







论文地址:https://arxiv.org/abs/2408.09720
代码地址:https://github.com/Event-AHU/OpenPAR
bib引用:
@misc{
jin2024pedestrianattributerecognitionnew,
title={
Pedestrian Attribute Recognition: A New Benchmark Dataset and A Large Language Model Augmented Framework},
author={
Jiandong Jin and Xiao Wang and Qian Zhu and Haiyang Wang and Chenglong Li},
year={
2024},
eprint={
2408.09720},
archivePrefix={
arXiv},
primaryClass={
cs.CV},
url={
https://arxiv.org/abs/2408.09720},
}
InShort
围绕行人属性识别(PAR)展开研究,提出新的基准数据集MSP60K和基于大语言模型增强的框架LLM-PAR:
- 研究背景与问题:PAR在计算机视觉和人工智能领域应用广泛,但当前模型受低光照、运动模糊等因素影响,且现有数据集存在性能饱和、忽视跨域影响、未突出挑战因素等问题,阻碍了PAR发展。
- 相关工作:介绍PAR的现有方法,包括先验引导、基于注意力和视觉语言建模等;回顾常用PAR基准数据集,如PETA、WIDER等及其问题;阐述视觉语言模型发展及在视觉任务中的挑战。
- MSP60K基准数据集
- 构建准则:大规模(标注60,122张图像,每张57个属性)、多距离和视角、复杂多样场景、丰富行人身份来源、模拟复杂真实环境。
- 属性分组与细节:57个属性分为11组,涵盖性别、年龄、着装等方面。
- 统计分析:数据规模大、场景丰富,采用随机和跨域分割策略,并对部分图像进行合成退化处理。具有长尾效应,不同场景属性分布不同。
- 基准基线:评估17种代表性PAR模型,包括基于CNN、Transformer等不同类型。
- 方法
- LLM-PAR框架概述:由多标签分类分支、大语言模型分支和模型聚合三部分组成,利用大语言模型探索属性间上下文关系辅助属性识别。
- 多标签分类分支:将图像分块投影为视觉令牌,经视觉编码器提取全局特征,MEQ-Former提取特定属性组特征,再用CBAM模块生成属性预测。
- 大语言模型分支:构建指令,获取指令嵌入与视觉特征拼接,输入大语言模型生成图像描述。
- 模型聚合:定义属性级和实例级分类器,融合两个分支结果提升预测效果。
- 损失函数:多标签分类分支用加权交叉熵损失,大语言模型分支用交叉熵损失。
- 实验
- 数据集与评估指标:在PETA、PA100K等多个数据集上对比17种方法,采用平均准确率(mA)等5种指标评估性能。
- 实现细节:训练时用模板扩展属性微调大语言模型,采用掩蔽策略防止信息泄露;推理时根据指令和图像特征生成结果。
- 对比实验结果:LLM-PAR在多个数据集上取得最优或接近最优结果,验证了有效性。
- 组件分析与消融实验:分析各组件贡献,研究不同模块设置对性能影响,如真值掩蔽策略、AGFA层数等。
- 可视化:展示LLM-PAR识别结果和特征图,其能准确识别属性,特征图可聚焦行人特定区域。
- 结论与展望:MSP60K数据集和LLM-PAR框架有效,未来计划扩大数据集规模并设计轻量级模型平衡精度和性能。
摘要
Pedestrian Attribute Recognition (PAR) is one of the indispensable tasks in human-centered research. However, existing datasets neglect different domains (e.g., environments, times, populations, and data sources), only conducting simple random splits, and the performance of these datasets has already approached saturation. In the past five years, no large-scale dataset has been opened to the public. To address this issue, this paper proposes a new large-scale, cross-domain pedestrian attribute recognition dataset to fill the data gap, termed MSP60K. It consists of 60,122 images and 57 attribute annotations across eight scenarios. Synthetic degradation is also conducted to further narrow the gap between the dataset and real-world challenging scenarios. To establish a more rigorous benchmark, we evaluate 17 representative PAR models under both random and cross-domain split protocols on our dataset. Additionally, we propose an innovative Large Language Model (LLM) augmented PAR framework, named LLM-PAR. This framework processes pedestrian images through a Vision Transformer (ViT) backbone to extract features and introduces a multi-embedding query Transformer to learn partial-aware features for attribute classification. Significantly, we enhance this framework with LLM for ensemble learning and visual feature augmentation. Comprehensive experiments across multiple PAR benchmark datasets have thoroughly validated the efficacy of our proposed framework. The dataset and source code accompanying this paper will be made publicly available at https://github.com/ Event-AHU/OpenPAR.
