







写在前面
【三年面试五年模拟】旨在整理&挖掘AI算法工程师在实习/校招/社招时所需的干货知识点与面试经验,力求让读者在获得心仪offer的同时,增强技术基本面。
WeThinkIn最新福利放送:大家只需关注WeThinkIn公众号,后台回复“简历资源”,即可获取包含Rocky独家简历模版在内的60套精选的简历模板资源,希望能给大家在AIGC时代带来帮助。
Rocky最新发布Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章,点击链接直达干货知识:https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期阅读《三年面试五年模拟》文章的时候了!本周期共更新了80多个AIGC面试高频问答,依旧干货满满!诚意满满!
《三年面试五年模拟》系列文章帮助很多读者获得了心仪的算法岗offer,收到了大家的很多好评,Rocky觉得很开心也很有意义。
在AIGC时代到来后,Rocky对《三年面试五年模拟》整体战略方向进行了重大的优化重构,在秉持着Rocky创办《三年面试五年模拟》项目初心的同时,增加了AIGC时代核心的版块栏目,详细的版本更新内容如下所示:
- 整体架构:分为AIGC知识板块和AI通用知识板块。
- AIGC知识板块:分为AI绘画、AI视频、大模型、AI多模态、数字人这五大AIGC核心方向。
- AI通用知识板块:包含AIGC、传统深度学习、自动驾驶等所有AI核心方向共通的知识点。
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的80+AIGC面试高频问答已经全部同步到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第二十三式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2024年9月16号-2024年9月29号更新的部分经典&干货面试知识点和面试问题,并配以相应的参考答案(精简版),供大家学习探讨。
在《三年面试五年模拟》版本更新白皮书,迎接AIGC时代中我们阐述了《三年面试五年模拟》项目在AIGC时代的愿景与规划,也包含了项目共建计划,感兴趣的朋友可以一起参与本项目的共建!
《三年面试五年模拟》系列将陪伴大家度过整个AI行业的职业生涯,并且让大家能够持续获益。
So,enjoy(与本文的BGM一起食用更佳哦):
正文开始
目录先行
AI绘画基础:
-
AI绘画大模型的数据预处理都包含哪些步骤?
-
AI绘画大模型的训练流程都包含哪些步骤?
AI视频基础:
-
介绍一下CogVideoX系列模型的VAE结构
-
在CogVideoX系列模型中VAE是如何训练的?
深度学习基础:
-
ROPE(Rotary-Position-Embedding)位置编码有何特点?
-
深度学习中模型权重融合有哪些主流的方法?
机器学习基础:
-
介绍一下总变分损失的概念与作用
-
介绍一下机器学习中的Nucleus采样原理
Python编程基础:
-
python中文件有哪些打开模式,它们的区别是什么?
-
python字典和json字符串如何相互转化?
模型部署基础:
-
介绍一下torch、torchvision、CUDA、cuDNN之间的关系
-
介绍一下XPU、MLU、MUSA各自的特点
计算机基础:
-
介绍一下AI行业中的API以及具体的作用
-
Linux中修改用户权限的命令有哪些?
开放性问题:
-
如何减少对下一个AIGC式的时代周期的错判率?
-
如何减少对下一个OpenAI式公司的错判率?
AI绘画基础
【一】AI绘画大模型的数据预处理都包含哪些步骤?
我们都知道,在AIGC时代,训练数据质量决定了AI绘画大模型的性能上限,所以Rocky也帮大家总结归纳了一套完整的数据预处理流程,希望能给大家带来帮助:
- 数据采集:针对特定领域,采集获取相应的数据集。
- 数据质量评估:对采集的数据进行质量评估,确保数据集分布与AI项目要求一致。
- 行业标签梳理:针对AI项目所处的领域,设计对应的特殊标签。
- 数据清洗:删除质量不合格的数据、对分辨率较小的数据进行超分、对数据中的水印进行去除等。
- 数据标注:使用人工标注、模型自动标注(img2tag、img2caption)等方式,生成数据标签。
- 标签清洗:对数据标签中的错误、描述不一致等问题,进行修改优化。
- 数据增强:使用数据增强技术,扩增数据集规模。
【二】AI绘画大模型的训练流程都包含哪些步骤?
