









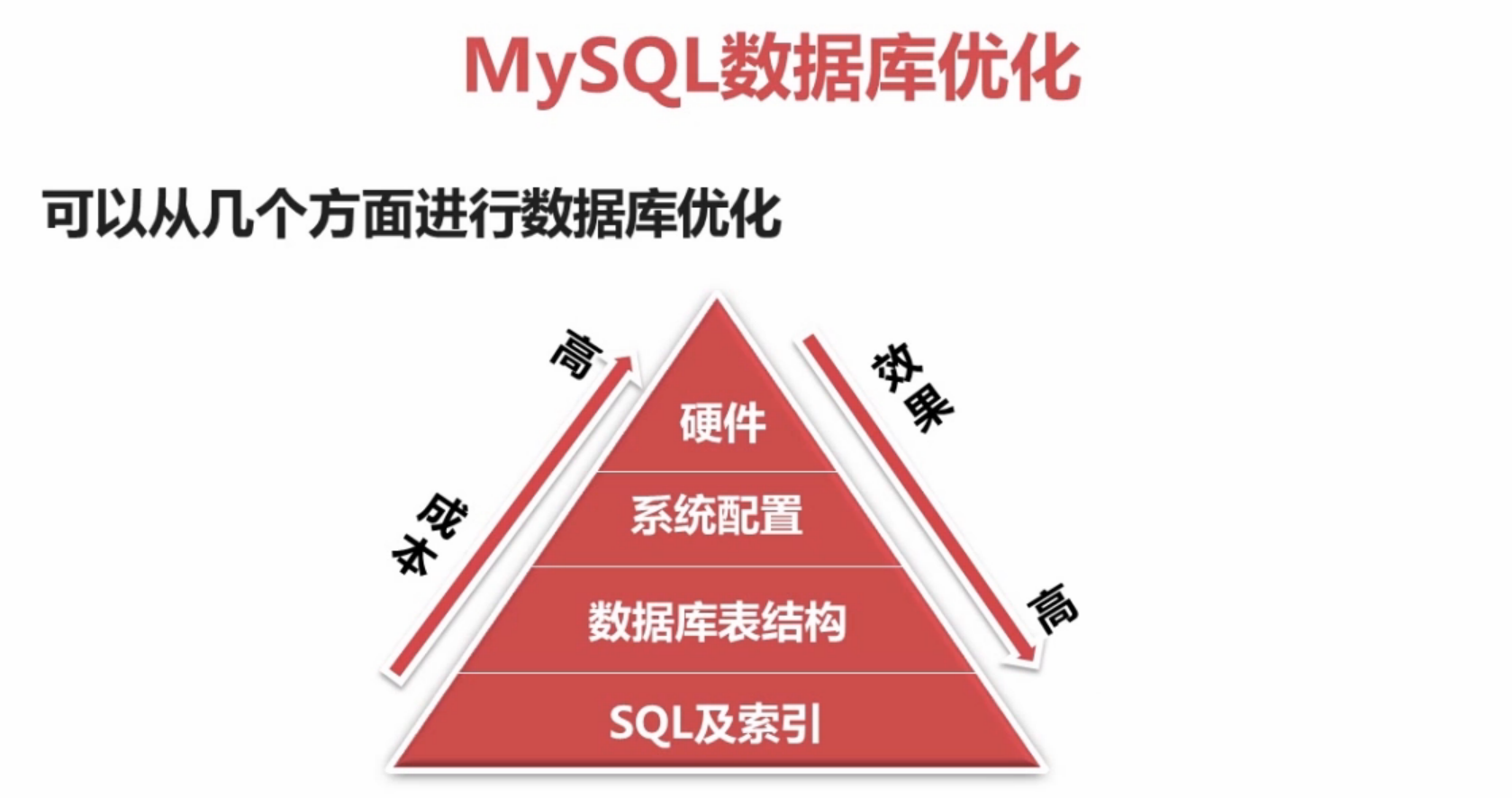
① Mysql优化的思路
1,SQL语句优化和索引优化
2,数据库表结构的优化
3,系统配置
4,硬件优化
②
查看慢查询日志状态:show variables like ‘slow_query_log’
如果上面的结果是OFF,开启慢查询日志:set global slow_query_log=on
log_queries_not_using_indexes表示将记录未使用键的查询。设置为on表示开启。
long_query_time=1表示将记录超过1s的查询。


安装pt-query-digest:
wget http://www.percona.com/get/pt-query-digest
chmod u+x pt-query-digest
移动到/usr/bin/等目录下。
pt-query-digest这个比较好。
③需要注意的sql语句
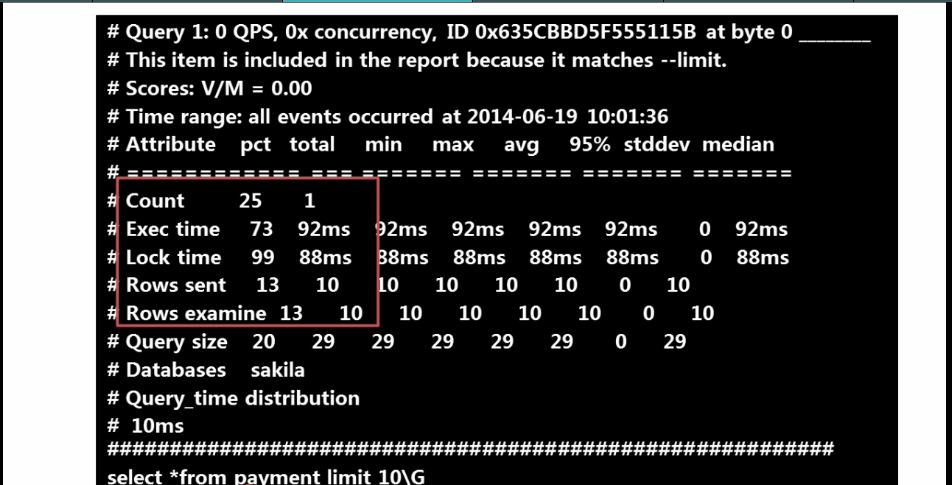
1) 查询次数多且每次查询占用时间长的SQL
通常是pt_query_digest分析的第三部分前几条
2) IO大的SQL
注意pt_query_digest分析中的Rows examine项
数据库大多数的瓶颈都是IO瓶颈
3) 未命中索引的SQL
注意pt_query_digest分析中Rows examine 和Rows Send的对比
④
mysql> explain select customer_id,first_name,last_name from customer;
返回值的表格对应的信息
table:表名;
type:连接的类型,const、eq_reg、ref、range、index和ALL;const:主键、索引;eq_reg:主键、索引的范围查找;ref:连接的查找(join),range:索引的范围查找;index:索引的扫描;
possible_keys:可能用到的索引;
key:实际使用的索引;
key_len:索引的长度,越短越好;
ref:索引的哪一列被使用了,常数较好;
rows:mysql认为必须检查的用来返回请求数据的行数;
extra:using filesort、using temporary(常出现在使用order by时)时需要优化。
