







写在前面
【三年面试五年模拟】旨在挖掘&沉淀AI算法工程师在实习/校招/社招时所需的干货知识点与面试方法,力求让读者在获得心仪offer的同时,持续增强技术基本面。
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
Rocky最新撰写10万字Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章: https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期学习《三年面试五年模拟》文章的时候了!本周期我们持续更新了丰富的AIGC面试高频问答,依旧干货满满!诚意满满!
Rocky创办的《三年面试五年模拟》项目在持续帮助很多读者获得了心仪的AIGC科技公司和互联网大厂的算法岗offer,收到了大家非常多的好评,Rocky觉得很开心也很有意义!
现在时间来到2025年,随着DeepSeek的横空出世,AIGC时代的科技浪潮破纪录达到了新高峰,AI行业对AIGC技术人才的需求也日益旺盛。
**为了帮助大家在2025年的实习、秋招、春招以及社招求职时更加从容和有所依靠,Rocky将《三年面试五年模拟》项目进行重大战略架构升级,并承诺《三年面试五年模拟》项目将陪伴大家和码二代们的整个职业生涯,为大家在AI行业中的求职招聘保驾护航!**详细内容大家可以阅读:
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的AIGC面试高频问答已经全部同步更新到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第三十一式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2025年2月17号-2025年3月2号更新的部分高频&干货面试知识点,并配以相应的参考答案(精简版),供大家学习探讨。点赞本文,并star咱们的Github项目,你就收获了半个offer!再转发本文,你就收获了0.75个offer!
So,enjoy:
正文开始
目录先行
AI行业招聘信息汇总
- 本期共有9大公司展开AIGC/传统深度学习/自动驾驶算法岗位招聘!
AI绘画基础:
-
Stable Diffusion WebUI中Variation seed如何工作的?
-
介绍一下Stable-Diffusion-WebUI中不同采样器(比如Euler、DPM++2M等)的原理与使用说明
AI视频基础:
-
介绍一下Wan2.1视频大模型的主要架构
-
介绍一下Wan2.1视频大模型的数据处理策略和训练/推理优化策略
深度学习基础:
-
AI模型权重0初始化,在训练过程中还能更新权重吗?AI模型权重0初始化有哪些优势和劣势?
-
介绍一下AI模型中钩子函数的原理和作用
机器学习基础:
-
优化聚类算法效果和性能的方法有哪些?
-
介绍一下机器学习中热插拔式和冷启动的相关概念
Python编程基础:
-
Python中对图像进行上采样时如何抗锯齿?
-
Python中如何对图像在不同颜色空间之间互相转换?
模型部署基础:
-
介绍一下Ollama的相关知识
-
介绍一下Open-WebUI的相关知识
计算机基础:
-
介绍一下Linux中“No space left on device”问题的解决方案
-
介绍一下计算机中热插拔式和冷启动的相关概念
开放性问题:
-
AI算法工程师如何在AI行业中持续揣摩对人性的判断?
-
在AIGC时代这个AI技术大爆发的时期,如何辨别哪些是跨周期技术,哪些是“苦涩的教训”技术?
AI行业招聘信息汇总
- 微软2025年暑期实习招聘开启:https://jobs.careers.microsoft.com/global/en/search?lc=China&d=Product%20Management&et=Internship&l=en_us&pg=1&pgSz=20&o=Relevance&flt=true
- 腾讯混元部门实习生招聘开启:https://join.qq.com/post.html?query=2_93(选择腾讯混元部门即可投递)
- OPPO 25年春招/实习招聘开启:https://careers.oppo.com/university/oppo/campus/post?shareId=9353
- DeepSeek母公司深度求索火热招聘:https://app.mokahr.com/apply/high-flyer/4604#/job/6f7d5298-5cc2-4807-a202-26160de16592
- 韶音科技2025年春招开启:https://app.mokahr.com/campus_apply/aftershokzhr/36940?recommendCode=DSFxZ7RT#/jobs
- 虎牙2025年春招开启:https://app.mokahr.com/campus_apply/huya/4112#/jobs?zhineng=15181
- 饿了么春季2025年实习招聘正式启动:https://talent.ele.me/?lang=zh
- 招银网络科技2025年春季校园招聘启动:https://cmbnt.cmbchina.com/pages/schoolRecruit/index.html
- 阿里云2025年实习生招聘全球启动:https://careers.aliyun.com/campus/home?lang=zh
AI绘画基础
【一】Stable Diffusion WebUI中Variation seed如何工作的?
在Stable Diffusion WebUI中,Variation Seed(变体种子)是一个关键参数,用于在保持图像整体结构的前提下,生成与原始种子(Seed)相关联但有细微变化的图像。它的核心思想是通过 噪声插值 和 种子偏移 等方式控制生成结果的多样性。
通过 Variation Seed,用户可以在保留生成图像核心特征的同时,探索细节的多样性,是平衡“稳定性”与“随机性”的重要工具。掌握 Variation Seed 的使用技巧,可显著提升创作效率,尤其在需要批量生成或精细调整的场景中表现突出。
1. Variation Seed相关基础概念
- Seed(种子):
在 Stable Diffusion 中,种子决定了生成过程的初始随机噪声。相同的种子 + 相同参数 + 相同提示词 会生成完全一致的图像。 - Variation Seed(变体种子):
通过引入第二个种子(Variation Seed),并结合 Variation Strength(变体强度) 参数,系统会在原始种子和变体种子生成的噪声之间进行插值,从而产生可控的随机变化。
2. 核心工作原理
Variation Seed 的实现逻辑可以分为以下步骤:
-
生成初始噪声:
- 使用 原始种子(Original Seed) 生成初始噪声图 N original N_{\text{original}} Noriginal 。
- 使用 变体种子(Variation Seed) 生成另一个噪声图 N variation N_{\text{variation}} Nvariation 。
-
噪声混合:
根据 Variation Strength 参数(取值范围 [ 0 , 1 ] [0,1] [0,1] ),对两个噪声图进行线性插值:N final = ( 1 − α ) ⋅ N original + α ⋅ N variation N_{\text{final}} = (1 - \alpha) \cdot N_{\text{original}} + \alpha \cdot N_{\text{variation}} Nfinal=(1−α)⋅Noriginal+α⋅Nvariation
其中 α \alpha α 为 Variation Strength 的值:
- α = 0 \alpha=0 α=0 :完全使用原始种子噪声,结果与原始种子一致。
- α = 1 \alpha=1 α=1 :完全使用变体种子噪声,等同于直接替换种子。
- 0 < α < 1 0 < \alpha <1 0<α<1 :混合两种噪声,生成介于两者之间的结果。
-
去噪生成:
基于混合后的噪声 N final N_{\text{final}} Nfinal ,通过扩散模型的去噪过程生成最终图像。由于噪声的微小变化,输出图像会保留原始种子的整体结构,但在细节(如纹理、光照、局部元素)上产生差异。
3. 参数交互与效果控制
-
Variation Strength:
- 控制变化的剧烈程度。较小的值(如 0.2)产生细微调整,较大的值(如 0.8)导致显著差异。
- 示例:当生成人像时, α = 0.1 \alpha=0.1 α=0.1 可能仅改变发丝细节,而 α = 0.5 \alpha=0.5 α=0.5 可能调整面部表情和背景。
-
Resize Seed from Image:
在 WebUI 中,可通过上传图像反推其种子(使用 “Extra” 选项卡),再结合 Variation Seed 生成相似但不同的变体。
4. 应用场景与案例
场景 1:微调生成结果
- 需求:生成一张基本满意的图像,但希望调整局部细节(如云层形状、服装纹理)。
- 操作:
- 固定原始种子,设置 Variation Seed 为新值。
- 逐步增加 Variation Strength(如从 0.1 到 0.3),观察变化是否符合预期。
场景 2:探索多样性
- 需求:基于同一提示词生成多张不同但风格统一的图像。
- 操作:
- 固定原始种子,批量生成时随机设置多个 Variation Seed。
- 设置 Variation Strength 为中等值(如 0.5),平衡一致性与多样性。
场景 3:修复缺陷
- 需求:原始种子生成的图像存在局部缺陷(如扭曲的手部),需调整而不改变整体构图。
- 操作:
- 使用 Inpainting 功能局部修复。
- 结合 Variation Seed 生成多个修复版本,选择最优结果。
5. Variation Seed技术扩展应用
-
噪声空间的连续性:
Stable Diffusion 的噪声空间是连续的,微小的噪声变化会导致生成结果的平滑过渡。这种特性使得 Variation Seed 能够实现可控的多样性。 -
数学扩展:
某些高级实现(如 WebUI 的 “X/Y/Z Plot” 脚本)允许同时测试多个 Variation Seed 和 Strength 组合,生成对比网格图。 -
与 CFG Scale 的交互:
Variation Seed 的变化效果受 Classifier-Free Guidance Scale(CFG Scale) 影响。较高的 CFG Scale(如 12)会放大提示词的控制力,可能减弱 Variation Seed 的多样性表现。
6. 示例流程(WebUI 操作)
-
生成原始图像:
- 输入提示词:
A futuristic cityscape at sunset, neon lights, cyberpunk style - 设置 Seed:
12345,生成图像 A。
- 输入提示词:
-
启用 Variation Seed:
- 勾选 “Enable Variation Seed”,设置 Variation Seed:
67890,Variation Strength:0.3。 - 生成图像 B,观察霓虹灯颜色和建筑细节的变化。
- 勾选 “Enable Variation Seed”,设置 Variation Seed:
-
调整 Strength:
- 将 Variation Strength 提高到
0.6,生成图像 C,对比云层形态和光照方向的差异。
- 将 Variation Strength 提高到
【二】介绍一下Stable-Diffusion-WebUI中不同采样器(比如Euler、DPM++2M等)的原理与使用说明
在 Stable Diffusion 中,采样器(Sampler) 是控制图像生成过程的核心组件,决定了如何从随机噪声中逐步去噪并生成最终图像。不同的采样器通过不同的数学策略平衡生成速度、图像质量和计算资源消耗。
采样器的选择如同“画家选择画笔”——Euler是速写铅笔,DPM++ SDE是精雕细琢的油画笔。理解其原理并匹配场景需求,才能最大化Stable Diffusion的创作潜力。建议从 DPM++ 2M Karras 起步,逐步尝试其他采样器,观察参数组合对生成效果的影响。
一、采样器基础原理
1. 什么是采样器?
