







论文地址:From Data Deluge to Data Curation: A Filtering-WoRA Paradigm for Efficient TBPS
代码地址:未开源(2025.01.22)
bib引用:
@misc{
ergasti2024marspayingattentionvisual,
title={
MARS: Paying more attention to visual attributes for text-based person search},
author={
Alex Ergasti and Tomaso Fontanini and Claudio Ferrari and Massimo Bertozzi and Andrea Prati},
year={
2024},
eprint={
2407.04287},
archivePrefix={
arXiv},
primaryClass={
cs.CV},
url={
https://arxiv.org/abs/2407.04287},
}
动机:合成数据集存在问题【①只有一部分数据对于解决问题是关键性的②涉及隐私问题③存在噪声导致的质量问题】所以通过合适的数据过滤策略也可以提高模型的性能。
解决方案:优秀的backbone + 有效的数据过滤策略 +大力出奇迹(8*A800)
InShort
提出Filtering-WoRA范式,用于基于文本的人员搜索,通过数据筛选和低秩适应策略,提升模型效率与性能。
- 研究背景与挑战
- 文本基人员搜索的重要性:相比传统图像基人员搜索,文本基人员搜索依据行人描述从候选集中定位目标个体,在公共安全领域应用广泛。
- 数据获取难题:行人数据有限,现有构建数据集的方式存在诸多问题,如人工标注成本高、隐私问题,网络数据质量不佳,生成数据存在冗余和噪声。
- 数据与模型优化需求:大量生成数据训练存在计算成本高、性能提升瓶颈等问题,需探索用更少数据和参数提升模型精度的策略。
- 相关工作
- 视觉语言预训练:包括粗粒度和细粒度方法,近期出现多种新方法旨在弥合对象级和图像级对齐学习的差距,本文利用预训练模型过滤噪声数据。
- 文本图像人员搜索:现有方法分为基于跨模态注意力交互和无跨模态注意力交互两类,均存在需微调整个网络导致效率低的问题,本文方法基于跨模态特征提取提升效率。
- 以数据为中心的学习:强调高质量数据集构建的重要性,数据选择、清洗、预处理和核心集选择等技术可提升模型性能,本文采用核心集方法筛选数据集。
- Filtering-WoRA范式方法
- 基线模型:基于APTM框架,包含图像、文本和交叉编码器以及两个基于MLP的头,使用多种损失函数进行预训练和微调。
- 数据过滤:利用BLIP - 2等大的跨模态模型提取图像和文本特征,计算自相似度和干扰相似度。在预训练阶段,从MALS数据集中筛选出79%高质量数据;在微调阶段,从CUHK - PEDES数据集中筛选出90%高质量数据,有效去除噪声数据,提升数据质量和训练效率。
- 加权低秩适应(WoRA):受LoRA和DoRA启发,引入新的可学习参数α和β,通过调整预训练权重的幅度和方向进行高效微调。相比LoRA和DoRA,WoRA学习性能更优,虽训练时间略长,但提升效果明显,且空间复杂度与DoRA相同。
- 实验评估
- 实验设置:使用MALS数据集预训练,CUHK - PEDES、RSTPReid和ICFG - PEDES数据集微调。采用平均精度均值(mAP)和Recall@1,5,10等指标评估,使用AdamW优化器,设置特定的学习率、批大小和训练轮数。
- 与现有方法对比:在多个数据集上,WoRA方法显著减少计算参数和时间,如在CUHK - PEDES数据集上,训练参数减少41%,FLOPs减少39%,训练时间缩短19.82%,同时召回率和mAP略有提升。
- 消融研究:数据过滤在预训练和微调阶段均有效,提升了模型性能;WoRA在模型预训练和整体性能提升上效果显著,相比LoRA和DoRA性能更优,rank = 8时模型性能最佳。
- 研究结论:Filtering-WoRA范式通过数据过滤和WoRA学习策略,在保持与现有模型相当精度的同时,训练速度提升19.82%,在多个公共基准测试中取得有竞争力的召回率和mAP,为基于文本的人员搜索提供了更高效的解决方案 。
摘要
In text-based person search endeavors, data generation has emerged as a prevailing practice, addressing concerns over privacy preservation and the arduous task of manual annotation. Although the number of synthesized data can be infinite in theory, the scientific conundrum persists that how much generated data optimally fuels subsequent model training. 【合成数据是有用但还存在问题,且只有一部分数据起着关键性的作用】We observe that only a subset of the data in these constructed datasets plays a decisive role. Therefore, we introduce a new Filtering-WoRA paradigm, which contains a filtering algorithm to identify this crucial data subset and WoRA (Weighted Low-Rank Adaptation) learning strategy for light fine-tuning. The filtering algorithm is based on the cross-modality relevance to remove the lots of coarse matching synthesis pairs. As the number of data decreases, we do not need to fine-tune the entire model. 【过滤算法+轻度微调策略】Therefore, we propose a WoRA learning strategy to efficiently update a minimal portion of model parameters. WoRA streamlines the learning process, enabling heightened efficiency in extracting knowledge from fewer, yet potent, data instances. Extensive experimentation validates the efficacy of pretraining, where our model achieves advanced and efficient retrieval performance on challenging real-world benchmarks. Notably, on the CUHK-PEDES dataset, we have achieved a competitive mAP of 67.02% while reducing model training time by 19.82%.
