







论文地址:https://arxiv.org/abs/2305.13653
代码地址:https://github.com/Flame-Chasers/RaSa
bib引用:
@inproceedings{Bai_2023, series={IJCAI-2023},
title={RaSa: Relation and Sensitivity Aware Representation Learning for Text-based Person Search},
url={http://dx.doi.org/10.24963/ijcai.2023/62},
DOI={10.24963/ijcai.2023/62},
booktitle={Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence},
publisher={International Joint Conferences on Artificial Intelligence Organization},
author={Bai, Yang and Cao, Min and Gao, Daming and Cao, Ziqiang and Chen, Chen and Fan, Zhenfeng and Nie, Liqiang and Zhang, Min},
year={2023},
month=aug, pages={555–563},
collection={IJCAI-2023} }
备注:两个新颖的任务:关系感知学习和敏感度感知学习
问题:现有方法在学习表示时赋予强正对组和弱正对组相等的权重,而忽视了弱正对组中的噪声问题,最终导致过拟合学习
数据集:CUHK-PEDES, ICFG-PEDES and RSTPReid
- CUHK-PEDES [Li et al, 2017b]是文本人物搜索中最常用的数 据集。总共包含40,206张图片和80,440个文本,来自13,003个 身份。其中,训练集包含34,054张图片和68,126个文本,来自 11,003个身份;验证集包含3,078张图片和6,158个文本,来自 1,000个身份;测试集包含3,074张图片和6,156个文本,来自 1,000个身份。所有文本的平均长度为23。
- ICFG-PEDES [Ding et al,20211是一个最近发布的数据集, 总共包含54,522张图片和4,102个身份。每张图片都有一个描 述文字。该数据集被分为训练集和测试集,训练集包含34,674张图片和3,102个身份,测试集包含19,848张图片和 1,000个身份。平均每个描述文字有37个词。
- RSTPReid [Zhu et al,2021]1是一个新发布的数据集,用于处 理真实场景。它包含20,505张图片,涵盖了4,101个身份。每 个身份有5张来自不同摄像头的对应图片。每张图片都有2个 文本描述,每个描述至少包含23个词。其中,3,701个身份用 于训练,200个身份用于验证,200个身份用于测试。
模型: ALBF
评估标准:Rank@1
提出一种关系和敏感度感知的表示学习方法RaSa,用于基于文本的人物搜索,在多个数据集上实验结果出色,有效提升检索性能。
- 研究背景与问题:基于文本的人物搜索旨在依据文本描述从大规模图像库中检索人物图像,面临跨模态搜索、类内差异大与类间差异小等挑战。现有方法在处理弱正样本噪声和学习鲁棒表示方面存在不足,导致过拟合或无法充分利用数据信息。
- 相关工作:回顾基于文本的人物搜索相关研究,包括跨模态对齐策略和特征表示学习方法;介绍等变对比学习概念,其为研究提供启发。
- 方法
- 模型架构:由图像、文本和跨模态编码器构成,采用文本引导的非对称交叉注意力模块,并通过指数移动平均维护动量模型指导在线模型学习。
- 优化目标:
- 关系感知学习(RA)含概率图像文本匹配(p - ITM)和正关系检测(PRD)任务,平衡弱正样本的利弊;
- 敏感度感知学习(SA)用基于MLM的词替换作为敏感变换,结合基于动量的替换标记检测(m - RTD)任务,促进细粒度表示学习;
- 对比学习(CL)在单模态编码器表示上进行,含跨模态和模态内对比学习,增强表示能力;联合学习将上述任务结合,形成联合优化目标。
- 实验
- 实验设置:在多个数据集上实验,采用Rank@K和mAP评估指标,以视觉语言预训练模型为骨干网络。
- 对比实验:与现有方法对比,RaSa在各数据集上指标领先,显著超越当前最优方法CFine。
- 消融实验:分析各优化目标有效性,RA减轻噪声干扰、实现深度跨模态融合,SA促使模型学习强大表示,超参数实验确定最优设置。
- 扩展实验与可视化:在不同粒度数据集上实验,结果表明RaSa有效且泛化能力强,可视化展示其检索准确性更高。
摘要
基于文本的人物搜索旨在根据文本描述检索指定的人物图像。解决这一具有挑战性任务的关键是学习强大的多模态表示。
为此,我们提出了一种关系感知和敏感性感知的表示学习方法(RaSa),包括两个新颖的任务:关系感知学习(RA)和敏感性感知学习(SA)。