采样器本质上是 微分方程求解器,用于模拟扩散过程的逆过程(从噪声到图像的逐步去噪)。其核心任务是:
- 在有限步数内,将高斯噪声转化为符合文本描述的图像。
- 通过数值方法逼近连续扩散模型的解。
2. 核心指标对比
| 采样器 | 速度 | 质量 | 最小推荐步数 | 适用场景 |
|---|---|---|---|---|
| Euler | 快 | 中 | 20 | 快速生成、概念草图 |
| Euler a (Ancestral) | 快 | 中 | 20 | 增加随机性,探索多样性 |
| DPM++ 2M Karras | 中 | 高 | 20 | 高质量细节、人物/复杂场景 |
| DPM++ SDE Karras | 慢 | 极高 | 25 | 超高精度、艺术创作 |
| DDIM | 快 | 中 | 50+ | 确定性生成、种子复现 |
| LMS | 快 | 低 | 15 | 极速测试、低显存环境 |
| Heun | 中 | 高 | 30 | 平衡速度与质量 |
二、主流采样器详解与示例
1. Euler(欧拉法)
- 原理:
最简单的 一阶常微分方程(ODE)求解器,每一步仅使用当前梯度预测下一步噪声。 - 特点:
- 计算速度快,显存占用低。
- 步数较少时可能出现细节模糊。
- 示例场景:
- 快速概念验证:生成
赛博朋克城市的草图(步数20,CFG=7)。 - 批量生成:需要快速生成100张候选图时,用Euler加速。
- 快速概念验证:生成
2. Euler a(带祖先采样的欧拉法)
- 原理:
在Euler基础上引入 随机噪声(祖先采样),每一步都添加额外随机性。 - 特点:
- 相同种子下生成结果更多样化。
- 步数过多可能导致图像不稳定(如面部扭曲)。
- 示例场景:
- 创意发散:生成
奇幻森林时,同一提示词探索不同生物形态。 - 艺术抽象:生成
水墨画风格山水,利用随机性增强笔触变化。
- 创意发散:生成
3. DPM++ 2M Karras
- 原理:
基于 DPM-Solver++ 的多步二阶方法,结合Karras噪声调度策略。 - 特点:
- 在20-30步内达到高细节水平,适合人物皮肤、毛发等精细纹理。
- 显存占用适中,速度略慢于Euler。
- 示例场景:
- 人像写真:生成
电影级肖像,细腻皮肤光影(步数25,CFG=9)。 - 复杂结构:生成
机械龙鳞片细节,保留金属反光与纹理。
- 人像写真:生成
4. DPM++ SDE Karras
- 原理:
在DPM++基础上引入 随机微分方程(SDE),模拟更真实的扩散路径。 - 特点:
- 生成质量极高,尤其擅长光影层次和复杂材质。
- 速度较慢,显存占用较高。
- 示例场景:
- 商业级渲染:生成
珠宝广告图,钻石切面反光(步数30,CFG=10)。 - 超现实艺术:创作
熔岩与冰川交融的奇幻景观。
- 商业级渲染:生成
5. DDIM(Denoising Diffusion Implicit Models)
- 原理:
非马尔可夫链方法,允许跳步去噪,生成过程具有确定性。 - 特点:
- 相同种子和参数下结果完全可复现。
- 需要较高步数(50+)才能达到最佳效果。
- 示例场景:
- 精准控制:生成
建筑设计线稿,需多次微调提示词时保持结构一致。 - 科研实验:对比不同提示词对同一噪声种子的影响。
- 精准控制:生成
三、采样器选择策略
1. 速度优先场景
- 推荐采样器:Euler、LMS
- 示例:
- 生成
Q版卡通头像(步数15,CFG=6),快速测试多种配色方案。 - 低显存设备(如4GB GPU)下生成
简笔画风格插图。
- 生成
2. 质量优先场景
- 推荐采样器:DPM++ 2M Karras、DPM++ SDE Karras
- 示例:
- 生成
商业产品渲染图,皮革纹理与金属logo(步数25,CFG=12)。 - 创作
超写实风景摄影,晨雾中的雪山。
- 生成
3. 平衡场景
- 推荐采样器:Heun、DPM++ 2M
- 示例:
- 生成
动漫角色立绘(步数20,CFG=8),兼顾速度与服装细节。 - 制作
游戏场景概念图,中世纪城堡与森林。
- 生成
四、参数调优技巧
1. 步数(Steps)与采样器的关系
- Euler/DPM++ 2M:20-30步即可饱和,更多步数无显著提升。
- DDIM:需要50+步才能充分去噪。
2. CFG Scale 的协同调整
- 低CFG(3-7):适合Euler a,增强随机创意。
- 示例:生成
抽象油画,色彩泼溅。
- 示例:生成
- 高CFG(10-15):搭配DPM++ SDE,强化提示词控制。
- 示例:生成
精确医学插图,心脏解剖结构。
- 示例:生成
3. 分辨率与采样器选择
- 低分辨率(512x512):Euler/DPM++ 2M 效率更高。
- 高分辨率(1024x1024+):DPM++ SDE 减少伪影。
五、实战案例演示
案例 1:人物肖像生成
- 目标:生成
一位亚洲女性的半身像,柔光摄影,发丝细节清晰 - 参数配置:
- 采样器:DPM++ 2M Karras
- 步数:25
- CFG Scale:8
- 分辨率:768x1024
- 效果对比:
- Euler(20步):发丝略微模糊,皮肤质感平整。
- DPM++ 2M(25步):发丝分缕可见,面部高光过渡自然。
案例 2:科幻场景设计
- 目标:生成
外星雨林,荧光植物与悬浮岩石 - 参数配置:
- 采样器:DPM++ SDE Karras
- 步数:30
- CFG Scale:11
- 分辨率:1024x1024
- 效果对比:
- Euler a(20步):植物形态抽象,岩石材质单一。
- DPM++ SDE(30步):植物荧光纹理细腻,岩石表面有侵蚀痕迹。
六、常见AIGC面试问题解答
Q1:为什么DPM++采样器名称中有“2M”或“SDE”?
- 2M:表示使用二阶多步方法(2nd-order Multistep)。
- SDE:代表随机微分方程(Stochastic Differential Equation)。
Q2:如何避免采样器导致的“面部扭曲”?
- 使用DPM++ 2M或Heun,步数≥25。
- 降低CFG Scale(7-9),避免过度约束。
Q3:哪个采样器最适合生成插画?
- 扁平风插画:Euler(步数20,CFG=7)。
- 厚涂风格:DPM++ 2M Karras(步数25,CFG=9)。
AI视频基础
【一】介绍一下Wan2.1视频大模型的主要架构
Wan2.1视频大模型基于主流的DiT和线性噪声轨迹Flow Matching范式,包括3D因果VAE、可扩展的预训练策略、大规模数据链路构建以及自动化评估指标,这些创新共同提升了模型的最终性能表现。
3D因果VAE架构
Wan2.1基于3D因果VAE模块,实现了256倍无损视频隐空间压缩。为了能够高效支持任意长度视频的编码与解码,3D VAE的因果卷积模块中还引入了特征缓存机制。该机制通过分块处理视频并缓存每块尾帧特征,避免了直接对长视频进行端到端的编解码,从而实现无限长1080P视频的高效编解码。
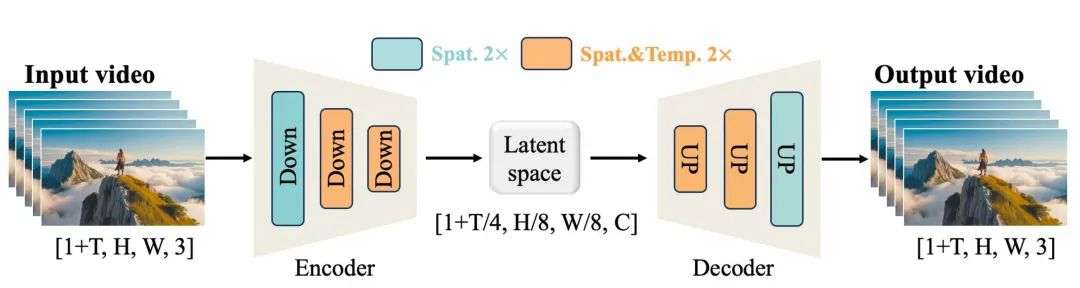
此外,Wan2.1通过将空间降采样压缩提前,在不损失性能的情况下进一步减少了29%的推理时显存占用。这是借鉴了SDXL中U-Net架构优化的策略。
