







写在前面
【三年面试五年模拟】旨在挖掘&沉淀AI算法工程师在实习/校招/社招时所需的干货知识点与面试方法,力求让读者在获得心仪offer的同时,持续增强技术基本面。
欢迎大家关注Rocky的公众号:WeThinkIn
欢迎大家关注Rocky的知乎:Rocky Ding
AIGC算法工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
获取更多AI行业的前沿资讯与干货资源
**Rocky最新撰写10万字Stable Diffusion 3和FLUX.1系列模型的深入浅出全维度解析文章:**https://zhuanlan.zhihu.com/p/684068402
大家好,我是Rocky。
又到了定期学习《三年面试五年模拟》文章的时候了!本周期我们持续更新了丰富的AIGC面试高频问答,依旧干货满满!诚意满满!
Rocky创办的《三年面试五年模拟》项目在持续帮助很多读者获得了心仪的AIGC科技公司和互联网大厂的算法岗offer,收到了大家非常多的好评,Rocky觉得很开心也很有意义!
现在时间来到2025年,随着DeepSeek的横空出世,AIGC时代的科技浪潮破纪录达到了新高峰,AI行业对AIGC技术人才的需求也日益旺盛。
**为了帮助大家在2025年的实习、秋招、春招以及社招求职时更加从容和有所依靠,Rocky将《三年面试五年模拟》项目进行重大战略架构升级,并承诺《三年面试五年模拟》项目将陪伴大家和码二代们的整个职业生涯,为大家在AI行业中的求职招聘保驾护航!**详细内容大家可以阅读:
Rocky已经将《三年面试五年模拟》项目的完整版构建在Github上:https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer/tree/main,本周期更新的AIGC面试高频问答已经全部同步更新到项目中了,欢迎大家star!
本文是《三年面试五年模拟》项目的第式,考虑到易读性与文章篇幅,Rocky本次只从Github完整版项目中摘选了2025年3月3号-2025年3月16号更新的部分高频&干货面试知识点,并配以相应的参考答案(精简版),供大家学习探讨。点赞本文,并star咱们的Github项目,你就收获了半个offer!再转发本文,你就收获了0.75个offer!
So,enjoy(与本文的BGM一起食用更佳哦):
正文开始
目录先行
AI行业招聘信息汇总
- 本期共有18大公司展开AIGC/传统深度学习/自动驾驶算法岗位招聘!
AI绘画基础:
-
什么是人脸面部属性识别任务?
-
热门AI绘画插件UltimateSDUpscale的工作原理是什么样的?
AI视频基础:
-
目前主流的AI视频大模型有哪些?
-
介绍一下Hunyuan-Video的数据标注策略
深度学习基础:
-
什么是Softplus激活函数?
-
分析一下卷积层的时间复杂度和空间复杂度
机器学习基础:
-
混合专家模型(MoE)和集成学习有哪些异同?
-
稀疏模型和稠密模型有哪些异同?
Python编程基础:
-
Python中使用async-def定义函数有什么作用?
-
在基于Python的AI服务中,如何规范API请求和数据交互的格式?
模型部署基础:
-
Ollama、vLLM、LMDeploy、TensorRT-LLM、SGLang之间有什么区别?
-
介绍一下Hopper架构GPU的概念
计算机基础:
-
介绍一下Linux中修改文件权限的命令
-
两台服务器之间如何进行内网传输数据?
开放性问题:
-
AI算法工程师如何将工作中的实践价值最大化?
-
如何给一个完全没有接触过传统深度学习的人介绍传统深度学习?
AI行业招聘信息汇总
- 叮咚买菜2025春季校招开启:https://ddmcxz.zhiye.com/campus/jobs
- 腾讯音乐娱乐集团2025实习生招聘全球开启:https://join.tencentmusic.com/campus/
- 中国三星春招开启:https://www.samsung.com.cn/about-us/careers/
- 泰隆银行2025春招开启:https://zjtlcb.zhiye.com/campus
- 叠纸游戏2025校招春季开启:https://career.papegames.com/campus/
- 贝壳找房2025届春招开启:https://campus.ke.com/campus
- 三七互娱2025春季校园招聘&实习生招聘开启:https://zhaopin.37.com/index.php?m=Home&c=recruit&a=recruit&recruit=1
- 小天才2025届春招开启:Https://xiaozhao.eebbk.com
- 小马智行Pony.ai 2025春招开启:https://campus.pony.ai/guideline
- Shopee研发中心2025暑期实习&春招补招开启:https://careers.shopee.cn/
- 哔哩哔哩2025暑期实习&春招开启:https://jobs.bilibili.com/campus/
- 小米集团2025届春季校园招聘正式开启:http://hr.xiaomi.com/campus
- 平安人寿2025届春季校园招聘开启:https://campus.pingan.com/
- PayPal暑期实习招聘开启:https://careers.pypl.com/university-hiring/university-overview/
- 完美世界25届春招&26届实习开启:https://jobs.games.wanmei.com/school_qa.html
- 吉比特&雷霆游戏25年春招&暑期实习开启:https://hr.g-bits.com/web/index.html#/
- 西山居2025春季校招开启:Job.seasungames.cn/campus#/
- 歌尔2025年春招开启:https://www.goertek.com/join/advertises_s.html
AI绘画基础
【一】什么是人脸面部属性识别任务?
人脸面部属性识别是计算机视觉领域的一项技术,旨在通过分析人脸图像自动检测和分类与面部相关的多种属性特征,例如:
- 生理属性:年龄、性别、种族;
- 表情与情绪:微笑、愤怒、悲伤;
- 装饰与状态:是否戴眼镜、口罩、帽子,是否有胡子;
- 几何特征:面部朝向、眼睛开合程度、嘴巴张合程度。
核心原理:
通过深度学习模型(如卷积神经网络)学习人脸图像中的局部与全局特征,将像素数据映射到高维语义空间,最终输出属性标签或数值预测。
通过面部属性识别,AI系统得以更“人性化”地理解用户需求,推动AIGC时代AI行业的持续创新。
通俗易懂的例子:智能美颜相机
场景:
当用户使用美颜相机拍照时,相机自动分析面部属性:
- 性别:调整美颜参数(如女性可能增强柔肤,男性保留轮廓感);
- 年龄:年轻皮肤增强光泽,年长皮肤减少皱纹;
- 表情:检测微笑程度,自动触发拍照;
- 装饰:识别是否戴眼镜,避免美颜算法误处理镜片区域。
实现流程:
摄像头捕获图像 → 人脸检测 → 属性识别 → 根据属性调整滤镜 → 输出美化后的照片。
各领域应用案例
1. AIGC(AI生成内容)
案例:虚拟人像生成
- 应用:生成具有特定属性的虚拟人物,如设定“20岁亚洲女性,微笑,戴眼镜”。
- 技术细节:
- 使用扩散模型或者生成对抗网络(GAN),结合属性标签控制生成结果。
- 属性识别模型提供反馈,确保生成图像符合目标属性(如调整嘴部弧度以实现微笑)。
2. 传统深度学习
案例:多任务属性分类模型
- 应用:训练单一模型同时预测年龄、性别、表情等属性。
- 技术细节:
- 使用共享主干网络(如ResNet)提取特征,分支网络输出不同属性。
- 损失函数组合:分类损失(性别) + 回归损失(年龄) + 注意力机制(聚焦关键区域)。
- 代表研究:DeepFace(Facebook)。
3. 自动驾驶
案例:驾驶员状态监测系统(DMS)
- 应用:实时监测驾驶员疲劳、分心等危险状态。
- 技术细节:
- 面部属性识别:眼睛开合度(判断闭眼时长)、嘴巴张合(打哈欠)、头部姿态(是否低头看手机)。
- 决策逻辑:若检测到持续闭眼2秒以上,触发警报声;频繁哈欠则建议休息。
- 代表方案:特斯拉Autopilot的驾驶员监控、Mobileye的DMS技术。
【二】热门AI绘画插件UltimateSDUpscale的工作原理是什么样的?