Rocky为大家总结了AI绘画大模型的主要训练流程,其中包括:
- 训练数据预处理:数据采集、数据质量评估、行业标签梳理、数据清洗、数据标注、标签清洗、数据增强等。
- 训练资源配置:底模型选择、算力资源配置、训练环境搭建、训练参数设置等。
- 模型微调训练:运行AI绘画大模型训练脚本,使用TensorBoard等技术监控模型训练过程,阶段性验证模型的训练效果。
- 模型测试与优化:将训练好的AI绘画大模型用于效果评估与消融实验,根据bad case和实际需求进行迭代优化。
AI视频基础
【一】介绍一下CogVideoX系列模型的VAE结构
和Sora类似,CogVideoX模型在输入端也是设计了一个3D Causal VAE结构对输入视频数据进行Latent编码。
视频数据比起图像数据,本质上是增加了时间信息,所以其数据量级和计算量级也远超图像数据,处理难度也更高。3D VAE架构主要通过3D卷积同时压缩视频的空间和时间维度,从而实现了对视频数据更高的压缩编码效率和更好的重建质量与连续性。
下图展示了3D VAE的结构示意图,主要包括一个Encoder(编码器)、一个Decoder(解码器)以及一个Latent Space Regularizer(潜在空间正则器):
- 编码器:用于将输入视频数据转换为Latent Feature。这一过程中,编码器会通过四个下采样阶段逐步减少视频数据的空间和时间分辨率。
- 解码器:将视频数据的Latent Feature转换成原始的像素级视频。解码器也包含四个对称的上采样阶段,用于恢复视频数据的空间和时间分辨率。
- 潜在空间正则化器:通过KL散度来约束高斯Latent空间,对编码器生成的Latent Feature进行正则化。这对于AI视频大模型的生成效果和稳定性至关重要。
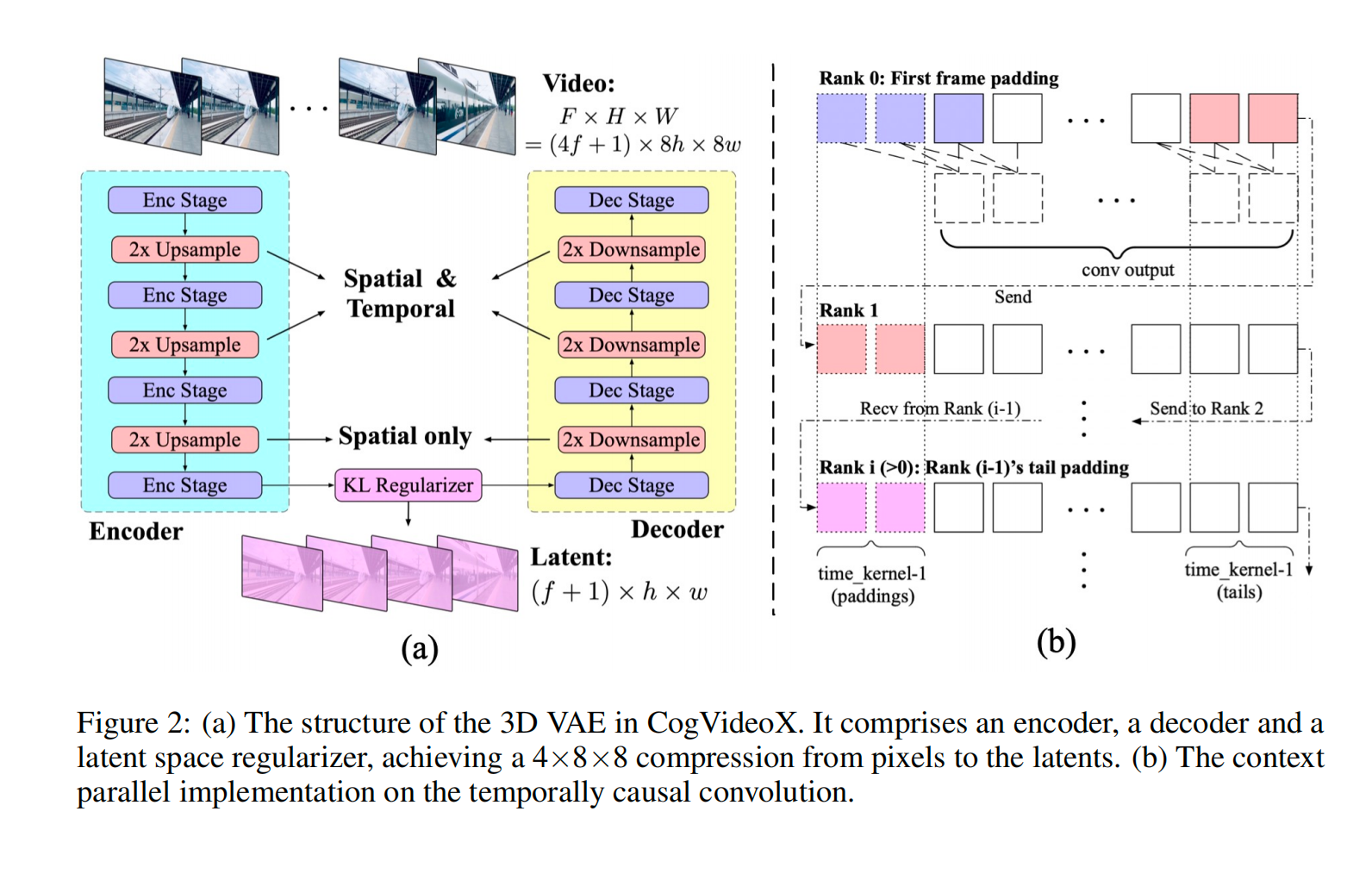
值得注意的是,编码器的前两个下采样阶段和解码器的最后两个上采样阶段涉及空间和时间维度,而最后一个阶段仅应用于空间采样。所以3D VAE在时间维度上实现了4倍的压缩,而在空间维度上实现了8×8倍的压缩。总的来说,实现了视频数据从像素级到Latent Feature的4×8×8压缩比率,整体压缩效率还是非常高的。
同时在3D VAE中采用了时间因果卷积,这是一种特殊的卷积网络,该卷积将所有填充放置在时间卷积的开头,如上图(b)中所示。这确保了未来帧的信息不会影响现在或过去的预测。这对于时间序列数据的处理非常重要,因为它保留了因果关系,使得模型的预测不会违反时间顺序。
由于处理视频数据的所有帧会消耗大量的GPU显存,CogVideoX为了适应大规模视频的处理,在时间维度上应用了上下文并行(context parallel)的策略进行3D卷积操作,将时间维度上的计算分配到多个GPU设备上进行并行计算,如上图中(b)所示。每个GPU设备只需要处理一部分时间段的数据,并将必要的信息传递给下一个GPU设备,这减少了GPU设备间的通信开销,并有效地分配了计算资源。由于卷积的因果性。
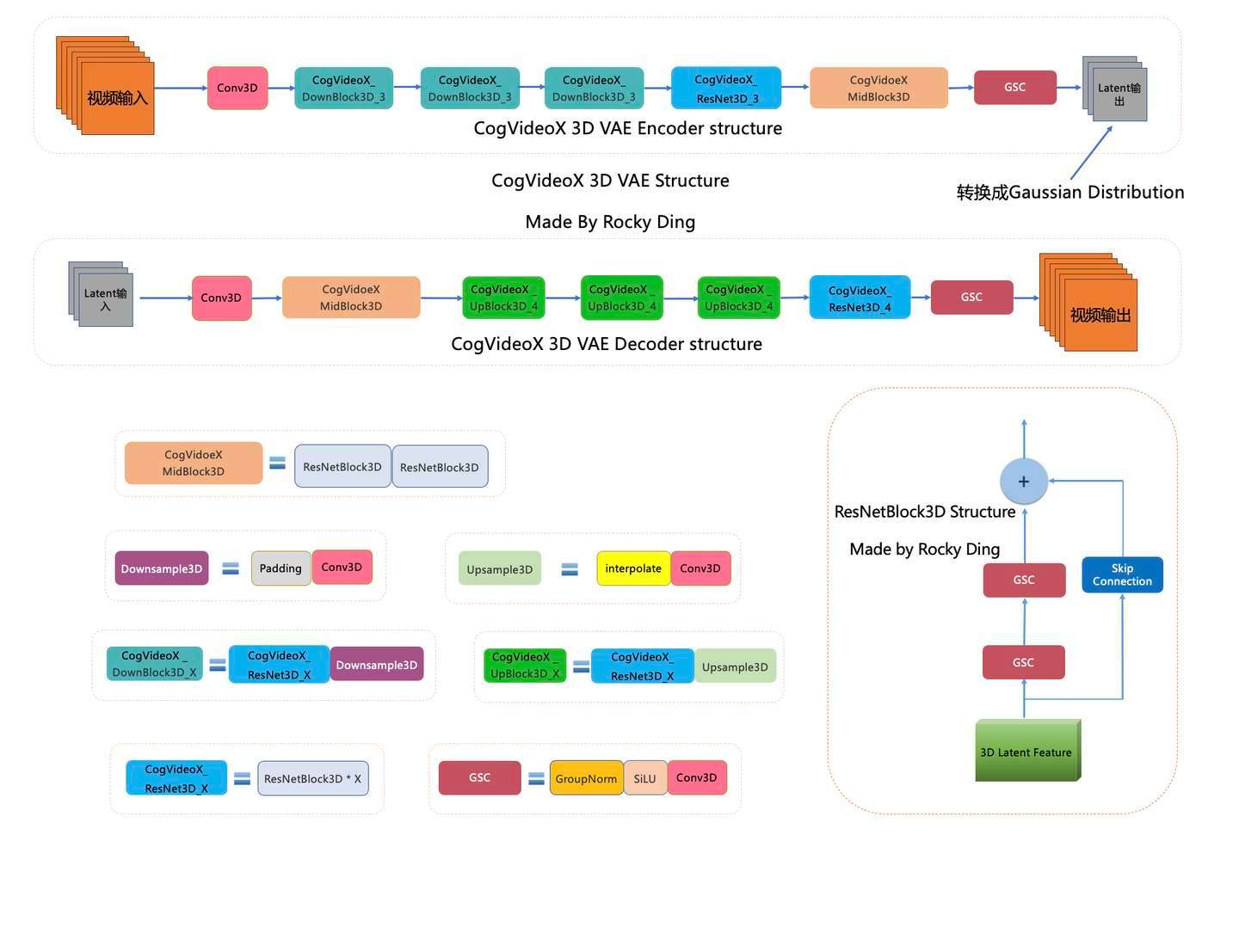
下图是Rocky梳理的CogVideoX 3D VAE的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习CogVideoX 3D VAE模型部分,相信大家脑海中的思路也会更加清晰:
【二】在CogVideoX系列模型中VAE是如何训练的?
为了节省计算资源并提高模型的泛化能力,CogVideoX系列模型在3D VAE的训练过程中设计了两阶段的训练策略:
第一阶段:在低分辨率和较少帧的视频数据(短视频)上训练3D VAE模型,这样既能让模型学习到基础的视频编码和解码能力,同时也节省了计算资源。经过第一阶段的训练后,3D VAE模型在较大分辨率的编码上有较好的泛化能力,但是在扩展要编码的帧数时则不那么顺畅。
第二阶段:在长视频上进行进一步微调训练。使用上下文并行的方法,在长视频上继续训练3D VAE模型,使其能够处理更多的视频帧数,同时保持高效的显存使用。
3D VAE模型的两个阶段训练都使用了三种损失函数的加权组合,分别是:
- L2损失:衡量重建图像与原始图像之间的像素级差异。
- LPIPS感知损失:用于衡量重建图像与原始图像之间的感知差异,即从视觉感知的角度来评估重建质量。
- GAN损失:通过3D鉴别器,使用对抗训练策略,进一步提升重建图像的真实性。
深度学习基础
【一】ROPE(Rotary-Position-Embedding)位置编码有何特点?