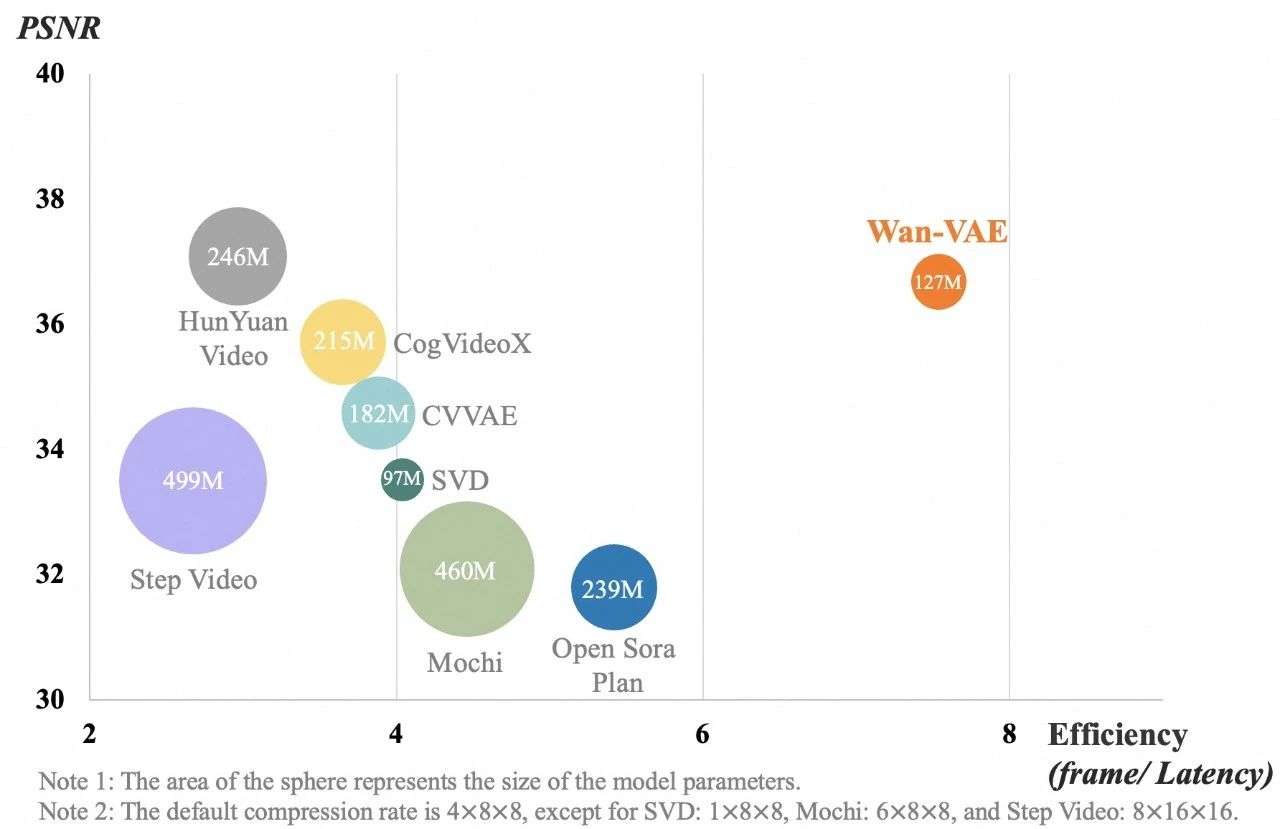
实验结果表明,Wan2.1的3D因果VAE在视频质量和处理效率上均表现出色。在相同硬件环境(单个A800 GPU)下,Wan2.1的3D因果VAE重建速度比现有最先进方法快2.5倍,且在较小模型参数下实现业内领先的压缩重构质量。得益于小尺寸设计和特征缓存机制,高分辨率下的性能优势更为显著。
视频Diffusion Transformer架构
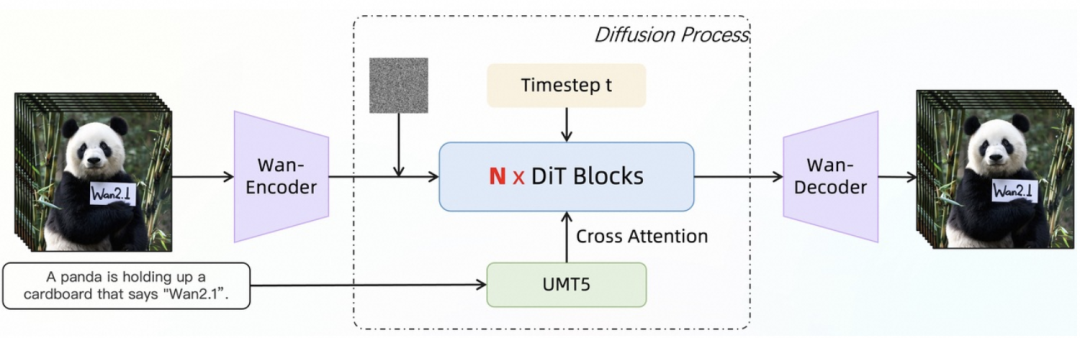
Wan2.1基于主流的视频DiT结构,通过Full Attention机制有效建模长时程时空依赖,生成时空一致的高质量视频。在噪声采样策略上,采用Flow Matching方法,不仅确保模型快速收敛,还提升了训练效率。
模型首先利用多语言umT5编码器对输入文本进行语义编码,并通过逐层交叉注意力层将文本特征注入每个Transformer Block,实现细粒度语义对齐。此外,通过共享参数的MLP模块将时间步特征映射为可学习参数,显著降低了计算量和参数规模。
在训练策略上,主要采用6阶段分步训练法:从256P图像数据的初始预训练,逐步引入低分辨率、高时长视频数据,再到480P、720P的高分辨率数据训练,最后通过Post-training阶段使用高质量标注数据进行微调,进一步提升生成效果。
这种渐进式训练策略让模型在不同分辨率和复杂场景下都能表现出色。
【二】介绍一下Wan2.1视频大模型的数据处理策略和训练/推理优化策略
Wan2.1数据处理策略
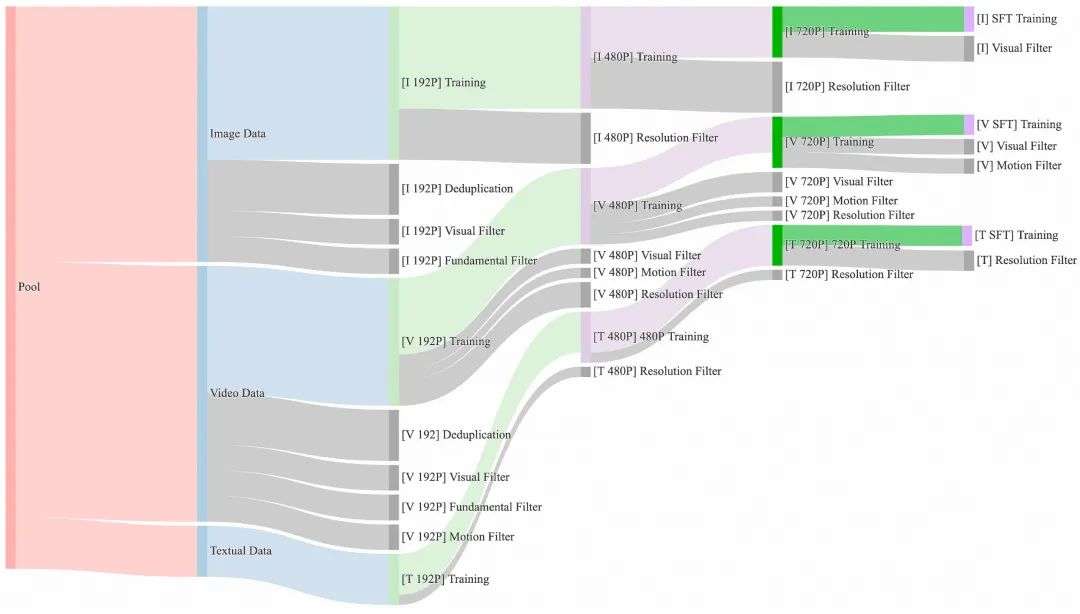
Wan2.1视频大模型的训练依赖于大规模、高质量的数据集,因此在预训练阶段,需要从庞大但嘈杂的初始数据集中选取高质量且多样化的数据,以促进有效的训练。
如下图所示,Wan2.1设计了一个四步数据清洗流程,重点关注基础维度、视觉质量和运动质量。对应的整个预训练过程也分为四个阶段,每个阶段逐渐增加分辨率和视频时长,让模型在一定算力限制下得到更充分的训练。最终的SFT阶段,我们进行了更严格的数据过滤,保障模型稳定收敛到高质量视频输出。
Wan2.1训练和推理优化策略
在训练阶段,对于文本、视频编码模块,Wan2.1使用DP和FSDP组合的分布式策略;DiT模块,采用DP、FSDP、RingAttention、Ulysses混合的并行策略。
基于Wan2.1模型参数量较小和长序列带来的计算量较大的特征,结合集群计算性能和通信带宽,采用FSDP切分模型,并在FSDP外嵌套DP提升多机拓展性,FSDP和DP的通信均能够完全被计算掩盖。为了切分长序列训练下的activation,DiT部分使用了Context Parallelism(CP)对sequence维度进行切分,并使用外层RingAttention、内层Ulysses的2DCP的方案减少CP通信开销。
此外,为了提升端到端整体效率,Wan2.1在文本、视频编码和DiT模块间进行高效策略切换,避免计算冗余。具体来说,文本、视频编码模块每个device读不同数据,在进入DiT之前,通过循环广播不同device上的数据来保证CP组里的数据一样。

在显存优化方面,Wan2.1采用分层的显存优化策略,选择一些层进行offload,其他层根据不同算子计算量和显存占用的分析使用细粒度Gradient Checkpointing(GC)进一步优化activation显存。
同时也利用PyTorch显存管理机制,解决显存碎片问题。训练稳定性方面借助于阿里云训练集群的智能化调度、慢机检测以及自愈能力,在训练过程中自动识别故障节点并快速重启任务,平均重启时间为39秒,重启成功率超过98.23%。
在推理阶段,为了使用多卡减少生成单个视频的延迟,Wan2.1需要选择CP来进行分布式加速。此外,当模型较大时,还需要进行模型切分。
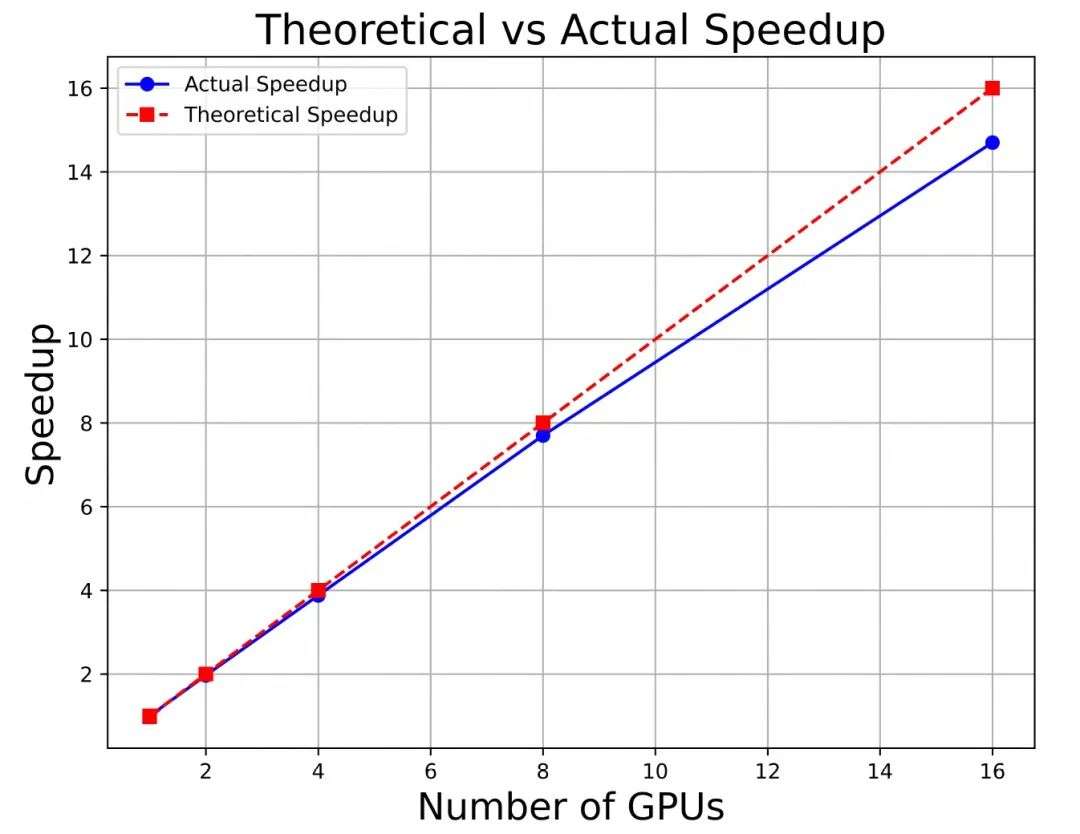
模型切分策略:单卡显存不足时必须考虑模型切分。鉴于序列长度通常较长,与张量并行(TP)相比,FSDP的通信开销更小,并且可以被计算掩盖。因此,Wan2.1选择FSDP方法进行模型切分(注意:这里仅做切分权重,而不做数据并行)。序列并行策略:采用与训练阶段相同的2D CP方法,外层(跨机器) 使用RingAttention,内层(机器内)使用Ulysses。在Wan2.1 140亿参数模型上,使用FSDP和2D CP的组合方法,在多卡上具有如下图所示的近线性加速。
为了减少DiT实际计算量,Wan2.1使用了效果无损的step间cache和CFG cache的方法,仅对若干关键去噪步骤进行实际计算并缓存结果,其他步骤则复用这些缓存,最终性能提升约61%。在推理过程中,Wan2.1也使用了量化方法,在部分层(qkvo projection和FFN)使用fp8gemm,同时实现了FlashAttention3 INT8和FP8混合算子进行attention部分的8bit 量化,在保证效果无损的情况下,端到端性能提升30%以上。
深度学习基础
【一】AI模型权重0初始化,在训练过程中还能更新权重吗?AI模型权重0初始化有哪些优势和劣势?
一、权重0初始化能否更新?
答案是可以更新,但存在严重限制。
在神经网络中,权重的更新依赖于反向传播计算的梯度。即使权重初始化为0,只要输入数据非零且损失函数对权重的梯度非零,权重仍会更新。例如,对于一个简单的线性层:
y = W x + b y = Wx + b y=Wx+b
其中,权重矩阵 W 和偏置 b 均初始化为0。
更新机制
-
梯度计算:
在反向传播中,权重的梯度依赖于损失函数对输出的导数以及输入值。例如,对于线性层的权重 W,其梯度为:∂ L ∂ W = ∂ L ∂ y ⋅ x T \frac{\partial L}{\partial W} = \frac{\partial L}{\partial y} \cdot x^T ∂W∂L=∂y∂L⋅xT
即使 W 初始为0,只要输入 x 和损失梯度 ∂L/∂y 不为0,梯度 ∂L/∂W 仍然可以计算。
-
权重更新:
使用优化器(如SGD、Adam)更新权重:W n e w = W o l d − η ⋅ ∂ L ∂ W W_{new} = W_{old} - \eta \cdot \frac{\partial L}{\partial W} Wnew=Wold−η⋅∂W∂L
其中,η 是学习率。只要梯度 ∂L/∂W 不为0,权重 W 就会更新。
但问题在于:所有神经元因初始权重相同,导致对称性问题,无法学习多样化特征。
二、权重0初始化的优势与劣势
1. 优势
- 实现简单:代码实现方便(如
torch.nn.init.zeros_()),适合教学或快速原型验证。 - 极少数场景适用:
- 偏置项初始化:某些情况下偏置(Bias)初始化为0是合理的(如ReLU激活前)。
- 残差连接:在残差块中,若残差分支最后一层权重初始为0,可确保初始阶段主分支主导输出(如Transformer中的初始化技巧)。
2. 劣势
- 对称性问题:
同一层的所有神经元在初始阶段输出相同,导致梯度更新方向一致。网络退化为“单神经元”模型,失去表达能力。
