- 图像风格迁移:CycleGAN、StyleGAN、StyleGAN2等
- 图像编辑:Pix2Pix、GauGAN、GauGAN2、DragGAN等
- 图像超分辨率重建:SRGAN、ESRGAN、Real-ESRGAN、AuraSR等
- 图像修复/人脸修复:GFPGAN等
AI视频基础
【一】AIGC时代的主流AI视频生成流程有哪些?
Rocky总结了如下图所示的AIGC时代主流AI视频生成流程,可以作为大家构建AI视频产品构架的基础底座:

深度学习基础
【一】为什么Transformer需要进行Multi-head-Attention?
Transformer模型中的Multi-head Attention(多头注意力)机制是其核心组件之一,它显著提升了模型的性能和表达能力。理解Multi-head Attention的必要性和具体工作原理有助于我们深入理解Transformer的强大之处。
1. Multi-head Attention机制计算流程
Multi-head Attention机制通过将查询、键和值矩阵分成多个子空间(即多个头)并行计算注意力,然后将结果进行拼接和线性变换,具体流程如下所示:
1.1 线性变换和分头
将输入矩阵 Q Q Q、 K K K 和 V V V 通过线性变换分别生成多组查询、键和值:
Q i = Q W i Q , K i = K W i K , V i = V W i V Q_i = QW_i^Q, \quad K_i = KW_i^K, \quad V_i = VW_i^V Qi=QWiQ,Ki=KWiK,Vi=VWiV
其中, W i Q W_i^Q WiQ 、 W i K W_i^K WiK 和 W i V W_i^V WiV 是线性变换的权重矩阵, i i i 表示第 i i i 个头。
1.2 并行计算注意力
对于每个头 i i i,计算注意力输出:
head i = Attention ( Q i , K i , V i ) \text{head}_i = \text{Attention}(Q_i, K_i, V_i) headi=Attention(Qi,Ki,Vi)
1.3 拼接和线性变换
将所有头的输出拼接起来,并通过线性变换得到最终的注意力输出:
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
其中, W O W^O WO 是输出的线性变换权重矩阵, h h h 是头的数量。
1.4 公式总结
总体而言,Multi-head Attention 的计算过程可以表示为:
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , … , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
其中,每个头的计算为:
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
注意力计算为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
2. Multi-head Attention机制的优势
我们再来总结一下使用Multi-head Attention(多头注意力)的好处:
2.1 更好的捕捉不同位置的关系
单头注意力在计算注意力权重时,可能会对某些特定位置的依赖过于集中,导致捕捉信息的单一性。而多头注意力允许模型在多个子空间中并行计算注意力,这样可以更好地捕捉输入序列中不同位置之间的复杂关系。
2.2 增强模型的表达能力
通过引入多个注意力头,模型能够在不同的子空间中学习到不同的表示。这种多样化的表示能力使得模型在处理复杂的任务时更加灵活和强大。
2.3 防止过拟合
多头注意力机制通过分散注意力权重,可以减少单个注意力头过拟合特定特征的风险,从而提高模型的泛化能力。
3. 实际代码示例
以下是一个简单的 PyTorch 实现示例,展示 Multi-head Attention 的计算:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.linear_q = nn.Linear(d_model, d_model)
self.linear_k = nn.Linear(d_model, d_model)
self.linear_v = nn.Linear(d_model, d_model)
self.linear_out = nn.Linear(d_model, d_model)
def forward(self, q, k, v):
batch_size = q.size(0)
# Perform linear operation and split into num_heads
q = self.linear_q(q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
k = self.linear_k(k).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
v = self.linear_v(v).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# Scaled dot-product attention
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
attn = F.softmax(scores, dim=-1)
output = torch.matmul(attn, v)
# Concat and apply final linear layer
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
output = self.linear_out(output)
return output
# 示例输入
batch_size = 2
seq_length = 5
d_model = 16
num_heads = 4
q = torch.rand(batch_size, seq_length, d_model)
k = torch.rand(batch_size, seq_length, d_model)
v = torch.rand(batch_size, seq_length, d_model)
mha = MultiHeadAttention(d_model, num_heads)
output = mha(q, k, v)
print(output.shape) # 输出: torch.Size([2, 5, 16])
【二】softmax在transformer中起到什么作用?