ROPE(Rotary Position Embedding)位置编码是在Transformer模型中用于引入位置信息的技术,是一种高效且简洁的相对位置编码方法,它特别适用于在输入序列中引入相对位置信息。这种方法与传统的正弦-余弦位置编码不同,它通过对输入的高维特征空间进行旋转来编码相对位置,从而增强模型在处理序列时对位置信息的捕获能力。
ROPE(Rotary Position Embedding)位置编码的背景
在 Transformer 模型中,由于自注意力机制的性质,模型对输入序列的元素是无序的。这意味着在没有明确的位置编码机制的情况下,模型无法捕获序列中不同元素的相对顺序。因此,引入位置编码成为解决这一问题的重要手段。
位置编码 方法主要有两种:
- 绝对位置编码(如正弦-余弦编码):为每个输入序列位置提供一个唯一的位置编码向量,通常独立于内容。缺点是无法很好地捕获相对位置信息。
- 相对位置编码:能够直接捕捉输入序列中元素的相对位置信息,但往往涉及复杂的计算。
ROPE 则提出了一种新颖的编码方式,它通过直接操作特征向量(例如 Query 和 Key)的内部表示,来引入位置信息。这种方法不仅保留了相对位置信息,而且引入方式简单高效。
ROPE 的原理
ROPE 的基本思想是通过旋转输入向量的高维空间坐标来实现位置信息的引入。具体来说,它通过在Embeddings空间对输入序列的每个位置进行特征向量旋转,利用旋转矩阵操作引入位置信息。
1. 向量旋转公式
ROPE 的核心是将每个位置 i i i 的向量 x i x_i xi 经过一个旋转变换,这个旋转变换是基于位置的。假设我们有一个向量 x i = [ x i 1 , x i 2 , … , x i d ] x_i = [x_{i1}, x_{i2}, \dots, x_{id}] xi=[xi1,xi2,…,xid] ,其中 d d d 是嵌入维度。对于每一对 ( x i k , x i ( k + 1 ) ) (x_{ik}, x_{i(k+1)}) (xik,xi(k+1)) (即嵌入维度中连续的两个分量),ROPE 通过一个旋转矩阵来操作这些分量。旋转矩阵的基本形式为:
R ( θ ) = [ cos ( θ ) − sin ( θ ) sin ( θ ) cos ( θ ) ] \mathbf{R}(\theta) = \begin{bmatrix} \cos(\theta) & -\sin(\theta) \\ \sin(\theta) & \cos(\theta) \end{bmatrix} R(θ)=[cos(θ)sin(θ)−sin(θ)cos(θ)]
2. 位置编码操作
对于每个位置 i i i ,ROPE 使用一个角度 θ i \theta_i θi 来进行旋转。这个角度通常与输入位置有关,可以被设计成正弦函数形式:
θ i = i ⋅ BaseAngle ( k ) \theta_i = i \cdot \text{BaseAngle}(k) θi=i⋅BaseAngle(k)
其中, BaseAngle ( k ) \text{BaseAngle}(k) BaseAngle(k) 是一个基于嵌入维度索引 k k k 的函数,通常与频率相关。ROPE 在每个维度上执行这样的旋转,保证在高维嵌入空间中,位置信息通过这种旋转操作得以引入。
3. 应用到 Query 和 Key 向量
在 Transformer 的自注意力机制中,位置编码通常作用于 Query 和 Key 向量。ROPE 通过对这些向量进行旋转操作,使得它们在内积计算中自然地带有相对位置信息。
给定输入向量 q i q_i qi 和 k j k_j kj 分别表示 Query 和 Key 的向量,ROPE 会对它们进行如下的旋转操作:
q i ′ = R ( θ i ) q i q_i' = \mathbf{R}(\theta_i) q_i qi′=R(θi)qi
k j ′ = R ( θ j ) k j k_j' = \mathbf{R}(\theta_j) k_j kj′=R(θj)kj
这样,计算 Query 和 Key 内积时就会隐含序列的位置信息,从而使得模型能够在进行自注意力计算时捕获输入元素的相对位置关系。
ROPE 的优势
-
相对位置编码:与传统的绝对位置编码不同,ROPE 在自注意力计算时能自然捕获输入序列的相对位置信息,而无需显式计算每对位置的差异。这使得模型能够更好地处理长序列中的相对关系。
-
高效与简洁:ROPE 的实现仅需要对输入特征向量进行旋转变换,其计算开销远小于许多复杂的相对位置编码方法,且可以无缝集成到现有的 Transformer 架构中。
-
处理长序列能力:由于 ROPE 的位置编码机制基于频率,因此它对长序列的处理效果较好。相比绝对位置编码,ROPE 在处理更长序列时表现出更强的泛化能力。
具体例子
假设我们有一个嵌入维度为 4 的简单 Transformer 模型,其中每个输入位置上的特征向量是一个 4 维的向量。为了方便展示,我们将嵌入维度分成两对来应用 ROPE 旋转操作。
输入序列
考虑一个 3 个单词组成的输入序列,每个单词已经过嵌入操作,得到了 4 维向量表示:
- 单词1: x 1 = [ x 1 , 1 , x 1 , 2 , x 1 , 3 , x 1 , 4 ] x_1 = [x_{1,1}, x_{1,2}, x_{1,3}, x_{1,4}] x1=[x1,1,x1,2,x1,3,x1,4]
- 单词2: x 2 = [ x 2 , 1 , x 2 , 2 , x 2 , 3 , x 2 , 4 ] x_2 = [x_{2,1}, x_{2,2}, x_{2,3}, x_{2,4}] x2=[x2,1,x2,2,x2,3,x2,4]
- 单词3: x 3 = [ x 3 , 1 , x 3 , 2 , x 3 , 3 , x 3 , 4 ] x_3 = [x_{3,1}, x_{3,2}, x_{3,3}, x_{3,4}] x3=[x3,1,x3,2,x3,3,x3,4]
假设我们以位置 1、位置 2、位置 3 对应于这三个单词在序列中的索引位置。
1. ROPE 的旋转矩阵
在 ROPE 中,位置编码通过旋转嵌入向量来完成。为了简单起见,我们将嵌入维度分为两对,每对两个分量组成的 2 维向量。对于每一对,我们使用旋转矩阵来引入位置相关的变化。
对于任意嵌入维度的两个连续分量 ( x i k , x i ( k + 1 ) ) (x_{ik}, x_{i(k+1)}) (xik,xi(k+1)) ,旋转公式如下:
[ x i k ′ x i ( k + 1 ) ′ ] = [ cos ( θ i ) − sin ( θ i ) sin ( θ i ) cos ( θ i ) ] [ x i k x i ( k + 1 ) ] \begin{bmatrix} x_{ik}' \\ x_{i(k+1)}' \end{bmatrix}= \begin{bmatrix} \cos(\theta_i) & -\sin(\theta_i) \\ \sin(\theta_i) & \cos(\theta_i) \end{bmatrix} \begin{bmatrix} x_{ik} \\ x_{i(k+1)} \end{bmatrix} [xik′xi(k+1)′]=[cos(θi)sin(θi)−sin(θi)cos(θi)][xikxi(k+1)]
其中, θ i \theta_i θi 是一个与位置 i i i 相关的旋转角度。为了直观起见,我们假设角度 θ i \theta_i θi 为简单的线性函数 θ i = i ⋅ BaseAngle \theta_i = i \cdot \text{BaseAngle} θi=i⋅BaseAngle 。
我们以 BaseAngle = 0.5 \text{BaseAngle} = 0.5 BaseAngle=0.5 为例:
- 位置1: θ 1 = 0.5 \theta_1 = 0.5 θ1=0.5
- 位置2: θ 2 = 1.0 \theta_2 = 1.0 θ2=1.0
- 位置3: θ 3 = 1.5 \theta_3 = 1.5 θ3=1.5
2. 应用旋转操作
接下来,假设我们分别对 x i x_i xi 的前两个分量和后两个分量应用旋转矩阵。具体步骤如下:
位置 1 的向量 x 1 = [ x 1 , 1 , x 1 , 2 , x 1 , 3 , x 1 , 4 ] x_1 = [x_{1,1}, x_{1,2}, x_{1,3}, x_{1,4}] x1=[x1,1,x1,2,x1,3,x1,4]
对于前两个分量 [ x 1 , 1 , x 1 , 2 ] [x_{1,1}, x_{1,2}] [x1,1,x1,2] ,使用旋转角度 θ 1 = 0.5 \theta_1 = 0.5 θ1=0.5 进行旋转:
[ x 1 , 1 ′ x 1 , 2 ′ ] = [ cos ( 0.5 ) − sin ( 0.5 ) sin ( 0.5 ) cos ( 0.5 ) ] [ x 1 , 1 x 1 , 2 ] \begin{bmatrix} x_{1,1}' \\ x_{1,2}' \end{bmatrix}= \begin{bmatrix} \cos(0.5) & -\sin(0.5) \\ \sin(0.5) & \cos(0.5) \end{bmatrix} \begin{bmatrix} x_{1,1} \\ x_{1,2} \end{bmatrix} [x1,1′x1,2′]=[cos(0.5)sin(0.5)−sin(0.5)cos(0.5)][x1,1x1,2]
假设计算后得到新的分量 x 1 , 1 ′ x_{1,1}' x1,1′ 和 x 1 , 2 ′ x_{1,2}' x1,2′ 。
对于后两个分量 [ x 1 , 3 , x 1 , 4 ] [x_{1,3}, x_{1,4}] [x1,3,x1,4] ,同样应用旋转矩阵,使用相同的角度 θ 1 = 0.5 \theta_1 = 0.5 θ1=0.5 进行旋转,得到新的分量 x 1 , 3 ′ x_{1,3}' x1,3′ 和 x 1 , 4 ′ x_{1,4}' x1,4′ 。