行人属性识别 (PAR) 是以人为中心的研究中不可或缺的任务之一。然而,现有的数据集忽略了不同的领域(例如,环境、时间、人口和数据源),只进行简单的随机拆分,这些数据集的性能已经接近饱和。近 5 年来,没有大规模的数据集向公众开放。为了解决这个问题,本文提出了一种新的大规模、跨域行人属性识别数据集来填补数据空白,称为 MSP60K。它由 8 个场景中的 60,122 张图像和 57 个属性注释组成。还进行了合成降级,以进一步缩小数据集与现实世界具有挑战性的场景之间的差距。为了建立更严格的基准,我们在数据集上评估了随机和跨域拆分协议下的 17 个代表性 PAR 模型。此外,我们还提出了一种创新的大型语言模型 (LLM) 增强 PAR 框架,名为 LLM-PAR。该框架通过 Vision Transformer (ViT) 主干网处理行人图像以提取特征,并引入多嵌入查询 Transformer 来学习用于属性分类的部分感知特征。值得注意的是,我们使用 LLM 增强了这个框架,用于集成学习和视觉特征增强。跨多个 PAR 基准数据集的全面实验彻底验证了我们提出的框架的有效性。本文随附的数据集和源代码将在 https://github.com/ Event-AHU/OpenPAR 上公开提供。
Introduction
研究现状
考虑到这些问题,我们仔细审查了 PAR 的现有工作和数据集,发现 PAR 领域的发展已开始进入瓶颈期。基准数据集作为推动 PAR 发展的有效推动力,发挥着至关重要的作用。但是,我们认为 PAR 社区需要解决基准数据集上的几个核心问题,如下所示:1). 现有行人属性识别数据集的性能接近饱和,新算法的性能提升呈减弱趋势。然而,在过去五年中,只有一个小规模的 PAR 相关数据集发布,因此迫切需要新的大规模数据集来支持新的研究工作。2). 现有的 PAR 数据集使用随机分区进行模型训练和测试,可以衡量 PAR 模型的整体识别能力。然而,这种分区机制忽略了跨域(例如,不同的环境、时间、群体和数据源)对 PAR 模型的影响。3). 现有的 PAR 数据集没有突出反映挑战因素,因此,这可能会导致在实际应用中忽视数据损坏的影响,从而在实际环境中引入安全隐患。总之,很明显,PAR 社区迫切需要一个新的大规模数据集来弥合现有的数据差距。

图 1.(a, b) 的现有 PAR 数据集与我们新提出的 MSP60K 数据集之间的比较。说明了我们在数据集中采用的合成降解挑战,以模拟复杂和动态的真实世界环境。
本文工作
在本文中,我们提出了一个新的基准数据集用于行人属性识别,称为 MSP60K,如图 1 所示。它包含 60,122 张图像和 5,000 多个个人 ID,这些图像是使用智能监控系统和移动电话收集的。
为了使我们的数据集更好地反映真实场景中的挑战,除了注释尽可能多的复杂图像外,我们还使用额外的破坏性操作来处理这些图像,包括模糊、遮挡、照明、添加噪点、jpeg 压缩等。由于这些图像属于不同的领域和场景,例如超市、厨房、建筑工地、滑雪场和各种户外场景,我们根据随机切分和跨域两种协议对这些图像进行切分。因此,新提出的基准数据集可以更好地验证 PAR 模型在真实场景中的性能,尤其是在跨域设置下。为了构建更全面的行人属性识别基准数据集,我们还训练并报告了 17 种具有代表性和最近发布的 PAR 算法。这些基准比较方法可以更好地促进未来 PAR 模型的后续验证和实验。
基于新提出的 MSP60K PAR 数据集,还提出了一种新的大型语言模型 (LLM) 增强行人属性识别框架,称为 LLM-PAR。基于广泛使用的多标签分类框架,我们重新思考行人图像感知与大语言模型之间的关系,作为这项工作的关键洞察。众所周知,大型语言模型在文本生成、理解和推理方面具有强大的能力。因此,我们引入了一个大型语言模型,该模型基于多标签分类框架生成图像属性的文本描述作为辅助任务。
这个 LLM 分支有双重目的:
一方面,它可以通过生成准确的文本描述来辅助视觉特征的学习,从而实现高性能的属性识别;
另一方面,LLM 可以促进视觉特征和提示之间的有效交互。输出文本标记也可以与上述多标签分类框架集成,用于集成学习。
As shown in Fig. 5, our proposed LLM-PAR can be divided into two main modules, i.e., the standard multi-label classification branch and the large language model augmentation branch. Specifically, we first partition the given pedestrian image into patches and project them into visual embeddings. Then, a visual encoder with LoRA [8] is utilized for global feature learning and a Multi-Embedding Query TransFormer (MEQ-Former) is proposed for partaware feature learning. After that, we adopt CBAM [40] attention modules to merge the output tokens and feed them into MLP (Multi-Layer Perceptron) layers for attribute classification. More importantly, we concatenate the part-aware visual tokens with the instruction prompt and feed them into the large language model for pedestrian attribute description. The text tokens are also fed into an attribute recognition head and ensembles with classification logits.