在Transformer模型中,softmax函数在多个地方起到了关键作用,主要用于归一化注意力权重和生成概率分布:
- 归一化注意力权重,确保模型在计算注意力时,形成一个有效的概率分布。
- 在输出阶段将得分转换为概率分布,便于进行词预测或分类任务。
以下是softmax在Transformer中的详细作用和原理:
1. 归一化注意力权重
Transformer模型的核心机制是自注意力机制(self-attention),它允许模型在处理序列中的每个位置时,能够关注序列中的其他所有位置。注意力机制的计算涉及生成注意力权重,这些权重决定了模型对每个位置的关注程度。softmax函数在这里的作用是将这些权重归一化,使它们形成一个有效的概率分布。
自注意力机制中的softmax
自注意力机制的计算步骤如下:
-
计算相似性得分:
- 首先,计算查询矩阵 Q Q Q 和键矩阵 K K K 的点积,得到相似性得分矩阵 Q K T QK^T QKT 。
- 然后,将相似性得分矩阵除以键的维度的平方根 ( d k ) (\sqrt{d_k}) (dk) ,以稳定梯度。
- 公式: scores = Q K T d k \text{scores} = \frac{QK^T}{\sqrt{d_k}} scores=dkQKT
-
应用softmax:
- 使用softmax函数将相似性得分矩阵转换为概率分布,这些概率表示每个位置的重要性。
- 公式: a t t e n t i o n w e i g h t s = s o f t m a x ( s c o r e s ) attentionweights = softmax(scores) attentionweights=softmax(scores)
-
加权求和:
- 最后,将注意力权重矩阵与值矩阵 V V V 相乘,得到加权求和的结果。
- 公式: output = a t t e n t i o n w e i g h t s × V \text{output} = attentionweights \times V output=attentionweights×V
通过应用softmax函数,注意力权重被归一化,使其和为1,从而形成有效的概率分布。这确保了模型在计算注意力时,能对每个位置的关注程度进行衡量。
2. 生成概率分布
除了在注意力机制中应用softmax,Transformer还在生成模型的输出阶段使用softmax,将最后的线性层输出转换为概率分布,以便进行词预测或分类任务。
输出阶段的softmax
在语言建模或机器翻译任务中,Transformer的最后一层通常是一个线性层,输出维度为词汇表的大小(即每个词的得分)。这些得分通过softmax函数转换为概率分布,表示每个词在当前上下文中作为下一个词的概率。
公式:
P ( word ∣ context ) = softmax ( W × h ) P(\text{word} \mid \text{context}) = \text{softmax}(W \times h) P(word∣context)=softmax(W×h)
其中:
- W W W 是线性层的权重矩阵。
- h h h 是最后一层的隐藏状态。
通过应用softmax,模型可以生成一个有效的概率分布,用于采样或选择最可能的下一个词。
3. softmax的数学定义
softmax函数的数学定义如下:
softmax ( z i ) = e z i ∑ j = 1 N e z j \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{N}e^{z_j}} softmax(zi)=∑j=1Nezjezi
其中:
- z i z_i zi 是输入得分(logits)。
- N N N 是得分的数量。
softmax函数的输出是一个概率分布,每个得分被转换为一个非负的概率,并且所有概率的和为1。
4. 示例代码
以下是一个简单的示例代码,展示如何在自注意力机制和输出阶段使用softmax函数:
import torch
import torch.nn.functional as F
# 假设有三个单词,每个单词有一个查询、键和值向量
Q = torch.randn(3, 5) # 3个单词,每个单词的查询向量维度为5
K = torch.randn(3, 5) # 3个单词,每个单词的键向量维度为5
V = torch.randn(3, 5) # 3个单词,每个单词的值向量维度为5
# 计算相似性得分
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(5.0))
# 应用softmax函数,将得分转换为注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 加权求和值向量
output = torch.matmul(attention_weights, V)
print("Attention Output:", output)
# 假设有一个线性层的输出,维度为词汇表大小(假设词汇表大小为10)
logits = torch.randn(3, 10) # 3个单词,每个单词对应词汇表中10个词的得分
# 应用softmax函数,将得分转换为概率分布
probabilities = F.softmax(logits, dim=-1)
print("Probabilities:", probabilities)
机器学习基础
【一】耦合和解耦的思想如何在机器学习中实践?
在机器学习领域中,耦合(coupling)和解耦(decoupling)是两个关键概念,涉及到模型、数据、测试和系统整体设计的独立性与依赖性。理解这两个概念有助于我们构建更灵活、可维护性更高的机器学习系统。根据具体应用场景选择合适的设计方法,将极大地提升机器学习项目的成功率和可持续性。
首先我们对这两个概念进行详细的解释:
耦合(Coupling)
耦合指的是机器学习系统的不同部分之间存在较强的依赖关系。高耦合的机器学习系统各部分紧密联系,改变一个部分可能会影响到其他部分,导致系统整体的复杂性和维护成本增加。
解耦(Decoupling)
解耦指的是机器学习系统的不同部分之间尽可能减少依赖关系,使得它们可以独立研发、测试和维护。解耦可以提高系统整体的灵活性、可扩展性和可维护性。
耦合和解耦在机器学习中的表现
耦合在机器学习中的表现
-
模型和数据存在耦合的情况:
- 例如,一个AI模型可能对特定的数据分布或特征非常依赖。这意味着如果数据分布发生变化,模型的性能可能会显著下降。
- 例子:在AIGC时代中,如果数据中大量混入低质量数据,模型推理效果可能很差,导致模型需要重新训练。
-
算法和硬件的耦合:
- 一些算法可能针对特定硬件(如GPU)的优化,这会导致算法无法在其他硬件(如CPU)上高效运行。
- 例子:深度神经网络训练时通常依赖GPU加速,如果没有GPU资源,训练速度会大大降低。