位置 2 的向量 x 2 = [ x 2 , 1 , x 2 , 2 , x 2 , 3 , x 2 , 4 ] x_2 = [x_{2,1}, x_{2,2}, x_{2,3}, x_{2,4}] x2=[x2,1,x2,2,x2,3,x2,4]
对于前两个分量 [ x 2 , 1 , x 2 , 2 ] [x_{2,1}, x_{2,2}] [x2,1,x2,2] ,使用旋转角度 θ 2 = 1.0 \theta_2 = 1.0 θ2=1.0 :
[ x 2 , 1 ′ x 2 , 2 ′ ] = [ cos ( 1.0 ) − sin ( 1.0 ) sin ( 1.0 ) cos ( 1.0 ) ] [ x 2 , 1 x 2 , 2 ] \begin{bmatrix} x_{2,1}' \\ x_{2,2}' \end{bmatrix}= \begin{bmatrix} \cos(1.0) & -\sin(1.0) \\ \sin(1.0) & \cos(1.0) \end{bmatrix} \begin{bmatrix} x_{2,1} \\ x_{2,2} \end{bmatrix} [x2,1′x2,2′]=[cos(1.0)sin(1.0)−sin(1.0)cos(1.0)][x2,1x2,2]
得到新的分量 x 2 , 1 ′ x_{2,1}' x2,1′ 和 x 2 , 2 ′ x_{2,2}' x2,2′ 。
对于后两个分量 [ x 2 , 3 , x 2 , 4 ] [x_{2,3}, x_{2,4}] [x2,3,x2,4] ,同样应用旋转矩阵,使用相同的角度 θ 2 = 1.0 \theta_2 = 1.0 θ2=1.0 进行旋转。
位置 3 的向量 x 3 = [ x 3 , 1 , x 3 , 2 , x 3 , 3 , x 3 , 4 ] x_3 = [x_{3,1}, x_{3,2}, x_{3,3}, x_{3,4}] x3=[x3,1,x3,2,x3,3,x3,4]
对位置3也执行相同的操作,使用 θ 3 = 1.5 \theta_3 = 1.5 θ3=1.5 对这四个分量进行两次旋转。
3. 将旋转后的向量应用于自注意力机制
完成旋转操作后,我们得到了所有位置向量的旋转结果。这些旋转后的向量 x 1 ′ , x 2 ′ , x 3 ′ x_1', x_2', x_3' x1′,x2′,x3′ 将被输入到自注意力机制中进行后续计算。
在自注意力机制中,位置编码通常会应用于 Query 和 Key 向量,这样在计算 Query 和 Key 的内积时,不同位置的向量由于旋转的不同,会带有位置信息。因此,内积不仅考虑到向量的内容,还隐含了序列中不同位置间的相对关系。这种方式帮助模型捕获输入序列中的相对位置信息,而无需显式地为每对位置编码计算差异。
4. 相对位置信息的捕获
ROPE 位置编码的独特之处在于,它通过旋转每个输入向量的方式,隐含地将相对位置信息注入到自注意力计算中。由于旋转角度 θ i \theta_i θi 是与位置 i i i 相关的,每个位置的特征向量在内积计算时都携带了位置信息,而内积的结果将反映不同位置向量之间的相对位置信息。
在这个例子中,位置 1、位置 2 和位置 3 的旋转角度不同,因此当这些向量用于计算自注意力时,不同位置的旋转特性会影响最终的注意力权重,从而让模型更好地理解输入序列中元素的相对位置。
【二】深度学习中模型权重融合有哪些主流的方法?
在深度学习中,模型权重融合(Model Weight Fusion)是指将多个模型的参数(权重)进行合并或融合,旨在提高模型的性能或实现模型压缩。权重融合的方法在模型集成、知识蒸馏、联邦学习等场景中具有广泛应用。以下是一些主流的权重融合方法:
1. 简单加权平均法 (Simple Weight Averaging)
-
原理:通过对多个模型的权重取加权平均,生成一个融合后的新模型。
-
公式:
W fused = 1 N ∑ i = 1 N W i W_{\text{fused}} = \frac{1}{N} \sum_{i=1}^N W_i Wfused=N1i=1∑NWi
其中, W i W_i Wi 是第 i i i 个模型的权重, N N N 是模型的数量。
-
应用场景:
- 联邦学习(Federated Learning):每个客户端训练本地模型,服务器通过聚合客户端模型权重来更新全局模型。
- 模型集成:结合多个相似结构的模型来生成更具鲁棒性的模型。
2. 线性插值法 (Linear Interpolation)
-
原理:给定两个模型,通过在它们的权重空间中进行线性插值生成新的模型。
-
公式:
W fused = α W 1 + ( 1 − α ) W 2 W_{\text{fused}} = \alpha W_1 + (1 - \alpha) W_2 Wfused=αW1+(1−α)W2
其中, W 1 W_1 W1 和 W 2 W_2 W2 是两个模型的权重, α \alpha α 是插值系数,通常取值在 [ 0 , 1 ] [0,1] [0,1] 之间。
-
应用场景:
- 在优化模型时,用于平衡两个模型之间的性能表现,特别是在权重空间中寻找局部最优解。
3. 逐层融合 (Layer-wise Fusion)
- 原理:通过逐层将多个模型的权重进行融合,而不是全局地直接对所有权重进行加权平均。
- 步骤:
- 对应层的权重矩阵或张量进行加权平均或其他操作。
- 每层都可以使用不同的融合方法。
- 应用场景:
- 在具有相同架构的模型之间融合时效果较好。
- 常用于知识蒸馏或模型压缩,逐层传递知识。
4. 基于权重相似性的融合 (Weight Similarity-based Fusion)
- 原理:基于多个模型的权重相似性来确定融合方式。通过计算不同模型权重的距离,调整不同模型的权重融合比例。
- 常用方法:
- 计算每个层权重的余弦相似性(Cosine Similarity)或欧氏距离(Euclidean Distance),来确定如何调整每个模型的权重贡献。
- 应用场景:
- 当模型结构相似但参数值差异较大时,利用权重相似性可以更智能地融合模型。
- 特别适用于使用不同数据集或不同初始化训练得到的模型。
5. 知识蒸馏 (Knowledge Distillation)
- 原理:知识蒸馏是通过训练一个“小模型”(学生模型)来逼近一个或多个“大模型”(教师模型)的行为,而不是直接融合权重。虽然这并非直接的权重融合,但可以看作是一种权重迁移的方式。
- 步骤:
- 使用教师模型生成软标签(Soft Targets),学生模型通过匹配这些软标签来学习教师模型的知识。
- 蒸馏过程中,学生模型的权重逐渐逼近教师模型的权重表示。
- 应用场景:
- 模型压缩:将大模型(如 BERT、GPT 等)蒸馏为较小的模型,适合在资源有限的设备上部署。
- 提高小模型的性能:在不增加复杂度的情况下,提升轻量模型的表现。
6. 联邦学习中的聚合方法 (Federated Averaging - FedAvg)
-
原理:联邦学习中,多个客户端在本地训练各自的模型,然后将模型权重发送到服务器,服务器通过加权平均的方式生成全局模型。
-
公式:
W global = ∑ i = 1 N n i n W i W_{\text{global}} = \sum_{i=1}^N \frac{n_i}{n} W_i Wglobal=i=1∑NnniWi
其中, n i n_i ni 是第 i i i 个客户端的样本数量, n n n 是所有客户端样本数量的总和。
-
应用场景:
- 联邦学习:用于保护数据隐私的分布式训练方法,数据存留在本地,每个客户端只发送模型权重到服务器进行聚合。
7. 最优化方法 (Optimization-based Fusion)
- 原理:通过最优化方法找到多个模型权重的最佳组合,最大化某个目标函数(例如交叉熵、精度等)。常见方法包括基于梯度下降的优化。
- 步骤:
- 定义一个目标函数来度量模型融合后的表现。
- 使用优化算法(如SGD、Adam)迭代更新融合后的权重,直到目标函数收敛。
- 应用场景:
- 适合在融合时需要考虑模型性能的情境。
- 通常用于复杂模型的组合优化。
8. 剪枝后的权重融合 (Pruned Model Fusion)
- 原理:首先对模型权重进行剪枝(即移除不重要的权重),然后对剪枝后的模型进行融合。
- 步骤:
- 先对多个模型进行剪枝,保留重要权重。
- 对保留的权重进行加权平均或其他融合操作。
- 应用场景:
- 模型压缩:通过剪枝和权重融合相结合,可以大大减少模型的存储和计算量,同时保持性能。
9. 弹性融合 (Elastic Weight Consolidation, EWC)
-
原理:EWC 是一种用于避免灾难性遗忘(catastrophic forgetting)的技术,尤其是在多任务学习中。它通过计算模型参数的重要性,并对重要参数施加较大的正则化项,来约束模型在新任务上的训练过程中不偏离原有权重太多。
-
公式:
L = L new task + λ 2 ∑ i F i ( θ i − θ i , old task ∗ ) 2 L = L_{\text{new task}} + \frac{\lambda}{2} \sum_i F_i (\theta_i - \theta^*_{i,\text{old task}})^2 L=Lnew task+2λi∑Fi(θi−θi,old task∗)2
其中, F i F_i Fi 是 Fisher 信息矩阵,代表参数 θ i \theta_i θi 的重要性, θ old task ∗ \theta^*_{\text{old task}} θold task∗ 是旧任务中的最优权重。
-
应用场景:
- 多任务学习:特别是连续学习(continual learning)中的权重融合,确保模型在学习新任务时不会遗忘旧任务的知识。
机器学习基础
【一】介绍一下总变分损失的概念与作用
在图像生成和图像处理领域,总变分损失(Total Variation Loss,简称TV损失)是一种常用的正则化方法,旨在减少生成图像中的噪声和不必要的细节,从而获得更加平滑和自然的结果。它在风格迁移、图像超分辨率、生成对抗网络(GAN)等应用中起到了重要作用。
理解总变分损失的概念和作用,可以帮助我们在实际应用中更好地构建和优化图像生成模型,提升生成图像的质量。
一、什么是总变分损失?