【LLM-PAR】:多标签分类+LLM数据增强
- 给定的行人图像划分为块,并将它们投影到视觉嵌入中。
- 利用带有 LoRA [8] 的视觉编码器进行全局特征学习,并提出了一种多嵌入查询 TransFormer (MEQ-Former) 用于部件感知特征学习。【BLIPv2用的也是QFormer】
- 采用 CBAM [40] 注意力模块来合并输出标记,并将它们馈送到 MLP(多层感知器)层进行属性分类。
- 将零件感知的视觉标记与指令提示连接起来,并将它们输入到行人属性描述的大型语言模型中。文本标记也被馈送到属性识别头和带有分类 logit 的集合中。
在新提出的 MSP60K 数据集和其他广泛使用的 PAR 基准数据集上进行的广泛实验都验证了我们提出的 LLM-PAR 的有效性。
2. 相关工作
2.1. 行人属性识别
行人属性识别 [ 36 ] 1 [36] ^{1} [36]1 旨在根据一组预定义的属性对行人图像进行分类。目前的方法大致可分为先验引导、基于注意力和视觉语言建模方法。鉴于行人属性与特定身体组成部分之间的强相关性。各种方法,如 HPNet [26] 和 DAHAR [26, 43],都侧重于通过注意力机制定位属性相关区域。姿势和视点的变化通常会对行人属性识别构成挑战。为了应对这些挑战,一些研究人员 [10, 30] 结合了先前的增强技术或引入补充神经网络来有效地模拟这些关系。此外,行人属性密切相关。因此,JLAC [32] 和 PromptPAR [37] 联合建模属性上下文和图像属性关系。虽然当前方法认识到在 PAR 任务中探索上下文关系的重要性,但利用 Transformers 等模型来捕获数据集中的属性关系通常难以表示涉及稀有属性的连接。
2.2. PAR的基准数据集
最常用的 PAR 数据集是 PETA [3]、WIDER [22]、RAP [17, 18] 和 PA100K [26]。
为了增强远距离识别行人属性的能力,邓等[3]引入了一个名为PETA的新行人属性数据集,该数据集由10个小规模行人再识别数据集编译而成,标记了60多个属性。
与 PETA 的身份级注释不同,RAP 数据集捕获了一个室内购物中心,并对行人图像使用了实例级注释。PETA 和 RAPv1 数据集都存在随机分割的问题,即出现在训练集中的个体也出现在测试集中,导致信息泄露。
为了解决这个问题,Liu 等 [26] 提出了监控场景中最大的行人属性识别数据集 PA100K,其中包含 100,000 张行人图像和 26 个属性。该数据集通过确保训练集和测试集中的行人之间没有重叠来缓解信息泄露问题。但是,这些数据集仅包含
2.3. 视觉语言模型
随着自然语言处理领域的快速发展,出现了许多大型语言模型(LLM),如Flan-T5 [27]和LLaMA [34]。尽管在视觉领域引入了像 SAM [15] 这样著名的基础模型,但视觉任务的复杂性阻碍了广义多域视觉模型的发展。一些研究人员已经开始将 LLM 视为世界模型,利用它们作为认知核心来增强各种多模态任务。认识到从头开始训练大型多模态模型的高成本,BLIP 系列 [19, 20]、MiniGPT-4 [50] 将现有的预训练视觉模型和大型语言模型连接起来。尽管这些模型在视觉理解和文本生成领域有了显着改进,但仍然存在许多挑战,例如低分辨率图像识别、细粒度图像描述和 LLM 的幻觉。