-
模型和超参数的耦合:
- 一些模型需要精细化调优超参数来取得较好的性能,如果参数调整的不正确,模型的性能可能会显著下降。
- 例子:AIGC、传统深度学习、自动驾驶领域的AI模型都有这个特性。
解耦在机器学习中的表现
-
模块化设计:
- 模型、数据和算力等模块彼此独立,可以单独测试和优化。
- 例子:在AIGC、传统深度学习、自动驾驶领域中,将数据处理、模型训练、模型测试、模型部署分开,每个模块单独研发和测试。
-
通用接口:
- 使用通用接口使得不同模块可以方便地互相替换或升级,而不会影响整个AI系统。
- 例子:定义标准的数据输入输出格式,使得更换数据预处理模块不会影响模型训练过程。
优点和挑战
高耦合的优点和挑战
-
优点:
- 优化性能:针对特定任务或数据进行优化可以提高模型的性能。
- 简化设计:在特定任务中,高耦合可以简化设计,因为所有部分紧密集成。
-
挑战:
- 维护困难:修改或扩展系统时,可能需要同时修改多个部分。
- 可移植性差:高耦合系统通常难以迁移到不同的环境或任务中。
解耦的优点和挑战
-
优点:
- 灵活性高:各模块可以独立研发、测试和优化,提高AI系统的灵活性。
- 可扩展性好:新模块可以方便地集成到现有AI系统中,而不需要大规模改动。
-
挑战:
- 设计复杂:设计解耦的AI系统需要考虑更多的接口和模块化设计,增加了初始设计的复杂性。
- 性能优化:解耦的AI系统中的各模块可能需要单独优化,确保整体性能。
【二】介绍一下自回归模型的概念
自回归模型(Autoregressive Model, AR)是时间序列分析中的一种经典模型,用于表示当前值是过去若干值的线性组合。自回归模型假设时间序列的数据点可以用其自身的历史数据来解释,即通过过去的观测值预测当前和未来的观测值。以下是详细讲解自回归模型的原理、公式、假设、应用以及示例。
1. 原理
自回归模型通过回归分析的方法,利用时间序列的过去值对当前值进行预测。其核心思想是,时间序列的当前值与其前几个时间点的值之间存在某种线性关系。
2. 公式
自回归模型的数学表达式为:
y t = c + ϕ 1 y t − 1 + ϕ 2 y t − 2 + ⋯ + ϕ p y t − p + ϵ t y_t = c + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \cdots + \phi_p y_{t-p} + \epsilon_t yt=c+ϕ1yt−1+ϕ2yt−2+⋯+ϕpyt−p+ϵt
其中:
- y t y_t yt 是时间 t t t 的观测值。
- c c c 是常数项。
- ϕ 1 , ϕ 2 , … , ϕ p \phi_1, \phi_2, \ldots, \phi_p ϕ1,ϕ2,…,ϕp 是模型的系数。
- p p p 是模型的阶数,表示回顾的时间步数。
- ϵ t \epsilon_t ϵt 是误差项,假设其为白噪声(即期望为零、方差为 σ 2 \sigma^2 σ2 的独立同分布随机变量)。
3. 模型的假设
- 线性关系:时间序列的当前值与过去 p p p 个时间点的值之间存在线性关系。
- 平稳性:时间序列应是平稳的,即其统计特性(如均值和方差)随时间不变。
- 白噪声误差:误差项 ϵ t \epsilon_t ϵt 是白噪声。
4. 应用
自回归模型广泛应用于经济学、金融学、气象学、工程学等领域,用于预测和分析时间序列数据。例如:
- 经济数据中的 GDP 增长率、失业率等的预测。
- 金融市场中的股票价格、利率等的预测。
- 气象学中的气温、降雨量等的预测。
5. 自回归模型的阶数选择
选择自回归模型的阶数 p p p 是一个重要步骤。常用的方法包括:
- AIC(Akaike 信息准则):通过最小化 AIC 选择最佳阶数。
- BIC(贝叶斯信息准则):通过最小化 BIC 选择最佳阶数。
6. 示例
下面是一个使用 Python 及 statsmodels 库来拟合和预测自回归模型的示例:
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.ar_model import AutoReg
# 生成一个模拟的自回归时间序列数据
np.random.seed(42)
n = 100
phi = [0.5, -0.3, 0.2] # AR(3) 模型的系数
y = np.zeros(n)
y[0], y[1], y[2] = np.random.normal(size=3) # 初始化前3个值
for t in range(3, n):
y[t] = phi[0] * y[t-1] + phi[1] * y[t-2] + phi[2] * y[t-3] + np.random.normal()
# 拟合 AR 模型
model = AutoReg(y, lags=3)
model_fit = model.fit()
# 模型系数
print("模型系数:", model_fit.params)
# 预测未来10个时间点的值
y_forecast = model_fit.predict(start=n, end=n+9)
print("预测值:", y_forecast)
# 绘制原始数据与预测值
plt.figure(figsize=(10, 6))
plt.plot(y, label='原始数据')
plt.plot(range(n, n+10), y_forecast, label='预测值', color='red')
plt.legend()
plt.show()
解释
-
数据生成:
- 使用一个已知的 AR(3) 模型生成模拟数据,其中系数为 [ 0.5 , − 0.3 , 0.2 ] [0.5, -0.3, 0.2] [0.5,−0.3,0.2]。
-
拟合 AR 模型:
- 使用
AutoReg类拟合 AR 模型,并指定滞后阶数为 3。
- 使用
-
输出模型系数:
- 使用
model_fit.params获取拟合模型的系数。
- 使用
-
预测未来值:
- 使用
model_fit.predict方法预测未来 10 个时间点的值。
- 使用
-
绘制图形:
- 使用
matplotlib库绘制原始数据和预测值的图形,以可视化效果展示预测结果。
- 使用
Python编程基础
【一】介绍一下Python中耦合和解耦的代码设计思想
在AI行业的Python使用中,耦合和解耦的思想是设计良好的AI算法系统的重要原则。耦合(coupling)指的是模块或组件之间的依赖关系,而解耦(decoupling)指的是减少或消除这种依赖性,使AI算法系统的各部分可以独立开发、测试和维护。以下是Rocky总结的关于 Python中耦合和解耦的详细方法(使用依赖注入、接口和抽象类、事件驱动架构等),提高AI算法系统的灵活性、可维护性和可扩展性。
1. 耦合(Coupling)
耦合表示不同模块或组件之间的依赖关系。当两个模块高度耦合时,一个模块的变化可能会影响另一个模块,导致系统维护和扩展的难度增加。耦合有两种主要形式:紧耦合和松耦合。