- 一方面,现有方法将所有正对图像进行聚类表示,忽视了由于文本和配对图像存在噪声对应关系而导致的弱正对图像的噪声问题,从而导致过拟合学习。RA通过引入一种新颖的正对关系检测任务(即学习区分强正对和弱正对)来抵消过拟合风险。
- 另一方面,在现有方法中,通过数据增强学习不变表示(即对某些变换不敏感)是提高表示鲁棒性的一般做法。除此之外,我们通过SA鼓励表示学习感知敏感变换(即学习检测替换的单词),从而提升表示的鲁棒性。 实验表明,RaSa在CUHK-PEDES、ICFG-PEDES和RSTPReid数据集的Rank@1方面分别比现有的最先进方法提高了6.94%、4.45%和15.35%。代码可在以下链接找到:
引言
基于文本的人物搜索Li等人(2017b);Wang等人(2021a)旨在在大规模人物图像库中检索给定人物的文本描述查询的人物图像。这个任务与人物再识别Ji等人(2021);Wang等人(2022b)和文本-图像检索Cao等人(2022);Li等人(2021a)相关,这些都是近年来非常活跃的研究课题。然而,它展示了独特的特点和挑战。与使用图像查询的人物再识别相比,基于文本的人物搜索通过更易于访问的开放式文本查询提供了更用户友好的搜索过程,同时由于跨模态搜索而面临更大的挑战。此外,与一般的图像-文本检索相比,基于文本的人物搜索侧重于针对具有更精细细节的人物的跨模态检索,倾向于更大的类内差异和更小的类间差异,这严重限制了检索性能。
针对基于文本的人物搜索,瞄准学习强大的特征表示和实现跨模态对齐,研究人员在过去几年中开发了一批技术(Wu等,2021年;Shao等,2022年)。已经证明,配备合理任务的模型往往能够学习到更好的表示。在本文中,我们提出了一种表示学习方法,即RaSa,其中包括两个新颖的任务:关系感知学习和敏感度感知学习,用于基于文本的人物搜索。
1.1. Relation-aware learning. 关系感知学习
在现有的方法中,Han等人(2021年);Li等人(2022b年)的事实上的优化目标是将同一身份的图像和文本表示(即正对组)聚集在一起,并将不同身份的表示(即负对组)分开。然而,它往往会遇到以下问题。通常,文本描述是通过在基于文本的人物搜索数据集中注释特定的单个图像来生成的。文本与注释的图像完全匹配,毫无疑问,然而,由于图像中的类内变化,它并不总是与同一人的其他正图像在语义层面上很好地对齐。如图1(a)所示,图像和文本描绘了同一个人,每个图像-文本对之间存在着正关系。然而,存在两种不同类型的正关系。文本 1 (或文本 2 )是图像 1 (或图像 2 )的确切描述,它们完全匹配并形成一个强正对组。然而,图像 1 和文本 2 (或 图像 2 和文本 1 )与噪声干扰构成一个弱正对组。例如,文本 1 中的“白色T恤”和“蓝色短裤”对应于图像 2 中由于遮挡而不存在的物体。现有方法在学习表示时赋予强正对组和弱正对组相等的权重,而忽视了弱正对组中的噪声问题,最终导致过拟合学习。
为了减轻来自弱正对噪声干扰的影响,我们提出了一种关系感知学习(RA)任务,该任务由概率图像-文本匹配( -ITM)任务和正关系检测(PRD)任务组成。
- ITM是常用的ITM的一种变体,旨在通过概率强或弱正输入来区分负对和正对,而PRD则旨在明确区分强正对和弱正对。
- 其中, ITM强调强正对和弱正对之间的一致性,而PRD则突出它们的差异,并可以视为 ITM的正则化。
- 装备有RA的模型不仅可以通过ITM从弱正对中学习有价值的信息,还可以通过PRD减轻来自它们的噪声干扰,最终达到一个折衷。
1.2. Sensitivity-aware learning敏感性感知学习
在一组手动选择的变换(在这种情况下也称为不敏感变换)下学习不变表示是提高现有方法中表示鲁棒性的一般做法Caron等人(2020); Chen和He(2021)。我们认识到这一点,但还有更多。受到最近等变对比学习Dangovski等人(2022)的成功启发,我们探索了敏感变换,当应用于学习变换不变表示时会损害性能。与保持对不敏感变换的不变性不同,我们鼓励学习到的表示具有意识到敏感变换的能力。
为了达到这个目的,我们提出了一种敏感性感知学习(SA)任务。我们采用词替换作为敏感性转换,并开发了基于动量的替换标记检测( -RTD)预训练任务,以检测一个标记是来自原始文本描述还是替换文本,如图1(b)所示。替换词与原词越接近(即更具迷惑性),这个检测任务就越困难。当模型被训练得很好地解决这样的检测任务时,预期它将具备学习更好表示的能力。考虑到这些,我们使用掩码语言建模(MLM)来进行词替换,它利用图像和文本上下文标记来预测被掩码的标记。此外,考虑到动量模型(在线模型的缓慢移动平均)可以比当前在线模型Grill等人(2020)学习更稳定的表示,以生成更具迷惑性的词,我们采用来自动量模型的MLM来进行词替换。 总的来说,多层感知机(MLM)和 -RTD共同构成了敏感性感知学习(SA),为表示学习提供了强大的替代监督。
我们的贡献可以总结如下:
- 我们在学习表示中区分强正面图像-文本对和弱正面图像-文本对,并提出了一种关系感知的学习任务。
- 我们开创了在基于文本的人物搜索中学习表征的理念,并开发了一个敏感度感知的学习任务。