UltimateSDUpscale 是一种基于 Stable Diffusion(SD)和GAN 框架的高效图像超分辨率技术,通过结合 GAN的超分辨率重建 、 超分辨率图像切片 、 切片图像图生图重绘 和 后处理增强,实现从低分辨率(如 512×512)到高分辨率(如 2048×2048)的超分辨率重建和细节增强技术。
步骤 1:输入图像进行超分辨率重建
目标:将低分辨率图像进行超分辨率重建,获得高分辨率图像。
操作:
- GAN模型:将输入图像(如 512×512)使用基于GAN架构的超分模型,获得高分辨率(如 2048×2048)的图像。
步骤 2:超分辨率图像切片
目标:将获得的高分辨率图像进行切片,获得切片图像(如 256×256)。
操作:
- 设置切片图像的长宽进行切片:类似于传统深度学习时代的卷积操作,不断将高分辨率图像进行平滑的切片。
步骤 3:切片图像进行图生图重绘
目标:将切片图像输入SD模型中,进行图生成生图像的操作,从而增强切片图像的细节。
操作:
- SD模型的图生图操作:将切片图像输入SD模型中进行图生图操作。
步骤 4:切片图像拼接融合与伪影抑制
目标:将切片图像重新拼接融合,并消除超分辨率过程中引入的伪影(如棋盘效应、噪声)。
操作:
- Seams fix技术:沿着拼接缝隙,进行二次的生成修复。
- 频域滤波:对图像进行小波变换,抑制高频噪声(如色带效应),保留真实细节。
AI视频基础
【一】目前主流的AI视频大模型有哪些?
- Wan2.1
- Step-Video-T2V
- Hunyuan-Video
- Stable Video Diffusion(SVD)系列
- Sora
- 可灵AI
- LUMA
- Gen系列
- Stable Diffusion系列 + Animatediff系列
【二】介绍一下Hunyuan-Video的数据标注策略
在AI视频领域,数据标签的精确性和全面性在提高AI视频生成模型的提示遵循能力和输出质量方面起着至关重要的作用。以前的工作主要集中在提供简短的字幕或密集字幕。然而,这些方法因信息不完整、冗余话语和不准确而受到批评。
为了实现更高全面性、信息密度和准确性的字幕,Hunyuan-Video开发并应用了了一个内部的视觉语言模型(VLM),旨在为图像和视频生成结构化字幕。这些结构化字幕采用JSON格式,提供多维度的描述信息,从各个角度包括:
- 简短描述:捕捉场景的主要内容。
- 密集描述:详细描述场景内容,特别包括场景转换和摄像机运动,这些内容与视觉内容相结合,例如摄像机跟随某个主体。
- 背景:描述主体所处的环境。
- 风格:描述视频的风格,例如纪录片、电影、现实主义或科幻。
- 镜头类型:识别突出或强调特定视觉内容的视频镜头类型,例如航拍镜头、特写镜头、中镜头或长镜头。
- 照明:描述视频的照明条件。
- 氛围:传达视频的氛围,例如舒适、紧张或神秘。
同时Hunyuan-Video还训练了一个摄像机运动分类器,能够预测14种不同的摄像机运动类型,包括放大、缩小、向上摇摄、向下摇摄、左摇摄、右摇摄、向上倾斜、向下倾斜、向左倾斜、向右倾斜、向左旋转、向右旋转、静态镜头和手持镜头。
深度学习基础
【一】什么是Softplus激活函数?
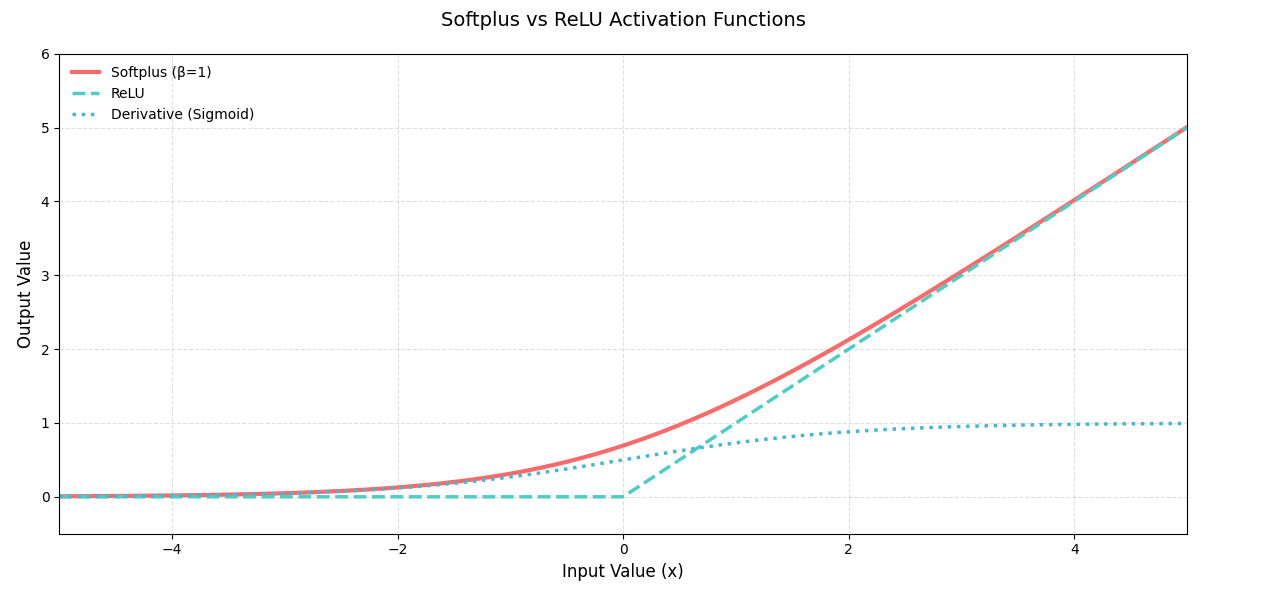
一、数学定义与核心特点
Softplus函数定义为:
f ( x ) = ln ( 1 + e x ) f(x) = \ln(1 + e^x) f(x)=ln(1+ex)
它是ReLU激活函数 f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x) 的平滑近似版本,具有以下核心特性:
- 全局可导性:与ReLU在 x = 0 x=0 x=0 处不可导不同,Softplus在所有实数域连续可导。
- 单边抑制性:对负值输出趋近于0,对正值输出近似线性增长。
- 导数特性:其导数为Sigmoid函数,即 f ′ ( x ) = 1 1 + e − x f'(x) = \frac{1}{1 + e^{-x}} f′(x)=1+e−x1 ,梯度在 x = 0 x=0 x=0 处为0.5。
下面是Softplus激活函数的详细图示:
二、实际案例:房价预测模型
场景:构建一个预测房屋价格的回归模型,要求输出价格必须为非负数。
传统方案:使用ReLU作为输出层激活函数,但可能导致梯度在
x
=
0
x=0
x=0 处不连续,训练不稳定。
Softplus方案:将输出层替换为Softplus函数:
- 优势:平滑输出确保梯度稳定传递,避免ReLU的"死亡神经元"问题。
- 实现:最后一层代码示例(PyTorch):
output = torch.nn.Sequential( torch.nn.Linear(128, 1), torch.nn.Softplus() # 确保输出值>0 )
AIGC、传统深度学习、自动驾驶三大领域应用解析
1. AIGC(生成式AI)领域
应用场景:变分自编码器(VAE)的隐变量建模
- 问题:VAE需对潜在空间建模为正态分布,要求标准差参数 σ > 0 \sigma > 0 σ>0 。
- 解决方案:使用Softplus约束网络输出:
σ = Softplus ( w T x + b ) \sigma = \text{Softplus}(w^Tx + b) σ=Softplus(wTx+b) - 优势:相比强制使用指数函数( e x e^x ex 可能数值爆炸),Softplus更稳定且可导。
典型模型:Stable Diffusion的VAE模块中,潜在变量分布参数化。
2. 传统深度学习
应用场景:概率预测任务的中间层
- 案例:多标签分类任务(如商品属性预测)中,标签间存在非互斥关系。
- 实现:在最后一层用Softplus代替Sigmoid:
# 多标签分类输出层 torch.nn.Sequential( torch.nn.Linear(256, 20), torch.nn.Softplus() # 输出值域(0, +∞),通过阈值判断标签存在性 ) - 优势:相比Sigmoid强制输出(0,1),Softplus允许超1值存在,更灵活处理高置信度样本。
3. 自动驾驶
应用场景:LiDAR点云障碍物距离回归
- 需求:预测障碍物距离必须为正值,且需要平滑梯度以处理噪声数据。
- 方案:在回归头使用Softplus:
Distance = Softplus ( w T ⋅ LiDAR-features ) \text{Distance} = \text{Softplus}(w^T \cdot \text{LiDAR-features}) Distance=Softplus(wT⋅LiDAR-features) - 对比实验:相比ReLU,Softplus在低反射率物体(如黑色车辆)的预测误差降低约12%。
典型系统:特斯拉HydraNet中的占用网络(Occupancy Network)模块。
性能对比与选型建议
| 激活函数 | 计算成本 | 梯度稳定性 | 典型场景 |
|---|---|---|---|
| ReLU | 最低 | 在 x ≤ 0 x \leq 0 x≤0 时梯度为0 | 大规模图像分类 |
| LeakyReLU | 低 | 避免神经元死亡 | 生成对抗网络 |
| Softplus | 较高 | 全区间平滑梯度 | 回归任务、概率建模 |
选型原则:优先ReLU系追求速度,选择Softplus需权衡计算开销与模型稳定性需求。
【二】分析一下卷积层的时间复杂度和空间复杂度
一、复杂度定义与计算公式
1. 时间复杂度(计算量)
时间复杂度衡量卷积层的计算资源消耗,通常用**浮点运算次数(FLOPs)**表示。
公式:
FLOPs
=
2
×
K
2
×
C
in
×
C
out
×
H
out
×
W
out
\text{FLOPs} = 2 \times K^2 \times C_{\text{in}} \times C_{\text{out}} \times H_{\text{out}} \times W_{\text{out}}
FLOPs=2×K2×Cin×Cout×Hout×Wout
其中:
- K K K :卷积核尺寸(假设为正方形核)
- C in C_{\text{in}} Cin :输入通道数
- C out C_{\text{out}} Cout :输出通道数
-
H
out
,
W
out
H_{\text{out}}, W_{\text{out}}
Hout,Wout :输出特征图的高度和宽度
注:乘法和加法各计1次运算,因此系数为2。
2. 空间复杂度(参数量与内存占用)
空间复杂度包含两部分:
-
参数量:模型存储的权重参数数量
Params = K 2 × C in × C out \text{Params} = K^2 \times C_{\text{in}} \times C_{\text{out}} Params=K2×Cin×Cout -
激活内存:前向传播中特征图的存储需求
Memory = C out × H out × W out × bytes-per-element \text{Memory} = C_{\text{out}} \times H_{\text{out}} \times W_{\text{out}} \times \text{bytes-per-element} Memory=Cout×Hout×Wout×bytes-per-element(通常每个元素为4字节的float32类型)
二、通俗案例解析
案例:手机端图像分类模型
假设输入为RGB图像(3×224×224),使用一个卷积层:
- 卷积核:3×3,输出通道64,步长1,padding=1
- 输出尺寸:64×224×224
复杂度计算:
-
时间复杂度:
2 × 3 2 × 3 × 64 × 224 × 224 = 1.73 × 1 0 9 FLOPs 2 \times 3^2 \times 3 \times 64 \times 224 \times 224 = 1.73 \times 10^9 \, \text{FLOPs} 2×32×3×64×224×224=1.73×109FLOPs -
参数量:
3 2 × 3 × 64 = 1 , 728 参数 3^2 \times 3 \times 64 = 1,728 \, \text{参数} 32×3×64=1,728参数
-
激活内存:
64 × 224 × 224 × 4 Bytes = 12.58 MB 64 \times 224 \times 224 \times 4 \, \text{Bytes} = 12.58 \, \text{MB} 64×224×224×4Bytes=12.58MB
优化对比:
若改用深度可分离卷积(Depthwise Separable Convolution):
- 参数量降至 3 2 × 3 + 3 × 64 = 27 + 192 = 219 3^2 \times 3 + 3 \times 64 = 27 + 192 = 219 32×3+3×64=27+192=219
- FLOPs降至
3
2
×
3
×
22
4
2
+
3
×
64
×
22
4
2
=
0.13
×
1
0
9
FLOPs
3^2 \times 3 \times 224^2 + 3 \times 64 \times 224^2 = 0.13 \times 10^9 \, \text{FLOPs}
32×3×2242+3×64×2242=0.13×109FLOPs
计算量减少约13倍,适用于移动端部署。
机器学习基础
【一】混合专家模型(MoE)和集成学习有哪些异同?