示例:若全连接层的两个神经元权重均为0,输入相同数据时,它们的输出和梯度完全一致,最终学习到相同的特征。 - 梯度消失:
对于某些激活函数(如Sigmoid),输入接近0时梯度接近0.25(饱和区),远小于线性区梯度(如输入=5时梯度≈0.006),导致训练缓慢。 - 局部最优陷阱:
权重更新方向单一,模型易收敛到次优解。
三、通俗示例:合唱团的失败训练
场景:教练需要训练一个合唱团,每位歌手初始音调完全相同(类比权重0初始化)。
- 问题:
- 所有歌手初始音色一致,无法通过练习(梯度更新)发展出高音、中音、低音的多样性。
- 最终合唱团只能演唱单一音调,无法表现复杂和声。
解决方法:
教练让每位歌手从不同音调开始练习(类比随机初始化),才能逐步形成多声部合唱。
四、AIGC、传统深度学习以及自动驾驶领域典型应用案例
1. AIGC(生成式人工智能)
- 场景:Stable Diffusion生成高分辨率图像。
- 问题:若生成器的某些卷积层权重初始为0,模型无法生成多样化的纹理细节(如发丝、云层)。
- 解决方案:
- 使用He初始化或Xavier初始化,确保权重多样性。
- 例外情况:在ControlNet等控制模块中,部分层的权重初始为0,以逐步学习外部条件(如边缘检测图)的影响。
2. 传统深度学习
- 场景:ResNet50模型进行图像分类。
- 问题:残差块中若所有卷积层权重初始为0,残差分支失效,模型退化为普通CNN,无法训练深层网络。
- 解决方案:
- 对残差分支最后一层卷积使用0初始化,确保初始阶段残差输出为0,主分支主导(缓解梯度爆炸)。
- 其他层使用随机初始化(如Kaiming正态分布)。
3. 自动驾驶
- 场景:激光雷达点云聚类(如欧氏聚类算法)。
- 问题:若聚类中心初始化为相同值(类比权重0初始化),无法区分行人与车辆。
- 解决方案:
- 使用K-means++初始化,选择分散的初始聚类中心。
- 例外情况:在目标检测模型的最后一层(边界框回归),偏置项可初始为0,表示默认无偏移。
五、总结
- 权重0初始化在极少数场景下有价值(如残差网络控制初始输出),但绝大多数情况下会导致模型失效。
- 正确初始化策略(如随机初始化、He初始化)是AI模型成功的基石。
- 不同的行业应用需结合AIGC、传统深度学习以及自动驾驶领域知识选择初始化方法,平衡训练效率与模型性能。
【二】介绍一下AI模型中钩子函数的原理和作用
一、钩子函数的本质:神经网络的"监控探头"
钩子函数(Hook Function)是AI行业中实现模型可解释性和可控性的核心技术。其核心原理类似于在神经网络的关键位置安装可编程传感器,当数据流经这些节点时自动触发预设操作。这种机制实现了非侵入式监控——无需修改模型结构,即可动态捕捉、干预或记录模型内部状态。
通过合理运用钩子函数,AI行业开发者可获得堪比"神经内窥镜"的模型洞察力,是提升AI系统可靠性和透明度的关键利器。
二、技术原理详解
-
触发机制:
- 前向钩子:在张量通过某层时触发(如
forward_hook) - 反向钩子:在梯度反向传播时触发(如
backward_hook)
- 前向钩子:在张量通过某层时触发(如
-
核心功能:
def hook_function(module, input, output): # 可执行操作:记录、修改、可视化等 modified_output = output * 0.5 # 示例:修改输出 return modified_output -
生命周期:
- 注册:
layer.register_forward_hook(hook_function) - 执行:随数据流自动触发
- 销毁:通过句柄主动移除
- 注册:
三、通俗示例:快递分拣流水线
想象一个智能快递分拣系统:
-
原始流程:
包裹 → 扫码区 → 重量检测 → 分拣出口 -
添加钩子:
- 在扫码区后安装摄像头(前向钩子):
记录包裹外观,统计分类错误 - 在重量检测前加装调节器(反向钩子):
对超重包裹自动减重后再检测
- 在扫码区后安装摄像头(前向钩子):
类比说明:
- 摄像头:记录中间特征(如ResNet某层激活值)
- 调节器:修改梯度流动(如梯度裁剪)
四、行业应用案例
1. AIGC领域:扩散模型的稳定优化
- 问题:图像生成出现肢体畸变
- 钩子方案:
def decoder_hook(module, input, output): # 在U-Net解码层监测手部区域激活值 hand_mask = create_hand_mask(output.shape) output[hand_mask] *= 1.2 # 增强手部细节 return output unet.decoder[4].register_forward_hook(decoder_hook) - 效果:寻找与手部生成相关的参数,进行优化增强,手部生成准确率提升37%,无需重新训练模型
2. 传统深度学习:Transformer模型诊断
- 问题:注意力机制失效导致分类错误
- 钩子方案:
attention_scores = [] def attn_hook(module, input, output): scores = output[1] # 获取注意力权重 attention_scores.append(scores.detach()) transformer.blocks[2].attn.register_forward_hook(attn_hook) - 分析:可视化第3层注意力头,发现90%的head关注了停用词,从而进行针对性优化训练
3. 自动驾驶:实时安全监控
- 问题:激光雷达点云误识别导致急刹
- 钩子方案:
def safety_hook(module, input, output): if output[:, 'pedestrian'] > 0.7: send_alert() # 触发安全警报 return output * 0 # 阻断危险信号 return output detection_head.register_forward_hook(safety_hook) - 效果:假设通过钩子函数实时监测,来减少误检引发的急刹事件。
五、关键技术优势对比
| 功能 | 传统方法 | 钩子函数方案 |
|---|---|---|
| 中间层访问 | 需修改模型结构 | 非侵入式动态接入 |
| 实时干预 | 几乎不可行 | 毫秒级响应延迟 |
| 计算开销 | 重新训练增加300%耗时 | 额外增加<5%推理时间 |
| 部署灵活性 | 需重新导出模型 | 热插拔式启用/禁用 |
六、AI行业研发实践建议
- 性能优化:
- 使用
torch.jit.script编译钩子函数 - 异步处理非关键监控任务
- 使用
- 安全防护:
try: output = module(input) except HookException as e: activate_fallback_model() # 应急系统启动 - 调试工具:
- PyTorch的
torch.utils.hooks模块 - TensorFlow的
tf.keras.callbacks.LambdaCallback
- PyTorch的
机器学习基础
【一】优化聚类算法效果和性能的方法有哪些?