- 广泛的实验表明,RaSa在CUHK-PEDES、ICFG-PEDES和RSTPReid数据集上的Rank@1指标上分别比现有的最先进方法提高了 6.94 %、 4.45 %和 15.35 %。
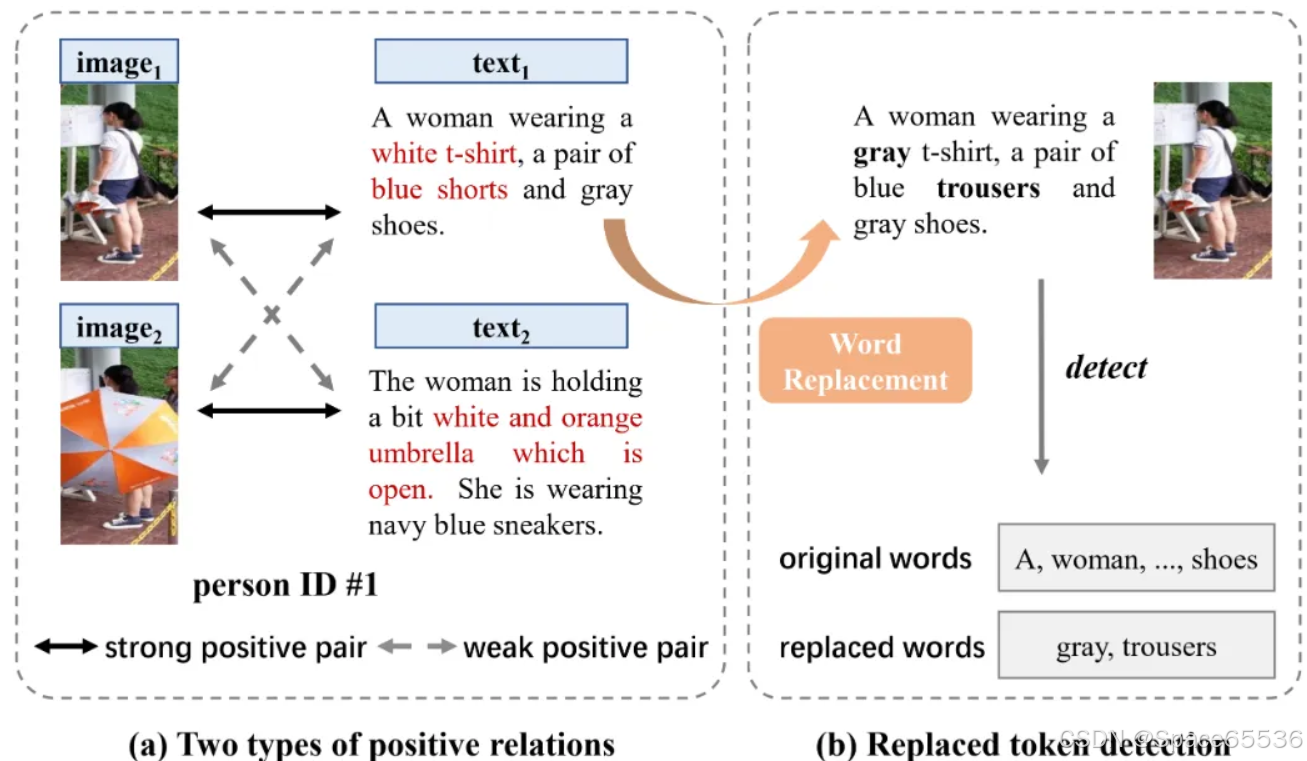
图1:关系感知学习的两种正向关系示意图,弱正向对中的噪声干扰用红色突出显示;敏感性感知学习的替代标记检测,其中词语替换被用作敏感性转换,替换的词语用粗体标记。
2.相关工作
2.1.Text-based Person Search
李等人[2017b]首次引入了基于文本的人物搜索任务,并发布了 一个具有挑战性的数据集CUHK-PEDES。随后,提出了一系列 方法来解决这个任务。其中一部分方法[郑等人,2020a;王等 人,2021a]专注于设计合理的跨模态对齐策略,而其他方法[张 和卢,2018;邵等人,2022]则专注于学习强大的特征表示。对 于跨模态对齐,它始于全局对齐[郑等人,2020b)或局部对应 (例如,补丁-词或区域-短语对应)[陈等人,2022;牛等人, 2020],并发展成自适应学习不同粒度之间的语义对齐[李等 人,2022b;高等人,2021]。除此之外,一些工作[王等人, 2020;朱等人,2021]利用外部技术(例如,人体分割,姿势估 计或属性预测)来辅助跨模态对齐。对于表示学习,吴等人[2021]基于颜色在基于文本的人物搜索中起关键作用的观察 提出了两个与颜色相关的任务。曾等人[2021]开发了三个辅助 推理任务,包括性别分类、外貌相似度和图像到文本生成。 Ding等人[2021]首次注意到弱正对之间的噪声干扰,并提出通 过在三元组损失中手动分配不同的边界来保持强正对和弱正对 之间的差异。最近一些研究[Han等人,2021;Shu等人, 2022;Yan等人,2022]采用视觉语言预训练模型来学习更好的 表示。在本文中,我们设计了两个新颖的任务:RA和SA。RA 检测到正对组的类型,以减弱来自弱正对的噪音与[Ding等人,2021]的方法不同,本方法对配对进行处理。SA 专注于通过检测敏感变换来进行表示学习,这在之前的方法中 尚未得到充分探索。
2.2.Equivariant Contrastive Learning 等变对比学习
不同于对比学习[He et al.,2020]旨在学习对变换不敏感的表示,等变对比学习(Dangovski tal,2022最近提出的是通过 额外鼓励学习到的表示具有感知敏感变换的能力。从数学上 讲,不敏感和敏感的概念可以归纳总结为: f ( T ( x ) ) = T ( f ( x ) ) f(T(x))=T(f(x)) f(T(x))=T(f(x)) , 其中T表示输入实例x的一组变换,f是用于计算x表示的编码 器。当T是恒等变换时,可以说f被训练成对T不敏感;否则,f 对T敏感。等变对比学习已经在计算机视觉(CV)Dangovski et al, 2022]和自然语言处理(NLP) [Chuang et al, 2022]领 域展示了成功的应用,这激发了我们在跨模态检索任务中探索 敏感变换以学习高质量的表示的兴趣。在本文中,我们开发了 一种敏感性感知学习方法,使用基于MLM的词替换作为敏感性 转换,以鼓励模型感知替换的词语,从而获得更多信息丰富和 具有区分性的表示。
补充1:存在强弱正样本对的本质原因
- 数据采集与标注特特性:由于拍摄视角、距离、光线以及遮挡等因素影响,同一人物的不同图像在外观表现上会存在差异。标注文本与某张图像精准匹配,却无法与同一人物的其他图像在语义层面完全对齐,从而产生了强正样本对(文本与图像精确匹配)和弱正样本对(存在匹配偏差)。
- 数据多样性:同一人物在不同时间、场景下的穿着打扮、姿态动作会发生变化,这使得描述同一人物的文本和对应的图像之间存在多种对应关系。同时,不同标注者对同一图像的理解和描述也可能不同,这些因素增加了数据的多样性和复杂性,也是强弱正样本对产生的重要原因。
补充2:RASA与ALBEF、BLIP、VLMo的区别
ALBEF(VLP框架):
- 模型架构:由图像编码器(12 层的 ViT-b/16)、文本编码器(6 层的多层感知器,即前 6 层的 Bert)和多模态编码器(Bert 最后 6 层,并带有跨模态注意力)组成。
- 损失函数:包括跨模态对比损失(ITC)、掩码语言建模(MLM)和图像-文本匹配(ITM)。
- 动量蒸馏:为了提高在噪声数据上的学习效果,提出了一种自训练方法,即动量蒸馏,通过保持一个动量版本的模型,利用其生成伪目标作为额外的监督信号。
BLIP:模型主要包括一个完整的 ViT 模型用于提取图像特征,以及三个针对文本的模型(文本编码器、图像-文本编码器和图像-文本解码器)。其结构与 ALBEF 有相似之处,例如都使用了 ViT 等。但 BLIP 为了解决生成任务,文本端使用了 decoder;并且提出了 CapFilt 机制,包含字幕生成器与过滤器,以应对网络大规模数据中普遍存在的图像与文本不匹配问题。