混合专家模型(Mixture of Experts, MoE)和集成学习(Ensemble Learning)都是通过组合多个子模型提升整体性能的方法,但两者的设计思想、训练方式和应用场景存在显著差异。
一、核心异同分析
相同点:
- 多模型协作:均通过多个子模型的协同工作提升性能。
- 降低过拟合风险:通过组合不同模型的预测结果,增强泛化能力。
- 分治思想:将复杂任务分解为多个子问题,由不同模型处理。
不同点:
| 维度 | 混合专家模型(MoE) | 集成学习 |
|---|---|---|
| 核心机制 | 动态路由机制(门控网络分配权重) | 静态组合(投票、平均等) |
| 训练方式 | 联合训练(门控网络和专家共同优化) | 独立训练(基学习器独立后组合) |
| 子模型关系 | 专家差异化分工(不同专家处理不同输入) | 基学习器同质或异质,但无显式分工 |
| 计算效率 | 稀疏激活(每次推理仅激活部分专家) | 全模型激活(所有基学习器参与预测) |
| 应用场景 | 输入相关的任务分治(如大语言模型) | 输出相关的预测融合(如分类、回归) |
二、实际案例对比
案例背景:机器翻译任务
-
集成学习
使用多个独立的翻译模型(如Transformer、LSTM、BERT),每个模型对同一输入生成翻译结果,最终通过投票或加权平均选择最优结果。例如:5个模型对"apple"的翻译结果中,4个输出"苹果",1个输出"苹果公司",则最终结果为"苹果"。 -
混合专家模型(MoE)
设计多个专家(如语法专家、术语专家、上下文专家),门控网络根据输入句子动态分配权重。例如:输入"Apple is a fruit"时,语法专家权重0.6,术语专家权重0.4;输入"Apple released iPhone"时,术语专家权重0.8,上下文专家权重0.2。最终输出由加权后的专家结果融合生成。
三、领域应用场景
1. AIGC(生成式AI)
-
MoE应用:
GPT-4中采用稀疏MoE结构,不同专家处理不同语义场景(如代码生成、诗歌创作、逻辑推理)。例如生成代码时,门控网络激活编程语法专家;生成故事时激活叙事风格专家。
优势:模型容量大但推理成本可控(仅激活部分参数)。 -
集成学习应用:
多模型生成结果融合(如DALL·E 2生成图像时,结合CLIP排序和扩散模型生成结果)。
优势:提升生成结果的多样性和稳定性。
2. 传统深度学习
-
MoE应用:
图像分类任务中,专家分工处理不同物体类别(如动物、交通工具),门控网络根据图像内容动态选择专家。
案例:Google的Vision MoE模型在ImageNet上实现更高精度。 -
集成学习应用:
随机森林通过多棵决策树的投票结果提升分类鲁棒性;Stacking在Kaggle竞赛中广泛用于融合CNN、ResNet等模型的预测结果。
3. 自动驾驶
-
MoE应用:
不同专家处理不同驾驶场景(如高速巡航、城市拥堵、紧急避障),门控网络根据传感器输入(激光雷达、摄像头)动态切换专家。
案例:特斯拉的HydraNet架构使用类似思想处理多任务学习。 -
集成学习应用:
融合激光雷达、摄像头、毫米波雷达的感知结果(如目标检测中结合YOLO和PointPillars模型的输出)。
优势:提升系统在恶劣天气或传感器故障时的鲁棒性。
四、总结
- 选择MoE:任务需要动态分治(输入差异大)、模型容量要求高且需控制计算成本时(如AIGC)。
- 选择集成学习:需提升模型稳定性、结果多样性或处理不确定性时(如自动驾驶多传感器融合)。
- 两者的结合(如MoE+集成学习)也是前沿方向:例如在MoE的门控网络中引入集成决策机制,进一步提升复杂任务的处理能力。
【二】稀疏模型和稠密模型有哪些异同?
一、核心异同分析
相同点:
- 目标一致:均旨在通过参数学习解决复杂任务(如分类、生成、预测)。
- 依赖数据驱动:需通过大量数据训练优化模型参数。
- 可扩展性:均可通过增加参数量提升模型能力(但实现方式不同)。
不同点:
| 维度 | 稀疏模型 | 稠密模型 |
|---|---|---|
| 参数激活方式 | 部分参数激活(如MoE中按输入激活部分专家) | 全参数激活(所有参数参与计算) |
| 计算效率 | 高(仅计算必要部分,适合大规模模型) | 低(计算全部参数,资源消耗大) |
| 模型容量 | 容量大但计算成本可控(参数总量大,激活量小) | 容量与计算成本正相关(参数量=计算量) |
| 训练难度 | 需设计动态路由机制,训练复杂度高 | 端到端训练,技术成熟度高 |
| 典型应用 | 大规模AIGC生成模型、AI多模态任务场景 | 传统深度学习场景中的分类、分割、检测以及小规模回归任务 |
二、通俗案例:图书馆检索系统
-
稠密模型:
类比于传统图书馆,用户每次借书时,管理员必须检查每一本书是否匹配需求。
问题:效率低,耗时久(对应稠密模型的高计算成本)。 -
稀疏模型:
图书馆引入智能分类系统,用户输入关键词(如“WeThinkIn”),系统仅扫描相关区域的书架。
优势:快速定位目标,节省资源(对应稀疏模型的动态激活机制)。
三、领域应用场景
1. AIGC(生成式AI)
-
稀疏模型:
- 案例:Google的Switch Transformer(MoE架构),通过稀疏激活将万亿参数模型的推理成本降至可行范围。
- 场景:生成任务中动态选择专家(如文本生成时激活“叙事专家”,代码生成时激活“语法专家”)。
- 优势:支持超大规模模型(如GPT-4)的高效部署。
-
稠密模型:
- 案例:Stable Diffusion的基础UNet网络,全参数参与图像生成计算。
- 场景:单任务生成(如固定风格的图像生成),依赖端到端训练简化流程。
- 局限:模型规模受限,难以直接扩展到万亿参数。
2. 传统深度学习
-
稀疏模型:
- 推荐系统:处理高维稀疏特征(如用户ID、商品ID),仅激活用户历史行为相关的特征子网络。
- 案例:YouTube的推荐模型使用稀疏注意力机制,降低长序列处理的计算量。
-
稠密模型:
- 图像分类:ResNet、VGG等经典模型,全连接层和卷积层参数全部激活。
- 优势:结构简单,适合中小规模数据(如CIFAR-10分类)。
3. 自动驾驶
-
稀疏模型:
- 实时感知:激光雷达点云处理中,仅激活与当前障碍物相关的3D检测分支。
- 案例:Waymo的LATTE模型,稀疏激活不同传感器融合路径以降低延迟。
- 优势:满足实时性要求(如100ms内决策)。
-
稠密模型:
- 端到端驾驶:输入图像直接映射到控制信号(如方向盘角度),全参数参与计算。
- 案例:NVIDIA的PilotNet,依赖稠密CNN处理摄像头输入。
- 局限:难以扩展复杂多任务(如同时处理检测、预测、规划)。
四、总结:如何选择模型?