在基于文本的人物搜索工作中,数据生成已成为一种普遍做法,解决了对隐私保护的担忧和手动注释的艰巨任务。尽管理论上合成数据的数量可以是无限的,但科学难题仍然存在,即生成的数据量可以最好地为后续的模型训练提供动力。我们观察到,在这些构建的数据集中,只有一部分数据起着决定性的作用。因此,我们引入了一种新的 Filtering-WoRA 范式,其中包含用于识别这个关键数据子集的过滤算法和用于轻度微调的 WoRA (Weighted Low-Rank Adaptation) 学习策略。过滤算法基于跨模态相关性,以删除大量粗略匹配的合成对。随着数据数量的减少,我们不需要对整个模型进行微调。因此,我们提出了一种 WoRA 学习策略,以有效地更新模型参数的最小部分。WoRA 简化了学习过程,从而提高了从较少但有效的数据实例中提取知识的效率。广泛的实验验证了预训练的有效性,我们的模型在具有挑战性的真实基准上实现了先进而高效的检索性能。值得注意的是,在 CUHK-PEDES 数据集上,我们实现了 67.02% 的有竞争力的 mAP,同时将模型训练时间缩短了 19.82%。
Introduction
研究现状
基于文本的人物搜索模型作为视觉语言检索的子任务,通常需要大量的数据进行训练,但行人数据的数量有限。大多数数据集 [12, 34, 68, 79] 是由三个来源构建的。(1) 第一个来源是通过摄像机镜头的采样,并附有手动注释。然而,由于隐私问题和高成本,构建大规模数据集通常是不可行的。(2) 第二个来源涉及从互联网收集图像和短视频。尽管数据集大小不断扩大,但嘈杂的 Web 文本和任务图像的不一致质量通常不是细粒度的最佳选择视觉-语言学习。(3) 因此,大多数研究人员 [68] 求助于利用生成模型,例如 GAN [77] 和扩散 [47, 52]。例如,APTM [68] 引入了由 Stable Diffusion [47] 生成的 1.51M 图像文本对,展示了在大型合成数据集上进行训练的潜力。
尽管在从大型合成数据集中学习方面取得了重大进展,但一个基本挑战仍然存在:考虑到训练过程中产生的大量计算成本,当面对实际上无限量的数据时,我们如何有效地提取知识?我们观察到两点:(1) 以前的工作 [68, 75, 77] 表明,即使提供了大量额外的生成数据,性能改进也会逐渐减少。这意味着并非海量合成数据集中的所有信息都同样有价值;相反,精心挑选的子集或 coreset 可能足以捕捉训练过程的本质。(2)如果我们只需要学习 coreset 数据,则模型不需要更新整个参数体积来保证训练精度。这种认识为显著缩短训练时间和模型复杂性提供了可能性。从本质上讲,我们的重点转移到探索通过更精简的数据和更紧凑的参数占用来提高准确性的策略。
本文工作
为此,我们提出了一种新的 Filtering-WoRA 范式,其中包含一种新的两阶段数据过滤方法,旨在识别核心集以提高模型性能,以及一种 WoRA(加权低秩适应)算法来优化预训练和微调模型,在保持模型性能和提高计算速度的同时,能够使用更少的参数进行训练。具体来说,我们的流程从数据集纯化开始,包括用于预训练的合成数据集和用于微调的真实数据集。为了过滤掉低质量的图像-文本对,例如不完整的描述性细节或模糊的图像细节,我们利用现成的大型跨模态模型从数据集中的图像和文本中提取特征,然后计算投影图像嵌入和投影文本嵌入之间的余弦相似性。此过程会为每个图像-文本对生成相似性分数,从而有助于根据我们预先确定的阈值选择高质量的数据集。随后,为了减少模型参数并提高计算速度,我们选择冻结预训练的权重,通过优化在适应过程中变化的秩分解矩阵来间接训练神经网络中的一些密集层。通过将预训练和微调权重分解为幅度和方向,我们的 WoRA 方法引入了三个新维度,以促进权重矩阵和秩分解矩阵的修改。这种方法允许学习最少数量的参数,同时提高模型性能(见图 1)。