VLMo:其亮点是在模型结构上进行了改进,采用了 Mixture-of-Modality-Experts(MoME)Transformer。在自注意力中所有模态共享参数,但在 FFN 层中,每个模态对应自己不同的 expert。训练时,根据输入模态的数据来训练相应模态的 expert。VLMo 也采用了 ITC、ITM、MLM 等训练损失函数。它通过分阶段模型预训练,先在单模态数据集上分别训练 vision expert 和 language expert,再在多模态数据集上进行训练。
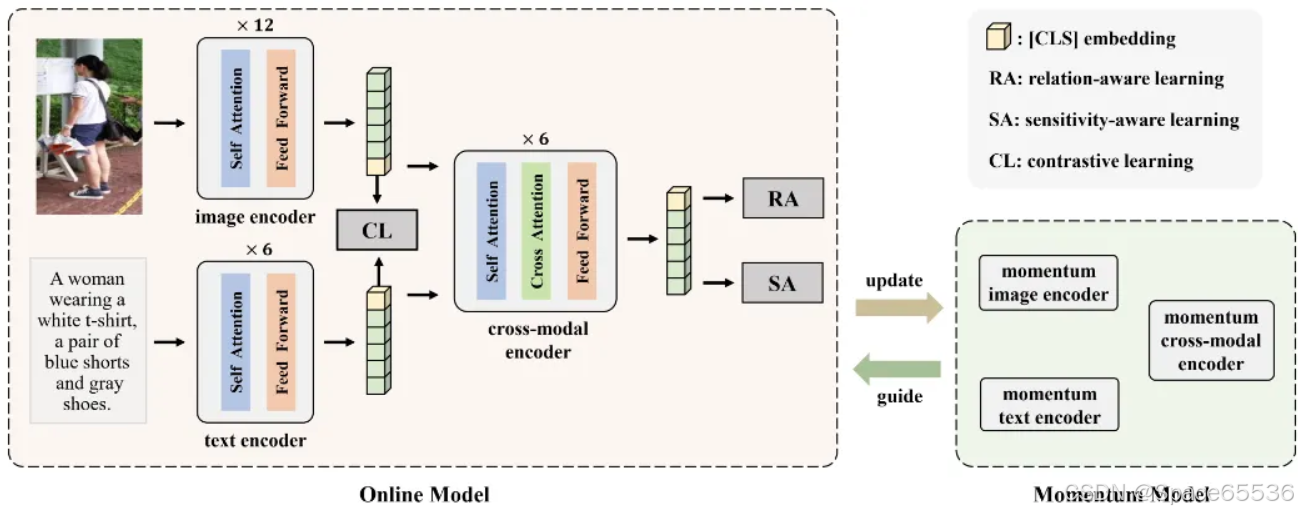
图2:RaSa的模型架构。它由图像编码器、文本编码器和跨模态编码器组成。在单模态编码器之后附加了一个单模态和跨模态的CL任务,用于单模态表示学习。在跨模态编码器之后,RA和SA任务被绑定在一起,用于多模态表示学习。动量模型(在线模型的缓慢移动)用于指导在线模型学习更好的表示。
3.方法
在本节中,我们以ALBEF [Liet al,2021a]作为骨干,并通过在 第3.1节介绍模态架构以及在第3.2节介绍涉及提出的RA和SA任 务的优化目标来详细说明所提出的方法RaSa。
3.1 Model Architecture
如图2所示,所提出的RaSa由两个单峰编码器和一个跨模态编码器组成。我们分别为图像和文本编码器采用12层和6层转换块。跨模态编码器包括6层转换块,其中在每个块中的自注意力模块之后添加一个交叉注意力模块。考虑到文本描述通常涵盖相应图像中的一部分信息,我们在跨模态编码器中采用文本引导的非对称交叉注意力模块,即使用文本表示作为查询,使用视觉表示作为键和值。同时,我们通过指数移动平均线(EMA)维护在线模型的动量版本。
具体而言,EMA被制定为
θ
^
=
m
θ
^
+
(
1
−
m
)
θ
\hat{\theta}=m\hat{\theta}+(1-m)\theta
θ^=mθ^+(1−m)θ,
其中
θ
^
\hat{\theta}
θ^和θ分别是动量和在线模型的参数,
m
∈
[
0
,
1
]
m\in[0,1]
m∈[0,1]是动量系数,动量模型呈现了在线模型的延迟和更稳定的版本,用于指导在线模型学习更好的表示。
给定一个图像-文本对 ( I , T ) (I, T) (I,T),我们首先将图像I输入图像编码器以获得一系列视觉表示 v c l s , v 1 , ⋯ , v M {v_{c l s},v_{1},\cdots,v_{M}} vcls,v1,⋯,vM其中 v c l s v_{c l s} vcls是全局视觉表示, v i ( i = 1 , ⋯ , M ) v_{i}(i=1,\cdots,M) vi(i=1,⋯,M)是补丁表示。类似地,我们通过将文本T输入文本编码器来获得一系列文本表示· t c l s , t 1 , ⋯ , t N {t_{c l s},t_{1},\cdots,t_{N}} tcls,t1,⋯,tN,其中 t c l s t_{c l s} tcls是全局文本表示, i ( i = 1 , ⋯ , N ) {i}(i=1,\cdots,N) i(i=1,⋯,N)是令牌表示。然后将视觉和文本表示馈送到跨模态编码器以获得多模态表示序列 f c l s 、 f 1 、 ⋯ 、 f N {f_{c l s}、f_{1}、\cdots、f_{N}} fcls、f1、⋯、fN,其中 f c l s fcls fcls表示I和T的联合表示,并且 f i ( i = 1 , ⋯ , N ) f_{i}(i=1,\cdots, N) fi(i=1,⋯,N)可以被视为图像I和文本T中第i个标记的联合表示。同时,采用动量模型获得动量表示序列。
3.2 Optimization Objectives
3.2.1. Relation-aware Learning
The vanilla widely-used ITM(Image-Text Matching,图像文本匹配)方法:首先计算输入图像-文本对是正样本还是负样本来进行预测。
L
i
t
m
=
E
p
(
I
,
T
)
H
(
y
i
t
m
,
ϕ
i
t
m
(
I
,
T
)
)
L_{itm}=\mathbb{E}_{p(I,T)}\mathcal{H}(y^{itm},\phi^{itm}(I,T))
Litm=Ep(I,T)H(yitm,ϕitm(I,T))中,
H
\mathcal{H}
H代表交叉熵函数,
y
i
t
m
y^{itm}
yitm是一个二维的独热向量,表示真实标签,即正样本对为
[
0
,
1
]
⊤
[0,1]^{\top}
[0,1]⊤,负样本对为
[
1
,
0
]
⊤
[1,0]^{\top}
[1,0]⊤。
ϕ
i
t
m
(
I
,
T
)
\phi^{itm}(I,T)
ϕitm(I,T)是图像-文本对的预测匹配概率,它是通过将
f
c
l
s
f_{cls}
fcls输入到一个二分类器中计算得到的,这个二分类器是一个全连接层后面跟着一个 softmax 函数。
然而,在基于文本的人物搜索中直接采用普通的图像文本匹配(ITM)是不合理的。一方面,弱正样本对存在噪声干扰,这会阻碍表示学习。另一方面,弱正样本对包含一定有价值的对齐信息,能够促进表示学习。因此,为了达到平衡,我们通过引入概率输入在 ITM 中保留一定比例的弱正样本对。具体来说,我们以较小的概率 p w p^{w} pw 输入弱正样本对,以概率 1 − p w 1-p^{w} 1−pw 输入强正样本对。为了与普通的 ITM 区分开来,我们将提出的概率 ITM 表示为 p -ITM。
