






一、可扩展哈希表
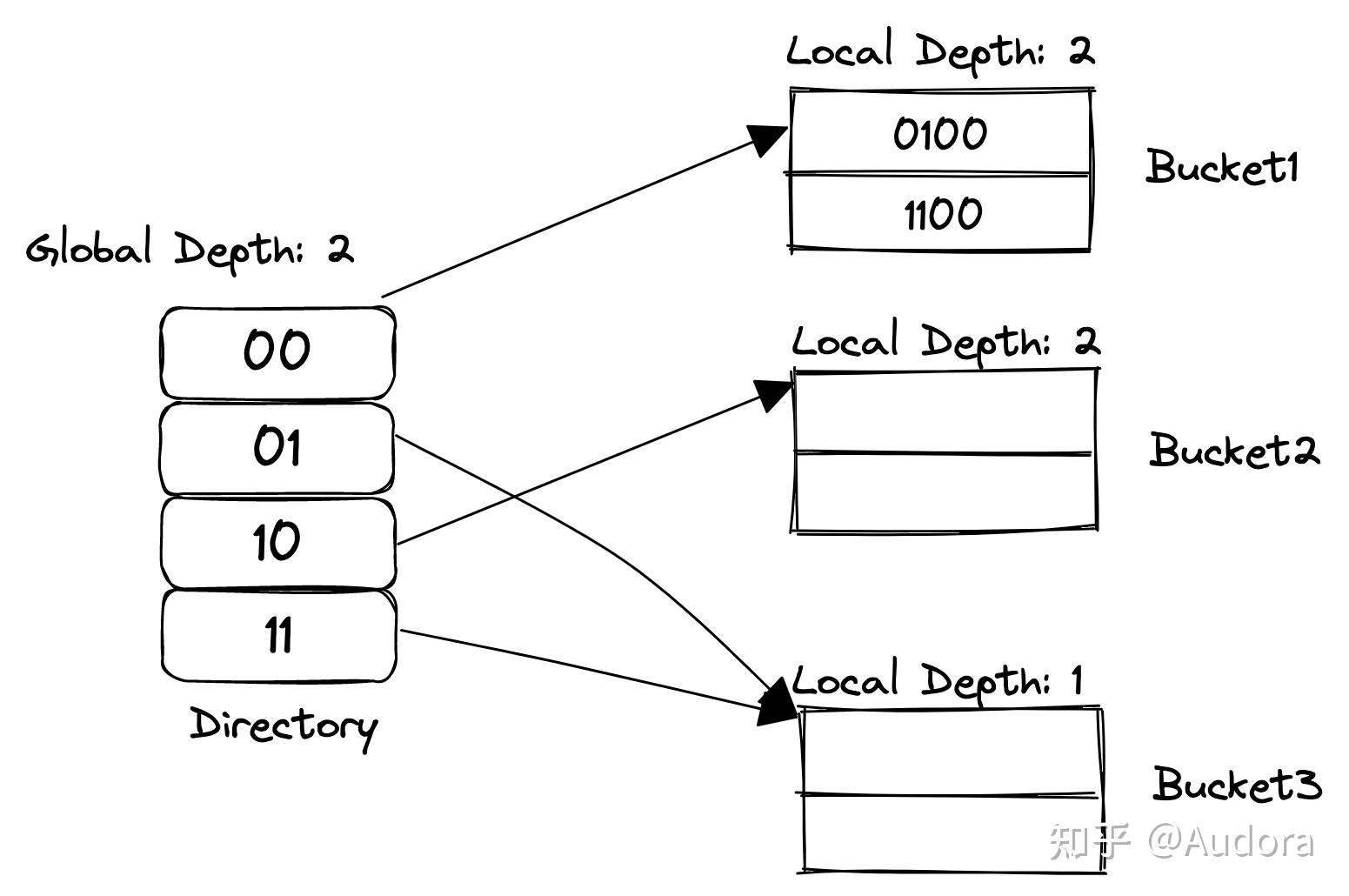
搞清楚全局深度、局部深度和桶大小的概念
全局深度规定取索引最后几位,针对的是vector dir_,局部深度类似,桶大小是定死的不会变。局部深度和全局深度一样时,会造成全局深度+1,发生扩容。
底层实现:vector数组存放bucket指针,bucket底层是一个链表,存放hash之后对应key的数据。
vector扩容时后一半的新空间和前一半的指向完全相同。(索引计算的规律)
二、LRU-K
需要一个历史队列(哈希表+链表)和一个缓存队列(哈希表+链表),一个访问次数记录表(哈希表),一个是否能驱逐记录表(哈希表)
1、每访问一个key,则把访问次数加1
2、到达k次后,从历史队列里弹出,加入到缓存队列里,更新所在队列位置(加入队列首部)
3、注意,历史队列里的位置不变化,只改变缓存队列的位置
4、执行驱逐时,先弹出历史队列,直到历史队列为空,再弹出缓存队列
5、驱逐时从队列尾部弹出元素,新访问的元素在首部

三、缓存池管理器
pin_count,为0表示该frame可以被驱逐或者是空闲的,>0则不能被驱逐,正在使用。
底层:空闲链表,page数组,page_table(可扩展哈希表,记录哪个page存放在哪个frame里)
关键:NewPgImp和FetchPgimp
NewPgImp是在缓冲池上创建一个新的page对象,等待读写操作之后flush回磁盘
FetchPgimp是从磁盘上读入一个page到缓存池上来
两个函数有很多共同之处,实现时需要注意:
1、利用pin_count是否为0来判断缓冲池上有无frame空余或者可以替换
2、空闲链表提供空闲的frame
3、空闲链表为空,需要执行驱逐
4、被驱逐的页面为脏,需要writepage写回磁盘
5、被驱逐的page,需要在page数组上把该位置清空,等新page填入
6、新进入缓存池的page的pin-count为1,且设置不能被驱逐,因为后续可能会读写操作它
















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