1. 总变分(Total Variation)的概念
总变分最初是数学分析中的一个概念,用于衡量一个函数在其定义域内变化的总量。在图像处理中,总变分用于衡量图像像素值在空间上的变化程度。
简单来说,总变分就是图像中所有像素之间差异的总和。如果一幅图像的总变分值较大,意味着图像中有较多的细节和噪声;如果总变分值较小,说明图像更平滑,细节和噪声较少。
2. 总变分损失的定义
在深度学习中,总变分损失是通过计算相邻像素之间的差异来定义的,其目的是鼓励生成的图像在空间上更加平滑,减少过度的噪声和纹理。
总变分损失通常表示为:
L T V = ∑ i , j ( ( I i , j − I i + 1 , j ) 2 + ( I i , j − I i , j + 1 ) 2 ) β 2 L_{TV} = \sum_{i,j} \left( (I_{i,j} - I_{i+1,j})^2 + (I_{i,j} - I_{i,j+1})^2 \right)^{\frac{\beta}{2}} LTV=i,j∑((Ii,j−Ii+1,j)2+(Ii,j−Ii,j+1)2)2β
- I i , j I_{i,j} Ii,j 表示图像中第 i i i 行第 j j j 列像素的值。
- β \beta β 是一个超参数,通常取值为1。
二、为什么需要总变分损失?
1. 减少噪声和伪影
在图像生成过程中,模型可能会生成一些不必要的噪声和伪影,使得图像看起来不自然。总变分损失通过惩罚相邻像素之间的过大差异,鼓励图像的平滑性,减少噪声。
2. 保持图像的整体结构
虽然总变分损失鼓励平滑,但它不会过度模糊图像,因为它只惩罚相邻像素之间的过大差异,而不会影响整体的图像结构和重要的细节。
3. 平衡细节和平滑性
在生成图像时,我们希望图像既有足够的细节,又不会因为噪声过多而影响视觉效果。总变分损失帮助模型在细节和平滑性之间取得平衡。
三、总变分损失是如何工作的?
1. 计算相邻像素差异
总变分损失通过计算图像中每个像素与其右边和下边像素的差异,然后将这些差异的平方和累加起来。
- 水平差异: ( I i , j − I i + 1 , j ) 2 (I_{i,j} - I_{i+1,j})^2 (Ii,j−Ii+1,j)2
- 垂直差异: ( I i , j − I i , j + 1 ) 2 (I_{i,j} - I_{i,j+1})^2 (Ii,j−Ii,j+1)2
2. 累加所有差异
将所有像素的水平和垂直差异累加,得到总变分损失。这代表了图像中像素值变化的总量。
3. 在损失函数中加入总变分损失
在训练模型时,将总变分损失作为损失函数的一部分,与其他损失(如内容损失、风格损失等)组合在一起。这样,模型在优化时会同时考虑生成图像的内容、风格和平滑性。
4. 调节权重
总变分损失通常会乘以一个权重系数,调节其在总损失中的影响力。通过调整这个权重,可以控制生成图像的平滑程度。
四、举例说明
1. 风格迁移中的应用
在风格迁移中,我们希望将一张内容图像的结构与另一张风格图像的纹理融合。总变分损失在这里用于:
- 减少噪声:防止生成的图像出现过多的随机纹理。
- 保持平滑性:使得生成的图像在视觉上更加连贯。
2. 图像超分辨率
在提高图像分辨率的任务中,总变分损失帮助模型生成更平滑的高分辨率图像,避免由于放大而产生的噪声。
五、注意事项
1. 过度平滑的问题
如果总变分损失的权重设置过高,可能会导致生成的图像过于平滑,丢失重要的细节。因此,需要在实验中找到合适的权重。
2. 与其他损失的平衡
总变分损失通常与其他损失函数一起使用,需要根据具体任务调整各个损失的权重,以达到最佳效果。
【二】介绍一下机器学习中的Nucleus采样原理
Nucleus 采样(Nucleus Sampling),也称为 Top-p 采样,是一种用于文本生成模型(如 GPT 系列模型)的采样策略,特别用于生成质量更高、更具多样性的文本。它通过动态调整生成候选集的大小,控制输出的质量和随机性。
1. 采样问题背景
在生成式任务中,如文本生成或对话系统,模型通常会在每个生成步骤从概率分布中选择一个单词。常见的策略有:
- 贪婪搜索:每一步选择概率最高的单词,容易导致重复和缺乏多样性。
- 随机采样:完全根据模型输出的概率分布随机选取,可能会导致生成无意义或语法不通的内容。
- Top-k 采样:仅从概率分布前 k 个最有可能的词中选择,而忽略剩下的候选词。这增加了一定的随机性,但 k 的值固定,可能忽略了一些罕见但有意义的词。
为了在 质量 和 多样性 之间取得更好的平衡,Nucleus 采样 应运而生。
2. Nucleus 采样原理
Nucleus 采样并不是简单地选择前 k 个最可能的词,而是根据一个动态的概率阈值 p p p 来决定候选集的大小。它的具体操作如下:
-
计算概率分布:给定模型在当前时间步的输出概率分布。
-
排序并累加概率:将词按照模型给出的概率从高到低排序,然后从最高概率开始累积这些概率值,直到累积的概率达到设定的阈值 p p p 。
-
采样候选集:生成的候选集是累积概率超过 p p p 的那一部分词。接下来,从这个候选集中根据概率分布随机采样。
因此,Nucleus 采样是基于累积概率的动态调整策略,它确保候选词集合足够灵活,包含那些对生成质量至关重要的高概率词,同时也保留了低概率但可能有创意的词。
3. 与 Top-k 采样的区别
-
Top-k 采样:Top-k 采样是从前 k 个最有可能的词中采样,忽略了剩下的词。而无论总概率分布如何,k 是一个固定的整数。它的局限性在于,k 的选择可能过小,限制了生成的多样性,或者过大,导致生成质量下降。
-
Nucleus 采样(Top-p 采样):Nucleus 采样动态选择候选词的数量,通过一个累积概率阈值 p。随着 p 的变化,候选词集合可以根据上下文自动扩展或收缩,因此比 Top-k 更灵活、更适应不同的生成情境。
4. p 值的影响
-
较小的 p:如果设定的 p p p 很小(接近 0.1 或 0.2),模型将只会从极少数的高概率词中选择,输出将趋于确定,类似贪婪搜索的效果。这会提高文本的连贯性和语法正确性,但可能缺乏多样性和创意。
-
较大的 p:如果设定的 p p p 较大(如 0.9),候选词集合会更大,包含更多低概率词,增加生成的随机性和多样性。这可能使文本生成更具创意和新颖性,但也可能会增加生成不连贯或无意义内容的风险。
5. Nucleus 采样的优势
-
灵活性:Nucleus 采样能够根据不同上下文动态调整候选集的大小,在保证生成质量的同时,增加文本的多样性。
-
避免冗余或无意义的选择:与 Top-k 不同,Nucleus 采样不会固定从 k 个词中采样,它会在保证语义连贯的前提下,选择最有意义的词进行采样。
-
平衡性:它提供了灵活的平衡机制,既能控制生成的连贯性和语法正确性,又能通过随机性保持生成内容的丰富性。
6. 实际应用场景
Nucleus 采样常用于生成式语言模型中,如 GPT-3、GPT-4 等,它可以生成对话、文本扩展等任务。通过调整 p 值,开发者可以控制模型输出的创造性和连贯性。比如:
- 在写作辅助场景中,可以设置较大的 p 值,鼓励模型生成具有创意的内容。
- 在对话系统中,较小的 p 值可能更适合,让模型的回答更加精确和连贯。
7. 示例代码
以下是一个使用 PyTorch 的简单示例,展示如何实现 Nucleus 采样。
import torch
def nucleus_sampling(logits, p):
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(torch.softmax(sorted_logits, dim=-1), dim=-1)
# 选出累积概率大于 p 的部分
cutoff_index = torch.where(cumulative_probs > p)[0][0]
filtered_logits = sorted_logits[:cutoff_index + 1]
filtered_indices = sorted_indices[:cutoff_index + 1]
# 在这些候选集中进行采样
sampled_index = torch.multinomial(torch.softmax(filtered_logits, dim=-1), 1)
return filtered_indices[sampled_index]
# 假设 logits 是一个表示词的概率的张量,下面的代码会从中进行 Nucleus 采样
logits = torch.tensor([0.1, 0.2, 0.05, 0.4, 0.15, 0.1])
p = 0.85 # 累积概率阈值
selected_word_index = nucleus_sampling(logits, p)
print(selected_word_index)
Python编程基础
【一】python中文件有哪些打开模式,它们的区别是什么?