一种减轻弱对噪声效应的方法,即提出了一个正关系检测(PRD)的预训练任务来检测正对的类型(强或弱)。
L
p
r
d
=
E
p
(
I
,
T
p
)
H
(
y
p
r
d
,
ϕ
p
r
d
(
I
,
T
p
)
)
L_{p r d}=\mathbb{E}_{p\left(I, T^{p}\right)} \mathcal{H}\left(y^{p r d}, \phi^{p r d}\left(I, T^{p}\right)\right)
Lprd=Ep(I,Tp)H(yprd,ϕprd(I,Tp))中,
(
I
,
T
p
)
(I, T^{p})
(I,Tp)表示一个正对,
y
p
r
d
y^{p r d}
yprd是真实标签(强正对为
[
1
,
0
]
⊤
[1,0]^{\top}
[1,0]⊤,弱对为
[
0
,
1
]
⊤
[0,1]^{\top}
[0,1]⊤),
ϕ
p
r
d
(
I
,
T
p
)
\phi^{p r d}(I, T^{p})
ϕprd(I,Tp)是通过在正对的联合表示
f
c
l
s
f_{cls}
fcls后添加一个二分类器计算得到的该对的预测概率。
Taken together, we define the Relation-Aware learning (RA) task as:
整体来看,我们将关系感知学习(RA)任务定义为:
L
r
a
=
L
p
−
i
t
m
+
λ
1
L
p
r
d
L_{r a}=L_{p-i t m}+\lambda_{1} L_{p r d}
Lra=Lp−itm+λ1Lprd(公式 3),
其中权重
λ
1
\lambda_{1}
λ1是一个超参数。这句话描述了关系感知学习任务的定义方式,通过将两个损失函数
L
p
−
i
t
m
L_{p-i t m}
Lp−itm和
λ
1
L
p
r
d
\lambda_{1} L_{p r d}
λ1Lprd相加得到
L
r
a
L_{r a}
Lra,其中
λ
1
\lambda_{1}
λ1作为一个超参数可以调整两个损失函数在总损失中的相对重要性。
在优化过程中,p -ITM 专注于强正样本对和弱正样本对之间的一致性,而 PRD 强调它们之间的差异。本质上,PRD 对 p -ITM 起到了一种正则化补偿的作用。总体而言,RA 在弱样本对的益处和其副作用风险之间实现了一种权衡。
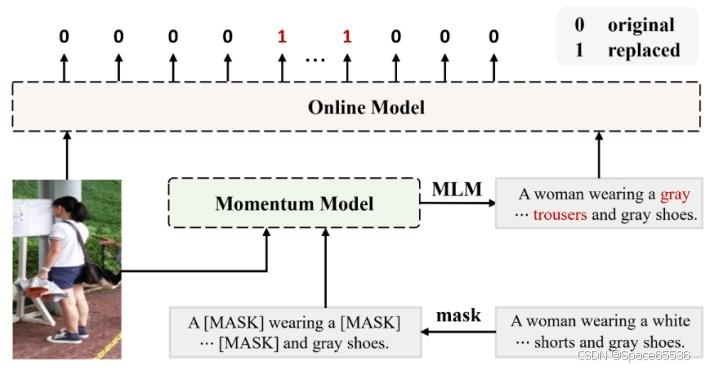
图3:m-RTD的示意图,它旨在通过上下文标记和配对图像的信息来 检测一个令牌是来自原始文本描述还是替换的。通过动量模型的掩码 语言建模(MLM)的结果获得具有词替换的文本。
3.2.2. Sensitivity-aware Learning
在数据的不敏感变换下学习不变表示是增强所学表示鲁棒性的常用方法,我们超越它,提出学习感知敏感变换的表示,具体而言,我们采用基于MLM的词替换作为敏感变换,并提出基于Momentum的替换令牌检测(m-RTD)借口任务来检测(即感知)替换。
给定一个强正样本对
(
I
,
T
s
)
(I, T^{s})
(I,Ts),掩码语言模型(MLM)损失被公式化为:
L
m
l
m
=
E
p
(
I
,
T
m
s
k
)
H
(
y
m
l
m
,
ϕ
m
l
m
(
I
,
T
m
s
k
)
)
L_{mlm}=\mathbb{E}_{p\left(I, T^{msk}\right)}\mathcal{H}\left(y^{mlm}, \phi^{mlm}\left(I, T^{msk}\right)\right)
Lmlm=Ep(I,Tmsk)H(ymlm,ϕmlm(I,Tmsk)),(4)。
其中, T m s k T^{m s k} Tmsk是一个掩码文本,其中输入文本 T s T^{s} Ts中的每个标记以概率 p m p^{m} pm随机被掩码。 y m i m y^{m i m} ymim是一个独热向量,表示被掩码标记的真实值。 ϕ m l m ( I , T m s k ) \phi^{m l m}(I, T^{m s k}) ϕmlm(I,Tmsk)是基于上下文文本 T m s k T^{m s k} Tmsk和配对图像“I”对被掩码标记的预测概率。
我们将动量模型的掩码语言模型(MLM)结果用作单词替换,记为 T r e p T^{rep } Trep。动量模型是在线模型的缓慢移动版本,可以学习到更稳定的表示。因此,期望动量模型生成更具迷惑性的标记。由于 m-RTD 能够很好地检测到这种具有挑战性的标记,所以该模型被激励去学习更具信息量的表示,以区分微小的差异。值得注意的是,除了作为单词替换的生成器之外,MLM 还在标记级别上起到优化作用,促进细粒度的表示学习。
m-RTD对基于掩码语言模型(MLM)的令牌替换进行检测的过程。
具体来说,将对
(
I
,
T
r
e
p
)
(I, T^{r e p})
(I,Trep)输入到模型中以获得一系列多模态表示
f
c
l
s
,
f
1
,
.