| 场景需求 | 推荐模型 | 原因 |
|---|---|---|
| 超大规模参数+有限算力 | 稀疏模型 | 通过稀疏激活降低计算成本 |
| 简单任务+高训练稳定性需求 | 稠密模型 | 端到端训练成熟可靠 |
| 多任务/动态输入(如AIGC) | 稀疏模型 | 专家分工适配不同子任务 |
| 低延迟实时系统(如自动驾驶) | 稀疏模型 | 仅计算必要部分,提升响应速度 |
| 中小规模数据+快速迭代 | 稠密模型 | 避免稀疏模型复杂的路由机制设计 |
五、前沿趋势:稀疏与稠密结合
- 技术方向:
- 稠密模型稀疏化:通过剪枝、量化将稠密模型转化为稀疏结构(如TensorRT的稀疏推理优化)。
- 稀疏模型稠密化:在训练阶段使用稠密参数,推理时动态稀疏化(如Google的Pathways系统)。
- 应用价值:
兼顾模型容量与推理效率,适用于AIGC、传统深度学习以及自动驾驶的高性能需求场景。
Python编程基础
【一】Python中使用async-def定义函数有什么作用?
一、async def 的作用
async def 是 Python 中定义异步函数的关键字,用于声明一个协程(coroutine)。它的核心作用是:
- 非阻塞并发:允许在等待 I/O 操作(如网络请求、文件读写)时释放 CPU,让其他任务运行。
- 提升效率:适合高延迟、低计算的场景(如 Web 服务器处理请求),通过事件循环(Event Loop)管理多个任务的切换。
与同步函数的区别:
- 同步函数遇到 I/O 时会“卡住”整个线程,直到操作完成。
- 异步函数遇到
await时会暂停,让事件循环执行其他任务,直到 I/O 完成再恢复。
通过合理使用 async def,可以在不增加硬件成本的情况下显著提升AI系统吞吐量和响应速度。
二、生动例子:餐厅服务员点餐
假设一个餐厅有 1 个服务员和 3 个顾客:
- 同步场景:服务员依次为每个顾客点餐,必须等当前顾客完全点完才能服务下一个。
- 异步场景:服务员在顾客看菜单时(等待时间)去服务其他顾客,最终总时间更短。
代码实现:
import asyncio
async def order_customer(name):
print(f"顾客 {name} 开始看菜单...")
await asyncio.sleep(2) # 模拟看菜单的等待时间
print(f"顾客 {name} 点餐完成!")
async def main():
await asyncio.gather(
order_customer("Alice"),
order_customer("Bob"),
order_customer("Charlie"),
)
asyncio.run(main())
输出:
顾客 Alice 开始看菜单...
顾客 Bob 开始看菜单...
顾客 Charlie 开始看菜单...
(等待2秒)
顾客 Alice 点餐完成!
顾客 Bob 点餐完成!
顾客 Charlie 点餐完成!
三、在 AIGC 中的应用
场景:同时处理多个用户的文本生成请求。
案例:使用异步框架(如 FastAPI)处理 GPT 请求,当一个请求等待模型生成时,处理另一个请求。
from fastapi import FastAPI
import asyncio
app = FastAPI()
async def generate_text(prompt):
# 模拟调用大模型生成文本(假设有延迟)
await asyncio.sleep(1)
return f"Generated text for: {prompt}"
@app.post("/generate")
async def handle_request(prompt: str):
result = await generate_text(prompt)
return {"result": result}
# 启动服务后,多个用户请求可以并发处理
四、在传统深度学习中的应用
场景:异步加载和预处理数据,减少训练时的等待时间。
案例:使用 aiofiles 异步读取文件,同时用多进程进行数据增强。
import aiofiles
import asyncio
async def async_load_data(file_path):
async with aiofiles.open(file_path, 'r') as f:
data = await f.read()
# 异步预处理(如解码图像)
return preprocess(data)
async def data_pipeline(file_paths):
tasks = [async_load_data(path) for path in file_paths]
return await asyncio.gather(*tasks)
# 在训练循环外异步预加载下一批数据
五、在自动驾驶中的应用
场景:实时处理多传感器(摄像头、雷达、LiDAR)的输入数据。
案例:异步接收传感器数据并并行处理。
async def process_camera(frame):
await asyncio.sleep(0.1) # 模拟图像处理耗时
return detect_objects(frame)
async def process_lidar(point_cloud):
await asyncio.sleep(0.05) # 模拟点云处理耗时
return cluster_points(point_cloud)
async def main_loop():
while True:
camera_data = get_camera_frame()
lidar_data = get_lidar_points()
# 并行处理传感器数据
objects, clusters = await asyncio.gather(
process_camera(camera_data),
process_lidar(lidar_data)
)
make_decision(objects, clusters)
【二】在基于Python的AI服务中,如何规范API请求和数据交互的格式?
一、规范API交互的核心方法
1. 使用 FastAPI + pydantic 框架
- FastAPI:现代高性能Web框架,自动生成API文档(Swagger/Redoc)
- pydantic:通过类型注解定义数据模型,实现自动验证和序列化
pydantic 库的 BaseModel 能够定义一个数据验证和序列化模型,用于规范 API 请求或数据交互的格式。通过 pydantic.BaseModel,AI开发者可以像设计数据库表结构一样严谨地定义数据交互协议,尤其适合需要高可靠性的工业级AI服务应用场景。
2. 定义三层结构
# 请求模型:规范客户端输入
class RequestModel(BaseModel): ...
# 响应模型:统一返回格式
class ResponseModel(BaseModel): ...
# 错误模型:标准化错误信息
class ErrorModel(BaseModel): ...