补充1:LLM幻觉类型、原因、解决方案
幻觉可以分为几种类型:
- 逻辑谬误:模型在进行推理时出现了错误,提供错误的答案。
- 捏造事实:模型自信地断言不存在的事实,而不是回答“我不知道”。
- 例如:谷歌的 AI 聊天机器人 Bard 在第一次公开演示中犯了一个事实错误。
- 数据驱动的偏见:由于某些数据的普遍存在,模型的输出可能会偏向某些方向,导致错误的结果。
- 例如:自然语言处理模型中发现的政治偏见。
大语言模型中的幻觉源于数据压缩(data compression)和不一致性(inconsistency)。 由于许多数据集可能已经过时或不可靠,因此质量保证具有挑战性。为了减轻幻觉,可以采取以下方法:
- 调整temperature参数以限制模型的创造力。 (temperature参数控制生成语言模型中生成文本的随机性和创造性,调整模型的softmax输出层中预测词的概率;其值越大,则预测词的概率的方差减小,即很多词被选择的可能性增大,利于文本多样化)
- 注意提示工程。要求模型逐步思考,并在回复中提供事实性信息和参考来源。
- 整合外部知识源来改进答案验证(answer verification)。
更多参考:
LLM 幻觉:现象剖析、影响与应对策略
OpenAI Lilian Weng万字长文解读LLM幻觉:从理解到克服
表 1.MSP60K 与现有 PAR 基准测试数据集之间的比较。
| Dataset | Year | Attributes | Images | Scene Split |
|---|---|---|---|---|
| PETA [3] | 2014 | 61 | 19,000 | X |
| WIDER [22] | 2016 | 14 | 57,524 | |
| RAPv1 [17] | 2016 | 69 | 41,585 | |
| PA100K [26] | 2017 | 26 | 100,000 | |
| RAPv2[18] | 2019 | 76 | 84,928 | xxxx> |
| Ours | 2024 | 57 | 60.015 |
表 2.MSP60K 数据集中定义的属性组和详细信息。
| Attribute Group | Details |
|---|---|
| Gender | Female |
| Age | Child, Adult, Elderly |
| Body Size | Fat, Normal, Thin |
| Viewpoint | Front, Back, Side |
| Head | Bald, Long Hair, Black Hair, Hat Glasses, Mask, Helmet, Scarf, Gloves |