.
.
,
f
N
{f_{c l s}, f_{1},..., f_{N}}
fcls,f1,...,fN,然后一个二分类器作用于
f
1
,
.
.
.
,
f
N
{f_{1},..., f_{N}}
f1,...,fN来预测第 i 个令牌是否被替换。m-RTD 最小化交叉熵损失,公式为
L
m
−
r
t
d
=
E
p
(
I
,
T
r
e
p
)
H
(
y
m
−
r
t
d
,
ϕ
m
−
r
t
d
(
I
,
T
r
e
p
)
)
L_{m-r t d}=\mathbb{E}_{p\left(I, T^{r e p}\right)} \mathcal{H}\left(y^{m-r t d}, \phi^{m-r t d}\left(I, T^{r e p}\right)\right)
Lm−rtd=Ep(I,Trep)H(ym−rtd,ϕm−rtd(I,Trep)),
其中
y
m
−
r
t
d
y^{m-r t d}
ym−rtd是表示被替换令牌的真实情况的独热向量,
ϕ
m
−
r
t
d
(
I
,
T
r
e
p
)
\phi^{m-r t d}(I, T^{r e p})
ϕm−rtd(I,Trep)是预测的替换概率。
最后提到为了清晰起见,在图 3 中展示了 m-RTD 的流程。
总体而言,敏感性感知学习(SA)损失定义为:
L
s
a
=
L
m
l
m
+
λ
2
L
m
−
r
t
d
,
(
6
)
L_{s a}=L_{m l m}+\lambda_{2}L_{m-r t d},\quad(6)
Lsa=Lmlm+λ2Lm−rtd,(6)其中权重
λ
2
\lambda_{2}
λ2是超参数。
总之,关系感知(RA)作用于全局表示 f c l s fcls fcls,主要关注图像与文本之间的相关性,可以被视为一种粗粒度的优化。作为补充,语义对齐(SA)作用于令牌表示 f 1 , . . . , f N {f_{1},..., f_{N}} f1,...,fN,更加注重图像与文本令牌之间的交互,呈现出细粒度的优化。这两个互补的任务有效地促进了表示学习。
3.2.3. 对比学习
提出的 RA 和 SA 直接应用于来自跨模态编码器的多模态表示。此外,我们在来自单模态编码器的表示上引入了一个中间对比学习任务(CL),以便使后续的跨模态融合更容易进行多模态表示学习。
给出一个图像-文本对 ( I , T ) (I,T) (I,T),将其输入到单模态编码器中,得到全局视觉和文本表示 v c l s v_{cls} vcls和 t c l s t_{cls} tcls。然后通过一个线性层将它们投影到低维表示 v c l s ′ v_{cls}' vcls′和 t c l s ′ t_{cls}' tcls′。同时,获得动量单模态编码器的输出,记为 v ^ c l s ′ \hat{v}_{cls}' v^cls′和 t ^ c l s ′ \hat{t}_{cls}' t^cls′。维护一个图像队列 Q ^ v \hat{Q}_{v} Q^v和一个文本队列 Q ^ t \hat{Q}_{t} Q^t,用于存储最近投影后的表示 v ^ c l s ′ \hat{v}_{cls}' v^cls′和 t ^ d s ′ \hat{t}_{ds}' t^ds′,这与 MoCo(He 等人,2020)类似。队列的引入隐含地增大了批处理大小,更大的批处理将提供更多的负样本,从而有利于表示学习。
对比学习(CL)中,InfoNCE 损失的一般形式被表述为:
L
n
c
e
(
x
,
x
+
,
Q
)
=
−
E
p
(
x
,
x
+
)
[
log
exp
(
s
(
x
,
x
+
)
/
τ
)
∑
x
i
∈
Q
exp
(
s
(
x
,
x
i
)
/
τ
)
]
L_{nce}(x,x_{+},Q)=-\mathbb{E}_{p(x,x_{+})}\left[\log\frac{\exp(s(x,x_{+})/\tau)}{\sum_{x_{i}\in Q}\exp(s(x,x_{i})/\tau)}\right]
Lnce(x,x+,Q)=−Ep(x,x+)[log∑xi∈Qexp(s(x,xi)/τ)exp(s(x,x+)/τ)],
其中
τ
\tau
τ是一个可学习的温度参数,
Q
Q
Q表示一个维护的队列,并且
s
(
x
,
x
+
)
=
x
T
x
+
/
∥
x
∥
∥
x
+
∥
s(x,x_{+})=x^{T}x_{+}/\|x\|\|x_{+}\|
s(x,x+)=xTx+/∥x∥∥x+∥测量了
x
x
x和
x
+
x_{+}
x+之间的余弦相似度。
跨模态图像-文本对比学习(ITC)以及在此基础上探索的模态内对比学习(IMC),并定义了整体的对比学习损失函数:
- 首先提到了广泛使用的跨模态图像-文本对比学习(ITC),用公式
- L i t c = [ L n c e ( v c l s ′ , t ^ c l s ′ , Q ^ t ) + L n c e ( t c l s ′ , v ^ c l s ′ , Q ^ v ) ] / 2 L_{itc}=\left[L_{nce}\left(v_{cls}',\hat{t}_{cls}',\hat{Q}_{t}\right)+L_{nce}\left(t_{cls}',\hat{v}_{cls}',\hat{Q}_{v}\right)\right]/2 Litc=[Lnce(vcls′,t^cls′,Q^t)+Lnce(tcls′,v^cls′,Q^v)]/2 表示。
- 在此之外还探索了模态内对比学习(IMC),其目的是让同一人的在每种模态下的表示比不同人的表示更接近,用公式
- L i m c = [ L n c e ( v c l s ′ , v ^ c l s ′ , Q ^ v ) + L n c e ( t c l s ′ , t ^ c l s ′ , Q ^ t ) ] / 2 L_{imc}=\left[L_{nce}\left(v_{cls}',\hat{v}_{cls}',\hat{Q}_{v}\right)+L_{nce}\left(t_{cls}',\hat{t}_{cls}',\hat{Q}_{t}\right)\right]/2 Limc=[Lnce(vcls′,v^cls′,Q^v)+Lnce(tcls′,t^cls′,Q^t)]/2 表示。
- 最后,将整体的对比学习损失函数定义为 L c l = ( L i t c + L i m c ) / 2 L_{cl}=\left(L_{itc}+L_{imc}\right)/2 Lcl=(Litc+Limc)/2。
3.2.4. Joint Learning
总体而言,我们将联合优化目标公式化为:
L
=
L
r
a
+
L
s
a
+
λ
3
L
c
l
L = L_{ra}+L_{sa}+\lambda_{3}L_{cl}
L=Lra+Lsa+λ3Lcl,
其中(11)式中
λ
3
\lambda_{3}
λ3是一个超参数。
在推理过程中,给定一个查询文本和一个大规模图像池,我们使用来自 p - ITM 的预测匹配概率对所有图像进行排序。