紧耦合
紧耦合是指模块之间的依赖性很强,任何一个模块的变化都会导致其他模块的变化。紧耦合系统难以维护和扩展。
示例:
class Database:
def connect(self):
print("Connecting to the database")
class UserService:
def __init__(self):
self.db = Database()
def get_user(self, user_id):
self.db.connect()
print(f"Getting user {user_id}")
user_service = UserService()
user_service.get_user(1)
在这个示例中,UserService 直接依赖于 Database,这使得它们高度耦合。如果 Database 类发生变化,UserService 也需要相应地修改。
2. 解耦(Decoupling)
解耦指的是减少或消除模块或组件之间的依赖关系,使它们能够独立地开发、测试和维护。解耦可以通过以下几种方法实现:
依赖注入(Dependency Injection)
依赖注入(松耦合)是一种设计模式,允许将依赖项从外部传递给一个对象,而不是在对象内部创建依赖项。
示例:
class Database:
def connect(self):
print("Connecting to the database")
class UserService:
def __init__(self, db):
self.db = db
def get_user(self, user_id):
self.db.connect()
print(f"Getting user {user_id}")
db = Database()
user_service = UserService(db)
user_service.get_user(1)
在这个示例中,UserService 不再直接创建 Database 实例,而是通过构造函数接收一个 Database 实例。这减少了模块之间的耦合度。
使用接口和抽象类
通过使用接口或抽象类,可以将具体实现与接口分离,从而实现解耦。
示例:
from abc import ABC, abstractmethod
class DatabaseInterface(ABC):
@abstractmethod
def connect(self):
pass
class Database(DatabaseInterface):
def connect(self):
print("Connecting to the database")
class UserService:
def __init__(self, db: DatabaseInterface):
self.db = db
def get_user(self, user_id):
self.db.connect()
print(f"Getting user {user_id}")
db = Database()
user_service = UserService(db)
user_service.get_user(1)
在这个示例中,Database 实现了 DatabaseInterface 接口,UserService 依赖于 DatabaseInterface 而不是 Database 的具体实现。这种方式提高了系统的灵活性和可维护性。
使用事件驱动架构
事件驱动架构通过事件和消息来解耦模块。模块通过事件总线进行通信,而不需要直接依赖其他模块。
示例:
class EventBus:
def __init__(self):
self.listeners = []
def subscribe(self, listener):
self.listeners.append(listener)
def publish(self, event):
for listener in self.listeners:
listener(event)
class Database:
def connect(self):
print("Connecting to the database")
class UserService:
def __init__(self, event_bus):
self.event_bus = event_bus
self.event_bus.subscribe(self.handle_event)
def handle_event(self, event):
if event == "GET_USER":
self.get_user(1)
def get_user(self, user_id):
db = Database()
db.connect()
print(f"Getting user {user_id}")
event_bus = EventBus()
user_service = UserService(event_bus)
event_bus.publish("GET_USER")
在这个示例中,UserService 通过事件总线 EventBus 进行通信,而不是直接依赖其他模块。这种架构提高了系统的模块化和扩展性。
【二】Python中的函数参数有哪些类型与规则?
在Python中,函数的参数有多种类型和一套设定的规则需要遵守,这使得函数定义和调用非常灵活。以下是Python详细的参数规则和类型解释:
1. 位置参数(Positional Arguments)
位置参数是最常见的参数类型,按顺序传递给函数。
def greet(name, age):
print(f"Hello, my name is {name} and I am {age} years old.")
greet("Alice", 30)
2. 关键字参数(Keyword Arguments)
关键字参数允许在函数调用时通过参数名指定参数值,使得参数传递更具可读性,并且不必按顺序传递。
greet(age=30, name="Alice")
3. 默认参数(Default Arguments)
默认参数在函数定义时指定默认值,如果在函数调用时未提供该参数,则使用默认值。
def greet(name, age=25):
print(f"Hello, my name is {name} and I am {age} years old.")
greet("Alice") # 使用默认值25
greet("Bob", 30) # 覆盖默认值
4. 可变位置参数(Variable Positional Arguments)
使用 *args 语法,允许函数接受任意数量的位置参数。 *args 是一个元组。
def greet(*names):
for name in names:
print(f"Hello, {name}!")