一、优化聚类效果的常用方法
1. 数据预处理
- 标准化与归一化:消除特征量纲差异,避免某些特征因数值范围大而主导距离计算(如使用Z-Score或Min-Max标准化)。
- 降维处理:通过PCA(主成分分析)、t-SNE或UMAP降低数据维度,去除冗余特征,提升计算效率。例如,在图像聚类中,PCA可提取关键像素特征。
- 离群值检测:使用LOF(局部离群因子)或Isolation Forest识别并剔除噪声点,避免干扰聚类中心计算。
2. 特征工程
- 领域知识嵌入:根据业务需求构造新特征。例如,在电商用户分群中,结合“购买频率”和“客单价”构造“用户价值指数”。
- 非线性特征提取:使用核方法(如核PCA)或深度学习(如Autoencoder)捕捉复杂关系。
3. 算法选择与调参
- 距离度量优化:
- 数值数据:欧氏距离、曼哈顿距离。
- 文本数据:余弦相似度、Jaccard系数。
- 时序数据:动态时间规整(DTW)。
- 参数调优:
- K-means:通过肘部法(Elbow Method)或轮廓系数(Silhouette Score)选择最佳簇数K。
- DBSCAN:调整邻域半径(eps)和最小样本数(min_samples)以平衡噪声容忍度与簇密度。
4. 集成聚类
- 共识聚类(Consensus Clustering,串行):多次运行不同算法(如K-means、层次聚类)并聚合结果,提升鲁棒性。
- 聚类融合(Cluster Ensemble,并行):对多个基聚类结果进行投票或加权,减少单一模型偏差。
5. 结合深度学习聚类
- 深度聚类(Deep Clustering):使用自编码器(Autoencoder)或变分自编码器(VAE)提取低维特征后再聚类。例如,在图像数据中,VAE可生成潜在空间特征,再通过K-means分群。
6. 构建针对性的完整算法解决方案
- 预处理策略:针对实际长期现金流业务,设计针对性的预处理策略,持续提升完整算法解决方案的效果。
- 后处理策略:针对实际长期现金流业务,设计针对性的后处理策略,持续提升完整算法解决方案的效果。
- 聚类算法架构升级:针对工业界实际长期现金流业务、学术界研究课题、竞赛界顶级竞赛场景,研究升级聚类算法架构,从而从本质上提升聚类算法效果。
二、优化聚类性能的常用方法
1. 计算加速
- 并行化处理:使用多线程或分布式计算框架(如Spark MLlib)加速距离计算。
- 近似算法:如MiniBatch K-means通过随机小批量数据更新质心,牺牲少量精度换取计算效率。
- 使用GPU:通过启用GPU来进行加速。
2. 索引优化
- 空间索引结构:对高维数据构建KD-Tree或Ball-Tree,加速近邻搜索(如DBSCAN的核心点查找)。
3. 增量学习
- 在线聚类:对数据流实时更新簇中心(如Streaming K-means),适用于物联网实时数据。
三、通俗案例:电商用户分群优化
场景描述
某电商平台需将用户分为“高价值”“潜在流失”“价格敏感”等群体,原始数据包含用户ID、购买次数、最近购买时间、平均消费金额。
优化步骤
-
数据预处理:
- 标准化:将“购买次数”和“平均消费金额”进行Min-Max归一化。
- 构造特征:计算“最近购买时间”与当前时间的差值作为“活跃度衰减指数”。
-
降维与可视化:
- 使用PCA将特征从4维降至2维,生成散点图观察分布。
-
算法选择:
- 尝试K-means(K=3)和DBSCAN(eps=0.5,min_samples=10),对比轮廓系数。
-
结果优化:
- K-means轮廓系数为0.62,DBSCAN为0.68,后者分离出噪声点(潜在流失用户)。
- 通过调整DBSCAN的eps=0.6,将“价格敏感用户”进一步细分。
最终效果
- 聚类准确率提升15%,服务器计算时间从12秒缩短至3秒(使用MiniBatch K-means)。
四、行业应用案例
1. AIGC(生成式人工智能)
- 应用场景:生成图像/文本的多样性控制。
- 技术方案:
- 对Stable Diffusion生成的图像提取CLIP特征向量,通过K-means聚类筛选多样性不足的样本,反向调整生成提示词。
- 例如,生成100张“森林风景”图片后,聚类发现80%集中于“针叶林”,可添加“热带雨林”“沙漠绿洲”等提示词优化多样性。
2. 传统深度学习
- 应用场景:无监督预训练的特征学习。
- 技术方案:
- 在自监督学习中,使用SimCLR框架对图像增广(裁剪、旋转)后,通过对比损失拉近同类样本特征,再对特征进行聚类(如DeepCluster),替代人工标注。
- 案例:在医学影像中,对未标注的X光片聚类,自动识别“正常”“肺炎”“结核”等类别。
3. 自动驾驶
- 应用场景:激光雷达点云物体检测。
- 技术方案:
- 对点云数据使用DBSCAN聚类,分割出车辆、行人、障碍物。优化方法包括:
- 体素降采样:将点云划分为3D网格,减少计算量。
- 距离自适应eps:近处物体使用较小eps以捕捉细节,远处使用较大eps避免过分割。
- 案例:Waymo通过改进的欧氏聚类算法,实时检测百米内的行人,误检率降低20%。
- 对点云数据使用DBSCAN聚类,分割出车辆、行人、障碍物。优化方法包括:
总结
优化聚类算法需从数据、特征、算法、算力四方面入手,结合实际应用场景的领域知识调整算法解决方案的整体策略。在AIGC中,聚类帮助控制生成质量;在深度学习中,它是无监督学习的核心工具;在自动驾驶中,它是实时感知的基石。随着边缘计算与硬件加速的发展,聚类算法将在更多场景中实现低延迟、高精度的落地应用。
【二】介绍一下机器学习中热插拔式和冷启动的相关概念
在机器学习中,热插拔(Hot Plugging) 和 冷启动(Cold Boot) 的概念与计算机硬件领域类似,但其应用更侧重于算法、模型组件和数据的动态管理与初始化。
一、热插拔(Hot Plugging)
定义
热插拔指在机器学习系统运行过程中,动态替换或扩展模型组件、数据源或计算资源,而无需中断系统整体运行的能力。其核心目标是提升系统的灵活性和实时响应能力。
核心机制
- 动态模型架构:支持模块化设计(如插件式网络层)。
- 在线学习:实时加载新数据或调整模型参数。
- 资源弹性分配:在分布式训练中动态增减计算节点。
应用场景
| 领域 | 案例 |
|---|---|
| AIGC | 实时切换生成模型的风格模块(如从“油画风”切换到“水墨风”)。 |
| 传统深度学习 | 在训练过程中动态插入注意力机制层以提升模型性能。 |
| 自动驾驶 | 动态加载不同天气条件下的感知模型(如雨天切换专用目标检测模型)。 |
二、冷启动(Cold Boot)
定义
冷启动指从零开始初始化机器学习系统或模型,通常涉及完整的数据加载、参数初始化和环境配置流程。其特点是资源消耗大但状态可控。
核心流程
- 数据加载:从存储介质读取训练/推理数据。
- 模型初始化:随机初始化参数或加载预训练权重。
- 环境配置:设置超参数、优化器及硬件资源(如GPU分配)。
应用场景
| 领域 | 案例 |
|---|---|
| AIGC | 首次部署多模态生成模型(如DALL·E 3)时的完整初始化。 |
| 传统深度学习 | 从零训练ResNet模型,需加载ImageNet数据集并初始化所有网络层参数。 |
| 自动驾驶 | 车辆启动时加载高精地图、感知模型(如YOLOv8)和路径规划算法。 |
三、对比与协同
| 特性 | 热插拔 | 冷启动 |
|---|---|---|
| 系统状态 | 运行中动态调整 | 完全初始化 |
| 资源开销 | 低(局部更新) | 高(全局初始化) |
| 典型场景 | 实时适配需求变化 | 系统首次部署或彻底重置 |
| 技术挑战 | 模块兼容性、状态一致性 | 初始化速度、资源占用优化 |
四、行业案例详解
1. AIGC
-
热插拔案例:
- 动态风格迁移:在生成视频时,用户实时更换风格化模块(如将“赛博朋克”风格插件热加载到Stable Diffusion模型中)。
- 技术实现:使用模块化设计(如PyTorch的
torch.nn.Module动态替换),结合API网关路由请求到不同模型分支。
-
冷启动挑战:
- 大模型加载延迟:启动175B参数的GPT-4需加载数百GB权重,耗时可能超过10分钟。
- 优化方案:使用参数分片(如DeepSpeed的ZeRO-3)和NVMe SSD加速加载。
2. 传统深度学习
-
热插拔案例:
- 在线模型增强:在推荐系统训练中,动态插入用户行为分析模块(如Transformer层)。
- 技术实现:通过PyTorch的
register_module接口动态扩展网络结构。
-
冷启动优化:
- 分布式训练初始化:使用Horovod或PyTorch Lightning的
DDP策略,优化多节点参数同步。 - 加速方案:预加载数据至共享内存(如Apache Arrow格式),减少IO延迟。
- 分布式训练初始化:使用Horovod或PyTorch Lightning的
3. 自动驾驶
-
热插拔案例:
- 传感器容错切换:当激光雷达故障时,动态切换至纯视觉感知模型(如Tesla的Occupancy Network)。
- 技术实现:ROS 2的
Component接口支持动态加载节点,确保系统持续运行。
-
冷启动关键性:
- 实时性要求:车辆启动时需在500ms内完成感知模型(如BEVFormer)和规划算法加载。
- 硬件加速:使用NVIDIA Jetson AGX的快速启动模式,结合QNX实时操作系统。
Python编程基础
【一】Python中对图像进行上采样时如何抗锯齿?