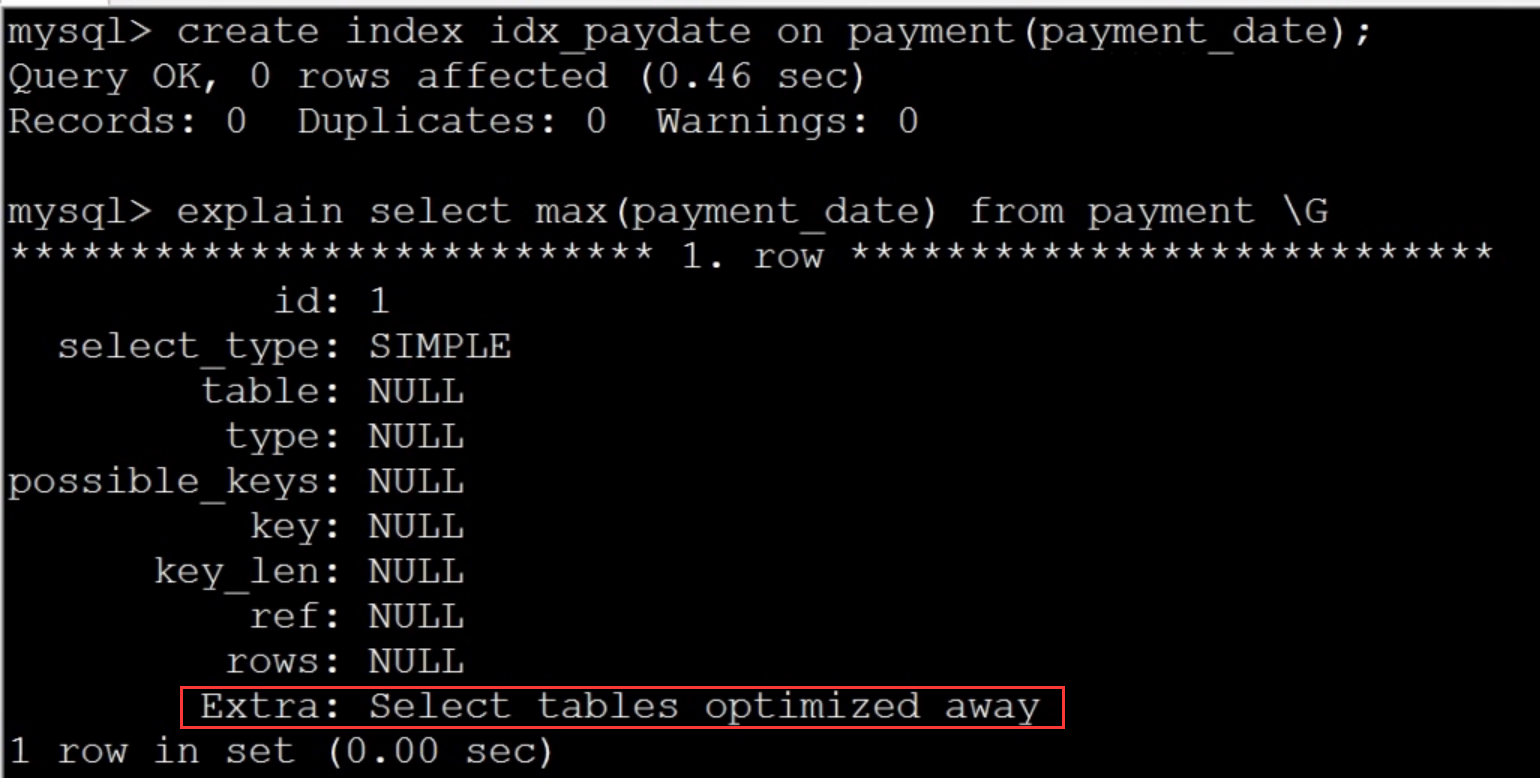
⑤ 关于max() 和count()的优化
max的查询可以通过索引的方式优化:create index idx_paydate on payment(payment_date);
覆盖索引
没创建索引的时候使用max会对整个表都进行查询
创建索引后使用max,因为索引是会按照数据大小排序的。
Max()和Count()的优化
1.对max()查询,可以为表创建索引,create index index_name on table_name(column_name 规定需要索引的列),然后在进行查询
2.count()对多个关键字进行查询,比如在一条SQL中同时查出2006年和2007年电影的数量,语句:
select count(release_year=’2006’ or null) as ‘2006年电影数量’,
count(release_year=’2007’ or null) as ‘2007年电影数量’
from film;
3.count(*) 查询的结果中,包含了该列值为null的结果
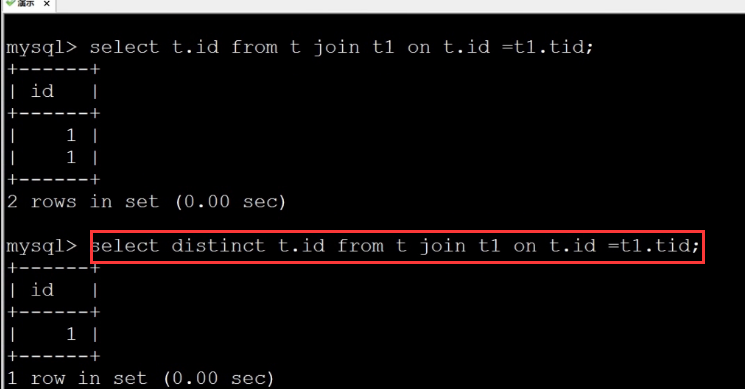
⑥子查询优化
子查询优化成join
子查询一对一 不会有重复的记录
joiin如果存在一对多 结果会有重复 利用distinct去重
⑦group by的优化
group by可能会出现临时表(Using temporary),文件排序(Using filesort)等,影响效率。
可以通过关联的子查询,来避免产生临时表和文件排序,可以节省io
改写前
select actor.first_name,actor.last_name,count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;改写后
select actor.first_name,actor.last_name,c.cnt
from sakila.actor inner join(
select actor_id,count(*) as cnt from sakila.film_actor group by
actor_id
)as c using(actor_id);⑧limit的优化方式