在 Python 中,文件操作是通过内建的 open() 函数实现的,而打开文件时可以指定不同的模式来决定如何对文件进行读写操作。这些模式主要控制文件是否是以文本模式或二进制模式打开,文件是否是只读、只写、读写,或者是否从文件末尾追加内容等。
以下是 Python 文件打开模式的种类和区别:
1. 基本打开模式
-
'r':只读模式(默认模式)- 打开一个文件用于读取。如果文件不存在,则会抛出
FileNotFoundError错误。 - 文件指针会放在文件的开头,文件内容不可写入。
- 适合用于读取文本文件。
f = open('file.txt', 'r') - 打开一个文件用于读取。如果文件不存在,则会抛出
-
'w':写入模式- 打开一个文件用于写入。如果文件已存在,则会清空文件内容(覆盖原有内容),如果文件不存在,则会创建该文件。
- 文件指针会放在文件的开头。
f = open('file.txt', 'w') -
'a':追加模式- 打开一个文件用于写入。如果文件不存在,则会创建一个新文件。如果文件存在,则会从文件末尾开始追加内容(不会覆盖文件中的已有数据)。
- 文件指针位于文件末尾。
f = open('file.txt', 'a') -
'x':独占写入模式- 打开一个文件用于写入。如果文件已存在,则会抛出
FileExistsError错误。这个模式可以避免意外覆盖已存在的文件。
f = open('file.txt', 'x') - 打开一个文件用于写入。如果文件已存在,则会抛出
2. 文本与二进制模式
-
't':文本模式(默认模式)- 文件以文本形式打开。读取或写入时,处理的是字符串类型(
str)。此模式下,会自动处理文件中的换行符(如\n和\r\n)以适应不同操作系统的换行符格式。
f = open('file.txt', 'rt') # 读取文本文件,等价于 'r' - 文件以文本形式打开。读取或写入时,处理的是字符串类型(
-
'b':二进制模式- 文件以二进制形式打开。读取或写入时,处理的是字节类型(
bytes)。在处理图片、音频、视频等非文本文件时,通常使用二进制模式。
f = open('file.bin', 'rb') # 读取二进制文件 - 文件以二进制形式打开。读取或写入时,处理的是字节类型(
3. 组合模式
-
'r+':读写模式- 打开一个文件用于读写。文件必须存在,否则会抛出
FileNotFoundError错误。可以同时读取和写入文件,文件指针位于文件开头。
f = open('file.txt', 'r+') - 打开一个文件用于读写。文件必须存在,否则会抛出
-
'w+':读写模式(写入)- 打开一个文件用于读写。如果文件存在,则会清空文件内容;如果文件不存在,则会创建新文件。可以同时读取和写入文件。
f = open('file.txt', 'w+') -
'a+':读写模式(追加)- 打开一个文件用于读写。如果文件不存在,则会创建该文件。如果文件存在,则从文件末尾开始追加内容,但仍可以读取文件中的已有内容。
- 文件指针位于文件末尾。
f = open('file.txt', 'a+') -
'x+':读写模式(独占创建)- 创建一个文件用于读写。如果文件已存在,则抛出
FileExistsError。同时支持读写操作。
f = open('file.txt', 'x+') - 创建一个文件用于读写。如果文件已存在,则抛出
4. 文件模式总结
| 模式 | 描述 |
|---|---|
'r' | 只读,文件必须存在 |
'w' | 写入,文件不存在则创建,存在则覆盖 |
'a' | 追加写入,文件不存在则创建 |
'x' | 创建文件并写入,文件存在则抛出错误 |
't' | 文本模式(默认) |
'b' | 二进制模式 |
'+' | 读写模式 |
【二】python字典和json字符串如何相互转化?
在 AI 行业中,Python 的字典(dict) 和 JSON 字符串 是非常常用的数据结构和格式。Python 提供了非常简便的方法来将字典与 JSON 字符串相互转化,主要使用 json 模块中的两个函数:json.dumps() 和 json.loads()。
1. 字典转 JSON 字符串
将 Python 字典转换为 JSON 字符串使用的是 json.dumps() 函数。
示例:
import json
# Python 字典
data_dict = {
'name': 'AI',
'type': 'Technology',
'year': 2024
}
# 转换为 JSON 字符串
json_str = json.dumps(data_dict)
print(json_str)
输出:
{"name": "AI", "type": "Technology", "year": 2024}
json.dumps()参数:indent:可以美化输出,指定缩进级别。例如json.dumps(data_dict, indent=4)会生成带缩进的 JSON 字符串。sort_keys=True:会将输出的 JSON 键按字母顺序排序。ensure_ascii=False:用于处理非 ASCII 字符(如中文),避免转换为 Unicode 形式。
2. JSON 字符串转字典
要将 JSON 字符串转换为 Python 字典,可以使用 json.loads() 函数。
示例:
import json
# JSON 字符串
json_str = '{"name": "AI", "type": "Technology", "year": 2024}'
# 转换为 Python 字典
data_dict = json.loads(json_str)
print(data_dict)
输出:
{'name': 'AI', 'type': 'Technology', 'year': 2024}
3. 字典与 JSON 文件的转换
在实际项目中,可能需要将字典保存为 JSON 文件或从 JSON 文件读取字典。json 模块提供了 dump() 和 load() 方法来处理文件的输入输出。
将字典保存为 JSON 文件:
import json
data_dict = {
'name': 'AI',
'type': 'Technology',
'year': 2024
}
# 保存为 JSON 文件
with open('data.json', 'w') as json_file:
json.dump(data_dict, json_file, indent=4)
从 JSON 文件读取为字典:
import json
# 从 JSON 文件中读取数据
with open('data.json', 'r') as json_file:
data_dict = json.load(json_file)
print(data_dict)
4. 处理特殊数据类型
在 Python 中,JSON 数据类型与 Python 数据类型基本对应,但是某些特殊类型(如 datetime、set)需要自定义处理,因为 JSON 不支持这些类型。可以通过自定义编码器来处理。
例如,处理 datetime:
import json
from datetime import datetime
# Python 字典包含 datetime 类型
data = {
'name': 'AI',
'timestamp': datetime.now()
}
# 自定义编码器
class DateTimeEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat()
return super(DateTimeEncoder, self).default(obj)
# 转换为 JSON 字符串
json_str = json.dumps(data, cls=DateTimeEncoder)
print(json_str)
模型部署基础
【一】介绍一下torch、torchvision、CUDA、cuDNN之间的关系
Torch、Torchvision、CUDA 和 cuDNN 是在AI领域研发中紧密相关的组件。它们共同作用,尤其是在 PyTorch 生态系统中,用于加速神经网络模型的开发与训练。下面是它们之间的详细关系解释:
1. PyTorch(Torch)
- PyTorch 是一个开源的深度学习框架,简化了神经网络的构建、训练和推理过程。Torch 是 PyTorch 的核心模块,它提供了张量操作(类似于 NumPy,但支持 GPU 加速)、自动微分和神经网络模块。
- PyTorch 支持自动梯度计算,允许在 GPU 上快速进行张量操作和模型训练,这正是通过 CUDA 和 cuDNN 的支持来实现 GPU 加速。
2. Torchvision
- Torchvision 是 PyTorch 的官方扩展库,专门用于计算机视觉领域。它包含:
- 数据集加载器:如 CIFAR-10、ImageNet 等常见的数据集。
- 预训练模型:如 ResNet、VGG 等常用的卷积神经网络(CNN),可以直接加载并使用,适合迁移学习。
- 图像处理工具:包括图像的增广(如裁剪、翻转、旋转等),便于在训练过程中进行数据增强。
- Torchvision 和 PyTorch 一起使用时,数据加载、图像处理和模型定义的操作可以无缝结合。而 GPU 加速依赖于 PyTorch 内部的 CUDA 调用。
3. CUDA
- CUDA(Compute Unified Device Architecture)是由 NVIDIA 提供的并行计算平台和 API,它使得开发者可以通过编程,利用 NVIDIA GPU 来加速计算密集型任务,特别是在神经网络训练中。
- 在 PyTorch 中,CUDA 提供了 GPU 运算的基础支持。通过 CUDA,PyTorch 可以在 GPU 上进行张量操作、反向传播和其他矩阵运算,从而大大加快神经网络的训练速度。
- PyTorch 中通过
tensor.cuda()或.to('cuda')的方式,可以将模型或者张量转移到 GPU 上执行。所有张量运算将利用 CUDA 实现,显著提高性能。
4. cuDNN
- cuDNN(CUDA Deep Neural Network Library)是 NVIDIA 提供的一个用于加速深度神经网络的 GPU 加速库。它专为神经网络中的常见操作进行了高度优化,特别是卷积运算、池化、归一化和激活函数。