| Upper Body | Short Sleeves, Long Sleeves, Shirt, Jacket, Suit, Vest Cotton Coat, Coat, Graduation Gown, Chef Uniform |
| Lower Body | Trousers, Shorts, Jeans, Long Skirt, Short Skirt, Dress |
| Shoes | Leather Shoes, Casual Shoes, Boots, Sandals, Other Shoes |
| Bag | Backpack, Shoulder Bag, Hand Bag Plastic Bag, Paper Bag, Suitcase, Others |
| Activity | Calling. Smoking. Hands Back, Arms Crossed |
| Posture | Walking, Running, Standing, Bicycle, Scooter, Skatcboard |
3. MSP60K基准数据集【 60,122 张行人图像,每张图像有 57 个属性】
3.1. 协议
为了提供一个强大的平台来训练和评估真实条件下的行人属性识别 (PAR),我们在构建 MSP60K 基准数据集时遵循以下准则:
1.大规模:我们注释了 60,122 张行人图像,每张图像有 57 个属性,全面分析了各种条件下的行人特征。
2. 多个距离和视点:使用各种相机和手持设备从不同的角度和距离捕获图像,覆盖前视图、后视图和侧视图。我们数据集中行人图像的分辨率从 30×80 到 2005×3008。
3. 复杂多样的场景:与具有统一背景的现有数据集不同,我们的数据集包括来自八种不同环境的图像,具有不同的背景和属性分布,有助于评估不同设置下的识别方法。
4. 丰富的行人身份来源:我们收集来自不同场景、国籍和季节变化的行人数据,增强具有不同风格和特征的数据集。
5. 模拟复杂的真实世界环境:该数据集包括照明、运动模糊、遮挡和恶劣天气条件的变化,模拟行人属性识别的真实挑战。
3.2. 属性组和详细信息
为了有效地评估现有 PAR 方法在复杂场景下的性能,我们数据集中的每张图像都标有 57 个属性,这些属性分为11 组:性别、年龄、体型、视点、头部、上半身、下半身、鞋子、包、身体运动和运动信息。表 2 中提供了已定义属性的完整列表。
3.3. 统计分析
如表 1 所示,MSP60K 提供 8 个不同的场景和 57 个属性,提供比 PA100K(26 个属性)和 WIDER(14 个属性)等数据集更丰富的注释。该数据集包含 60,122 张图像,超过 5,000 张独特的图像分度。它包括各种环境,例如市场、学校、厨房、滑雪胜地、各种户外和建筑工地,提供比其他数据集更广泛的范围。
在我们的基准测试数据集中,我们使用随机和跨域分区策略来拆分数据:
- 随机分区:30,298 张图像用于训练,6,002 张图像用于验证,23,822 张用于测试,确保场景的随机分布,就像其他 PAR 基准测试数据集一样。