考虑到具有二次交互操作的跨模态编码器效率低下,我们参考 ALBEF(Li 等人,2021a),在跨模态编码器之前排除大量不相关的图像候选,从而加快推理速度。具体来说,我们首先通过单模态编码器计算每对的相似度
s
(
t
c
l
s
,
v
c
l
s
)
s(t_{cls},v_{cls})
s(tcls,vcls),然后选择相似度最高的前 128 张图像发送到跨模态编码器,并计算 p - ITM 匹配概率以进行排序。
4.实验
4.2. Backbones
基于文本的人物搜索方法及所提出的 RaSa 可插入的多种骨干模型。
大部分基于文本的人物搜索方法(如 Li 等人在 2022b 年的研究、Shao 等人在 2022 年的研究)依赖于两个分别在未对齐的图像和文本上预训练的特征提取器,例如视觉提取器使用 ResNet(He 等人在 2016 年提出)或 ViT(Dosovitskiy 等人在 2020 年提出),文本提取器使用双向长短期记忆网络(Bi-LSTM,Hochreiter 和 Schmidhuber 在 1997 年提出)或 BERT(Devlin 等人在 2018 年提出)。最近,一些研究工作(如 Shu 等人在 2022 年的研究、Yan 等人在 2022 年的研究)将视觉语言预训练(VLP)应用于基于文本的人物搜索并取得了令人瞩目的结果。在此基础上,本文采用 VLP 模型作为骨干。
所提出的 RaSa 可以插入到各种骨干模型中。为了充分验证其有效性,在三个 VLP 模型上进行了 RaSa:ALBEFF(Li 等人在 2021a 年提出)、TCL(Yang 等人在 2022 年提出)和 CLIP(Radford 等人在 2021 年提出)。在接下来的实验中,默认使用 ALBEF 作为骨干,它在 1400 万图像-文本对数据上进行预训练,并采用图像-文本对比(ITC)和图像-文本匹配(ITM)任务进行图像-文本检索。TCL 和 CLIP 的详细信息和实验在附录 A.4 中展示。
4.3. 实验细节
所有实验均在 4 个 NVIDIA 3090 GPU 上进行。我们用 30 个周期和 52 的批量大小来训练模型。
采用 AdamW 优化器(Loshchilov 和 Hutter,2019),权重衰减为 0.02。
对于 PRD 和 m-RTD 中的分类器参数,学习率初始化为 1e-4,对于模型的其余参数,学习率初始化为 1e5。
所有图像都调整为 384×384,并采用随机水平翻转进行数据增强。
对于所有数据集,输入文本的最大长度设置为 50。动量模型中的动量系数设置为
m
=
0.995
m = 0.995
m=0.995。
在对比学习(CL)中,队列大小 R 设置为 65536,温度 T 设置为 0.07。
在关系感知学习(RA)中,输入弱正对的概率设置为
p
w
=
0.1
p^{w}=0.1
pw=0.1,在自注意力(SA)中,文本中掩码单词的概率设置为
p
m
=
0.3
p^{m}=0.3
pm=0.3。
目标函数中的超参数设置为
λ
1
=
0.5
\lambda_{1}=0.5
λ1=0.5,
λ
2
=
0.5
\lambda_{2}=0.5
λ2=0.5,
λ
3
=
0.5
\lambda_{3}=0.5
λ3=0.5。
5.结论
In this paper, we propose a Relation and Sensitivity aware representation learning method (RaSa) for text-based person search, which contains two novel tasks, RA and SA, to learn powerful multi-modal representations. Given that the noise from the weak positive pairs tends to result in overfitting learning, the proposed RA utilizes an explicit detection between strong and weak positive pairs to highlight the difference, serving as a regularization of p -ITM that focuses on their consistency. Beyond learning transformationinsensitive representations, SA encourages the sensitivity to MLM-based token replacement. Extensive experiments on multiple benchmarks demonstrate the effectiveness of RaSa.
在本文中,我们提出了一种用于基于文本的人物搜索的关系和敏感性感知表示学习方法(RaSa),它包含两个新颖的任务 RA 和 SA,以学习强大的多模态表示。鉴于来自弱正样本对的噪声往往会导致过拟合学习,所提出的 RA 利用强正样本对和弱正样本对之间的显式检测来突出差异,作为专注于它们一致性的 p-ITM 的正则化。除了学习对变换不敏感的表示之外,SA 鼓励对基于 MLM 的标记替换的敏感性。在多个基准上的大量实验证明了 RaSa 的有效性。
补充:关键代码
def forward(self, image1, image2, text1, text2, alpha, idx, replace):
# extract image features
image_embeds = self.visual_encoder(image1)
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(image1.device)
image_feat = F.normalize(self.vision_proj(image_embeds[:, 0, :]), dim=-1)
# extract text features
text_output = self.text_encoder.bert(text2.input_ids, attention_mask=text2.attention_mask,
return_dict=True, mode='text')
text_embeds = text_output.last_hidden_state
text_feat = F.normalize(self.text_proj(text_embeds[:, 0, :]), dim=-1)
# Contrastive loss
idx = idx.view(-1, 1)
idx_all = torch.cat([idx.t(), self.idx_queue.clone().detach()], dim=1)
pos_idx = torch.eq(idx, idx_all).float()
sim_targets = pos_idx / pos_idx.sum(1, keepdim=True)
with torch.no_grad():
self._momentum_update()
...