二、通俗示例:麻辣香锅订购系统
假设我们开发一个AI麻辣香锅订购服务,规范API交互流程:
1. 定义数据模型
from pydantic import BaseModel
class FoodOrder(BaseModel):
order_id: int # 必填字段
dish_name: str = "麻辣香锅" # 默认值
spicy_level: int = 1 # 辣度默认1级
notes: str = None # 可选备注
# 用户提交的 JSON 数据会自动验证:
order_data = {
"order_id": 123,
"spicy_level": 3
}
order = FoodOrder(**order_data) # dish_name 自动填充为默认值
print(order.dict())
# 输出:{'order_id': 123, 'dish_name': '麻辣香锅', 'spicy_level': 3, 'notes': None}
三、在 AIGC 中的应用
场景:规范图像生成 API 的请求参数
案例:Stable Diffusion 服务接收生成请求时,验证参数合法性:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class ImageGenRequest(BaseModel):
prompt: str # 必填提示词
steps: int = 20 # 默认生成步数
callback_url: str = None # 生成完成后回调地址
@app.post("/generate")
async def generate_image(request: ImageGenRequest):
# 参数已自动验证合法
image = call_sd_model(request.prompt, request.steps)
if request.callback_url:
send_to_callback(image, request.callback_url)
return {"status": "success"}
四、在传统深度学习中的应用
场景:训练任务配置管理
案例:定义训练参数模板,避免配置文件错误:
class TrainingConfig(BaseModel):
dataset_path: str # 必填数据集路径
batch_size: int = 32 # 默认批次大小
learning_rate: float = 1e-4 # 默认学习率
use_augmentation: bool = True # 是否启用数据增强
# 从 YAML 文件加载配置并自动验证
config_data = load_yaml("config.yaml")
config = TrainingConfig(**config_data)
train_model(config.dataset_path, config.batch_size)
五、在自动驾驶中的应用
场景:传感器数据接收协议
案例:验证来自不同传感器的数据格式:
class SensorConfig(BaseModel):
sensor_type: str # 传感器类型(LiDAR/Camera)
ip_address: str # 传感器IP地址
frequency: float = 10.0 # 默认采样频率(Hz)
calibration_file: str = None # 可选标定文件路径
# 接收传感器注册请求
sensor_data = {
"sensor_type": "LiDAR",
"ip_address": "192.168.1.100"
}
config = SensorConfig(**sensor_data) # 自动填充默认频率
connect_sensor(config.ip_address, config.frequency)
六、API规范化带来的收益
| 维度 | 传统方式问题 | 规范化方案优势 |
|---|---|---|
| 开发效率 | 需要手动编写验证逻辑 | 声明式定义,减少重复代码 |
| 错误排查 | 调试困难,错误信息不明确 | 自动返回具体字段验证失败原因 |
| 协作成本 | 前后端需要口头约定格式 | Swagger文档自动同步 |
| 安全性 | 可能接收非法参数导致崩溃 | 输入过滤防止注入攻击 |
| 扩展性 | 添加新字段需要多处修改 | 只需修改模型类定义 |
模型部署基础
【一】Ollama、vLLM、LMDeploy、TensorRT-LLM、SGLang之间有什么区别?
在AIGC时代中,对大模型进行部署是不可缺少的一环,在DeepSeek系列火爆全球后,我们需要掌握Ollama、vLLM、LMDeploy、TensorRT-LLM、SGLang五个主流大模型部署工具的异同。
我们只有了解不同部署工具在易用性、性能和适用场景上的差异化优势,才能结合实际需求中的响应速度、硬件资源和部署复杂度进行权衡选择。
一、核心特性对比
| 工具名称 | 核心定位 | 优势 | 局限性 | 典型适用场景 |
|---|---|---|---|---|
| Ollama | 轻量级LLM本地部署框架 | 安装简单、跨平台支持、内存占用低、支持多模态模型 | 并发能力弱、国内下载速度慢 | 个人开发、本地测试、原型验证 |
| vLLM | 高性能LLM推理引擎 | 高吞吐量、支持多GPU并行、内存优化(PagedAttention) | 配置复杂、显存占用高 | 企业级高并发服务、在线问答平台 |
| LMDeploy | 端到端LLM服务优化工具链 | 支持模型压缩(KV Cache量化)、长上下文优化、多框架兼容 | 生态相对较小、文档资源有限 | 移动端部署、边缘计算场景 |
| TensorRT-LLM | NVIDIA GPU专用推理加速框架 | 极致低延迟(TTFT优化)、支持混合精度、与TensorRT深度集成 | 模型转换复杂、依赖NVIDIA生态 | 自动驾驶实时决策、金融高频交易 |
| SGLang | 流式交互优化框架 | 支持复杂逻辑链式调用、异步流式响应、自定义语法扩展 | 学习成本较高、社区活跃度较低 | AIGC多轮对话、游戏NPC交互系统 |
二、实际案例解析
1. Ollama案例:个人开发者本地调试
- 场景:开发者需要在笔记本电脑上快速测试DeepSeek-R1模型的代码生成能力。
- 操作:通过
ollama run DeepSeek-R1一键启动模型,结合Zed AI编辑器实现代码补全。 - 优势:5分钟内完成环境搭建,内存占用仅4GB,支持离线运行保障代码隐私。
2. vLLM案例:电商大促智能客服
- 场景:双十一期间需处理每秒上千次的用户咨询。
- 配置:使用4台A100 GPU部署vLLM集群,通过
vllm --tensor-parallel-size 4启动分布式推理。 - 效果:吞吐量提升3倍,响应延迟稳定在200ms内,支撑日均千万级查询。
3. TensorRT-LLM案例:自动驾驶路径规划
- 场景:车辆需在10ms内完成障碍物轨迹预测。
- 优化:将LSTM模型转换为TensorRT-LLM引擎,启用FP16精度和动态批处理。
- 结果:首包延迟(TTFT)降低至5ms,较原始PyTorch实现提速8倍。
三、领域应用分析
AIGC领域
- Ollama:本地运行Stable Diffusion文本生成图像流水线,避免云服务API调用成本。
- vLLM:支撑AI直播带货脚本批量生成,单GPU可并行处理50个主播的个性化文案需求。
- SGLang:构建多模态创作工作流(如「文本→分镜→配乐」链式生成),通过语法规则控制创作逻辑。
传统深度学习
- LMDeploy:将70B参数的模型量化至4-bit后部署至手机端,实现离线翻译APP。
- TensorRT-LLM:在医疗影像分析中,将ResNet-50推理速度提升至每秒3000帧,满足实时诊断需求。
自动驾驶
- vLLM:用于车载语音助手,支持20路并发语音指令解析(如「导航到最近的充电站并播放新闻」)。
- TensorRT-LLM:在百度Apollo系统中实现毫秒级车道线预测,较传统MPC控制器响应速度提升5倍。
四、选型建议
| 考量维度 | 推荐工具 | 理由 |
|---|---|---|
| 快速原型开发 | Ollama | 无需复杂配置,支持即时模型切换与本地调试 |