limit常用于分页处理,时常会伴随order by从句使用,因此大多时候会使用Filesorts这样会造成大量的io问题
1.使用有索引的列或主键进行order by操作,使用主键排序的话会大大提高功能
2.记录上次返回的主键,在下次查询时使用主键过滤
使用这种方式有一个限制,就是主键一定要顺序排序和连续的,如果主键出现空缺可能会导致最终页面上显示的列表不足5条,解决办法是附加一列,保证这一列是自增的并增加索引就可以了
⑨ 建立索引
选择合适的索引列
1.在where,group by,order by,on从句中出现的列
2.索引字段越小越好(因为数据库的存储单位是页,一页中能存下的数据越多越好 )
3.离散度大得列放在联合索引前面
select count(distinct customer_id), count(distinct staff_id) from payment;
查看离散度 通过统计不同的列值来实现 count越大 离散程度越高
当一个索引包含了这个查询里面的所有列,就称之为覆盖索引
⑩索引优化sql方法
过多的索引不但影响写入,而且影响查询,索引越多,分析越慢
如何找到重复和多余的索引,主键已经是索引了,所以primay key 的主键不用再设置unique唯一索引了
冗余索引,是指多个索引的前缀列相同,innodb会在每个索引后面自动加上主键信息
冗余索引查询工具
pt-duplicate-key-checker
//查找出重复的索引
SELECT a.TABLE_SCHEMA AS '数据名'
,a.TABLE_NAME AS '表名
,a.INDEX_NAME AS '索引1'
,b.INDEX_NAME AS '索引2'
,a.COLUMN_NAME AS '重复列名'
FROM STATISTICS a
JOIN STATISTICS b ON a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX
AND a.COLUMN_NAME = b.COLUMN_NAME
WHERE a.SEQ_IN_INDEX = 1 AND a.INDEX_NAME <> b.INDEX_NAME关于表设计功能待续。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