greet("Alice", "Bob", "Charlie")
5. 可变关键字参数(Variable Keyword Arguments)
使用 **kwargs 语法,允许函数接受任意数量的关键字参数。 **kwargs 是一个字典。
def greet(**kwargs):
for key, value in kwargs.items():
print(f"{key} is {value}")
greet(name="Alice", age=30, location="Wonderland")
参数顺序规则
在定义函数时,参数应按照以下顺序排列:
- 位置参数
- 关键字参数
- 默认参数
- 可变位置参数
*args - 可变关键字参数
**kwargs
示例
def example(a, b=2, *args, **kwargs):
print(a, b, args, kwargs)
example(1) # 输出: 1 2 () {}
example(1, 3, 4, 5, x=10, y=20) # 输出: 1 3 (4, 5) {'x': 10, 'y': 20}
模型部署基础
【一】英伟达显卡中Volatile-GPU-Util代表什么含义?
在英伟达的显卡监控工具中,Volatile GPU Util 是一个重要的指标,用于显示GPU利用率的波动情况。它反映了在一个采样周期内GPU的使用百分比,这个百分比指示了GPU在这段时间内忙于执行计算任务的时间占比。
这个指标在AIGC、传统深度学习、自动驾驶领域都很重要,能够方便我们查看GPU的使用情况,测试排查GPU问题,筛选出高性能GPU来提升AI模型的训练推理效率,增强AI系统的整体性能。下面Rocky再给大家讲解一下Volatile GPU Util详细含义和用途:
含义
-
瞬时利用率:
- Volatile GPU Util表示的是在特定采样周期内GPU的利用率,这个采样周期通常是非常短的(例如几秒钟),因此这个值是瞬时的而非累积的。GPU的利用率不等于GPU内计算单元干活的比例,GPU Util本质上只是反应了在采样时间段内,一个或多个内核(kernel)在GPU上执行的时间百分比,采样时间段取值1/6s~1s。
-
活动时间百分比:
- 这个值表示GPU在采样周期内有多少时间在执行计算任务。例如,50%的Volatile GPU Util表示在采样周期的一半时间里GPU是忙于计算任务的。
-
动态变化:
- 因为这个指标是瞬时的,它会随着时间的变化而波动,反映GPU利用率的动态变化情况。这对于实时监控GPU负载非常有帮助。
用途
-
性能监控:
- AI行业开发者可以使用Volatile GPU Util来监控GPU的实时负载情况,以确定当前的计算任务是否充分利用了GPU资源。
-
瓶颈识别:
- 通过观察Volatile GPU Util,我们可以识别出是否存在GPU资源不足的问题。例如,如果利用率一直接近100%,说明GPU可能成为AI系统的瓶颈,任务可能受限于GPU的计算能力。
-
资源分配:
- 管理多个AI任务和资源的调度时,Volatile GPU Util可以帮助确定哪个AI任务在消耗大量GPU资源,从而更好地分配计算资源和优化性能。
-
优化和调试:
- AI行业开发者可以根据这个指标来优化代码和算法,以提高GPU的利用率。低利用率可能表明存在性能瓶颈或资源浪费的情况,需要进行优化。
示例
在使用英伟达提供的 nvidia-smi 命令工具后,我们可以看到Volatile GPU Util的输出。例如:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GTX 1080 Off | 00000000:01:00.0 Off | N/A |
| 30% 58C P2 42W / 180W | 0MiB / 8119MiB | 28% Default |
+-------------------------------+----------------------+----------------------+
在这个示例中,GPU-Util 一栏显示 28%,这表示在当前采样周期内,这个GPU的利用率是28%。通过理解和监控Volatile GPU Util,我们可以更好地管理和优化GPU资源,确保AI系统的高效运行。
【二】有哪些设计高效CNN架构的方法与经验?