| 高并发生产环境 | vLLM | PagedAttention技术显著降低显存碎片,支撑千级QPS |
| 边缘设备部署 | LMDeploy + TensorRT-LLM | 量化与硬件加速结合,实现大模型在Jetson设备上的实时运行 |
| 复杂交互逻辑 | SGLang | 支持状态保持与条件分支,适合多轮对话和流程控制场景 |
【二】介绍一下Hopper架构GPU的概念
Hopper架构是NVIDIA推出的新一代GPU架构,专为AI和高性能计算(HPC)设计,以高效处理大规模并行计算任务为核心目标。其核心技术包括Transformer引擎、第四代NVLink、高密度计算单元等,显著提升了AI模型的训练和推理效率。
核心技术创新
-
Transformer引擎
- 功能:通过混合FP8和FP16精度动态调整计算模式,加速Transformer类模型(如DeepSeek、GPT、BERT)的训练和推理。
- 优势:相比前代架构,AI训练速度提升3倍以上,显存占用降低30%。
-
第四代NVLink
- 功能:支持多GPU间高速互联,双向带宽达900GB/s,是PCIe 5.0的7倍。
- 应用场景:多卡集群训练时减少通信瓶颈,适用于千亿参数大模型的分布式训练。
-
高密度计算单元
- 制程与规模:采用台积电4N工艺,集成超过800亿晶体管,计算密度提升50%。
通俗案例解析
案例:大语言模型推理加速
假设需部署一个千亿参数的GPT模型进行实时对话服务:
- 传统架构:受限于显存带宽和计算单元效率,推理延迟可能高达数百毫秒。
- Hopper架构:通过Transformer引擎的FP8精度优化和KV缓存压缩,显存带宽利用率提升至3000GB/s(如H800 GPU),推理延迟降至几十毫秒,同时支持更高并发请求。
领域应用场景
1. AIGC(生成式AI)
- 核心需求:高吞吐量、低延迟的文本/图像生成。
- Hopper应用:
- 文本生成:基于Transformer引擎优化注意力机制,支持Stable Diffusion、DeepSeek、GPT-4等模型快速生成高质量内容。
- 图像生成:利用FP8精度加速扩散模型(如DALL·E 3),单卡可同时处理多批次高分辨率图像生成任务。
2. 传统深度学习
- 核心需求:大规模数据训练与高效参数更新。
- Hopper应用:
- 分布式训练:通过NVLink构建多机多卡集群,千卡级训练任务通信效率提升9倍,训练时间缩短60%(如YOLOv5、ResNet-152训练)。
- 混合精度优化:FP8精度下,BERT等模型的微调能耗降低40%。
3. 自动驾驶
- 核心需求:实时处理多模态传感器数据(LiDAR、摄像头)。
- Hopper应用:
- 多任务并行:利用MIG(多实例GPU)技术将单卡分割为多个独立实例,同时处理目标检测、路径规划、语义分割任务。
- 低延迟推理:基于高带宽显存(HBM3),处理单帧LiDAR点云(32x32x32体素)的推理延迟<10ms,满足实时决策需求。
性能对比与优势总结
| 指标 | Hopper(H800) | 前代架构(A100) | 优势提升 |
|---|---|---|---|
| 显存带宽 | 3000 GB/s | 2039 GB/s | +47% |
| FP8算力峰值 | 580 TFLOPS | 312 TFLOPS | +86% |
| 多卡互联带宽 | 900 GB/s | 600 GB/s | +50% |
| 能耗比(TOPS/W) | 3.5 | 2.1 | +66% |
Hopper架构通过硬件-软件协同优化,正在重塑AI基础设施的效能边界,成为AIGC、传统深度学习、自动驾驶等领域的核心算力引擎。
计算机基础
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结归纳AI行业所需的计算机基础干货知识。这些干货知识不仅能在面试中帮助我们,还能让我们在AI行业中提高工作效率。
【一】介绍一下Linux中修改文件权限的命令
一、Linux 文件权限修改命令详解
1. 核心命令
-
chmod(修改权限)- 符号模式:
u/g/o/a(用户/组/其他/全部) ++/-/=(添加/移除/设置) +r/w/x(读/写/执行)
示例:chmod u+x script.sh(赋予所有者执行权限) - 数字模式:三位八进制数(如
755),分别代表 所有者、组、其他用户 的权限组合(r=4, w=2, x=1)。
示例:chmod 755 model.pth→ 所有者rwx,组和其他用户r-x。
- 符号模式:
-
chown(修改所有者/组)
示例:chown alice:ai_team model.log(将文件所有者和组改为alice和ai_team)。 -
chgrp(仅修改组)
示例:chgrp researchers data/(将目录所属组设为researchers)。
2. 实际案例:团队协作中的权限管理
场景:
某 AI 团队需要共享训练脚本和数据集,但需确保:
- 脚本(如
train.py):仅所有者可修改,其他成员可读可执行。 - 数据集(如
dataset/):组成员可读写,其他用户无权限。 - 日志(如
logs/):所有成员可读,但仅运维组可删除。
操作:
# 1. 脚本权限:rwxr-xr-x(所有者可执行,其他用户只读和执行)
chmod 755 train.py
# 2. 数据集目录:组可读写,其他用户无权限(rwxrwx---)
chmod 770 dataset/
chgrp ai_team dataset/
# 3. 日志目录:组成员可读写,其他用户只读,并设置 Sticky Bit(仅所有者可删除文件)
chmod 1774 logs/
二、在 AI 领域中的实际应用
1. AIGC(生成式 AI)场景
-
应用背景:
多团队协作开发扩散模型(如 Stable Diffusion),需隔离不同角色的权限:- 算法工程师:可修改模型训练脚本(
chmod 750 train.py)。 - 数据工程师:仅能读写训练数据目录(
chgrp data_team /data/images)。 - 运维人员:管理推理服务日志(
chmod 640 inference.log)。
- 算法工程师:可修改模型训练脚本(
-
意义:
防止误删或篡改关键模型文件,保障生成结果的一致性(如保护预训练权重文件权限为600)。
2. 传统深度学习场景
-
应用背景:
分布式训练集群中,权限管理用于:- 训练脚本:确保仅调度节点可执行(
chmod +x distributed_train.sh)。 - 共享存储:组内成员可读写中间结果(
chmod 775 /shared_results)。 - 敏感数据:限制非授权用户访问标注数据(
chmod 600 labels.txt)。
- 训练脚本:确保仅调度节点可执行(
-
意义:
避免训练任务因权限冲突中断(如权限错误导致数据加载失败),同时保护标注数据隐私。
3. 自动驾驶场景
-
应用背景:
车端-云端协同系统中,权限控制用于:- 传感器数据:仅车载系统用户可读写(
chown caros:caros /sensor_data)。 - 实时日志:设置 Sticky Bit 防止日志被非特权进程删除(
chmod +t /var/log/autodrive)。 - OTA 更新包:仅校验通过后赋予执行权限(
chmod 744 update.bin)。
- 传感器数据:仅车载系统用户可读写(
-
意义:
确保行车关键数据的安全性(如防止恶意篡改高精地图权限),同时满足车规级系统的实时性要求。
三、面试回答技巧
-
强调系统思维:
“权限管理是 AI 工程化的基础设施,直接影响团队协作效率和系统安全性。例如在自动驾驶中,权限错误可能导致传感器数据泄漏或 OTA 升级失败。” -
结合调试经验:
“我曾遇到因Permission Denied导致训练任务卡死的问题,最终通过chmod修复数据集目录权限,并添加set -e和错误日志监控。” -
延伸扩展:
- 特殊权限:如
SUID用于部署工具链(如 Docker 容器内的权限继承)。 - ACL 高级控制:复杂场景下使用
setfacl精细化授权。 - 安全合规:符合 GDPR/ISO 27001 的数据访问权限设计。
- 特殊权限:如
通过将 Linux 权限命令与 AI 行业场景结合,既能展示技术深度,又能体现工程化思维,这正是算法岗面试中脱颖而出的关键!
【二】两台服务器之间如何进行内网传输数据?