sim_i2t_targets = alpha * F.softmax(sim_i2t_m, dim=1) + (1 - alpha) * sim_targets
sim_t2i_targets = alpha * F.softmax(sim_t2i_m, dim=1) + (1 - alpha) * sim_targets
sim_i2i_targets = alpha * F.softmax(sim_i2i_m, dim=1) + (1 - alpha) * sim_targets
sim_t2t_targets = alpha * F.softmax(sim_t2t_m, dim=1) + (1 - alpha) * sim_targets
sim_i2t = image_feat @ text_feat_all / self.temp
sim_t2i = text_feat @ image_feat_all / self.temp
sim_i2i = image_feat @ image_feat_all / self.temp
sim_t2t = text_feat @ text_feat_all / self.temp
loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1) * sim_i2t_targets, dim=1).mean()
loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1) * sim_t2i_targets, dim=1).mean()
loss_i2i = -torch.sum(F.log_softmax(sim_i2i, dim=1) * sim_i2i_targets, dim=1).mean()
loss_t2t = -torch.sum(F.log_softmax(sim_t2t, dim=1) * sim_t2t_targets, dim=1).mean()
loss_cl = (loss_i2t + loss_t2i + loss_i2i + loss_t2t) / 4
self._dequeue_and_enqueue(image_feat_m, text_feat_m, idx)
# Relation-aware Learning: Probabilistic Image-Text Matching + Positive Relation Detection
# Probabilistic Image-Text Matching
# forward the positve image-text pairs
output_pos = self.text_encoder.bert(encoder_embeds=text_embeds,
attention_mask=text2.attention_mask,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
mode='fusion',
)
with torch.no_grad():
bs = image1.size(0)
weights_i2t = F.softmax(sim_i2t[:, :bs], dim=1)
weights_t2i = F.softmax(sim_t2i[:, :bs], dim=1)
mask = torch.eq(idx, idx.T)
weights_i2t.masked_fill_(mask, 0)
weights_t2i.masked_fill_(mask, 0)
# select a negative image for each text
image_neg_idx = torch.multinomial(weights_t2i, 1).flatten()
image_embeds_neg = image_embeds[image_neg_idx]
# select a negative text for each image
text_neg_idx = torch.multinomial(weights_i2t, 1).flatten()
text_embeds_neg = text_embeds[text_neg_idx]
text_atts_neg = text2.attention_mask[text_neg_idx]
# forward the negative image-text pairs
text_embeds_all = torch.cat([text_embeds, text_embeds_neg], dim=0)
text_atts_all = torch.cat([text2.attention_mask, text_atts_neg], dim=0)
image_embeds_all = torch.cat([image_embeds_neg, image_embeds], dim=0)
image_atts_all = torch.cat([image_atts, image_atts], dim=0)
output_neg_cross = self.text_encoder.bert(encoder_embeds=text_embeds_all,
attention_mask=text_atts_all,
encoder_hidden_states=image_embeds_all,
encoder_attention_mask=image_atts_all,
return_dict=True,
mode='fusion',
)
vl_embeddings = torch.cat([output_pos.last_hidden_state[:, 0, :], output_neg_cross.last_hidden_state[:, 0, :]],
dim=0)
vl_output = self.itm_head(vl_embeddings)
itm_labels = torch.cat([torch.ones(bs, dtype=torch.long), torch.zeros(2 * bs, dtype=torch.long)],
dim=0).to(image1.device)
loss_pitm = F.cross_entropy(vl_output, itm_labels)
# Positive Relation Detection
prd_output = self.prd_head(output_pos.last_hidden_state[:, 0, :])
loss_prd = F.cross_entropy(prd_output, replace)
# Sensitivity-aware Learning: Masked Language Modeling + Momentum-based Replaced Token Detection
input_ids = text1.input_ids.clone()
labels = input_ids.clone()
mrtd_input_ids = input_ids.clone()
# Masked Language Modeling
probability_matrix = torch.full(labels.shape, self.mlm_probability)
input_ids, labels = self.mask(input_ids, self.text_encoder.config.vocab_size, targets=labels, probability_matrix=probability_matrix)
with torch.no_grad():
logits_m = self.text_encoder_m(input_ids,
attention_mask=text1.attention_mask,
encoder_hidden_states=image_embeds_m,
encoder_attention_mask=image_atts,
return_dict=True,
return_logits=True,
)
prediction = F.softmax(logits_m, dim=-1)
mlm_output = self.text_encoder(input_ids,
attention_mask=text1.attention_mask,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
labels=labels,
soft_labels=prediction,
alpha=alpha
)
loss_mlm = mlm_output.loss
# Momentum-based Replaced Token Detection
with torch.no_grad():
probability_matrix = torch.full(labels.shape, self.mrtd_mask_probability)
mrtd_input_ids = self.mask(mrtd_input_ids, self.text_encoder.config.vocab_size, probability_matrix=probability_matrix)
# momentum module is used as generator
mrtd_logits_m = self.text_encoder_m(mrtd_input_ids,
attention_mask=text1.attention_mask,
encoder_hidden_states=image_embeds_m,
encoder_attention_mask=image_atts,
return_dict=True,
return_logits=True,
)
weights = F.softmax(mrtd_logits_m, dim=-1)
mrtd_input_ids, mrtd_labels = self.mrtd_mask_modeling(mrtd_input_ids, text1.input_ids, text1.attention_mask, weights)
output_mrtd = self.text_encoder.bert(mrtd_input_ids,
attention_mask=text1.attention_mask,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
return_dict=True,
)
mrtd_output = self.mrtd_head(output_mrtd.last_hidden_state.view(-1, self.text_width))
loss_mrtd = F.cross_entropy(mrtd_output, mrtd_labels.view(-1))
return loss_cl, loss_pitm, loss_mlm, loss_prd, loss_mrtd



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