首先,我们在设计高效CNN架构之前,需要对CNN架构本身有一定的理解:
- CNN主要有网络深度和通道宽度两个核心参数,通常来说,网络越深越宽,性能越好。宽度代表通道(channel)的数量;网络深度代表layer的层数,比如resnet52 有52层网络。
- 网络深度的意义:CNN的网络层能够对输入图像数据进行逐层抽象,比如第一层学习到了图像边缘特征,第二层学习到了简单形状特征,第三层学习到了目标形状的特征,网络深度增加也提高了模型的特征提取和抽象的能力。
- 网络宽度的意义:网络的宽度(通道数)代表了滤波器(3 维)的数量,滤波器越多,对目标特征的提取能力越强,即让每一层网络学习到更加丰富的特征,比如不同方向、不同频率的纹理特征等。
了解了CNN的一些概念,我们可以开始设计高效CNN架构了,下面是一些设计经验与建议,也欢迎大家一起来补充:
- 分析模型的推理性能需要结合具体的推理平台(比如GPU、ARM CPU、NPU以及端侧芯片等)。
- 目前已知影响CNN模型推理性能的因素包括: 算子计算量FLOPs(参数量 Params)、卷积block的内存访问代价(访存带宽)、网络并行度等。在相同硬件平台、相同网络架构条件下, FLOPs加速比与推理时间加速比成正比。
- 建议对于轻量级网络设计应该评估直接metric(例如速度speed),而不是间接metric(例如FLOPs)。
- FLOPs低不等于latency低,尤其是在有加速功能的硬体(GPU、DSP与TPU)上不成立,得结合具硬件架构具体分析。
- 不同网络架构的CNN模型,即使是FLOPs相同,但其MAC也可能差异巨大。
- 在GPU上,Depthwise卷积算子实际上是使用了大量的低FLOPs、高数据读写量的操作。这些具有高数据读写量的操作,加上多数时候GPU芯片算力的瓶颈在于访存带宽,使得模型把大量的时间浪费在了从显存中读写数据上,导致GPU的算力没有得到“充分利用”。
- 在大多数的AI端侧硬件上,channel数为16的倍数比较有利高效计算。如海思351x系列芯片,当输入通道为4倍数和输出通道数为16倍数时,时间加速比会近似等于 FLOPs 加速比,有利于提供 NNIE 硬件计算利用率。
- 在低channel数的情况下 (如网络的前几层),在有加速功能的硬件(NPU芯片)上使用普通convolution通常会比separable convolution有效率。
- shufflenetv2论文提出的四个高效网络设计的实用指导思想: (1)同样大小的通道数可以最小化MAC(2)分组数太多的卷积会增加MAC(3)网络碎片化会降低并行度(4)逐元素的操作不可忽视。
- RepVGG论文指出GPU芯片上 3 × 3 3\times 3 3×3 卷积非常快,其计算密度(理论运算量除以所用时间)可达 1 × 1 1\times 1 1×1 和 5 × 5 5\times 5 5×5 卷积的四倍。
- 如果想从解决梯度信息冗余问题入手,来提高模型推理效率,可参考CSPNet网络的构建思路。
- 如果想从解决DenseNet的密集连接带来的高内存访问成本和能耗问题入手,可参考VoVNet网络,其由OSA(One-Shot Aggregation,一次聚合)模块组成。
计算机基础
Rocky从工业界、应用界、竞赛界以及学术界角度出发,总结沉淀AI行业中需要用到的实用计算机基础知识,不仅能在面试中帮助到我们,还能让我们在日常工作中提高效率。
【一】介绍一下Linux系统中的Shell脚本
在Linux系统中,Shell脚本是一种非常强大的工具,在AIGC、传统深度学习、自动驾驶领域中主要用于自动化任务、管理系统和处理日常操作。直观上看,Shell脚本是一系列shell命令的集合,以脚本文件的形式存储,并通过shell解释器来执行。下面是Rocky对Linux系统中shell脚本的详细讲解,包括基础知识、编写示例和一些高级用法:
Shell脚本基础
什么是Shell
Shell是用户与Linux操作系统之间的命令解释器,它可以执行命令、脚本和其他操作。常见的shell包括:
- Bourne Shell (sh): /bin/sh
- Bourne Again Shell (bash): /bin/bash
- C Shell (csh): /bin/csh
- Korn Shell (ksh): /bin/ksh
- Z Shell (zsh): /bin/zsh
在AI领域中,主要使用/bin/sh和/bin/bash两种命令解释器。Rocky再讲一下两者的区别,以便大家更好的理解:
- Bash是sh的超集,这意味着Bash包含了sh的所有功能,并且向后兼容sh脚本。使用sh编写的脚本几乎可以在Bash中不做修改地运行。
- Bash提供了许多增强的交互功能,如命令行编辑(使用Emacs和Vi模式)、命令历史记录、Tab补全等。sh提供的交互功能较少,更适合编写简单的脚本而不是交互式使用。
- Bash支持一系列高级编程特性,如数组、命令替换、进程替换、改进的变量替换、字符串操作等。sh提供的编程功能较为基本,主要用于简单的脚本和系统级任务。
- sh通常比bash更轻量级,因为它的功能较少。因此,sh可能在一些简单的脚本中表现更快。bash提供了更多功能和灵活性,适用于更复杂的脚本和交互式使用,但在某些情况下可能比sh略慢。
创建Shell脚本
- 脚本文件:创建一个以
.sh结尾的文件,例如WeThinkIn.sh。 - Shebang 行:脚本文件的第一行通常是
#!开头,指定要使用的解释器,例如第一行设置为#!/bin/bash时,在运行Shell脚本后,系统会读取 shebang 行,并使用/bin/bash来解释和执行脚本的内容。 - 命令和逻辑:在 shebang 行之后,我们需要编写要执行的shell命令和脚本逻辑。
Shell脚本示例与运行
Shell脚本示例
#!/bin/bash
# 简单示例
echo "Hello, World!"
# 带变量的情况
name="Alice"
echo "Hello, $name!"
# 带条件的情况
if [ "$name" == "Alice" ]; then
echo "Your name is Alice."
else
echo "Your name is not Alice."
fi
# 带函数和循环的情况
greet() {
echo "Hello, $1!"
}
for name in Alice Bob Charlie; do
greet $name
done
执行Shell脚本
- 赋予执行权限:使用
chmod +x WeThinkIn.sh命令为脚本赋予执行权限。 - 运行脚本:通过
sh WeThinkIn.sh、bash WeThinkIn.sh或者./WeThinkIn.sh命令运行脚本。
我们可以在命令行中通过 sh WeThinkIn.sh 执行刚才的Shell脚本示例,可以看到如下的输出结果:
Hello, World!