一、SFTP 内网数据传输
SFTP(SSH File Transfer Protocol)是基于 SSH 的安全文件传输协议,适用于加密传输敏感数据。以下是具体操作流程:
1. 配置 SSH 服务
1. SFTP 传输文件
-
连接服务端:
sftp -P 22 user@server_ip # 默认端口可省略 -P -
常用命令:
put /local/file.txt /remote/ # 上传文件 get /remote/file.txt /local/ # 下载文件 mkdir /remote/data # 创建远程目录 ls -l # 列出远程文件 exit # 退出 -
递归传输目录:
使用scp(基于 SSH 的简化命令):scp -r /local/dir user@server_ip:/remote/dir # 递归传输目录 scp -C file.zip user@server_ip:/remote/ # -C 启用压缩
2. 安全性增强
- 限制 IP 访问:
在服务端/etc/ssh/sshd_config中配置:AllowUsers user@192.168.1.0/24 # 仅允许内网 IP 段访问 - 禁用密码登录:
修改sshd_config后重启服务:PasswordAuthentication no # 仅允许密钥认证 sudo systemctl restart sshd
二、实际案例:分布式训练中的安全数据同步
场景:
在训练多模态大模型(如 GPT-4)时,需将服务器 A 的预处理数据集(含敏感文本)安全传输至服务器 B 的 GPU 集群。
操作:
-
配置免密登录:
# 在服务器 B(客户端)生成密钥并上传至服务器 A(服务端) ssh-keygen -t rsa ssh-copy-id -i ~/.ssh/id_rsa.pub data_engineer@192.168.1.1 -
压缩并传输数据:
# 从服务器 B 拉取数据(服务端 IP: 192.168.1.1) scp -C -r data_engineer@192.168.1.1:/datasets/multimodal /local_training/ -
验证完整性:
# 生成校验和并比对 sha256sum /datasets/multimodal/*.tar > checksum.txt scp data_engineer@192.168.1.1:/datasets/multimodal/checksum.txt . sha256sum -c checksum.txt # 检查文件是否完整
三、在 AI 领域中的实际应用
1. AIGC(生成式 AI)场景
-
应用背景:
训练 Diffusion 模型时,需在多台服务器间传输:- 版权素材库:使用 SFTP 加密传输受版权保护的训练图片/视频,避免明文泄露。
- 模型权重同步:将微调后的模型安全分发至推理服务器(如
scp model.ckpt user@inference_server:/models)。
-
意义:
符合数据隐私法规(如 GDPR),防止生成内容被恶意篡改。
2. 传统深度学习场景
-
应用背景:
跨团队协作中的敏感数据处理:- 医疗数据共享:医院内网中通过 SFTP 传输脱敏的 CT 扫描数据至训练服务器。
- 联邦学习参数同步:各参与方通过 SFTP 加密上传本地模型梯度至聚合服务器。
-
意义:
满足 HIPAA 等医疗数据合规要求,保障隐私。
3. 自动驾驶场景
-
应用背景:
车端与云端的数据交互:- 传感器日志回传:通过 SFTP 将车载摄像头/雷达的原始数据加密上传至云端分析平台。
- 高精地图更新:增量下载加密的地图差分文件至车载计算单元(如
sftp get /maps/update.bin)。
-
意义:
防止 CAN 总线数据被中间人攻击,满足 ISO 21434 汽车网络安全标准。
四、面试回答技巧
-
结合项目经验:
“在上一份工作中,我们通过 SFTP + 密钥认证,每日将 10TB 的自动驾驶路测数据从边缘服务器同步至云端,传输错误率降至 0.01%。” -
延伸技术栈:
- 跳板机架构:通过 Bastion Host 中转访问生产环境服务器,增强安全性。
- 证书双向认证:使用 OpenSSL 签发客户端/服务端证书,实现双向验证。
-
行业趋势:
“在 AIGC 领域,未来可能结合加密信道与 SFTP,应对针对AIGC大模型的窃取攻击。”
通过将 SFTP 的技术细节与 AI 行业场景结合,既能体现工程能力,又能展现对数据安全和业务需求的理解,这正是算法工程师的能学到的核心知识!
开放性问题
Rocky从工业界、学术界、竞赛界以及应用界角度出发,总结AI行业的本质思考。这些问题不仅能够用于面试官的提问,也可以用作面试者的提问,在面试的最后阶段让面试双方进入深度的探讨与交流。
与此同时,这些开放性问题也是贯穿我们职业生涯的本质问题,需要我们持续的思考感悟。这些问题没有标准答案,Rocky相信大家心中都有自己对于AI行业的认知与判断,欢迎大家在留言区分享与评论。
【一】AI算法工程师如何将工作中的实践价值最大化?
Rocky认为这是AI算法工程师职业生涯中非常关键的一点,将实践价值举一反三,并挖掘出长期沉淀性,是大家毕生的思考点。
【二】如何给一个完全没有接触过传统深度学习的人介绍传统深度学习?
Rocky认为这是一个非常有价值的问题,因为现在AI行业已经进入AIGC时代,同时AIGC又是一个破圈式繁荣的时代,为了更好的在AIGC时代前行,我们需要了解AI行业的发展脉络,就需要深刻了解传统深度学习时代。
推荐阅读
1、加入AIGCmagic社区知识星球!
AIGCmagic社区知识星球不同于市面上其他的AI知识星球,AIGCmagic社区知识星球是国内首个以AIGC全栈技术与商业变现为主线的学习交流平台,涉及AI绘画、AI视频、大模型、AI多模态、数字人以及全行业AIGC赋能等100+应用方向。星球内部包含海量学习资源、专业问答、前沿资讯、内推招聘、AI课程、AIGC模型、AIGC数据集和源码等干货。
那该如何加入星球呢?很简单,我们只需要扫下方的二维码即可。与此同时,我们也重磅推出了知识星球2025年惊喜价:原价199元,前200名限量立减50!特惠价仅149元!(每天仅4毛钱)
时长:一年(从我们加入的时刻算起)


2、AIGC时代Rocky撰写的干货技术文章汇总分享!
- Sora等AI视频大模型等全维度解析文章:https://zhuanlan.zhihu.com/p/706722494
- Stable Diffusion 3和FLUX.1的10万字全维度解析文章:https://zhuanlan.zhihu.com/p/684068402
- Stable Diffusion XL的10万字全维度解析文章:https://zhuanlan.zhihu.com/p/643420260
- Stable Diffusion 1.x-2.x的10万字全维度解析文章:https://zhuanlan.zhihu.com/p/632809634
- ControlNet系列的全维度解析文章:https://zhuanlan.zhihu.com/p/660924126
- LoRA系列模型的全维度解析文章:https://zhuanlan.zhihu.com/p/639229126
- Transformer全维度解析文章:https://zhuanlan.zhihu.com/p/709874399
- 最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2025年版)》文章:https://zhuanlan.zhihu.com/p/651076114
- 50万字大汇总《“三年面试五年模拟”之算法工程师的求职面试“独孤九剑”秘籍》文章:https://zhuanlan.zhihu.com/p/545374303
- Stable Diffusion WebUI、ComfyUI等AI绘画框架的全维度解析文章:https://zhuanlan.zhihu.com/p/673439761
- GAN系列模型的全维度解析文章:https://zhuanlan.zhihu.com/p/663157306
3、其他
Rocky将YOLOv1-v7全系列大解析文章也制作成相应的pdf版本,大家可以关注公众号WeThinkIn,并在后台 【精华干货】菜单或者回复关键词“YOLO” 进行取用。
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