- 跨域分区:为了验证 PAR 模型的域泛化和零镜头性能,我们根据场景划分数据集,即使用五个场景(建筑工地、市场、厨房、学校、滑雪场)34,128 张图像进行训练,而三个场景(Outdoors1、Outdoors2、Outdoors3)24,994 张图像用于测试。
为了评估模型的稳健性,我们通过引入照明变化、随机遮挡、模糊和噪声等变化,有意降低每个子集中 1/3 的图像质量。MSP60K 具有广泛的尺寸和多样化的条件,为评估 PAR 方法提供了一个全面的平台。
该数据集还表现出长尾效应,类似于现有的 PAR 数据集,如图 2 (a) 所示,并反映了现实世界的属性分布。图 2 (b) 显示了行人属性的共现矩阵,其中每个单元格表示两个属性一起出现的频率。较暗的区域表示共现频率较高。例如,棉衬外套和长袖具有很强的关联,而秃头和长发/黑发等属性很少同时出现。图 2 (c) 显示了不同场景(如建筑工地、市场、厨房等)中的属性分布,属性在同心圆图中用不同的颜色表示。例如,School 场景具有更多的 Child 属性,而 Outdoors3 场景显示 Short Sleeves 和 Sandals 属性的普遍性更高。
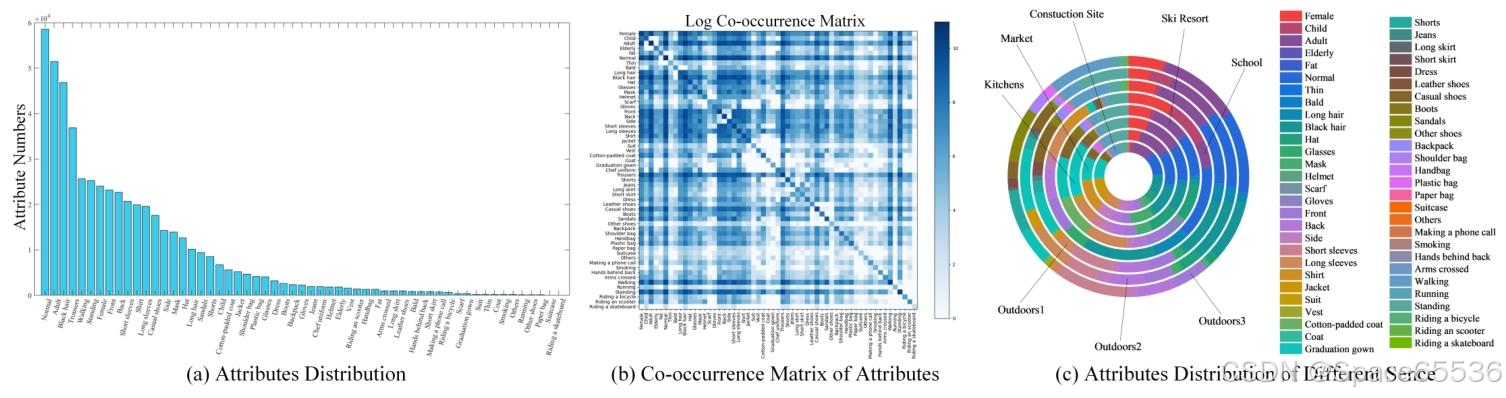
图 2.(a) 属性分布:显示数据集中各个属性的普遍性的条形图;(b) 属性共现矩阵:显示属性对共现频率的对数热图;(c) 不同场景中的属性分布:圆形图表,说明了 8 个不同场景中的属性分布。
3.4. Benchmark Baselines
我们的评估涵盖多种方法(共 17 种),包括:
1)基于 CNN:DeepMAR [16]、RethinkPAR [11]、SSCNet [10]、SSPNet [31]。
2)基于Transformer :DFDT [46]、PARFormer [5]。
3) 基于Mamba :MambaPAR [39]、MaHDFT [38]。
4)PAR Human centric 的预训练模型:PLIP [51]、HAP [45]。
5)PAR 的视觉语言模型:VTB [2]、Label2Label [21]、PromptPAR [37]、SequencePAR [13]。
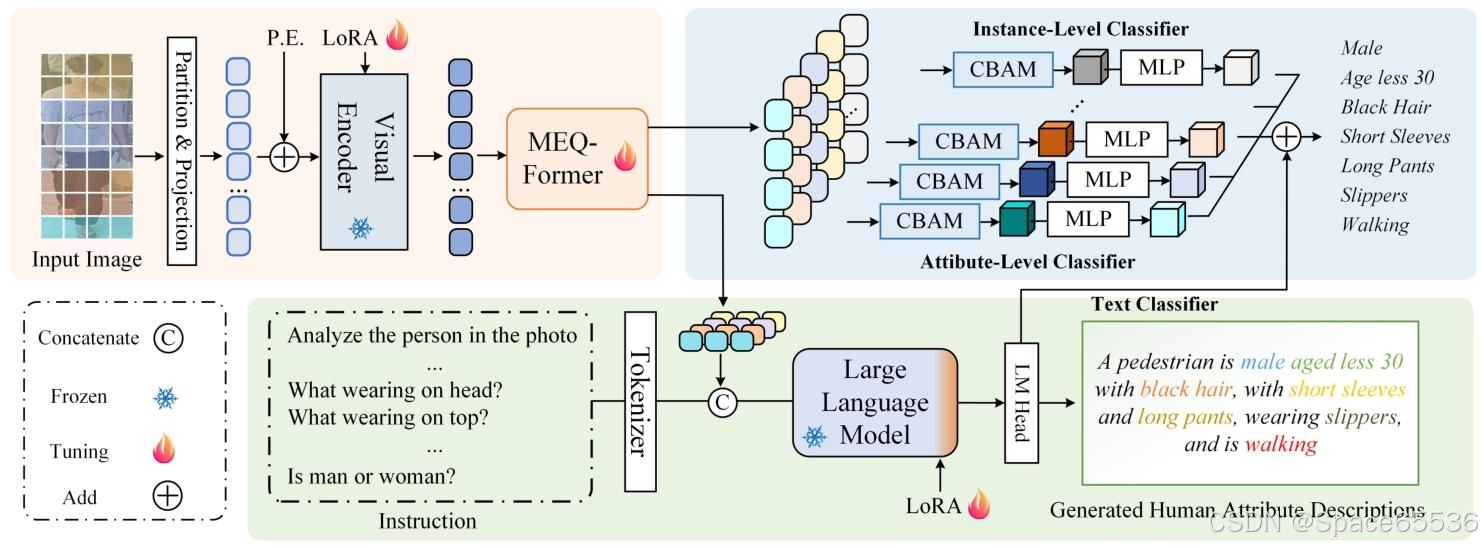
图 5.我们提出的 LLM-PAR 框架的插图说明了我们如何使用多模态大型语言模型 (MLLM) 进行深度语义推理,结合图像和描述性文本以提供更易解释的视觉理解。通过这个框架,我们可以识别行人属性并生成自然语言描述,从而提供更直观的解释。我们的框架由三个部分组成:视觉特征提取、语言描述生成和语言增强分类。
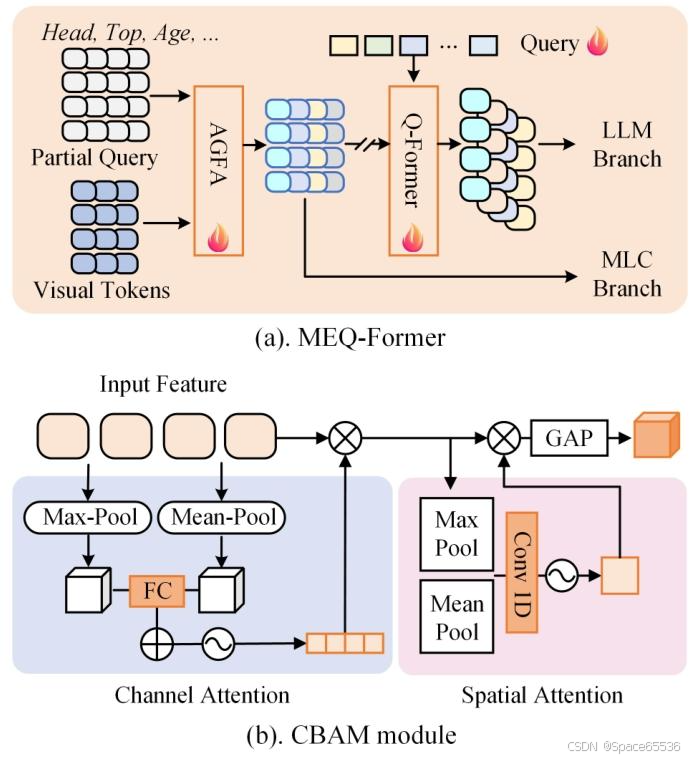
图 6.(a) 详细架构 MEQ-Former (b)CBAM 模块
4. 方法
介绍提出的行人属性识别框架 LLM-PAR。三个主要部分:视觉特征提取、图像描述生成和分类模块。