Hello, Alice!
Your name is Alice.
Hello, Alice!
Hello, Bob!
Hello, Charlie!
Shell常用命令和特性
设置变量和参数
- 定义变量:
variable_name=value - 引用变量:
$variable_name - 脚本参数:
$0表示脚本名称,$1, $2, ...表示脚本参数,$#表示参数个数,$@表示所有参数。
条件语句
-
if语句:
if [ condition ]; then # do something elif [ condition ]; then # do something else else # do another thing fi -
case语句:
case "$variable" in pattern1) # do something ;; pattern2) # do something else ;; *) # default case ;; esac
循环
-
for循环:
for var in list; do # do something with $var done -
while循环:
while [ condition ]; do # do something done
函数
-
定义函数:
function_name() { # function body } -
调用函数:
function_name argument1 argument2
Shell高级用法
输入输出重定向
- 重定向输出:
command > WeThinkIn.txt(内容覆盖文件),command >> WeThinkIn.txt(内容追加到文件)。 - 重定向输入:
command < WeThinkIn.txt。 - 管道:
command1 | command2。
下面Rocky对管道的用法进行举例,让大家更好的理解:ps aux | grep "python"
上面的命令表示将 ps 输出传递给 grep 以查找Python进程。
错误处理
- 捕获错误:在Shell脚本中添加
set -e行,当脚本中发生任何命令的失败时退出脚本。 - 错误消息:
command || echo "Command failed"。
调试脚本
-
开启调试模式:
-
使用
set -x和set +x命令set -x:开启调试模式。set +x:关闭调试模式。
-
在 shebang 行中添加
-x选项#!/bin/bash -x:直接在脚本的shebang行中添加-x选项,整个脚本都将处于调试模式。
-
-
示例脚本:
- 示例1:使用
set -x和set +x
#!/bin/bash # Script to demonstrate debugging echo "This is a test script." set -x # 开启调试模式 # 变量定义 name="Alice" echo "Hello, $name!" # 条件语句 if [ "$name" == "Alice" ]; then echo "Your name is Alice." else echo "Your name is not Alice." fi set +x # 关闭调试模式 echo "Script execution completed."执行这个脚本时,
set -x和set +x之间的部分会显示调试信息:This is a test script. + name=Alice + echo 'Hello, Alice!' Hello, Alice! + '[' Alice == Alice ']' + echo 'Your name is Alice.' Your name is Alice. Script execution completed.- 示例2:在 shebang 行中添加
-x选项
#!/bin/bash -x # Script to demonstrate debugging echo "This is a test script." # 变量定义 name="Alice" echo "Hello, $name!" # 条件语句 if [ "$name" == "Alice" ]; then echo "Your name is Alice." else echo "Your name is not Alice." fi echo "Script execution completed."执行这个脚本时,整个脚本都会显示调试信息:
+ echo 'This is a test script.' This is a test script. + name=Alice + echo 'Hello, Alice!' Hello, Alice! + '[' Alice == Alice ']' + echo 'Your name is Alice.' Your name is Alice. + echo 'Script execution completed.' Script execution completed. - 示例1:使用
【二】介绍一下AI行业中规范的AI服务启动Shell脚本
在AI行业中,AIGC、传统深度学习、自动驾驶等核心领域一般都使用Shell脚本启动AI程序服务。Shell脚本可以自动化AI程序的启动、停止和监控过程,使得对AI服务管理变得更加高效和可靠。以下是Rocky总结的编写规范Shell脚本的详细步骤,并对每个步骤进行深入浅出的讲解。
1. 先配置Shebang行和脚本说明
Shebang行
#!/bin/bash
- 解释:
#!/bin/bash指定了脚本使用/bin/bash解释器执行。Shebang行必须是脚本的第一行。
脚本说明
# This script is used to start the AI service.
# Author: WeTHinkIn
# Date: 2024-08-12
- 解释:脚本头部的注释部分提供了脚本的基本信息,包括用途、作者和创建日期。这有助于后续的AI服务维护和扩展。
2. 设置环境变量
# 定义环境变量
export MODEL_DIR="/path/to/model"
export DATA_DIR="/path/to/data"
export LOG_DIR="/path/to/logs"
export CONFIG_FILE="/path/to/config.yaml"
export PYTHON_ENV="/path/to/virtualenv/bin/python"
- 解释:环境变量用于存储配置文件、数据目录、日志目录等路径。使用
export命令将这些变量导出,使其在当前Shell脚本的所有子进程中都可见和可访问,这意味着当前脚本启动的任何其他脚本或命令中都能访问到这些变量。
3. AI服务代码构建
通过git相关命令获取最新AI服务代码
# 首先确定要获取的AI服务代码的分支:检查启动Shell脚本时是否提供了第一个命令行参数,如果没有提供,则将变量branch设置为默认值"master";如果提供了第一个命令行参数,则将变量branch设置为该参数的值。
if [ -z "$1" ]; then
branch="master"
else
branch="$1"
fi
# 清理当前工作目录,获取制定分支的最新AI服务代码
cd /path/to/code_path
git pull
git reset
git checkout .