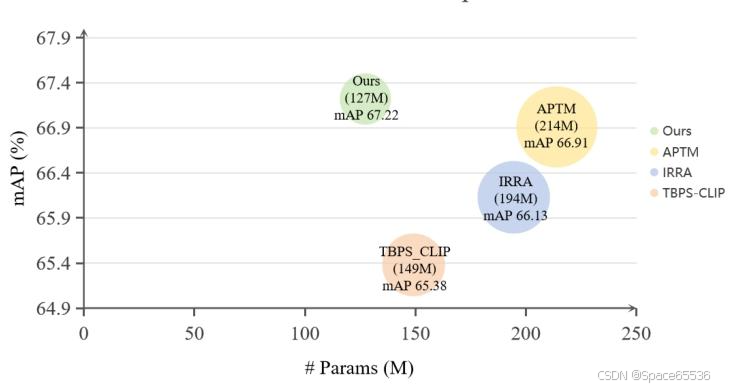
图 1:所提出的方法与现有方法在 mAP 准确度和参数数量方面的比较。我们观察到,与竞争方法(即 APTM [68]、IRRA [23] 和 TBPS-CLIP [4])相比,我们的方法部署的参数更少,同时实现了更高的 mAP。
2 RELATED WORK
2.1. VLP【粗粒度→细粒度→外部知识/辅助模块/采样策略/指令微调等:本文用来过滤嘈杂数据】
当前的 VLP 研究主要分为粗粒度和细粒度方法。
- 粗粒度方法采用卷积网络 [21, 22, 24] 或视觉转换器 [25, 31, 42, 46] 来提取和编码整体图像特征,从而构建视觉语言模型 (VLM)。SOHO [21] 等技术建议利用视觉词典 (VD) 来提取全面而紧凑的图像特征,从而促进增强的跨模态理解。ALBEF [31] 引入了一种对比损失,用于通过跨模态注意力在图像和文本表示融合之前对齐图像和文本表示,从而促进更扎实的视觉语言表示学习。此外,它还利用动量蒸馏来增强从嘈杂网络数据中的学习能力。尽管这些以图像为中心的整体方法很有效,但它们的性能通常被细粒度方法所超越。
- 受 NLP 领域进步的启发,细粒度方法 [9, 14, 28, 32, 37, 44, 55] 采用预训练的对象检测器 [2, 51],这些检测器在常见对象的注释数据集上训练,例如 COCO [38] 和 Visual Genome [26]。这使模型能够识别和分类图像中的所有潜在对象区域,将它们表示为以对象为中心的特征的集合。例如,VinVL [71] 增强了 V+L 任务的视觉表示,并开发了一种改进的对象检测模型来提供以对象为中心的图像表示。然而,这种以对象为中心的特征表示难以捕获不同区域中多个对象之间的关系,从而限制了其在编码多粒度视觉概念方面的有效性。另一个限制是对象检测器无法识别训练数据中不存在的不常见对象。
最近,出现了新的方法来弥合对象级和图像级对齐的学习。E2E-VLP [66] 采用 DETR [5] 作为目标检测模块,以增强检测能力。KD-VLP [41] 依靠外部对象检测器进行对象知识蒸馏,促进了跨不同语义层的跨模态对齐学习。OFA [57] 将视觉语言任务表述为序列到序列 (seq2seq) 问题,在预训练和微调阶段都坚持基于指令的学习,无需额外的任务特定层。Uni-Perceiver [80] 构建了一个统一的感知架构,使用单个 Transformer 和共享参数来应对不同的模式和任务,采用非混合采样策略进行稳定的多任务学习。X-VLM [69] 和 X2-VLM [70] 提出了一种具有灵活模块化架构的集成模型,可以同时学习多粒度对齐和定位,实现学习与各种文本描述相关的无限视觉概念的能力。在这项工作中,我们利用proficient VLP来过滤嘈杂的数据。
2.3. 以数据为中心的学习【数据质量差导致性能差→需要提取有效数据子集coreset】