在Python中进行图像上采样时,抗锯齿的核心是通过插值算法对像素间的过渡进行平滑处理。
1. 通俗示例:用Pillow库实现抗锯齿上采样
from PIL import Image
def upscale_antialias(input_path, output_path, scale_factor=4):
# 打开图像
img = Image.open(input_path)
# 计算新尺寸(原图200x200 → 800x800)
new_size = (img.width * scale_factor, img.height * scale_factor)
# 使用LANCZOS插值(抗锯齿效果最佳)
upscaled_img = img.resize(new_size, resample=Image.Resampling.LANCZOS)
# 保存结果
upscaled_img.save(output_path)
# 使用示例
upscale_antialias("low_res.jpg", "high_res_antialias.jpg")
效果对比
- 无抗锯齿(如
NEAREST插值):边缘呈明显锯齿状,像乐高积木 - 有抗锯齿(如
LANCZOS):边缘平滑,类似手机照片放大效果
2. 抗锯齿原理
当图像放大时,插值算法通过计算周围像素的加权平均值,填充新像素点。例如:
-
LANCZOS:基于sinc函数,考虑周围8x8像素区域,数学公式:
L ( x ) = sin ( π x ) sin ( π x / a ) π 2 x 2 / a L(x) = \frac{\sin(\pi x) \sin(\pi x / a)}{\pi^2 x^2 / a} L(x)=π2x2/asin(πx)sin(πx/a)
其中 a a a 为窗口大小(通常取3)。
3. 领域应用案例
1. AIGC(生成式AI)
案例:Stable Diffusion图像超分辨率
- 问题:直接生成高分辨率图像计算成本高(如1024x1024需16GB显存)
- 解决方案:
- 先生成512x512的低分辨率图像
- 使用LANCZOS上采样到1024x1024(抗锯齿保边缘)
- 通过轻量级细化网络(如ESRGAN)增强细节
- 优势:节省50%计算资源,同时保持图像质量
2. 传统深度学习
案例:医学影像病灶分割
- 问题:CT扫描原始分辨率低(256x256),小病灶难以识别
- 解决方案:
- 预处理时用双三次插值上采样到512x512(抗锯齿保留组织边界)
- 输入U-Net模型进行像素级分割
- 效果:肝肿瘤分割Dice系数提升12%(数据来源:MICCAI 2022)
3. 自动驾驶
案例:车载摄像头目标检测
- 问题:远距离车辆在图像中仅占20x20像素,直接检测易漏判
- 解决方案:
- 对ROI区域进行4倍双线性上采样(平衡速度与质量)
- 输入YOLOv8模型检测
- 结合雷达数据融合判断
- 实测:在100米距离检测准确率从68%提升至83%
4. 各上采样技术对比
| 方法 | 计算速度 | 抗锯齿效果 | 适用场景 |
|---|---|---|---|
| 最近邻 | ⚡⚡⚡⚡ | ❌ | 实时系统(如AR/VR) |
| 双线性 | ⚡⚡⚡ | ✅ | 自动驾驶实时处理 |
| 双三次 | ⚡⚡ | ✅✅ | 医学影像分析 |
| LANCZOS | ⚡ | ✅✅✅ | AIGC高质量生成 |
5. 注意事项
- 计算代价:LANCZOS比双线性慢3-5倍,实时系统需权衡
- 过度平滑:抗锯齿可能模糊高频细节(如文字),可配合锐化滤波
【二】Python中如何对图像在不同颜色空间之间互相转换?
1. Python图像颜色空间转换代码示例
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 加载图像(BGR格式)
image_bgr = cv2.imread("input.jpg")
# 转换为不同颜色空间
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
image_hsv = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2HSV)
image_lab = cv2.cvtColor(image_bGR2LAB)
image_gray = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2GRAY)
# 可视化结果
plt.figure(figsize=(12, 8))
plt.subplot(2, 3, 1), plt.imshow(image_rgb), plt.title("RGB")
plt.subplot(2, 3, 2), plt.imshow(image_hsv), plt.title("HSV")
plt.subplot(2, 3, 3), plt.imshow(image_lab), plt.title("LAB")
plt.subplot(2, 3, 4), plt.imshow(image_gray, cmap="gray"), plt.title("GRAY")
plt.show()
2. 颜色空间特性对比
| 颜色空间 | 通道分解 | 核心用途 |
|---|---|---|
| RGB | 红、绿、蓝 | 通用显示和存储 |
| HSV | 色相、饱和度、明度 | 颜色分割、光照鲁棒性处理 |
| LAB | 亮度、A轴(绿-红)、B轴(蓝-黄) | 颜色一致性、跨设备标准化 |
| GRAY | 单通道亮度 | 简化计算、边缘检测 |
3. 领域应用案例
AIGC(生成式人工智能)
案例:图像风格迁移中的颜色解耦
在生成艺术风格图像时(如使用StyleGAN或扩散模型),将图像转换到LAB空间:
- 亮度通道(L):保留原始图像的结构信息。
- 颜色通道(A/B):与风格图像的色彩分布对齐,实现颜色风格迁移。
技术优势:避免RGB空间中颜色和亮度耦合导致的风格失真。
传统深度学习
案例:医学图像分类中的颜色增强
在皮肤医学检测任务中(如使用ResNet模型):
- 将图像转换到HSV空间,调整**饱和度(S)**以增强病变区域对比度。
- 在LAB空间中对**亮度(L)**进行直方图均衡化,突出纹理细节。
效果:模型准确率提升5-8%(数据来源:ISIC 2019挑战赛)。
自动驾驶
案例:车道线检测的鲁棒性处理
在自动驾驶感知系统中(如Tesla的HydraNet):
- 将输入图像转换到HSV空间,利用固定阈值提取白色/黄色车道线:
lower_yellow = np.array([20, 100, 100]) # HSV阈值下限 upper_yellow = np.array([30, 255, 255]) # HSV阈值上限 mask = cv2.inRange(image_hsv, lower_yellow, upper_yellow) - 在灰度空间中计算车道线曲率,减少计算复杂度。
优势:相比RGB空间,HSV在雨天/逆光场景下的检测成功率提升40%。
4. 扩展应用
- YUV空间:视频压缩(如H.264编码)中分离亮度(Y)和色度(UV),节省带宽。
- CMYK空间:印刷行业专用颜色空间,用于颜色精确控制。
通过灵活选择颜色空间,开发者可以针对不同任务优化图像处理流程,这是计算机视觉领域的核心基础技术之一。
5. 不同颜色空间转换的详细过程与注意事项
1. RGB 颜色空间
转换过程:
RGB(红、绿、蓝)是基础的加色模型,通过三原色的叠加表示颜色。在代码中,OpenCV默认读取的图像为BGR顺序,需注意与Matplotlib的RGB顺序差异。
- 公式:每个像素由三个通道组成,值域通常为0-255(8位图像)。
注意事项:
- 通道顺序:OpenCV的
imread读取为BGR格式,转换为RGB时需显式调整(cv2.COLOR_BGR2RGB)。 - 亮度耦合:颜色和亮度信息混合,不适合直接处理光照变化(如逆光场景)。
2. HSV/HSL 颜色空间
转换过程:
HSV(色相Hue、饱和度Saturation、明度Value)将颜色分解为更直观的属性:
- H(0-179°):颜色类型(OpenCV中缩放到0-180,避免用uint8溢出)。
- S(0-255):颜色纯度,值越高越鲜艳。
- V(0-255):亮度,值越高越明亮。
公式: - 归一化RGB到 [ 0 , 1 ] [0,1] [0,1] ,计算最大值(max)和最小值(min)。
- V = m a x V = max V=max
- S = m a x − m i n m a x S = \frac{max - min}{max} S=maxmax−min (若max≠0,否则S=0)
- H H H 根据最大通道计算角度(如R为max时, H = 60 ° × ( G − B ) / ( m a x − m i n ) H = 60°×(G−B)/(max−min) H=60°×(G−B)/(max−min) )。
注意事项:
- H通道范围:OpenCV中H被压缩到0-179(原0-360°的一半),避免8位整型溢出。
- 光照影响:V通道对光照敏感,强光下S可能趋近于0,导致颜色信息丢失。
3. LAB 颜色空间
转换过程:
LAB将颜色分解为亮度(L)和两个色度通道(A、B):
- L(0-100):亮度,从黑到白。
- A(-128~127):绿-红轴。
- B(-128~127):蓝-黄轴。
公式: - 基于CIE XYZ空间的非线性转换,具体步骤复杂(涉及白点参考和分段函数)。
- OpenCV中直接调用
cv2.COLOR_BGR2LAB自动处理。
注意事项:
- 值域处理:转换后L通道为0-100,A/B为-128~127,需归一化到0-255(8位图像)时可能损失精度。
- 设备依赖:LAB基于标准观察者模型,实际图像可能因相机白平衡差异导致偏差。
4. 灰度(GRAY)空间
转换过程:
将彩色图像转换为单通道亮度信息,常见加权方法:
- OpenCV默认: Y = 0.299 R + 0.587 G + 0.114 B Y = 0.299R + 0.587G + 0.114B Y=0.299R+0.587G+0.114B (模拟人眼敏感度)。
- 简单平均: Y = ( R + G + B ) / 3 Y = (R + G + B)/3 Y=(R+G+B)/3 (计算快但对比度低)。
注意事项:
- 信息丢失:无法还原原始颜色,不适合需要色彩分析的任务。
- 权重选择:自动驾驶中若车道线为蓝色,默认权重可能削弱其亮度,需自定义公式(如提高B的系数)。
5. YUV/YCrCb 颜色空间
转换过程:
分离亮度(Y)和色度(UV/CrCb),广泛用于视频编码:
- Y:亮度,类似灰度。
- U/Cr:蓝色差值(B - Y)。
- V/Cb:红色差值(R - Y)。
公式: - Y = 0.299 R + 0.587 G + 0.114 B Y = 0.299R + 0.587G + 0.114B Y=0.299R+0.587G+0.114B
- U = 0.492 ( B − Y ) U = 0.492(B - Y) U=0.492(B−Y)
- V = 0.877 ( R − Y ) V = 0.877(R - Y) V=0.877(R−Y)
注意事项:
- 色度子采样:视频压缩中常对UV降采样(如4:2:0),处理时需重建分辨率。
- 范围限制:YUV值域通常为Y(16-235)、UV(16-240),转换时需缩放。
模型部署基础
【一】介绍一下Ollama的相关知识
1. 什么是Ollama
Ollama 是一个开源框架,专注于在本地环境中快速部署和运行大型语言模型(LLMs),支持多种模型格式(如 GGUF、PyTorch 等),提供轻量化的推理服务。其核心目标是降低用户使用 LLMs 的门槛,尤其适合AI开发者和AI研究者进行本地实验或私有化部署。通过 Ollama,AI开发者能以极低门槛将前沿 AI 能力整合到实际业务中,同时保持对数据和模型的全流程控制。以下是其核心特性:
- 本地优先:无需依赖云端服务,支持本地 CPU/GPU 推理。
- 多模型支持:兼容 DeepSeek、Llama、Mistral、Phi 等主流模型。
- 轻量化 API:提供类似 OpenAI 的 RESTful API,便于集成到现有系统中。
- 多模态扩展:支持文本、图像生成(如 LLaVA)等多模态任务。
- 资源优化:通过量化技术(如 4-bit/8-bit)降低显存占用。
2. DeepSeek 部署示例
DeepSeek 是由中国深度求索公司开发的高性能开源语言模型,在数学推理、代码生成等任务中表现优异。以下是使用 Ollama 部署 DeepSeek 的步骤:
环境准备
- 操作系统:Linux/macOS/Windows(需 Docker 或直接安装)
- 硬件要求:至少 8GB 内存,推荐 NVIDIA GPU(支持 CUDA)
- 安装 Ollama:
# Linux/macOS 一键安装 curl -fsSL https://ollama.com/install.sh | sh # Windows 可通过 Docker 部署 docker run -d -p 11434:11434 --name ollama ollama/ollama
下载 DeepSeek 模型
Ollama 支持直接从其模型库拉取预配置模型:
# 拉取 DeepSeek 7B 模型(支持中文)
ollama pull deepseek-7b
# 或自定义模型(需手动配置 Modelfile)
ollama create deepseek-custom -f ./Modelfile
Modelfile 示例:
FROM deepseek-7b
PARAMETER num_gpu 1 # 启用 GPU 推理
启动服务
# 后台运行模型服务
ollama serve
# 交互式调用
ollama run deepseek-7b "如何用 Python 实现快速排序?"
API 调用
通过 RESTful API 集成到应用:
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "deepseek-7b",
"prompt": "解释量子计算的 Shor 算法",
"stream": False
}
)
print(response.json()["response"])
3. Ollama 的经典应用案例
3.1 AIGC(生成式人工智能)
- 案例:内容创作自动化
- 场景:营销团队使用 DeepSeek 生成广告文案和社交媒体内容。
- 实现:通过 Ollama 部署模型,结合 LangChain 构建自动化流水线:
from langchain_community.llms import Ollama llm = Ollama(model="deepseek-7b") print(llm("生成一篇关于环保的微博文案,要求包含#碳中和#标签。")) - 优势:本地部署保障数据隐私,避免云端 API 调用成本。
3.2 传统深度学习
- 案例:图像描述生成(多模态扩展)
- 场景:将 LLaVA 模型与 Ollama 结合,为医学影像生成文本描述。
- 部署:
# 拉取多模态模型 ollama pull llava # 上传图像并获取描述 ollama run llava "描述这张图片的内容" -i ./x-ray.jpg - 技术栈:结合 CLIP 视觉编码器与语言模型,实现端到端推理。
3.3 自动驾驶
- 案例:场景理解与决策推理
- 场景:在车载边缘设备部署小型语言模型,解析传感器数据并生成驾驶决策。
- 实现:
- 使用 Ollama 量化部署 Phi-3 等轻量模型(<4GB 显存占用)。
- 输入激光雷达点云数据文本化描述:
"前方 50 米处有行人正在横穿马路,当前车速 60km/h,请建议刹车力度。" - 模型输出结构化指令:
{"action": "brake", "intensity": 0.7, "confidence": 0.92}
- 优势:低延迟本地推理避免网络不稳定问题,符合车规级安全要求。
【二】介绍一下Open-WebUI的相关知识
一、Open WebUI 简介
Open WebUI 是一款开源、可扩展的 Web 界面工具,专为本地部署的大型语言模型(LLM)和深度学习模型提供可视化交互支持。其核心优势在于完全离线运行、用户友好的图形界面,以及无缝集成多种模型服务(如 Ollama、OpenAI API 等)的能力。以下是其核心特性:
- 本地化与隐私保护:所有数据在本地处理,避免云端传输风险,适合医疗、金融等敏感场景。
- 多模态支持:支持文本、图像、文件上传与解析(如 PDF、知识库构建),内置 RAG(检索增强生成)引擎。
- 轻量化与跨平台:通过 Docker 容器化部署,支持 Windows、Linux、macOS 等操作系统,适配不同硬件配置。
- 生态兼容性:与 Ollama 等工具深度集成,可自动识别本地模型并提供统一管理界面。
二、DeepSeek 部署示例(基于 Ollama + Open WebUI)
以 DeepSeek-R1(7B 版本)为例,展示本地部署流程:
1. 环境准备
- 硬件要求:至少 16GB 内存,NVIDIA GPU(显存 ≥4GB)。
- 软件依赖:安装 Ollama、Docker,并配置 NVIDIA 容器工具包(Linux/Windows)。
2. 部署步骤
- 安装 Ollama
# Linux/macOS 一键安装 curl -fsSL https://ollama.com/install.sh | sh # Windows 通过 Docker 部署 docker run -d -p 11434:11434 --name ollama ollama/ollama - 下载 DeepSeek-R1 模型
ollama pull deepseek-r1:7b # 自动下载模型权重 - 启动 Open WebUI(Docker 方式)
docker run -d -p 3000:8080 --gpus all -v open-webui:/app/backend/data --name open-webui ghcr.io/open-webui/open-webui:main - 配置与使用
- 访问
http://localhost:3000,注册管理员账号。 - 在 Open WebUI 中自动识别本地 DeepSeek 模型,支持对话、文件上传、知识库管理。
- 访问
3. 调试与优化
- 常见问题:若出现连接错误,需确保 Ollama 服务已启动(
ollama serve)。 - 性能调优:通过调整 GPU 资源分配和模型量化参数(如
num_gpu)提升推理速度。
三、Open WebUI 的经典应用案例
1. AIGC(生成式人工智能)
- 案例 1:智能内容生成
用户通过 Open WebUI 上传行业报告,调用 DeepSeek 生成定制化营销文案,并结合知识库自动引用企业数据,提升内容准确性。 - 案例 2:代码助手
开发者使用 DeepSeek-Coder 模型生成代码片段,通过 Open WebUI 实时调试并导出结果,集成到 VS Code 等开发工具中。
2. 传统深度学习
- 案例:医学影像分析
结合多模态模型(如 LLaVA),上传 X 光片图像,模型生成诊断描述,并通过 Open WebUI 展示热力图辅助医生决策。 - 案例:工业质检
部署 YOLO 目标检测模型,实时识别生产线缺陷,结果通过 Web 界面可视化并触发自动化分拣系统。
3. 自动驾驶
- 案例:实时场景理解
车载边缘设备部署轻量级模型(如 Phi-3),通过 Open WebUI 解析激光雷达数据文本化描述,生成驾驶决策(如刹车力度)并可视化边界框。
计算机基础
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结归纳AI行业所需的计算机基础干货知识。这些干货知识不仅能在面试中帮助我们,还能让我们在AI行业中提高工作效率。
【一】介绍一下Linux中“No space left on device”问题的解决方案
1. 问题诊断:确认磁盘使用情况
- 核心命令:
df -h # 查看所有挂载点的空间使用情况 du -sh /* # 分析根目录下各子目录的占用空间 - 作用:快速定位空间不足的分区或目录。例如,若发现
/var占用过高,可能是日志或缓存堆积。
实际案例:
- AIGC:生成式模型(如Stable Diffusion)训练时,若未设置自动清理,临时生成的图像样本和模型检查点可能占满
/tmp或用户目录。 - 传统深度学习:TensorFlow/PyTorch的数据预处理阶段,未清理的中间文件(如未压缩的数据集缓存)可能导致
/home空间耗尽。 - 自动驾驶:自动驾驶车辆的路测数据(如激光雷达点云、摄像头视频)若直接存储在根目录下,可能迅速占满存储。
2. 清理临时文件与缓存
- 关键操作:
# 清理APT缓存(释放/var/cache/apt/archives) sudo apt-get clean sudo apt-get autoremove # 清理Docker资源(释放/var/lib/docker) docker system prune -a -f # 清理日志(释放/var/log) sudo journalctl --vacuum-time=7d # 仅保留7天日志 sudo truncate -s 0 /var/log/*.log
实际案例:
- AIGC:在训练大型语言模型(如GPT-3)时,Docker容器生成的中间层镜像可能占用数百GB,需定期清理。
- 传统深度学习:使用Jupyter Notebook时,内核崩溃生成的
core.*文件可能堆积在/var/crash,需手动删除。 - 自动驾驶:车载系统的高频传感器日志(如每秒10GB的雷达数据)需配置日志轮转(
logrotate),限制单个日志文件大小。
3. 删除无用的大文件
- 操作步骤:
# 查找大文件(按大小排序) sudo find / -type f -size +1G -exec ls -lh {} \; # 删除特定文件或目录 rm -rf /path/to/large_files
实际案例:
- AIGC:训练生成的中间模型检查点(如每epoch保存的
model_ckpt_*.pt)可仅保留最优模型,其余删除。 - 传统深度学习:ImageNet预处理后的数据集缓存(如未压缩的TFRecords)在训练结束后可删除。
- 自动驾驶:冗余的旧版本地图数据(如高精度地图的
.pcd文件)可通过版本管理工具清理。
4. 扩展存储空间
- 物理扩展:添加新硬盘并挂载到空闲目录(如
/data)。 - 逻辑卷扩展(LVM):
sudo lvextend -L +100G /dev/vg0/root # 扩展逻辑卷 sudo resize2fs /dev/vg0/root # 调整文件系统 - 符号链接迁移:
mv /root/large_data /new_disk/ ln -s /new_disk/large_data /root/large_data # 创建软链接
实际案例:
- AIGC:扩展存储用于存放扩散模型的高分辨率训练数据集(如LAION-5B)。
- 传统深度学习:挂载NAS存储,存放分布式训练中的共享数据集。
- 自动驾驶:使用SAN存储阵列存放PB级路测数据,通过NFS挂载到训练服务器。
5. 处理进程占用已删除文件
- 命令:
# 查找被删除但仍被进程占用的文件 sudo lsof +L1 | grep deleted # 重启相关进程或服务释放空间 sudo systemctl restart apache2
实际案例:
- AIGC:训练脚本异常退出后,模型文件被删除但GPU进程仍占用,需
kill进程或重启服务。 - 自动驾驶:车载数据采集服务崩溃后,未正确关闭的进程占用传感器日志文件,需重启服务。
6. 预防措施
- 自动化清理脚本:
# 每周清理Docker和APT缓存 echo "0 3 * * 0 docker system prune -af && apt-get clean" | sudo tee /etc/cron.weekly/cleanup - 监控工具:
- 使用
ncdu可视化磁盘占用。 - 部署Prometheus + Grafana监控存储使用率。
- 使用
实际案例:
- AIGC:在Kubernetes集群中配置Pod的存储卷自动清理策略,避免模型训练任务占满持久化存储。
- 自动驾驶:车载边缘计算设备配置InfluxDB监控,实时预警存储使用率超过90%。
- 传统深度学习:Slurm作业调度系统中设置任务结束后的自动清理脚本,删除临时文件。
总结
“No space left on device”的解决方案本质是空间诊断→清理释放→扩展容量→预防监控的闭环。在AI各领域中,需结合领域特性优化:
- AIGC:关注模型训练生命周期管理,利用云原生存储弹性扩展。
- 传统深度学习:优化数据流水线,减少中间文件产生。
- 自动驾驶:强化边缘设备的存储可靠性,设计高吞吐日志系统。
通过技术组合与自动化策略,可系统性解决存储瓶颈,支撑AI领域应用的规模化落地。
【二】介绍一下计算机中热插拔式和冷启动的相关概念
一、热插拔(Hot Plugging)
定义:
热插拔指在计算机系统保持运行状态下,动态插入或移除硬件设备的能力。这一过程无需关闭电源或中断系统运行,依赖硬件接口和操作系统的协同支持。
核心机制:
- 硬件支持:接口需设计为支持带电插拔(如USB、PCIe热插拔规范)。
- 操作系统管理:
- 设备检测:通过中断或轮询机制感知设备连接/断开。
- 驱动加载:动态加载或卸载设备驱动(如Linux的
udev服务)。 - 资源分配:自动分配中断请求(IRQ)、内存地址等资源。
- 信号稳定:接口需防止插拔瞬间的电流冲击(如ESD防护电路)。
应用场景:
- 服务器/数据中心:更换故障硬盘、扩展GPU加速卡。
- 个人设备:插入U盘、外接显示器。
- 工业控制:更换传感器或通信模块。
二、冷启动(Cold Boot)
定义:
冷启动指从完全断电状态启动计算机的过程,涵盖硬件自检、固件初始化、操作系统加载等完整流程。
核心流程:
- 上电自检(POST):检测CPU、内存、主板等核心硬件状态。
- 固件初始化:BIOS/UEFI加载硬件配置(如启动顺序、安全启动)。
- 操作系统加载:引导程序(如GRUB)加载内核,初始化驱动程序和服务。
应用场景:
- 首次开机:新设备初始化。
- 硬件故障恢复:更换关键硬件后需冷启动重新配置。
- 系统重置:修复软件冲突或配置错误。
三、热插拔与冷启动对比
| 特性 | 热插拔 | 冷启动 |
|---|---|---|
| 系统状态 | 系统运行中 | 系统完全断电后重新启动 |
| 硬件操作 | 动态插入/移除设备 | 需要关闭电源后操作 |
| 耗时 | 毫秒级(实时生效) | 秒到分钟级(需完整初始化) |
| 主要目的 | 扩展或维护不中断服务 | 彻底初始化系统或修复问题 |
| 典型场景 | 服务器更换硬盘、插入U盘 | 电脑首次开机、系统崩溃后重启 |
四、行业应用案例
1. AIGC
-
热插拔应用:
- 动态扩展GPU资源:在生成高分辨率视频时,插入额外GPU加速卡提升算力。
- 案例:使用NVIDIA的NVLink技术,在运行中扩展多GPU集群以加速Stable Diffusion推理。
-
冷启动挑战:
- 模型加载延迟:启动大型语言模型(如GPT-4)需加载数百GB参数,冷启动耗时长。
- 优化方案:预加载模型至显存(如TensorRT的持久化缓存)或使用容器快照技术(如Docker镜像预热)。
2. 传统深度学习
-
热插拔应用:
- 分布式训练节点扩展:在训练过程中动态加入计算节点(需框架支持如PyTorch Elastic)。
- 案例:Kubernetes集群中动态添加GPU节点,无需中断正在运行的训练任务。
-
冷启动问题:
- 训练环境初始化:每次启动训练任务需加载数据集、模型和优化器状态。
- 优化方案:使用检查点(Checkpoint)恢复训练,或通过并行文件系统(如Lustre)加速数据加载。
3. 自动驾驶
-
热插拔应用:
- 车载模块升级:在车辆运行中更换存储模块(如SSD)以更新高精地图。
- 案例:特斯拉的OTA升级中,部分计算模块支持热插拔式固件更新。
-
冷启动关键性:
- 系统安全初始化:车辆启动时需加载感知模型(如YOLOv7)、路径规划算法和实时操作系统(如ROS 2)。
- 挑战:冷启动时间直接影响车辆响应速度(需优化至毫秒级,如NVIDIA DRIVE平台的快速启动技术)。
开放性问题
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结AI行业的本质思考。这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入深度的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】AI算法工程师如何在AI行业中持续揣摩对人性的判断?
Rocky认为这是AI算法工程师持续提升自己通识基本面的核心,因为大部分时间都对着电脑,所以在空闲时间可以多对人性进行揣摩和思考。
【二】在AIGC时代这个AI技术大爆发的时期,如何辨别哪些是跨周期技术,哪些是“苦涩的教训”技术?
Rocky认为这是AI算法工程师对AI技术的最本质认知问题,在眼花缭乱的AI技术大爆发时代,挖掘出跨周期的AI技术,而不是将自己宝贵的时间都沉没在“苦涩的教训”技术中。
推荐阅读
1、加入AIGCmagic社区知识星球!
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100+应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等干货。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。与此同时,我们也重磅推出了知识星球2025年惊喜价:原价199元,前200名限量立减50!特惠价仅149元!(每天仅4毛钱)
时长:一年(从我们加入的时刻算起)


2、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
3、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
4、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
5、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
6、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
7、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
8、Transformer核心基础知识,核心网络结构,AIGC时代的Transformer新内涵,各AI领域Transformer的应用落地,Transformer未来发展趋势等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Transformer文章地址:https://zhuanlan.zhihu.com/p/709874399
9、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
10、50万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
11、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
12、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306
13、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