- cuDNN 的作用:在训练深度学习模型时,卷积神经网络的核心操作是卷积,这些操作需要大量的矩阵运算,而 cuDNN 可以大幅优化这些运算的效率。PyTorch 使用 cuDNN 来加速这些关键操作,使得卷积层等计算密集的部分可以快速运行。
- cuDNN 与 CUDA 的区别:CUDA 是一个更通用的 GPU 编程框架,而 cuDNN 是专门为深度学习设计的高效库,依赖 CUDA 进行低级 GPU 操作。CUDA 提供了基本的并行计算支持,cuDNN 则在这个基础上进一步优化了深度学习相关的运算。
四者之间的关系:
- PyTorch(Torch):是深度学习框架,负责张量计算、自动微分和神经网络构建。它是最顶层的框架,使用 CUDA 和 cuDNN 来加速深度学习任务。
- Torchvision:是 PyTorch 的扩展库,专注于计算机视觉,提供了预处理工具、预训练模型和常见数据集。它与 PyTorch 紧密集成,所有操作可以在 PyTorch 的基础上执行,并且同样可以通过 CUDA 和 cuDNN 加速。
- CUDA:用于 GPU 加速,提供了并行计算的能力。PyTorch 通过 CUDA 来实现 GPU 上的张量运算、反向传播等操作。
- cuDNN:专为深度学习设计的高效加速库,针对卷积、池化等操作进行高度优化。PyTorch 使用 cuDNN 来优化卷积网络中的计算。
形象理解:
- PyTorch 就像是汽车的发动机,负责处理所有的操作(如张量运算、自动微分等),它为深度学习提供了基础的功能。
- Torchvision 是给汽车加上的额外组件,如汽车的 GPS、音响系统,它专门用于计算机视觉任务,提供了常用的图像处理工具和模型。
- CUDA 是汽车的动力系统(类似汽车的燃油系统),它给 PyTorch 提供了加速的能力,使得计算可以在 GPU 上高效运行。
- cuDNN 是汽车的涡轮增压器,特别针对深度学习任务进行优化,进一步提升了计算速度。
实际应用中的协同工作:
假设你正在训练一个图像分类的卷积神经网络(CNN)模型,你的典型流程可能如下:
- 使用 Torchvision 从
CIFAR-10数据集中加载训练数据,并对图像进行预处理。 - 构建一个卷积神经网络模型(例如 ResNet),使用 PyTorch 来定义模型结构。
- 使用 CUDA 将模型和训练数据转移到 GPU 上,通过并行计算加速训练。
- 在训练过程中,模型中的卷积操作由 cuDNN 提供优化,使得卷积层的前向传播和反向传播都能快速进行。
示例代码
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 使用 Torchvision 加载 CIFAR-10 数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# 构建一个简单的卷积神经网络
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3) # 卷积层
self.pool = nn.MaxPool2d(2, 2) # 池化层
self.fc1 = nn.Linear(16 * 6 * 6, 10) # 全连接层
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = x.view(-1, 16 * 6 * 6)
x = self.fc1(x)
return x
# 使用 CUDA 将模型移到 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = SimpleCNN().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(2): # 多次循环遍历数据集
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device) # 将数据转移到 GPU
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 优化
running_loss += loss.item()
print(f"Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}")
【二】介绍一下XPU、MLU、MUSA各自的特点
XPU、MLU 和 MUSA 都是不同的硬件加速器架构,各自由不同的公司开发并用于加速 AI 和高性能计算任务。它们的主要功能是通过专门设计的硬件来加速大规模计算任务,特别是在AIGC、传统深度学习、自动驾驶等领域。以下是对每个加速器架构的详细介绍和它们的特点:
1. XPU(Cross Processing Unit)
-
背景:XPU 通常用作 Intel 的新一代可扩展异构计算平台的统称,涵盖了不同的硬件架构,用于处理 AI、数据分析和高性能计算任务。Intel 的 XPU 通过整合 CPU、GPU、FPGA 和专用 AI 加速器(如 Nervana 或 Habana)等硬件,实现广泛的计算场景支持。
-
特点:
- 异构计算:XPU 的主要特点是它能够支持异构计算,即在同一计算框架中结合 CPU、GPU、FPGA 和其他 AI 加速硬件来提高计算性能。
- 通用性强:XPU 设计的核心是通用计算,能够支持从数据中心到边缘设备的各种计算需求。
- 软件兼容性:借助 oneAPI,Intel 提供了一个统一的编程平台,使开发者能够使用单一代码库来开发支持不同硬件加速的应用程序,这大大简化了异构计算的开发复杂度。
-
应用领域:
- 高性能计算(HPC)
- AI 加速(如训练和推理任务)
- 数据分析和处理
2. MLU(Machine Learning Unit)
-
背景:MLU 是由中国公司 寒武纪科技(Cambricon)开发的专用机器学习处理器,专门用于加速深度学习和 AI 相关的任务。MLU 处理器通常部署在数据中心、云计算平台和边缘计算设备中。
-
特点:
- AI 加速优化:MLU 是为 AI 任务优化的芯片,特别擅长深度学习模型的训练和推理任务。与传统的 GPU 不同,它是专门为处理神经网络计算所设计的。
- 自定义架构:寒武纪在设计 MLU 架构时,采用了针对神经网络计算的定制硬件,使其在神经网络计算时比传统的通用处理器更高效。
- 高吞吐量与能效比:MLU 的设计目标是提供高吞吐量,并在大规模并行计算中保持较高的能效比。这使得 MLU 特别适合在数据中心进行大规模深度学习任务的处理。
-
应用领域:
- 数据中心 AI 加速
- 边缘计算设备
- 云端 AI 服务
3. MUSA(Machine Unified Smart Accelerator)
-
背景:MUSA 是由 摩尔线程(Moore Threads)开发的一种 AI 加速架构。摩尔线程是一家中国的半导体公司,致力于开发用于高性能图形渲染和 AI 计算的图形处理器和加速器。
-
特点:
- 多功能性:MUSA 是一种智能加速器,能够同时支持图形渲染和 AI 计算任务。与单纯的 AI 加速器不同,MUSA 兼具 AI 和图形处理能力,适合图形计算与 AI 场景结合的应用。
- 可编程性:MUSA 支持丰富的编程模型,可以通过不同的 API 和框架来进行开发,适合需要自定义计算任务的用户。
- AI 与图形渲染结合:MUSA 特别适合在图形处理和 AI 推理需要同时进行的场景中发挥作用,比如在实时渲染和 AI 驱动的增强现实、虚拟现实(AR/VR)应用中。
-
应用领域:
- 高性能图形渲染
- AI 推理加速
- 混合场景应用,如游戏、虚拟现实、增强现实
三者的对比:
- XPU 更倾向于异构计算,强调广泛的适用性,并结合了多种计算架构(CPU、GPU、FPGA 等)。
- MLU 专注于 AI 计算任务,特别是AI模型的训练和推理,适用于大规模 AI 计算场景。
- MUSA 则是一种结合了图形处理和 AI 计算的加速器,适合图形密集型任务和 AI 计算的混合场景,如游戏和虚拟现实中的 AI 增强效果。
计算机基础
Rocky从工业界、应用界、竞赛界以及学术界角度出发,总结沉淀AI行业中需要用到的实用计算机基础知识,不仅能在面试中帮助到我们,还能让我们在日常工作中提高效率。
【一】介绍一下AI行业中的API以及具体的作用
API(Application Programming Interface,应用程序编程接口)是一组定义和协议,用于构建和集成软件应用程序。它允许不同的软件系统相互通信和数据交换,提供了标准化的接口,简化了开发过程。
在人工智能(AI)行业中,API通常指AI服务提供商向开发者开放的接口,允许他们调用预训练的AI模型和算法,例如:
- AIGC:图像生成、视频生成、文本对话、音频生成等。
- 传统深度学习:图像识别、物体检测、面部识别、文本分析、情感分析、机器翻译。
- 自动驾驶:车载智能服务、车载娱乐服务等。
这些API使开发者无需从头开始训练复杂的AI模型,就能将先进的AI功能集成到自己的应用程序或服务中。
API的具体作用:
-
简化开发流程
- 降低技术门槛:开发者无需具备深厚的AI专业知识即可使用先进的AI功能。
- 节省时间和资源:避免了从零开始训练和部署模型的繁琐过程。
-
加速产品上市
- 快速集成:通过API,AI功能可以迅速集成到现有产品中。
- 抢占市场先机:更快地推出具备AI功能的产品,提升竞争力。
-
促进创新
- 丰富功能组合:API提供多样化的AI能力,鼓励开发者探索新应用场景。
- 协同合作:标准化的接口促进了不同团队和组织之间的协作。
-
可扩展性和灵活性
- 按需调用:根据需求灵活调用不同的AI服务,支持业务的可扩展性。
- 资源优化:按使用量付费,优化成本。
-
持续更新和维护
- 技术迭代:API提供商负责模型的更新和优化,开发者可持续受益于最新技术。
- 降低维护成本:减少了对模型维护和基础设施管理的需求。
-
数据安全和合规性
- 安全保障:许多AI API内置了安全机制,确保数据传输和处理的安全性。
- 法规遵从:帮助企业满足数据隐私和合规要求。
实例举例:
-
OpenAI API
- 功能:提供GPT-4等大型语言模型的访问接口。
- 应用:文本生成、对话机器人、内容总结等。
-
Google Cloud AI APIs
- 功能:包括视觉分析、语言处理、语音识别等多种AI服务。
- 应用:图像标签、情感分析、语音转文字等。
-
Amazon Web Services(AWS)AI服务
- 功能:提供个性化推荐、欺诈检测、预测分析等。
- 应用:电商推荐系统、金融风险评估、库存预测等。
【二】Linux中修改用户权限的命令有哪些?