4.1. Overview
本文介绍了一种使用多模态大语言模型 (MLLM) 改进行人属性识别 (LLM-PAR) 的方法,该方法详细描述了图像。如图 5 所示,我们利用 MLLM 来探索属性之间的上下文关系,生成有助于属性识别的描述。该方法由三个主要模块组成:1) 多标签分类分支,2) 大型语言模型分支,以及 3) 模型聚合。
具体来说,我们首先使用视觉编码器提取行人的视觉特征。
然后,设计了 MEQ-Former 来提取不同属性组的特定特征并转化为 MLLM 的潜在空间。
属性组特征通过投影层集成到指令嵌入中,特征馈送到大型语言模型中以生成行人描述。
最后,将每个组的视觉特征的分类结果与语言分支的结果聚合,以生成最终的分类结果。
4.2. 多标签分类分支
给定一个输入行人图像 I ∈ R H × W × 3 I \in \mathbb{R}^{H ×W ×3} I∈RH×W×3 ,如图 5,我们首先将其划分为补丁并将它们投影到视觉标记中。视觉标记是使用位置嵌入 (P.E.) 添加的,该嵌入对空间信息进行编码。输出将被馈送到视觉编码器(默认采用 EVA-ViT-G [6])中,以提取全局视觉表示 F V F_{V} FV 。
在实现中,冻结了预训练的视觉编码器的参数,并采用 LoRA [8] 来实现高效的调整。
Multi Embedding Query Transformer (MEQ-Former) 从主要视觉特征派生的不同属性组中提取特定特征。
在这里,属性组是通过将属性分类为组 A j ∣ j = 0 , 1 , . . . , K A^{j} | j={0,1, ..., K} Aj∣j=0,1,...,K ,根据其类型(如头部、上半身服装、动作)来获取的,其中 K 表示属性组的数量。
如图 6 所示,我们创建了 K 组部分查询 (PartQ) Q p ∈ R K × L × D Q_{p} \in \mathbb{R}^{K ×L ×D} Qp∈RK×L×D ,
其中 L 和 D 分别是查询的数量和维度。
这些嵌入被馈送到属性组特征聚合 (AGFA) 模块中,以提取不同属性组的特定特征 F g = F_{g}= Fg= F g 1 , F g 2 , . . . , F g K {F_{g}^{1}, F_{g}^{2}, ..., F_{g}^{K}} Fg1,Fg2,...,FgK。
AGFA 模块由堆叠的前馈网络 (FFN) 和交叉注意力 (CrossAttn) 层组成。
这个过程可以表述为:
F g = F F N ( C r o s s A t t n ( Q = Q p , K = F V , V = F V ) ) ( 1 ) F_{g}=F F N\left(Cross Attn\left(Q=Q_{p}, K=F_{V}, V=F_{V}\right)\right) (1) Fg=FFN(CrossAttn(Q=Qp,K=F
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