git clean -f
git checkout $branch
git pull
# 下面两个命令可以停止特定端口(比如8888)上的已有程序,为即将启动的AI程序服务提供空闲端口
lsof -i :8888 | grep LISTEN | awk '{print $2}' | xargs kill -9
# 或者
pkill -f 'python.*8888'
- 解释:上面的AI服务代码构建命令中主要分成三步,分别是确定AI服务代码的分支;清理当前工作目录,获取最新AI服务代码;为AI服务代码提供空闲端口。
启动AI程序服务
echo "Starting WeThinkIn AI service..."
nohup python /path/to/WeThinkIn.py --model_dir ${MODEL_DIR} --data_dir ${DATA_DIR} --config ${CONFIG_FILE} > ${LOG_DIR}/service.log 2>&1 &
echo "WeThinkIn AI service started. Logs are available at ${LOG_DIR}/service.log"
- 解释:正式启动AI程序服务,使用
nohup和&将服务放入后台运行,并将输出和错误重定向到日志文件。
4. 错误捕获和错误处理
错误处理函数
handle_error() {
echo "Error occurred in script at line: $1."
exit 1
}
- 解释:
handle_error函数打印错误信息并退出脚本。$1是错误发生的行号。
设置错误捕获
trap 'handle_error $LINENO' ERR
- 解释:
trap命令捕获错误信号(ERR),并调用handle_error函数,传递错误发生的行号$LINENO。
完整示例脚本
#!/bin/bash
# This script is used to start the AI service.
# Author: WeTHinkIn
# Date: 2024-08-12
# 如果出现报错,及时结束程序
set -e
# 定义环境变量
export MODEL_DIR="/path/to/model"
export DATA_DIR="/path/to/data"
export LOG_DIR="/path/to/logs"
export CONFIG_FILE="/path/to/config.yaml"
export PYTHON_ENV="/path/to/virtualenv/bin/python"
# 首先确定要获取的AI服务代码的分支:检查启动Shell脚本时是否提供了第一个命令行参数,如果没有提供,则将变量branch设置为默认值"master";如果提供了第一个命令行参数,则将变量branch设置为该参数的值。
if [ -z "$1" ]; then
branch="master"
else
branch="$1"
fi
# 清理当前工作目录,获取制定分支的最新AI服务代码
cd /path/to/code_path
git pull
git reset
git checkout .
git clean -f
git checkout $branch
git pull
# 下面两个命令可以停止特定端口(比如8888)上的已有程序,为即将启动的AI程序服务提供空闲端口
lsof -i :8888 | grep LISTEN | awk '{print $2}' | xargs kill -9
# 或者
pkill -f 'python.*8888'
# 启动AI程序服务
echo "Starting WeThinkIn AI service..."
nohup python /path/to/WeThinkIn.py --model_dir ${MODEL_DIR} --data_dir ${DATA_DIR} --config ${CONFIG_FILE} > ${LOG_DIR}/service.log 2>&1 &
echo "WeThinkIn AI service started. Logs are available at ${LOG_DIR}/service.log"
# 错误捕获与错误处理
handle_error() {
echo "Error occurred in script at line: $1."
exit 1
}
trap 'handle_error $LINENO' ERR
通过以上步骤,我们就可以编写出一个结构清晰、功能完整的Shell脚本,用于启动AI程序服务。Shell脚本中要包括环境变量设置、AI服务代码获取、服务启动和错误处理等功能,来保证Shell脚本的可维护性和鲁棒性。
开放性问题
Rocky从工业界、应用界、竞赛界以及学术界角度出发,思考总结AI行业的一些开放性问题,这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入更深入的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】AI算法工程师的核心竞争力是什么?
Rocky认为这是一个非常有价值的问题,不管是面试者还是面试官,都需要用整个职业生涯去思考感受。
Rocky认为我们需要从如下几个方面构建来构建AI算法工程师的核心竞争力:
- 技术深度:需要从实际现金流业务中去不断成长。
- 技术广度:要了解最新技术的整体思路、效果、实现过程、落地成本等维度。
- 技术跨周期能力:要沉淀能够跨越周期的技术知识、技术认知与技术思考。就像从传统深度学习时代到AIGC时代那样。
- 商务能力:需要学习商务能力,知道商务逻辑与商务成本。
- 产品能力:需要学习产品能力,知道产品逻辑与产品成本。
- 运营能力:需要学习运营能力,知道运营逻辑与运营成本。
- 演讲能力
- 统筹管理能力
【二】AI算法工程师的宏观职业发展路径是什么样的?
Rocky认为这是一个非常有价值的问题,不管是面试者还是面试官,都需要用整个职业生涯去思考感受。
Rocky总结了AI算法工程师的宏观职业发展路径,供大家参考借鉴:
AI算法初学者 -> AI算法实习生 -> AI算法工程师 -> AI算法高级工程师 -> AI算法专家/研究员 -> AI算法总监 -> CTO -> CEO
推荐阅读
2、Stable Diffusion XL核心基础知识,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
3、Stable DiffusionV1-V2核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
4、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1上手构建ControlNet高级应用等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
5、LoRA系列模型核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
6、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
7、10万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能给个star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
8、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
9、GAN网络核心基础知识、深入浅出解析GAN在AIGC时代的应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306

















 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