在Linux系统中,用户权限是保证系统安全和稳定运行的关键因素。正确理解和使用权限管理命令,可以有效地控制用户对系统资源的访问。通过chmod、chown、usermod等命令,可以精确地控制用户和组对文件、目录的访问权限。理解并正确使用这些命令,有助于维护系统的安全和稳定。
一、文件权限概述
在Linux系统中,每个文件和目录都有一组权限,定义了所有者(Owner)、所属组(Group)和其他用户(Others)对该文件或目录的访问权限。这些权限分为:
- 读(r):允许查看文件内容或列出目录内容。
- 写(w):允许修改文件内容或在目录中创建、删除文件。
- 执行(x):允许执行文件或进入目录。
权限可以通过两种方式表示:
- 符号表示法:使用
r、w、x字符表示权限。 - 数字表示法:使用八进制数字表示权限,例如
7表示rwx。
二、修改文件权限的命令:chmod
1. 基本用法
chmod命令用于改变文件或目录的权限。
chmod [选项] 模式 文件名
2. 符号表示法修改权限
使用符号表示法,可以针对所有者、所属组和其他用户分别修改权限。
- 符号说明:
u:文件所有者(user)g:文件所属组(group)o:其他用户(others)a:所有用户(all,等同于ugo)
- 操作符:
+:添加权限-:移除权限=:设置权限
示例:
# 给文件 owner.txt 的所有者添加执行权限
chmod u+x owner.txt
# 移除文件 group.txt 的所属组的写权限
chmod g-w group.txt
# 设置文件 all.txt 的所有用户权限为读和执行
chmod a=rx all.txt
3. 数字表示法修改权限
数字表示法使用三位八进制数字,每位数字对应所有者、所属组和其他用户的权限。
- 权限数值对应:
r:4w:2x:1
示例:
# 将文件 example.txt 的权限设置为所有者读写,所属组读,其他用户无权限
chmod 640 example.txt
# 将目录 mydir 的权限设置为所有用户可读写执行
chmod 777 mydir
三、修改文件所有者和所属组的命令:chown 和 chgrp
1. 修改文件所有者:chown
chown命令用于改变文件或目录的所有者。
chown [选项] 新所有者 文件名
示例:
# 将文件 example.txt 的所有者改为 user1
sudo chown user1 example.txt
# 递归修改目录 mydir 下所有文件的所有者为 user2
sudo chown -R user2 mydir
2. 修改文件所属组:chgrp
chgrp命令用于改变文件或目录的所属组。
chgrp [选项] 新组 文件名
示例:
# 将文件 example.txt 的所属组改为 group1
sudo chgrp group1 example.txt
# 递归修改目录 mydir 下所有文件的所属组为 group2
sudo chgrp -R group2 mydir
3. 同时修改所有者和所属组:chown 的组合用法
chown [新所有者][:新组] 文件名
示例:
# 将文件 example.txt 的所有者改为 user1,所属组改为 group1
sudo chown user1:group1 example.txt
# 仅修改所属组
sudo chown :group2 example.txt
四、修改用户账户权限的命令
1. 修改用户所属组:usermod
usermod命令用于修改用户账户属性,包括所属组、登录权限等。
添加用户到附加组
sudo usermod -aG 组名 用户名
示例:
# 将用户 user1 添加到组 sudo
sudo usermod -aG sudo user1
修改用户的主组
sudo usermod -g 组名 用户名
示例:
# 将用户 user1 的主组改为 group1
sudo usermod -g group1 user1
2. 修改组的信息:groupmod
groupmod命令用于修改组的属性。
sudo groupmod [选项] 组名
示例:
# 修改组 group1 的名称为 newgroup
sudo groupmod -n newgroup group1
五、管理用户和组
1. 添加用户:adduser 或 useradd
sudo adduser 用户名
2. 删除用户:deluser 或 userdel
sudo deluser 用户名
3. 添加组:addgroup 或 groupadd
sudo addgroup 组名
4. 删除组:delgroup 或 groupdel
sudo delgroup 组名
六、权限管理示例
1. 为用户赋予sudo权限
# 将用户 user1 添加到 sudo 组
sudo usermod -aG sudo user1
2. 限制用户对文件的访问
# 将文件 secret.txt 的权限设置为只有所有者可读写
chmod 600 secret.txt
3. 共享目录给特定组
# 创建组 sharegroup
sudo addgroup sharegroup
# 将用户 user1 和 user2 添加到 sharegroup
sudo usermod -aG sharegroup user1
sudo usermod -aG sharegroup user2
# 修改目录 sharedir 的所属组为 sharegroup
sudo chown :sharegroup sharedir
# 设置目录权限,使组成员可读写执行
chmod 770 sharedir
七、注意事项
- 谨慎使用
sudo:带有sudo的命令拥有超级用户权限,操作不当可能导致系统不稳定。 - 备份重要数据:在修改权限前,备份重要文件以防数据丢失。
- 最小权限原则:只赋予用户完成任务所需的最低权限,增强系统安全性。
- 定期检查权限:使用
ls -l命令查看文件权限,确保符合预期。
开放性问题
Rocky从工业界、应用界、竞赛界以及学术界角度出发,思考总结AI行业的一些开放性问题,这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入更深入的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】如何减少对下一个AIGC式的时代周期的错判率?
Rocky认为这是一个贯穿AI行业的本质问题,是每个AI行业从业者在整个职业生涯中都要持续思考的问题。
【二】如何减少对下一个OpenAI式公司的错判率?
Rocky认为这是一个非常有价值的本质问题,是每个AI行业从业者和投资者在整个职业生涯中都要持续思考的问题。
推荐阅读
1、加入AIGCmagic社区知识星球
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、ChatGPT等大模型、AI多模态、数字人、全行业AIGC赋能等50+应用方向,内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AIGC模型、AIGC数据集和源码等。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。知识星球原价:299元/年,前200名限量活动价,终身优惠只需199元/年。大家只需要扫描下面的星球优惠卷即可享受初始居民的最大优惠:


2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable DiffusionV1-V2核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1上手构建ControlNet高级应用等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
9、10万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能给个star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
10、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
11、GAN网络核心基础知识、深入浅出解析GAN在AIGC时代的应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
12、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