随着大型语言模型的普及,对用于模型训练的大量数据集的需求越来越大[49,68\u201270]。然而,为在真实场景中训练模型而构建的开源数据集,例如 MALS 数据集 [68],可能会遇到文本描述不正确、图像或文本质量差以及图像-文本对之间的特征匹配不足等问题,所有这些都会对模型训练性能产生不利影响。随着数据集规模的扩大,可以观察到它们的质量并不总是同步扩展 [77]。通常,高质量数据的子集可以达到甚至超过大量但质量较差的数据集的效用。这种现象强调了精心策划高质量数据集的极端重要性,从而凸显了数据集构建效率和精度的必要性。例如,数据选择方法 [48, 64] 旨在仅使用最相关和信息量最大的示例进行识别和训练,丢弃不相关或冗余的数据。这样可以提高学习效率并提高模型性能,尤其是在处理大型数据集时。主动学习寻求通过选择信息量最大的注释实例来降低标记成本。数据清理和预处理技术旨在消除数据中的噪声、错误和不一致,使其更适合学习。核心集选择 [29, 30] 侧重于识别一小部分数据点(核心集),足以训练一个在整个数据集中表现良好的模型。通过选择具有代表性的子集,核心集选择可以降低训练的计算成本并提高模型泛化。我们的方法提倡一种旨在提高模型性能的 coreset 方法,建议使用现成的视觉语言模型来分割和过滤数据集的文本和图像对匹配分数,从而获得用于有效训练的核心集数据集。

图 2:我们的架构概述。图片的左半部分是整个训练阶段的流程图。通过嵌入图像文本对和属性特征,将通过图像编码器、文本编码器和交叉编码器获得相应的特征。在训练过程中,文本-图像和属性-图像匹配任务都有六个损失目标。在右侧,我们深入说明了 WoRA 方法,在图像编码器的上下文中精心应用。通过微调预训练权重的分解为振幅和方向分量,并使用 LoRA [20] 更新这两个分量,同时添加α和 β 可学习参数,来更新模型。由于图像编码器消耗最多的 GPU 内存和时间。在实践中,我们主要将 WoRA 应用于图像编码器。
3. 方法
3.1. Baseline revisit【itc;itm;mlm;apl】
我们采用联合属性提示学习和文本匹配学习框架 APTM [68] 作为我们的基线模型。该框架分为两个主要阶段:综合数据集的预训练和下游数据集的微调。基线包括三个编码器(图像编码器、文本编码器和交叉编码器)以及两个基于 MLP 的base headers。我们不追求这项工作中的网络贡献。因此,我们采用 Common backbone 进行公平的比较。图像编码器是一个 Swin Transformer (Swin-B) [42],而我们应用 Bert [11] 进行文本编码。[CLS] 嵌入表示整个图像/文本。交叉编码器集成了用于预测任务的图像和文本表示,利用 Bert 的后 6 层来处理先前获得的文本和图像嵌入,从而辨别它们的语义关系。我们采用两种类型的损失函数来支持对齐约束,分别为 imagetext 和 image-attribute 关联量身定制。图文功能包括图文对比学习 (ITC)、图文匹配学习 (ITM) 和掩码语言建模 (MLM),属性提示学习包括图像属性对比学习 (IAC) 损失、图像属性匹配学习 (IAM) 损失和掩码属性建模 (MAM) 损失。
总体 APL 损失为 L A P L = 1 3 ( L i a c + L i a m + L m a m ) L_{A P L}=\frac{1}{3}(L_{iac }+L_{iam }+L_{mam }) LAPL=31(Liac+Liam+Lmam) ,
完整的训练前损失公式为: L t o t a l = L i t c + L i t m + L m l m + η L A P L L_{total }=L_{i t c}+L_{i t m}+L_{m l m}+\eta L_{A P L} Ltotal=Litc+Li
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









